Back-ups - een van de belangrijkste dingen om voor te zorgen bij het beheren van databases. Er wordt gezegd dat er twee soorten mensen zijn:degenen die een back-up van hun gegevens maken en degenen die een back-up van hun gegevens maken. In deze blogpost bespreken we goede praktijken rond back-ups en laten we u zien hoe u een betrouwbaar back-upsysteem kunt bouwen met ClusterControl.
We zullen zien hoe ClusterControl's u gecentraliseerd back-upbeheer biedt voor MySQL, MariaDB, MongoDB en PostgreSQL. Het biedt u hot-back-ups van grote datasets, point-in-time recovery, in-rust en in-transit data-encryptie, data-integriteit via automatische herstelverificatie, cloud-back-ups (AWS, Google en Azure) voor Disaster Recovery, retentiebeleid om naleving te garanderen , en geautomatiseerde waarschuwingen en rapportage.
Back-uptypes
Er zijn twee hoofdtypen back-up die we kunnen doen in ClusterControl:
- Logische back-up - back-up van gegevens wordt opgeslagen in een voor mensen leesbare indeling zoals SQL
- Fysieke back-up - back-up bevat binaire gegevens
Beide vullen elkaar aan - logische back-up stelt u in staat om (min of meer eenvoudig) tot een enkele rij gegevens op te halen. Fysieke back-ups zouden meer tijd vergen om dat te bereiken, maar aan de andere kant stellen ze je in staat om een hele host heel snel te herstellen (iets dat uren of zelfs dagen kan duren bij gebruik van logische back-up).
ClusterControl ondersteunt back-up voor MySQL/MariaDB/Percona Server, PostgreSQL en MongoDB.
Back-up plannen
Het starten van een back-up in ClusterControl is eenvoudig en efficiënt met behulp van een wizard. Het plannen van een back-up biedt gebruiksvriendelijkheid en toegang tot andere functies, zoals encryptie, automatische test/verificatie van back-ups of cloudarchivering.
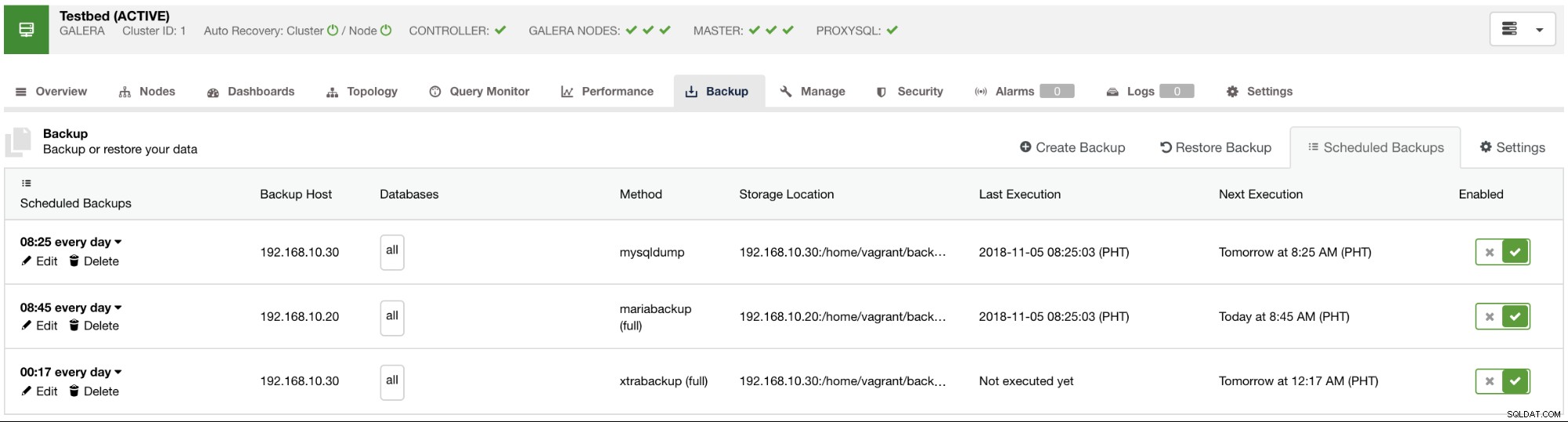
Beschikbare geplande back-ups worden weergegeven op het tabblad Geplande back-ups, zoals te zien is in de onderstaande afbeelding:
Als een goede gewoonte voor het plannen van een back-up, moet u al uw gedefinieerde back-upretentie hebben en een dagelijkse back-up wordt aanbevolen. Het hangt echter ook af van de gegevens die u nodig hebt, het verkeer dat u zou verwachten en de beschikbaarheid van de gegevens wanneer u ze nodig hebt, vooral tijdens gegevensherstel waarbij gegevens per ongeluk zijn verwijderd of een schijfbeschadiging - die onvermijdelijk zijn. Er zijn ook situaties waarin gegevensverlies reproduceerbaar is of handmatig kan worden gedupliceerd, zoals het genereren van rapporten, miniaturen of gegevens in de cache. Hoewel de vraag afhangt van hoe je ze onmiddellijk nodig hebt wanneer zich een ramp voordoet; indien mogelijk wilt u dagelijks zowel mysqldump- als xtrabackup-back-ups maken zodat MySQL gebruikmaakt van de logische en fysieke back-upbeschikbaarheid. Om nog meer bases te dekken, wil je misschien meerdere incrementele xtrabackup-runs per dag plannen. Dit kan wat schijfruimte, schijf-I/O of zelfs CPU-I/O besparen in plaats van een volledige back-up te maken.
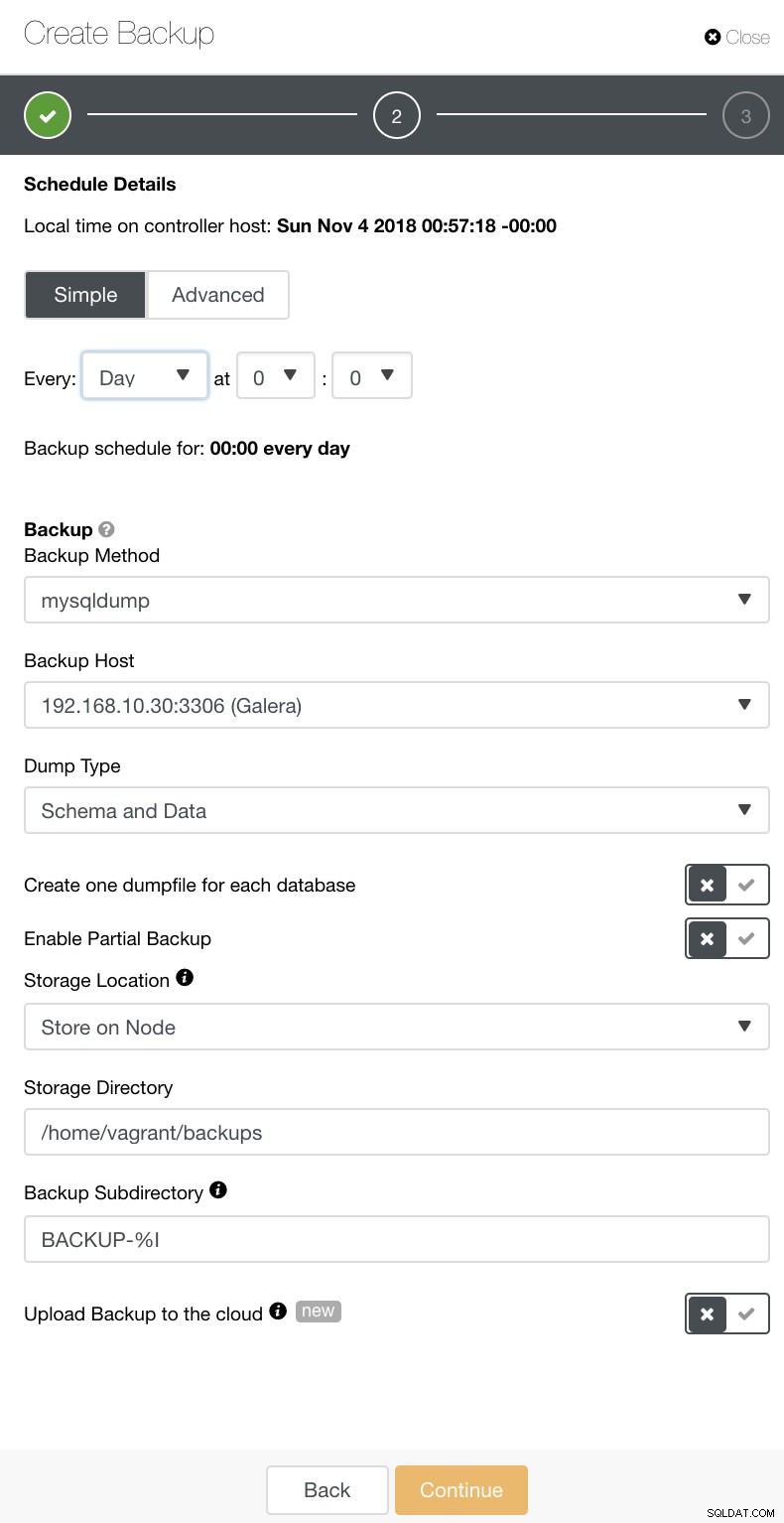
In ClusterControl plan je deze verschillende soorten back-ups eenvoudig in. Er zijn een aantal instellingen om over te beslissen. U kunt een back-up opslaan op de controller of lokaal, op het databaseknooppunt waar de back-up wordt gemaakt. U moet beslissen op welke locatie de back-up moet worden opgeslagen en van welke databases u een back-up wilt maken:alle datasets of afzonderlijke schema's? Zie de afbeelding hieronder:
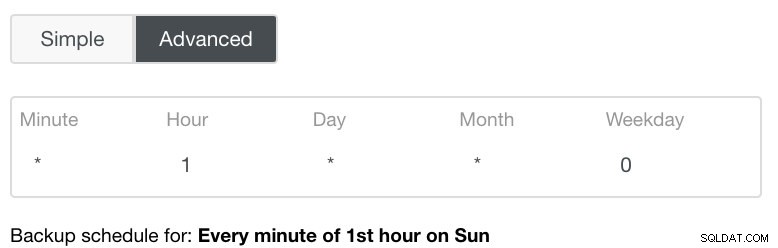
De geavanceerde instelling zou profiteren van een cron-achtige configuratie voor meer granulariteit. Zie onderstaande afbeelding:
Telkens wanneer zich een storing voordoet, behandelt ClusterControl deze problemen efficiënt en produceert het logs voor verdere diagnose van de back-upfout.
Afhankelijk van het back-uptype dat u hebt gekozen, zijn er afzonderlijke instellingen om te configureren. Voor Xtrabackup en Galera Cluster hebt u mogelijk de opties om te kiezen welke instellingen uw fysieke back-up van toepassing zou zijn bij het uitvoeren. Zie hieronder:
- Compressie gebruiken
- Compressieniveau
- Desync-knooppunt tijdens back-up
- Back-upvergrendelingen
- DDL vergrendelen per tabel
- Xtrabackup parallelle kopieerthreads
- Throttle Rate voor netwerkstreaming (MB/s)
- Gebruik PIGZ voor parallelle gzip
- Encryptie inschakelen
- Retentie
In de onderstaande afbeelding kunt u zien hoe u de opties dienovereenkomstig kunt markeren en er zijn knopinfopictogrammen die meer informatie geven over de opties die u wilt gebruiken voor uw back-upbeleid.
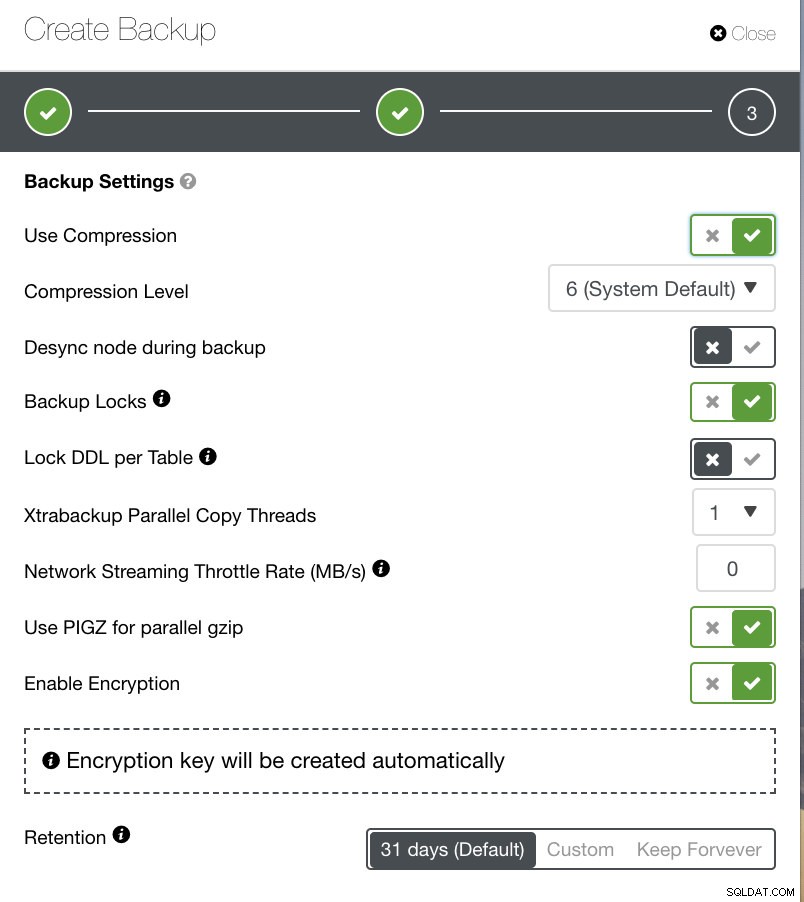
Afhankelijk van uw back-upbeleid kan ClusterControl worden afgestemd op de best practices voor het up-to-date maken van uw back-ups. Bij het definiëren van uw back-upbeleid wordt verwacht dat u de vereiste instellingen beschikbaar moet hebben, van hardware tot software tot cloud, duurzaamheid, hoge beschikbaarheid of schaalbaarheid.
Wanneer u back-ups maakt op een Galera-cluster, is het een goede gewoonte om de Galera-node wsrep_desync=ON in te stellen terwijl de back-up wordt uitgevoerd. Hierdoor wordt het knooppunt uitgesloten van deelname aan Flow Control en wordt het hele cluster beschermd tegen replicatievertraging, vooral als uw gegevens waarvan een back-up moet worden gemaakt, groot zijn. Houd er in ClusterControl rekening mee dat hierdoor mogelijk ook uw doelback-upknooppunt uit de taakverdelingsset wordt verwijderd. Dit is met name het geval als u HAProxy-, ProxySQL- of MaxScale-proxy's gebruikt. Als u een waarschuwingsmanager hebt ingesteld voor het geval de node is gedesynchroniseerd, kunt u deze uitschakelen tijdens de periode waarin de back-up is geactiveerd.
Een andere populaire manier om de impact van een back-up op een Galera Cluster of een replicatiemaster te minimaliseren, is door een replicatieslave in te zetten en deze vervolgens te gebruiken als een bron voor back-ups - op deze manier zal Galera Cluster op geen enkel moment worden beïnvloed, aangezien de back-up op de slave is ontkoppeld van het cluster.
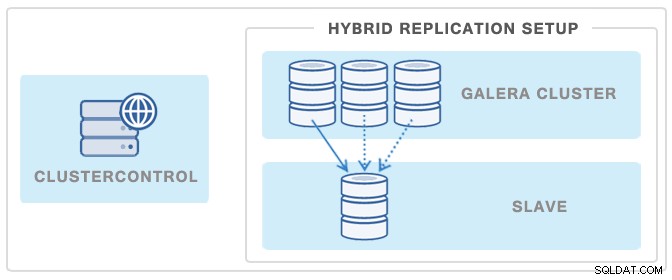
Met ClusterControl zet u zo'n slave in slechts een paar klikken in. Zie onderstaande afbeelding:
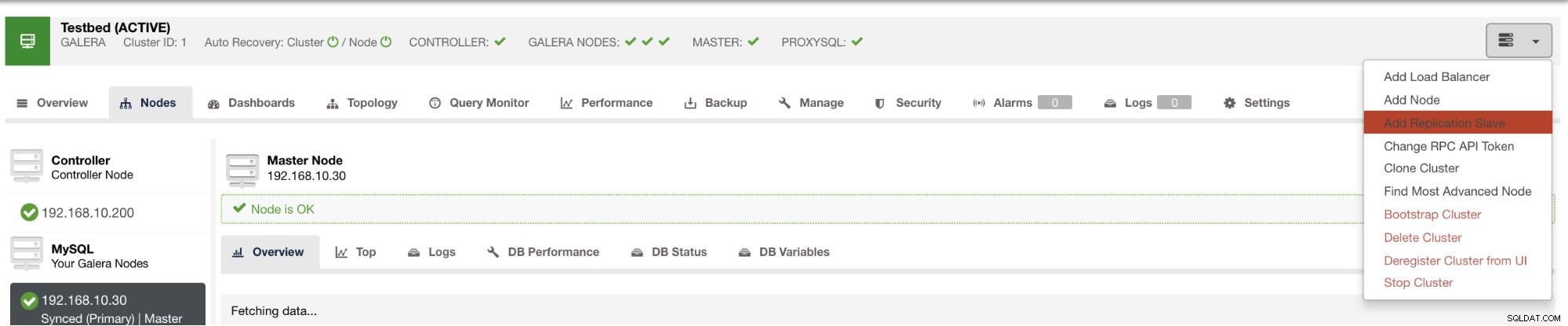
en zodra u op die knop klikt, kunt u selecteren op welke knooppunten u een slave wilt instellen. Zorg ervoor dat de binaire logboekregistratie van de knoop punten is ingeschakeld. Het inschakelen van het binaire logboek kan ook worden gedaan via ClusterControl, wat meer haalbaarheid toevoegt voor het beheren van uw gewenste master. Zie onderstaande afbeelding:
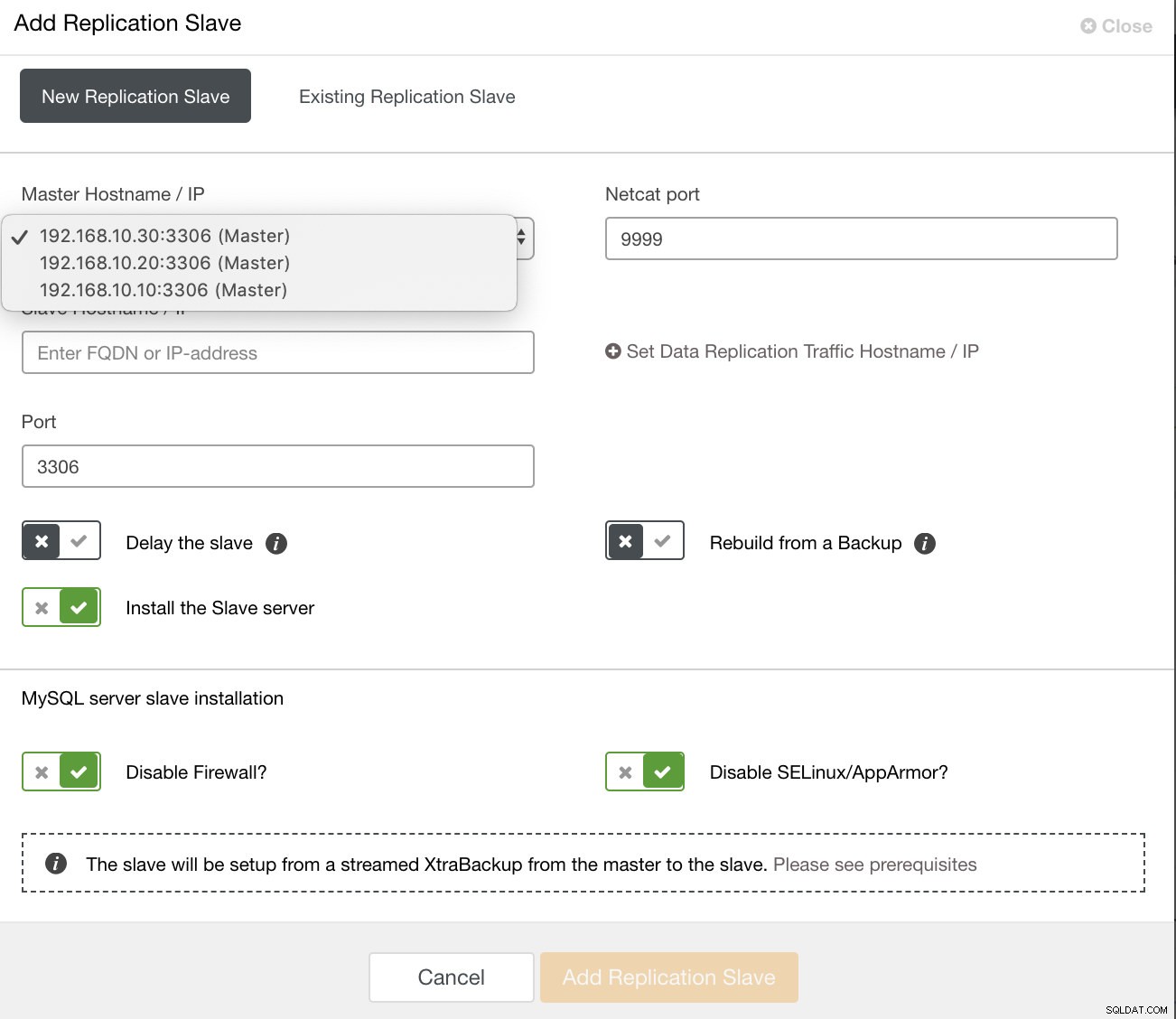
en u kunt ook een bestaande replicatieslave instellen,
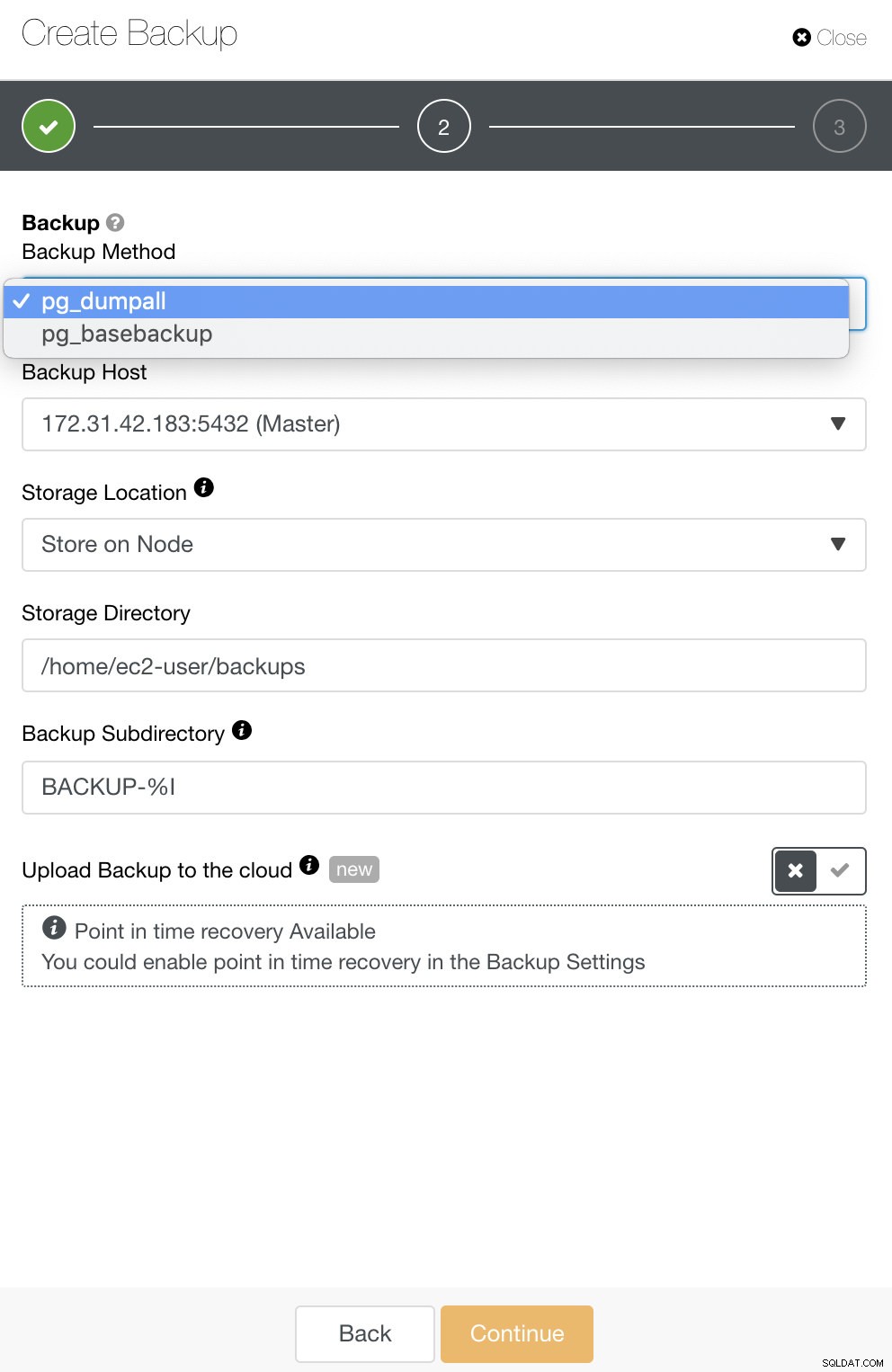
Voor PostgreSQL hebt u opties om een back-up te maken van logische of fysieke back-ups. In ClusterControl kunt u uw PostgreSQL-back-ups gebruiken door pg_dump of pg_basebackup te selecteren. pg_basebackup werkt niet voor versies ouder dan 9.3.
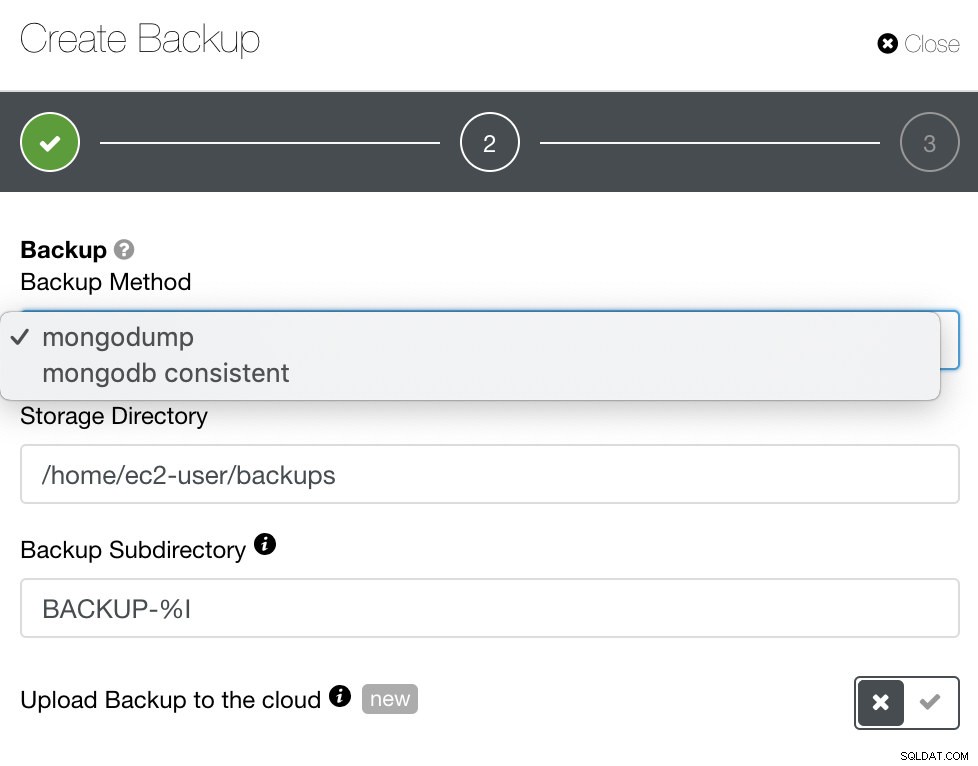
Voor MongoDB biedt ClusterControl mongodump of mongodb consistent. Mogelijk moet u er rekening mee houden dat mongodb consistent RHEL 7 niet ondersteunt, maar u kunt het mogelijk handmatig installeren.
ClusterControl zal standaard een rapport weergeven van alle gemaakte, succesvolle of mislukte back-ups. Zie hieronder:
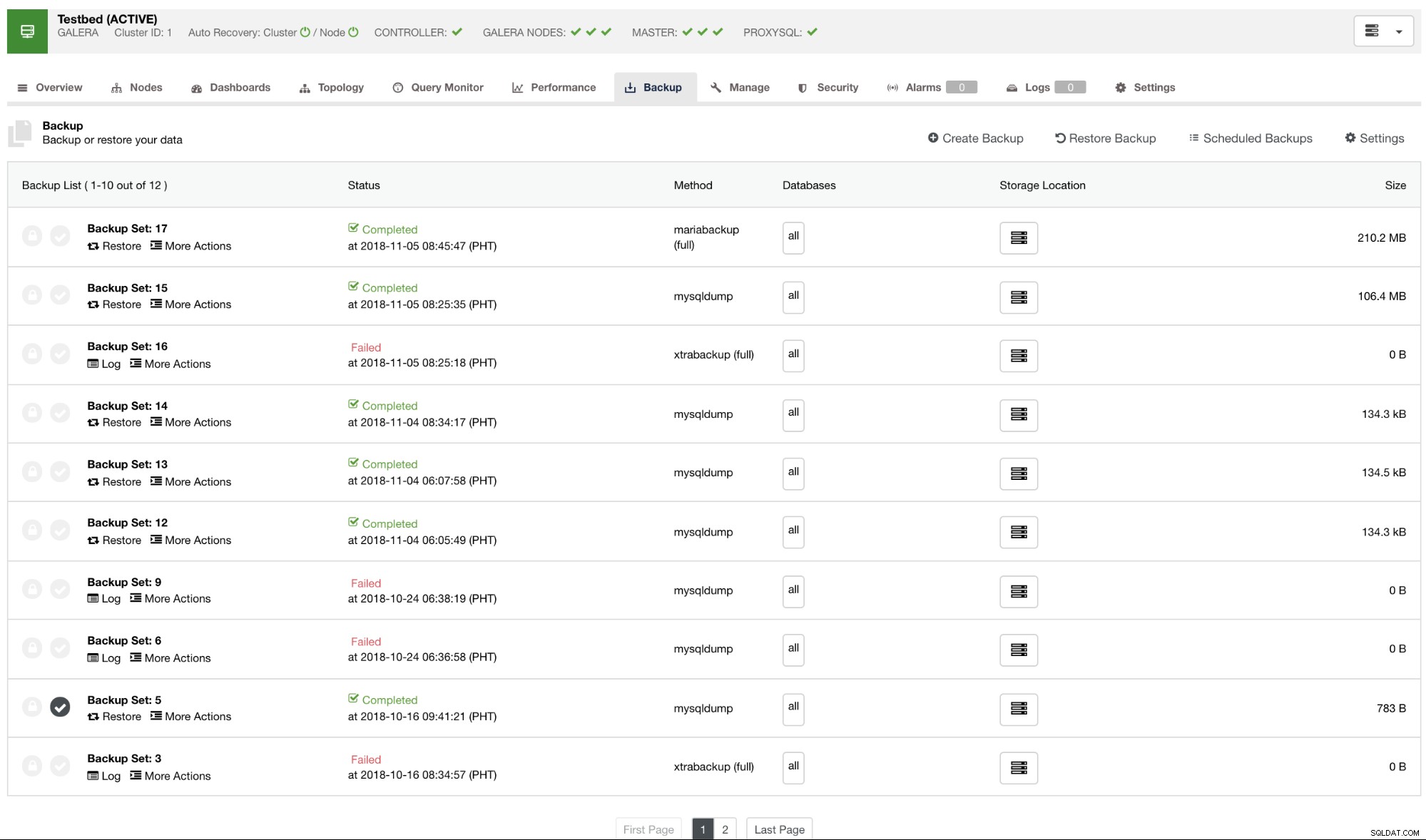
U kunt de lijst met back-uprapporten bekijken die zijn gemaakt of gepland met ClusterControl. Binnen de lijst kunt u de logboeken bekijken voor verder onderzoek en diagnose. Als de back-up bijvoorbeeld correct is voltooid volgens uw gewenste back-upbeleid, of compressie en codering correct zijn ingesteld, of als de gewenste back-upgegevensgrootte correct is. Dit is een goede manier om een snelle sanity check uit te voeren - als uw dataset ongeveer 1 GB groot is, kan een volledige back-up nooit zo klein zijn als 100 KB - er moet op een gegeven moment iets mis zijn gegaan.
Rampherstel
Het opslaan van back-ups binnen het cluster (direct op een databaseknooppunt of op de ClusterControl-host) is handig wanneer u uw gegevens snel wilt herstellen:alle back-upbestanden zijn aanwezig en kunnen snel worden gedecomprimeerd en hersteld. Als het gaat om Disaster Recovery (DR), is dit misschien niet de beste optie. Er kunnen verschillende problemen optreden:servers kunnen crashen, het netwerk werkt mogelijk niet betrouwbaar, zelfs volledige datacenters zijn mogelijk niet toegankelijk vanwege een soort storing. Het kan gebeuren of u nu werkt met een kleinere serviceprovider met één datacenter, of een wereldwijde leverancier zoals Amazon Web Services. Het is daarom niet veilig om al uw eieren in één mand te bewaren - u moet ervoor zorgen dat u een kopie van uw back-up op een externe locatie hebt opgeslagen. ClusterControl ondersteunt Amazon S3, Google Storage en Azure Cloud Storage.
Voor degenen die hun eigen DR-beleid willen implementeren, worden ClusterControl-back-ups opgeslagen in een mooi gestructureerde map. Je hebt ook de mogelijkheid om je back-up naar de cloud te uploaden. Zie onderstaande afbeelding:
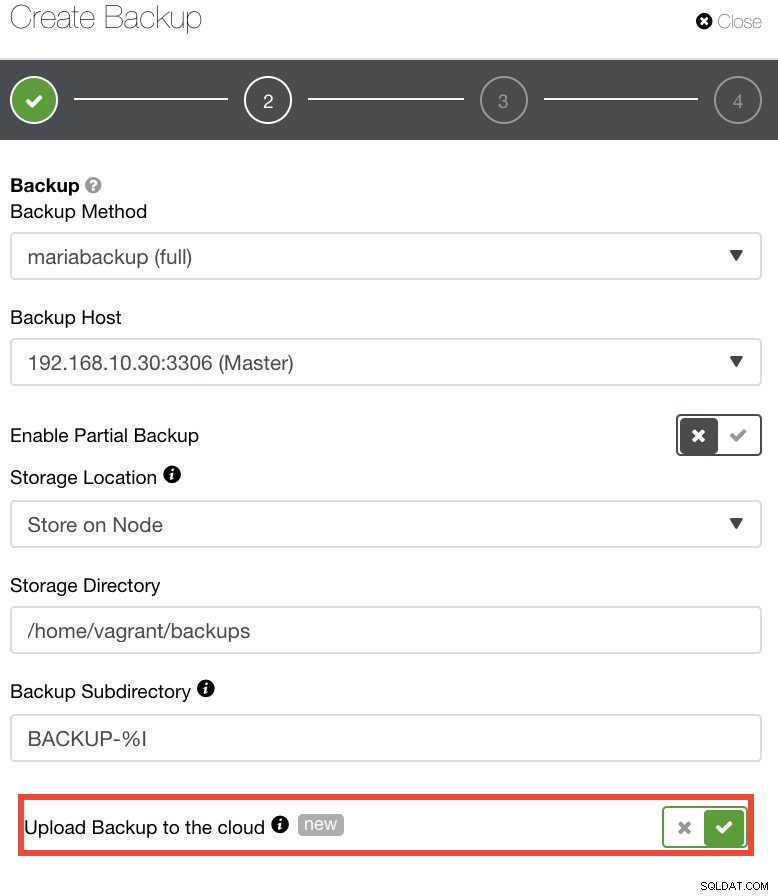
U kunt selecteren en uploaden naar Amazon Web Services, Google Cloud en Microsoft Azure. Zie onderstaande afbeelding:
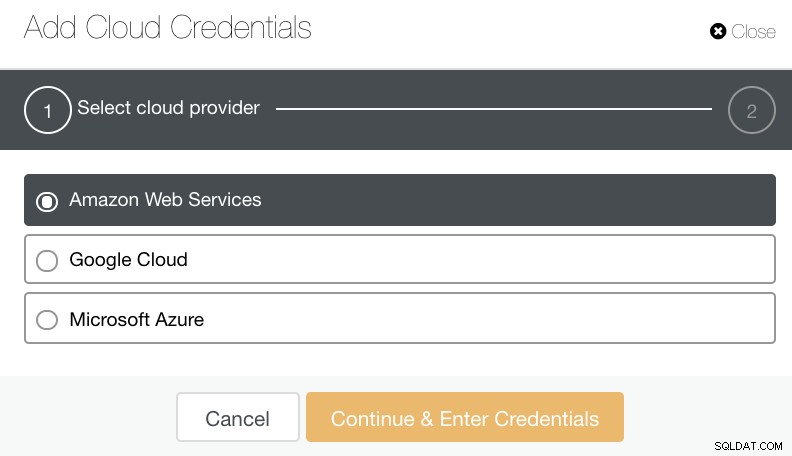
Als een goede gewoonte bij het archiveren van uw databaseback-ups, moet u ervoor zorgen dat uw doelcloudbestemming is gebaseerd op dezelfde regio als uw databaseservers, of in ieder geval de dichtstbijzijnde. Zorg ervoor dat het een hoge beschikbaarheid, duurzaamheid en schaalbaarheid biedt; aangezien u moet overwegen hoe vaak en onmiddellijk u uw gegevens nodig heeft.
Naast het maken van een logische of fysieke back-up voor uw DR, kan het maken van een volledige momentopname van uw gegevens (bijvoorbeeld met behulp van LVM Snapshot, Amazon EBS Snapshots of Volume Snapshots als u het Veritas-bestandssysteem gebruikt) op het specifieke knooppunt uw back-upherstel vergroten. U kunt ook WAL (voor Postgres) gebruiken voor uw Point In Time Recovery (PITR) of uw MySQL binaire logbestanden voor uw PITR. U moet er dus rekening mee houden dat u mogelijk uw eigen archivering voor uw PITR moet maken. Het is dus prima om uw eigen set scripts te bouwen en te implementeren en DR af te handelen volgens uw exacte vereisten.
Een andere geweldige manier om een Disaster Recovery-beleid te implementeren, is door een asynchrone replicatieslave te gebruiken - iets dat we eerder in deze blogpost noemden. Je kunt zo'n asynchrone slave op een externe locatie inzetten, misschien een ander datacenter, en het dan gebruiken om back-ups te maken en ze lokaal op die slave op te slaan. Natuurlijk wilt u een lokale back-up van uw cluster maken om deze lokaal bij de hand te hebben als u het cluster moet herstellen. Het verplaatsen van gegevens tussen datacenters kan lang duren, dus als u lokaal back-upbestanden beschikbaar hebt, kunt u wat tijd besparen. In het geval dat u de toegang tot uw hoofdproductiecluster verliest, heeft u mogelijk nog steeds toegang tot de slave. Deze setup is zeer flexibel - ten eerste heb je een draaiende MySQL-host met je productiegegevens, dus het zou niet al te moeilijk moeten zijn om je volledige applicatie op de DR-site te implementeren. U hebt ook back-ups van uw productiegegevens die u kunt gebruiken om uw DR-omgeving uit te schalen.
Ten slotte en vooral, een back-up die niet is getest, blijft een niet-geverifieerde back-up, ook wel Schroedinger-back-up genoemd. Om er zeker van te zijn dat je een werkende back-up hebt, moet je een hersteltest uitvoeren. ClusterControl biedt een manier om uw back-up automatisch te verifiëren en te testen.
We hopen dat dit u voldoende informatie geeft om een veilige en betrouwbare back-upprocedure te bouwen voor uw open source databases.