In onze vorige Hadoop blogs die we hebben bestudeerd elk onderdeel van de Hadoop MapReduce-proces in detail. Hierin gaan we het zeer interessante onderwerp bespreken, namelijk Map Only-baan in Hadoop.
Eerst zullen we een korte introductie geven van de Kaart en Verminderen fase in Hadoop Mapreduce, daarna zullen we bespreken wat Map only-taak is in Hadoop MapReduce.
Ten slotte zullen we in deze tutorial ook de voor- en nadelen van de Hadoop Map Only-taak bespreken.
Wat is Hadoop Map Only Job?
Alleen kaart-taak in de Hadoop is het proces waarin mapper doet alle taken. Er wordt geen taak uitgevoerd door de reducer . De uitvoer van Mapper is de uiteindelijke uitvoer.
MapReduce is de gegevensverwerkingslaag van Hadoop. Het verwerkt grote gestructureerde en ongestructureerde gegevens die zijn opgeslagen in HDFS . MapReduce verwerkt ook een enorme hoeveelheid gegevens parallel.
Het doet dit door de taak (ingediende taak) op te delen in een reeks zelfstandige taken (subtaak). In Hadoop werkt MapReduce door de verwerking in fasen op te splitsen:Kaart en Verminderen .
- Kaart: Het is de eerste verwerkingsfase, waarin we alle complexe logische code specificeren. Het neemt een set gegevens en converteert naar een andere set gegevens. Het verdeelt elk afzonderlijk element in tuples (sleutel-waardeparen ).
- Verminderen: Het is de tweede fase van verwerking. Hier specificeren we lichtgewicht verwerking zoals aggregatie/sommatie. Het neemt de uitvoer van de kaart als invoer. Vervolgens combineert het die tuples op basis van de sleutel.
Uit dit voorbeeld van het aantal woorden kunnen we zeggen dat er twee sets parallelle processen zijn, in kaart brengen en verkleinen. In het kaartproces wordt de eerste invoer gesplitst om het werk over alle kaartknooppunten te verdelen, zoals hierboven weergegeven.
Vervolgens identificeert het framework elk woord en wijst het toe aan het nummer 1. Het creëert dus paren die tupels (sleutel-waarde) paren worden genoemd.
In het eerste mapperknooppunt passeert het drie woorden leeuw, tijger en de rivier. Het produceert dus 3 sleutel-waardeparen als uitvoer van het knooppunt. Drie verschillende sleutels en waarde ingesteld op 1 en hetzelfde proces herhaalt zich voor alle knooppunten.
Vervolgens geeft het deze tuples door aan de reductieknooppunten. Partitioner voert shuffelen uit zodat alle tuples met dezelfde sleutel naar hetzelfde knooppunt gaan.
In het reduceerproces gebeurt er in feite een aggregatie van waarden of liever een bewerking op waarden die dezelfde sleutel delen.
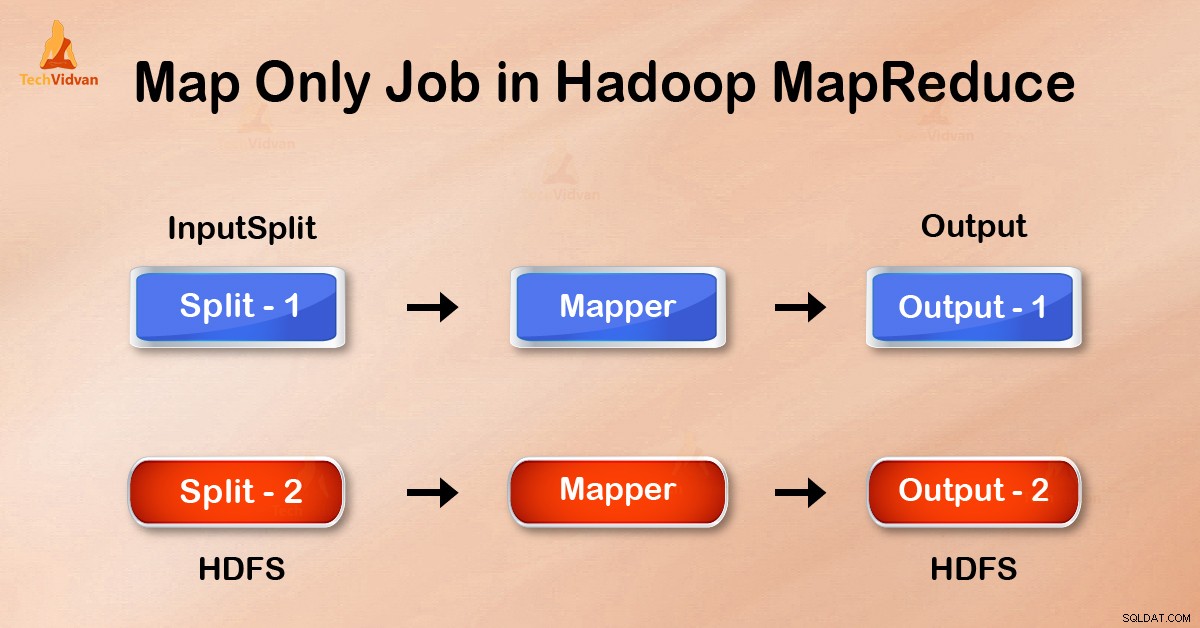
Laten we nu eens kijken naar een scenario waarin we alleen de bewerking hoeven uit te voeren. We hebben geen aggregatie nodig, in dat geval geven we de voorkeur aan 'Alleen kaart-taak ’.
In de taak 'Alleen kaart' voert de kaart alle taken uit met zijn InputSplit . Verkleiner werkt niet. De uitvoer van Mappers is de uiteindelijke uitvoer.
Hoe de reductiefase in MapReduce te vermijden?
Door job.setNumreduceTasks(0) . in te stellen in de configuratie in een driver kunnen we de reductiefase vermijden. Dit maakt een aantal reducer als 0 . Dus de enige mapper zal de volledige taak uitvoeren.
Voordelen van een baan met alleen kaarten in Hadoop
In MapReduce-taakuitvoering tussen kaart- en reductiefasen is er een sleutel-, sorteer- en shuffle-fase. Schudden –Sorteren zijn verantwoordelijk voor het sorteren van de sleutels in oplopende volgorde. Groepeer vervolgens waarden op basis van dezelfde sleutels. Deze fase is erg duur.
Als de reductiefase niet nodig is, moeten we deze vermijden. Omdat het vermijden van de reductiefase ook de sorteer- en shuffle-fase zou elimineren. Dit bespaart dus ook netwerkcongestie.
De reden is dat bij het schudden een uitvoer van de mapper reist om te verminderen. En wanneer de gegevensomvang enorm is, moeten grote gegevens naar de verkleiner reizen.
De uitvoer van de mapper wordt naar de lokale schijf geschreven voordat deze wordt verzonden om te verminderen. Maar in de taak met alleen kaart wordt deze uitvoer rechtstreeks naar HDFS geschreven. Dit bespaart nog meer tijd en verlaagt ook de kosten.
Conclusie
Daarom hebben we gezien dat een alleen-kaarttaak de netwerkcongestie vermindert door shuffle, sortering en fasevermindering te vermijden. Kaart alleen zorgt voor de algehele verwerking en produceert de uitvoer. DOOR job.setNumreduceTasks(0) . te gebruiken dit is bereikt.
Ik hoop dat je de functie van alleen de Hadoop-kaart hebt begrepen en dat deze belangrijk is omdat we alles hebben behandeld over de functie Map Only in Hadoop. Maar als u een vraag heeft, kunt u deze met ons delen in het opmerkingengedeelte.