Automatische failover voor MySQL-replicatie is al jaren onderwerp van discussie.
Is het een goede zaak of een slechte zaak?
Voor degenen met een lang geheugen in de MySQL-wereld, herinneren ze zich misschien de GitHub-storing in 2012 die voornamelijk werd veroorzaakt doordat software de verkeerde beslissingen nam.
GitHub was toen net gemigreerd naar een combinatie van MySQL Replication, Corosync, Pacemaker en Percona Replication Manager. PRM besloot een failover uit te voeren na mislukte gezondheidscontroles op de master, die tijdens een schemamigratie overbelast was. Er werd een nieuwe master geselecteerd, maar deze presteerde slecht vanwege koude caches. De hoge vraagbelasting van de drukke site zorgde ervoor dat PRM-hartslagen opnieuw faalden op de koude master, en PRM activeerde vervolgens een nieuwe failover naar de oorspronkelijke master. En de problemen gingen gewoon door, zoals hieronder samengevat.
 Bron:Henrik Ingo &Massimo Brignoli's op Percona Live 2013
Bron:Henrik Ingo &Massimo Brignoli's op Percona Live 2013 Een paar jaar snel vooruit en GitHub is terug met een behoorlijk geavanceerd raamwerk voor het beheren van MySQL-replicatie en geautomatiseerde failover! Zoals Shlomi Noach het zegt:
“Daarvoor maken we gebruik van geautomatiseerde masterfailovers. De tijd die een mens nodig heeft om een defecte master te wekken en te repareren, gaat onze verwachting van beschikbaarheid te boven, en het uitvoeren van een dergelijke failover is soms niet triviaal. We verwachten dat masterfouten automatisch worden gedetecteerd en hersteld binnen 30 seconden of minder, en we verwachten dat failover zal resulteren in minimaal verlies van beschikbare hosts."
De meeste bedrijven zijn geen GitHub, maar je zou kunnen stellen dat geen enkel bedrijf van storingen houdt. Storingen zijn storend voor elk bedrijf en kosten ook geld. Mijn gok is dat de meeste bedrijven die er zijn waarschijnlijk wensten dat ze een soort geautomatiseerde failover hadden, en de redenen om het niet te implementeren zijn waarschijnlijk de complexiteit van de bestaande oplossingen, gebrek aan competentie bij het implementeren van dergelijke oplossingen, of gebrek aan vertrouwen in software om te nemen zo'n belangrijke beslissing.
Er zijn een aantal geautomatiseerde failover-oplossingen, waaronder (en niet beperkt tot) MHA, MMM, MRM, mysqlfailover, Orchestrator en ClusterControl. Sommige zijn al een aantal jaren op de markt, andere zijn recenter. Dat is een goed teken, meerdere oplossingen betekenen dat de markt er is en dat mensen het probleem proberen aan te pakken.
Toen we automatische failover binnen ClusterControl ontwierpen, gebruikten we een paar leidende principes:
-
Zorg ervoor dat de master echt dood is voordat je een failover uitvoert
In het geval van een netwerkpartitie, waarbij de failover-software het contact met de master verliest, zal deze deze niet meer zien. Maar de master werkt mogelijk goed en kan worden gezien door de rest van de replicatietopologie.
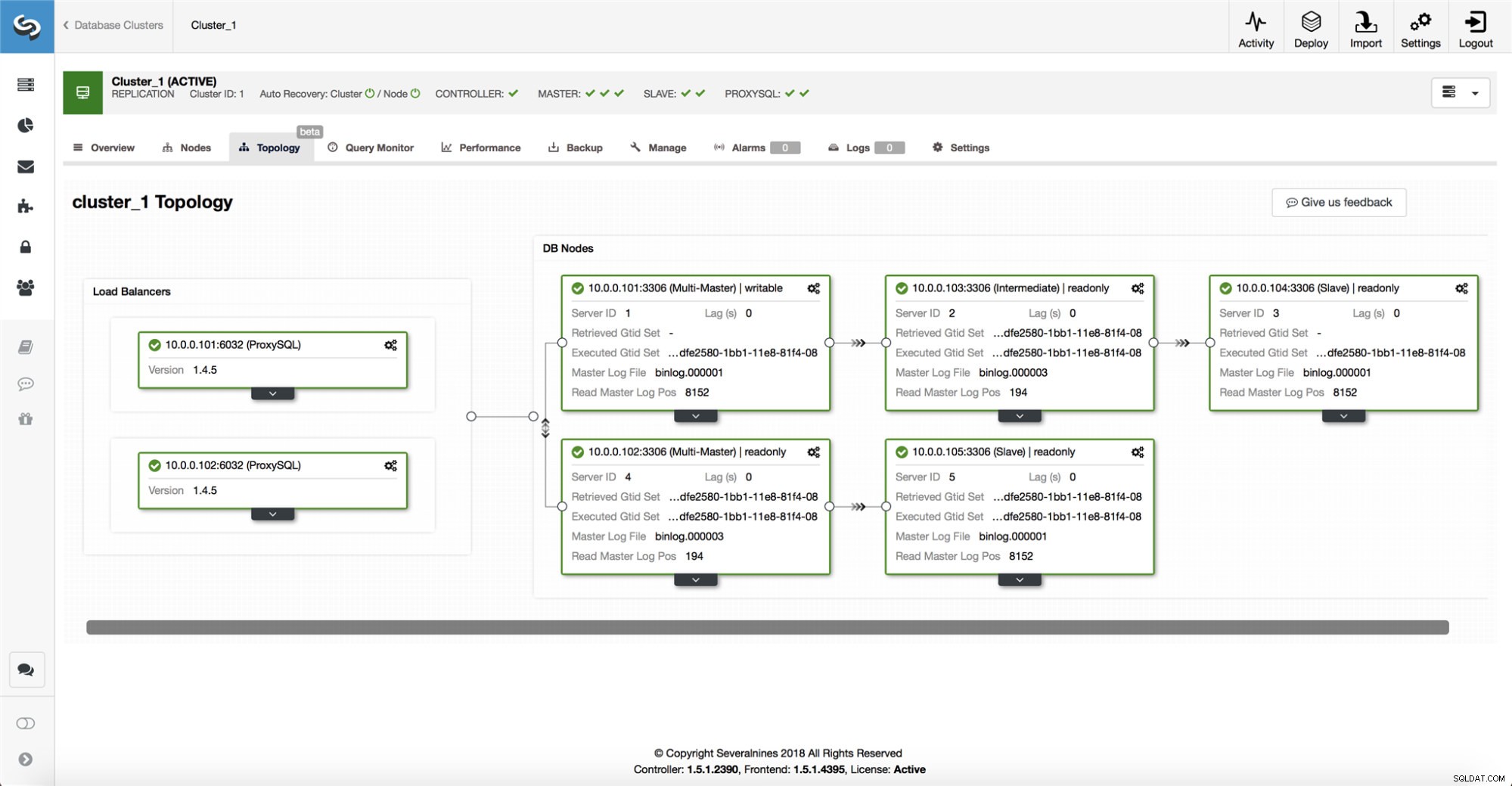
ClusterControl verzamelt informatie van alle databaseknooppunten en alle gebruikte databaseproxy's/load balancers, en bouwt vervolgens een weergave van de topologie. Het zal geen failover proberen als de slaves de master kunnen zien, en ook niet als ClusterControl niet 100% zeker is van de status van de master.
ClusterControl maakt het ook gemakkelijk om de topologie van de installatie te visualiseren, evenals de status van de verschillende knooppunten (dit is ClusterControl's begrip van de status van het systeem, op basis van de informatie die het verzamelt).
-
Slechts één keer failover
Over flappen is al veel geschreven. Het kan erg rommelig worden als de beschikbaarheidstool besluit meerdere failovers uit te voeren. Dat is een gevaarlijke situatie. Elke gekozen master, hoe kort de periode ook was, kan zijn eigen reeks wijzigingen hebben die nooit naar een server zijn gerepliceerd. U kunt dus inconsistentie krijgen tussen alle gekozen meesters.
-
Maak geen failover naar een inconsistente slaaf
Bij het selecteren van een slaaf om als meester te promoveren, zorgen we ervoor dat de slaaf geen inconsistenties heeft, b.v. foutieve transacties, aangezien dit de replicatie heel goed kan verbreken.
-
Alleen schrijven naar de master
Replicatie gaat van de master naar de slave(s). Rechtstreeks schrijven naar een slaaf zou een divergerende dataset opleveren, en dat kan een potentiële bron van problemen zijn. We hebben de slaves ingesteld op read_only en super_read_only in recentere versies van MySQL of MariaDB. We adviseren ook het gebruik van een load balancer, bijvoorbeeld ProxySQL of MaxScale, om de applicatielaag af te schermen van de onderliggende databasetopologie en eventuele wijzigingen daarin. De load balancer dwingt ook schrijfacties af op de huidige master.
-
Herstel de mislukte master niet automatisch
Als de master is mislukt en er een nieuwe master is gekozen, zal ClusterControl niet proberen de mislukte master te herstellen. Waarom? Die server kan gegevens bevatten die nog niet zijn gerepliceerd, en de beheerder zou wat onderzoek moeten doen naar de fout. Oké, je kunt ClusterControl nog steeds configureren om de gegevens op de mislukte master te wissen en deze als slaaf bij de nieuwe master te laten aansluiten - als je het goed vindt om wat gegevens te verliezen. Maar standaard laat ClusterControl de mislukte master staan, totdat iemand ernaar kijkt en besluit deze opnieuw in de topologie te introduceren.
Dus, moet u failover automatiseren? Het hangt af van hoe u replicatie hebt geconfigureerd. Circulaire replicatie-instellingen met meerdere beschrijfbare masters of complexe topologieën zijn waarschijnlijk geen goede kandidaten voor automatische failover. We zouden ons houden aan de bovenstaande principes bij het ontwerpen van een replicatie-oplossing.
Op PostgreSQL
Als het gaat om PostgreSQL-streamingreplicatie, gebruikt ClusterControl vergelijkbare principes om failover te automatiseren. Voor PostgreSQL ondersteunt ClusterControl zowel asynchrone als synchrone replicatiemodellen tussen de master en de slaves. In beide gevallen en bij uitval wordt de slave met de meest actuele gegevens als nieuwe master gekozen. Mislukte masters worden niet automatisch hersteld/gefixeerd om opnieuw deel te nemen aan de replicatie-instellingen.
Er zijn een paar beschermende maatregelen genomen om ervoor te zorgen dat de mislukte master down is en blijft, b.v. het wordt verwijderd uit de taakverdeling die is ingesteld in de proxy en het wordt gedood als b.v. de gebruiker zou het handmatig opnieuw opstarten. Het is daar wat uitdagender om netwerksplitsingen tussen ClusterControl en de master te detecteren, omdat de slaves geen informatie geven over de status van de master waarvan ze repliceren. Een proxy voor de database-configuratie is dus belangrijk omdat deze een ander pad naar de master kan bieden.
Op MongoDB
MongoDB-replicatie binnen een replicaset via de oplog lijkt erg op binlog-replicatie, dus hoe komt het dat MongoDB automatisch een mislukte master herstelt? Het probleem is er nog steeds en MongoDB lost dat op door alle wijzigingen terug te draaien die niet naar de slaven werden gerepliceerd op het moment van de storing. Die gegevens worden verwijderd en in een 'rollback'-map geplaatst, dus het is aan de beheerder om deze te herstellen.
Bekijk ClusterControl voor meer informatie; en voel je vrij om hieronder te reageren of vragen te stellen.