Ontdek de architectuur van Hadoop, het meest gebruikte raamwerk voor het opslaan en verwerken van enorme hoeveelheden gegevens.
In dit artikel zullen we Hadoop Architecture bestuderen. Het artikel legt de Hadoop-architectuur uit en de componenten van de Hadoop-architectuur die HDFS, MapReduce en YARN zijn. In het artikel zullen we de Hadoop-architectuur in detail onderzoeken, samen met het Hadoop Architecture-diagram.
Laten we nu beginnen met Hadoop Architecture.
Hadoop-architectuur
Het doel van het ontwerpen van Hadoop is het ontwikkelen van een goedkoop, betrouwbaar en schaalbaar raamwerk dat de opkomende big data opslaat en analyseert.
Apache Hadoop is een softwareframework ontworpen door Apache Software Foundation voor het opslaan en verwerken van grote datasets van verschillende groottes en formaten.
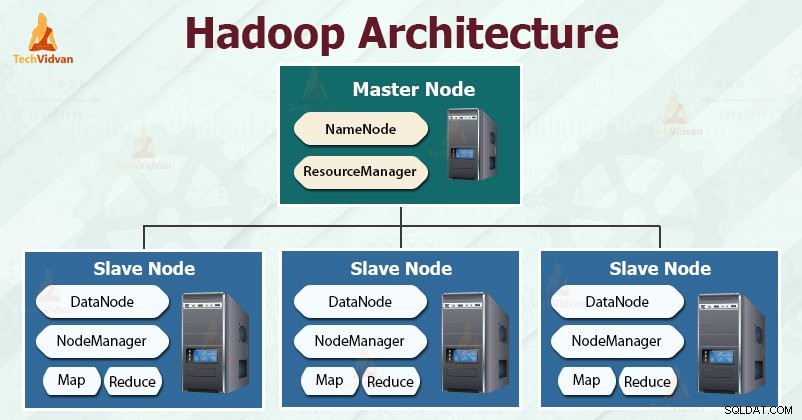
Hadoop volgt de master-slave architectuur voor het effectief opslaan en verwerken van grote hoeveelheden gegevens. De master nodes wijzen taken toe aan de slave nodes.
De slave-knooppunten zijn verantwoordelijk voor het opslaan van de feitelijke gegevens en het uitvoeren van de feitelijke berekening/verwerking. De hoofdknooppunten zijn verantwoordelijk voor het opslaan van de metadata en het beheren van de bronnen in het cluster.
Slave-knooppunten slaan de feitelijke bedrijfsgegevens op, terwijl de master de metagegevens opslaat.
De Hadoop-architectuur bestaat uit drie lagen. Dit zijn:
- Opslaglaag (HDFS)
- Bronbeheerlaag (YARN)
- Verwerkingslaag (MapReduce)
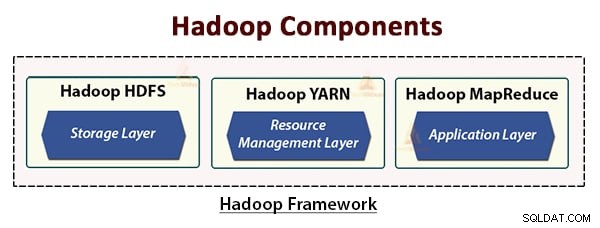
De HDFS, YARN en MapReduce zijn de kerncomponenten van het Hadoop Framework.
Laten we deze drie kerncomponenten nu in detail bestuderen.
1. HDFS
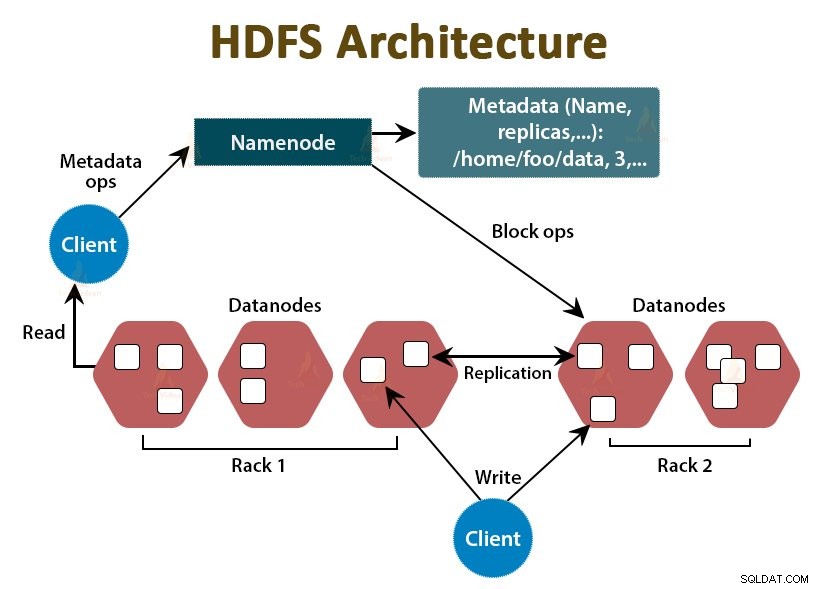
HDFS is het Hadoop gedistribueerde bestandssysteem , die draait op goedkope basishardware. Het is de opslaglaag voor Hadoop. De bestanden in HDFS worden opgedeeld in blokken van blokgrootte die datablokken worden genoemd.
Deze blokken worden vervolgens opgeslagen op de slave-knooppunten in het cluster. De blokgrootte is standaard 128 MB, die we kunnen configureren volgens onze vereisten.
Net als Hadoop volgt HDFS ook de master-slave-architectuur. Het bestaat uit twee daemons:NameNode en DataNode. De NameNode is de hoofddaemon die op het hoofdknooppunt draait. De DataNodes zijn de slave-daemon die op de slave-nodes draait.
NameNode
NameNode slaat de metadata van het bestandssysteem op, dat wil zeggen bestandsnamen, informatie over blokken van een bestand, blokkeert locaties, machtigingen, enz. Het beheert de Datanodes.
DataNode
DataNodes zijn de slave-knooppunten die de feitelijke bedrijfsgegevens opslaan. Het bedient de lees-/schrijfverzoeken van de klant op basis van de NameNode-instructies.
DataNodes slaat de blokken van de bestanden op en NameNode slaat de metadata op zoals bloklocaties, toestemming, enz.
2. MapReduce
Het is de gegevensverwerkingslaag van Hadoop. Het is een softwareraamwerk voor het schrijven van applicaties die grote hoeveelheden gegevens (binnen het bereik van terabytes tot petabytes) parallel verwerken op het cluster van standaardhardware.
Het MapReduce-framework werkt op de
De taak MapReduce is de werkeenheid die de klant wil uitvoeren. MapReduce-taak bestaat voornamelijk uit de invoergegevens, het MapReduce-programma en de configuratie-informatie. Hadoop voert de MapReduce-taken uit door ze te verdelen in twee soorten taken die kaarttaken zijn en taken verminderen . De Hadoop YARN heeft deze taken gepland en uitgevoerd op de knooppunten in het cluster.
Als de taken mislukken, worden vanwege een aantal ongunstige omstandigheden automatisch opnieuw gepland op een ander knooppunt.
De gebruiker definieert de kaartfunctie en de reduceer functie voor het uitvoeren van de MapReduce-taak.
De invoer voor de kaartfunctie en de uitvoer van de verkleiningsfunctie is het sleutel-waardepaar.
De functie van de kaarttaken is het laden, ontleden, filteren en transformeren van de gegevens. De uitvoer van de kaarttaak is de invoer voor de verkleiningstaak. Taak verkleinen voert vervolgens groepering en aggregatie uit op de uitvoer van de kaarttaak.
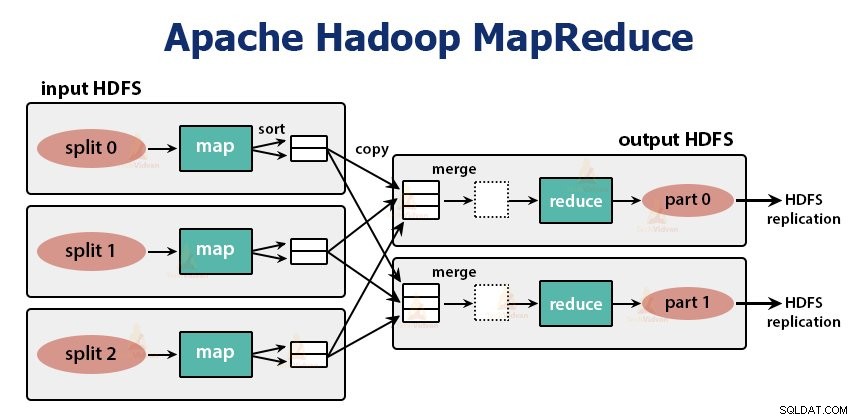
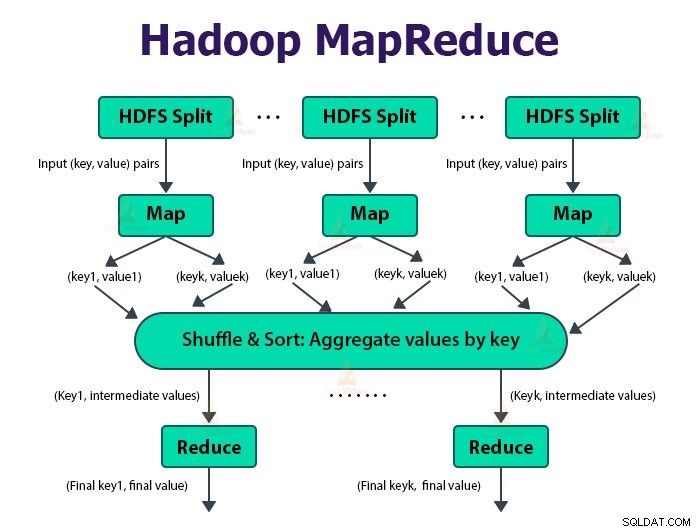
De MapReduce-taak wordt in twee fasen uitgevoerd-
1. Kaartfase
Hadoop verdeelt de invoer voor de MapReduce-taak in de splitsingen van vaste grootte die invoersplitsingen worden genoemd of splitst. De RecordReader zet deze splitsingen om in records en ontleedt de gegevens in records, maar het ontleedt de records zelf niet. RecordReader levert de gegevens aan de mapper-functie in sleutel-waardeparen.
In de kaartfase maakt Hadoop één kaarttaak die een door de gebruiker gedefinieerde functie uitvoert, kaartfunctie genaamd, voor elk record in de invoersplitsing. Het genereert nul of meerdere tussenliggende sleutel-waardeparen als uitvoer van de kaarttaak.
De kaarttaak schrijft de uitvoer naar de lokale schijf. Deze tussentijdse uitvoer wordt vervolgens verwerkt door de reductietaken die een door de gebruiker gedefinieerde reductiefunctie uitvoeren om de uiteindelijke uitvoer te produceren. Zodra de taak is voltooid, wordt de kaartuitvoer leeggemaakt.
De invoer voor de enkele verkleiningstaak is de uitvoer van alle Mappers die wordt uitgevoerd door alle kaarttaken. Met Hadoop kan de gebruiker een combinerfunctie definiëren die op de kaartuitvoer wordt uitgevoerd.
Combiner groepeert de gegevens in de kaartfase voordat ze worden doorgegeven aan Reducer. Het combineert de uitvoer van de kaartfunctie die vervolgens wordt doorgegeven als invoer voor de verkleiningsfunctie.
Als er meerdere reducers zijn, partitioneren de maptaken hun uitvoer, waarbij elk een partitie maakt voor elke reduceertaak. In elke partitie kunnen veel sleutels en de bijbehorende waarden zijn, maar de records voor een bepaalde sleutel bevinden zich allemaal in een enkele partitie.
Met Hadoop kunnen gebruikers de partitionering beheren door een door de gebruiker gedefinieerde partitioneringsfunctie op te geven. Over het algemeen is er een standaard Partitioner die de sleutels in een bucket plaatst met behulp van de hash-functie.
2. Verlaag fase:
De verschillende fasen bij het verminderen van de taak zijn als volgt:
De taak Reducer begint met een stap in shuffle en sorteren. Het belangrijkste doel van deze fase is om de equivalente sleutels bij elkaar te verzamelen. Met de sorteer- en shuffle-fase worden de gegevens gedownload die door de partitioner zijn geschreven naar het knooppunt waar Reducer wordt uitgevoerd.
Het sorteert elk gegevensstuk in een grote gegevenslijst. Het MapReduce-framework voert dit soort en shuffles uit, zodat we het gemakkelijk kunnen herhalen in de verkleiningstaak.
De sorteer en schuifel worden automatisch door het framework uitgevoerd. De ontwikkelaar kan via het vergelijkingsobject controle hebben over hoe de sleutels worden gesorteerd en gegroepeerd.
De Reducer, de door de gebruiker gedefinieerde reduceerfunctie, wordt eenmaal per toetsgroepering uitgevoerd. De reducer filtert, verzamelt en combineert gegevens op verschillende manieren. Zodra de taak verkleinen is voltooid, geeft deze nul of meer sleutel-waardeparen aan de OutputFormat. De taakuitvoer wordt opgeslagen in Hadoop HDFS.
Het neemt de uitvoer van het verloopstuk en schrijft het door RecordWriter naar het HDFS-bestand. Standaard scheidt het sleutel, waarde door een tab en elk record door een nieuwe regel.
3. GAREN
YARN staat voor Yet Another Resource Negotiator . Het is de resource management-laag van Hadoop. Het werd geïntroduceerd in Hadoop 2.
YARN is ontworpen met het idee om de functionaliteiten van taakplanning en resourcebeheer op te splitsen in afzonderlijke daemons. Het basisidee is om een globale ResourceManager en applicatiemaster per applicatie te hebben waarbij de applicatie een enkele job of DAG van jobs kan zijn.
YARN bestaat uit ResourceManager, NodeManager en ApplicationMaster per applicatie.
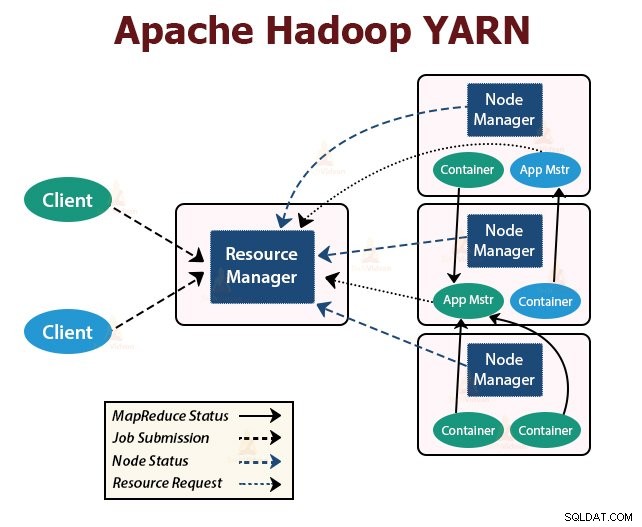
1. ResourceManager
Het bemiddelt tussen alle applicaties in het cluster.
Het heeft twee hoofdcomponenten:Scheduler en ApplicationManager.
- De Scheduler wijst resources toe aan de verschillende applicaties die in het cluster worden uitgevoerd, rekening houdend met de capaciteiten, wachtrijen, enz.
- Het is een pure Scheduler. Het controleert of volgt de status van de applicatie niet.
- Scheduler garandeert niet het opnieuw opstarten van de mislukte taken die zijn mislukt vanwege een applicatiefout of hardwarefout.
- Het voert de planning uit op basis van de resourcevereisten van de applicaties.
- Zij zijn verantwoordelijk voor het accepteren van de ingediende vacatures.
- ApplicationManager onderhandelt over de eerste container voor het uitvoeren van applicatiespecifieke ApplicationMaster.
- Ze bieden service voor het herstarten van de ApplicationMaster-container bij een storing.
- De ApplicationMaster per applicatie is verantwoordelijk voor het onderhandelen over containers van de Scheduler. Het volgt en bewaakt hun status en voortgang.
2. NodeManager:
NodeManager draait op de slave-knooppunten. Het is verantwoordelijk voor containers, het bewaken van het gebruik van de machinebronnen, dat wil zeggen CPU, geheugen, schijf, netwerkgebruik, en rapporteert dit aan de ResourceManager of Scheduler.
3. ApplicationMaster:
De ApplicationMaster per applicatie is een framework-specifieke bibliotheek. Het is verantwoordelijk voor het onderhandelen over middelen van de ResourceManager. Het werkt met de NodeManager(s) voor het uitvoeren en bewaken van de taken.
Samenvatting
In dit artikel hebben we Hadoop-architectuur bestudeerd. De Hadoop volgt de master-slave-topologie. De master nodes wijzen taken toe aan de slave nodes. De architectuur bestaat uit drie lagen:HDFS, YARN en MapReduce.
HDFS is het gedistribueerde bestandssysteem in Hadoop voor het opslaan van big data. MapReduce is het verwerkingsraamwerk voor het gedistribueerd verwerken van enorme gegevens in het Hadoop-cluster. YARN is verantwoordelijk voor het beheer van de resources tussen applicaties in het cluster.
De HDFS-daemon NameNode en YARN-daemon ResourceManager worden uitgevoerd op het hoofdknooppunt in het Hadoop-cluster. De HDFS-daemon DataNode en de YARN NodeManager draaien op de slave-knooppunten.
HDFS en MapReduce-framework draaien op dezelfde set knooppunten, wat resulteert in een zeer hoge totale bandbreedte over het cluster.
Blijf leren!!