Krijg een overzicht van de beschikbare mechanismen voor het maken van back-ups van gegevens die zijn opgeslagen in Apache HBase, en hoe u die gegevens kunt herstellen in het geval van verschillende scenario's voor gegevensherstel/failover
Met de toegenomen acceptatie en integratie van HBase in kritieke bedrijfssystemen, moeten veel ondernemingen dit belangrijke bedrijfsmiddel beschermen door robuuste strategieën voor back-up en noodherstel (BDR) uit te bouwen voor hun HBase-clusters. Hoe ontmoedigend het ook mag klinken om snel en eenvoudig een back-up te maken en potentieel petabytes aan gegevens te herstellen, HBase en het Apache Hadoop-ecosysteem bieden veel ingebouwde mechanismen om precies dat te bereiken.
In dit bericht krijgt u een overzicht op hoog niveau van de beschikbare mechanismen voor het maken van back-ups van gegevens die zijn opgeslagen in HBase, en hoe u die gegevens kunt herstellen in het geval van verschillende scenario's voor gegevensherstel/failover. Na het lezen van dit bericht zou u een weloverwogen beslissing moeten kunnen nemen over welke BDR-strategie het beste is voor uw zakelijke behoeften. U moet ook de voor-, nadelen en prestatie-implicaties van elk mechanisme begrijpen. (De details hierin zijn van toepassing op CDH 4.3.0/HBase 0.94.6 en hoger.)
Opmerking:op het moment van schrijven biedt Cloudera Enterprise 4 productieklare back-up en noodherstelfunctionaliteit voor HDFS en de Hive Metastore via Cloudera BDR 1.0 als een afzonderlijk gelicentieerde functie. HBase is niet opgenomen in die GA-release; daarom zijn de verschillende mechanismen die in deze blog worden beschreven, vereist. (Cloudera Enterprise 5, momenteel in bèta, biedt HBase snapshotbeheer via Cloudera BDR.)
Back-up
HBase is een gedistribueerd gegevensarchief met een logboekgestructureerde merge-tree met complexe interne mechanismen om de nauwkeurigheid, consistentie, versiebeheer, enzovoort van de gegevens te garanderen. Dus hoe kun je in vredesnaam een consistente back-up van deze gegevens krijgen die zich in een combinatie van HFiles en Write-Ahead-Logs (WAL's) op HDFS en in het geheugen op tientallen regioservers bevindt?
Laten we beginnen met de minst storende, kleinste gegevensvoetafdruk, minst prestatiebelastende mechanisme en ons opwerken tot de meest ontwrichtende tool in vorkheftruckstijl:
- Momentopnamen
- Replicatie
- Exporteren
- Kopieertabel
- HTable API
- Offline back-up van HDFS-gegevens
De volgende tabel geeft een overzicht om deze benaderingen snel te kunnen vergelijken, die ik hieronder in detail zal beschrijven.
| Prestatie-impact | Gegevensvoetafdruk | Stilstand | Incrementele back-ups | Gemak van implementatie | Mean Time To Recovery (MTTR) | |
| Momentopnamen | Minimaal | Klein | Kort (Alleen bij Herstellen) | Nee | Eenvoudig | Seconden |
| Replicatie | Minimaal | Groot | Geen | Intrinsiek | Gemiddeld | Seconden |
| Exporteren | Hoog | Groot | Geen | Ja | Eenvoudig | Hoog |
| CopyTable | Hoog | Groot | Geen | Ja | Eenvoudig | Hoog |
| API | Gemiddeld | Groot | Geen | Ja | Moeilijk | Aan jou |
| Handleiding | N.v.t. | Groot | Lang | Nee | Gemiddeld | Hoog |
Momentopnamen
Vanaf CDH 4.3.0 zijn HBase-snapshots volledig functioneel, rijk aan functies en vereisen ze geen clusterdowntime tijdens het maken ervan. Mijn collega Matteo Bertozzi heeft snapshots heel goed behandeld in zijn blogbericht en de daaropvolgende diepe duik. Hier zal ik alleen een overzicht op hoog niveau geven.
Snapshots leggen eenvoudig een moment vast voor uw tabel door het equivalent van harde UNIX-koppelingen naar de opslagbestanden van uw tabel op HDFS te maken (Afbeelding 1). Deze snapshots zijn binnen enkele seconden voltooid, plaatsen bijna geen prestatieoverhead op het cluster en creëren een minuscule gegevensvoetafdruk. Uw gegevens worden helemaal niet gedupliceerd, maar alleen gecatalogiseerd in kleine metagegevensbestanden, waardoor het systeem kan terugkeren naar dat moment als u die momentopname moet herstellen.
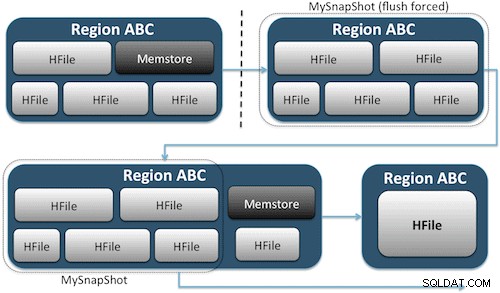
Het maken van een momentopname van een tabel is net zo eenvoudig als het uitvoeren van deze opdracht vanuit de HBase-shell:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Nadat u deze opdracht hebt gegeven, vindt u enkele kleine gegevensbestanden in /hbase/.snapshot/myTable (CDH4) of /hbase/.hbase-snapshots (Apache 0.94.6.1) in HDFS die de nodige informatie bevatten om uw snapshot te herstellen . Herstellen is net zo eenvoudig als het geven van deze commando's vanuit de shell:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Opmerking:zoals u kunt zien, vereist het herstellen van een momentopname een korte onderbreking omdat de tabel offline moet zijn. Alle gegevens die zijn toegevoegd/geüpdatet nadat de herstelde momentopname is gemaakt, gaan verloren.
Als uw zakelijke vereisten zodanig zijn dat u een externe back-up van uw gegevens moet hebben, kunt u de opdracht exportSnapshot gebruiken om de gegevens van een tabel te dupliceren naar uw lokale HDFS-cluster of een externe HDFS-cluster naar keuze.
Snapshots zijn elke keer een volledig beeld van uw tafel; er is momenteel geen incrementele snapshot-functionaliteit beschikbaar.
HBase-replicatie
HBase-replicatie is een ander back-upprogramma met zeer lage overheadkosten. (Mijn collega Himanshu Vashishtha behandelt replicatie in detail in deze blogpost.) Samengevat, replicatie kan worden gedefinieerd op kolomfamilieniveau, werkt op de achtergrond en houdt alle bewerkingen gesynchroniseerd tussen clusters in de replicatieketen.
Replicatie heeft drie modi:master->slave, master<->master en cyclisch. Deze aanpak biedt u de flexibiliteit om gegevens uit elk datacenter op te nemen en zorgt ervoor dat deze worden gerepliceerd in alle exemplaren van die tabel in andere datacenters. In het geval van een catastrofale storing in één datacenter, kunnen clientapplicaties worden omgeleid naar een alternatieve locatie voor de gegevens met behulp van DNS-tools.
Replicatie is een robuust, fouttolerant proces dat 'uiteindelijke consistentie' biedt, wat inhoudt dat recente bewerkingen van een tabel op elk moment mogelijk niet beschikbaar zijn in alle replica's van die tabel, maar dat ze er uiteindelijk wel zullen komen.
Opmerking:voor bestaande tabellen moet u eerst de brontabel handmatig naar de doeltabel kopiëren via een van de andere manieren die in dit bericht worden beschreven. Replicatie werkt alleen bij nieuwe schrijfbewerkingen/bewerkingen nadat u deze hebt ingeschakeld.

(Van Apache's Replicatie-pagina)
Exporteren
De Export-tool van HBase is een ingebouwd HBase-hulpprogramma waarmee gegevens uit een HBase-tabel eenvoudig kunnen worden geëxporteerd naar gewone SequenceFiles in een HDFS-directory. Er wordt een MapReduce-taak gemaakt die een reeks HBase API-aanroepen naar uw cluster maakt, en één voor één elke rij met gegevens uit de opgegeven tabel haalt en die gegevens naar uw opgegeven HDFS-directory schrijft. Dit hulpprogramma is prestatie-intensiever voor uw cluster omdat het gebruikmaakt van MapReduce en de HBase-client-API, maar het is rijk aan functies en ondersteunt het filteren van gegevens op versie of datumbereik, waardoor incrementele back-ups mogelijk worden.
Hier is een voorbeeld van de opdracht in zijn eenvoudigste vorm:
hbase org.apache.hadoop.hbase.mapreduce.Export
Zodra uw tabel is geëxporteerd, kunt u de resulterende gegevensbestanden kopiëren waar u maar wilt (zoals offsite/off-cluster storage). U kunt ook een externe HDFS-cluster/directory opgeven als de uitvoerlocatie van de opdracht, en Export zal de inhoud rechtstreeks naar de externe cluster schrijven. Houd er rekening mee dat deze aanpak een netwerkelement introduceert in het schrijfpad van de export, dus u moet controleren of uw netwerkverbinding met het externe cluster betrouwbaar en snel is.
Kopieertabel
Het hulpprogramma CopyTable wordt goed behandeld in het blogbericht van Jon Hsieh, maar ik zal de basis hier samenvatten. Net als bij Export, maakt CopyTable een MapReduce-taak die de HBase-API gebruikt om uit een brontabel te lezen. Het belangrijkste verschil is dat CopyTable de uitvoer rechtstreeks naar een bestemmingstabel in HBase schrijft, die lokaal kan zijn voor uw broncluster of op een externe cluster.
Een voorbeeld van de eenvoudigste vorm van het commando is:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Deze opdracht kopieert de inhoud van een tabel met de naam "test" naar een tabel in hetzelfde cluster met de naam "testCopy".
Merk op dat er een aanzienlijke prestatie-overhead is voor CopyTable, omdat het individuele "puts" gebruikt om de gegevens rij voor rij naar de doeltabel te schrijven. Als uw tabel erg groot is, kan CopyTable ervoor zorgen dat de memstore op de servers van de bestemmingsregio vol raakt, waardoor de geheugenopslag moet worden leeggemaakt, wat uiteindelijk zal leiden tot verdichting, het verzamelen van afval, enzovoort.
Bovendien moet u rekening houden met de prestatie-implicaties van het uitvoeren van MapReduce via HBase. Met grote datasets is die aanpak misschien niet ideaal.
HTable API (zoals een aangepaste Java-toepassing)
Zoals altijd het geval is met Hadoop, kunt u altijd uw eigen aangepaste toepassing schrijven die gebruikmaakt van de openbare API en de tabel rechtstreeks opvraagt. U kunt dit doen via MapReduce-taken om gebruik te maken van de voordelen van gedistribueerde batchverwerking van dat framework, of via een andere manier van uw eigen ontwerp. Deze aanpak vereist echter een diepgaand begrip van Hadoop-ontwikkeling en alle API's en prestatie-implicaties van het gebruik ervan in uw productiecluster.
Offline back-up van onbewerkte HDFS-gegevens
Het meest brute-force back-upmechanisme — ook het meest ontwrichtende — omvat de grootste gegevensvoetafdruk. U kunt uw HBase-cluster netjes afsluiten en handmatig alle gegevens en directorystructuren kopiëren die zich in /hbase in uw HDFS-cluster bevinden. Omdat HBase niet beschikbaar is, zorgt dat ervoor dat alle gegevens zijn bewaard in HFiles in HDFS en krijgt u een nauwkeurige kopie van de gegevens. Incrementele back-ups zijn echter bijna onmogelijk te verkrijgen, omdat u bij toekomstige back-ups niet kunt vaststellen welke gegevens zijn gewijzigd of toegevoegd.
Het is ook belangrijk op te merken dat het herstellen van uw gegevens een offline metareparatie vereist omdat de .META. tabel zou mogelijk ongeldige informatie bevatten op het moment van herstel. Deze aanpak vereist ook een snel, betrouwbaar netwerk om de gegevens offsite over te dragen en later indien nodig te herstellen.
Om deze redenen raadt Cloudera deze benadering van HBase-back-ups ten zeerste af.
Rampherstel
HBase is ontworpen als een extreem fouttolerant gedistribueerd systeem met native redundantie, ervan uitgaande dat hardware vaak uitvalt. Herstel na noodgevallen in HBase komt meestal in verschillende vormen:
- Catastrofale storing op datacenterniveau, waardoor failover naar een back-uplocatie nodig is
- Een eerdere kopie van uw gegevens moeten herstellen vanwege een gebruikersfout of per ongeluk verwijderen
- De mogelijkheid om een point-in-time kopie van uw gegevens te herstellen voor controledoeleinden
Zoals bij elk rampherstelplan, bepalen de bedrijfsvereisten hoe het plan wordt ontworpen en hoeveel geld erin wordt geïnvesteerd. Nadat u de back-ups van uw keuze hebt gemaakt, neemt het terugzetten verschillende vormen aan, afhankelijk van het type herstel dat nodig is:
- Failover naar back-upcluster
- Tabel importeren/een momentopname herstellen
- Wijs de HBase-hoofdmap naar de back-uplocatie
Als uw back-upstrategie zodanig is dat u uw HBase-gegevens hebt gerepliceerd naar een back-upcluster in een ander datacenter, is failover net zo eenvoudig als het doorverwijzen van uw eindgebruikersapplicaties naar het back-upcluster met DNS-technieken.
Houd er echter rekening mee dat als u van plan bent om gegevens naar uw back-upcluster te schrijven tijdens de uitvalperiode, u ervoor moet zorgen dat de gegevens terugkeren naar het primaire cluster wanneer de storing voorbij is. Master-naar-master of cyclische replicatie zal dit proces automatisch voor u afhandelen, maar een master-slave-replicatieschema zorgt ervoor dat uw mastercluster niet synchroon loopt, waardoor handmatige tussenkomst na de storing nodig is.
Samen met de eerder beschreven Export-functie, is er een corresponderende Import-tool die de gegevens kan nemen waarvan eerder een back-up is gemaakt door Export en deze kan herstellen naar een HBase-tabel. Dezelfde implicaties voor de prestaties die van toepassing waren op Export, zijn ook van toepassing op Import. Als uw back-upschema het maken van momentopnamen inhield, is het terugzetten naar een eerdere kopie van uw gegevens net zo eenvoudig als het herstellen van die momentopname.
U kunt ook herstellen van een ramp door simpelweg de eigenschap hbase.root.dir in hbase-site.xml te wijzigen en deze naar een reservekopie van uw /hbase-directory te verwijzen als u de brute-force offline kopie van de HDFS-gegevensstructuren had gedaan . Dit is echter ook de minst wenselijke van de herstelopties omdat het een langdurige uitval vereist terwijl u de volledige gegevensstructuur terug kopieert naar uw productiecluster, en zoals eerder vermeld, .META. kan niet synchroon lopen.
Conclusie
Samengevat vereist het herstellen van gegevens na een of andere vorm van verlies of uitval een goed ontworpen BDR-plan. Ik raad u ten zeerste aan om uw zakelijke vereisten voor uptime, nauwkeurigheid/beschikbaarheid van gegevens en noodherstel grondig te begrijpen. Gewapend met gedetailleerde kennis van uw zakelijke vereisten, kunt u zorgvuldig de tools kiezen die het beste aan die behoeften voldoen.
Het selecteren van de tools is echter nog maar het begin. U moet uw BDR-strategie op grote schaal testen om er zeker van te zijn dat deze functioneel werkt in uw infrastructuur, voldoet aan uw zakelijke behoeften en dat uw operationele teams zeer goed bekend zijn met de stappen die nodig zijn voordat een storing optreedt en u erachter komt op de harde manier dat je BDR-abonnement werkt niet.
Als je op dit onderwerp wilt reageren of verder wilt discussiëren, gebruik dan ons communityforum voor HBase.
Verder lezen:
- Jon Hsieh's Strata + Hadoop World 2012 presentatie
- HBase:de definitieve gids (Lars George)
- HBase in actie (Nick Dimiduk/Amandeep Khurana)