Onderhoud is iets waar een operatieteam niet omheen kan. Servers moeten gelijke tred houden met de nieuwste software, hardware en technologie om ervoor te zorgen dat systemen stabiel zijn en werken met het laagst mogelijke risico, terwijl ze gebruikmaken van nieuwere functies om de algehele prestaties te verbeteren.
Er is ongetwijfeld een lange lijst met onderhoudstaken die door systeembeheerders moeten worden uitgevoerd, vooral als het gaat om kritieke systemen. Sommige taken moeten met regelmatige tussenpozen worden uitgevoerd, zoals dagelijks, wekelijks, maandelijks en jaarlijks. Sommige moeten meteen worden gedaan, dringend. Desalniettemin mag elke onderhoudsoperatie niet leiden tot een ander groter probleem, en elk onderhoud moet met extra zorg worden uitgevoerd om elke onderbreking van het bedrijf te voorkomen.
Het krijgen van een twijfelachtige status en valse alarmen is gebruikelijk terwijl onderhoud aan de gang is. Dit is te verwachten omdat de server tijdens de onderhoudsperiode niet naar behoren zal werken totdat de onderhoudstaak is voltooid. ClusterControl, het allesomvattende beheer- en monitoringplatform voor uw open-sourcedatabases, kan worden geconfigureerd om deze omstandigheden te begrijpen om uw onderhoudsroutines te vereenvoudigen, zonder concessies te doen aan de monitoring- en automatiseringsfuncties die het biedt.
Onderhoudsmodus
ClusterControl introduceerde de onderhoudsmodus in versie 1.4.0, waar u een individuele node in onderhoud kunt plaatsen, waardoor ClusterControl geen alarm kan slaan en meldingen kan verzenden voor de opgegeven duur. De onderhoudsmodus kan worden geconfigureerd vanuit de gebruikersinterface van ClusterControl en ook met de ClusterControl CLI-tool genaamd "s9s". Ga vanuit de gebruikersinterface naar Nodes -> kies een node -> Node-acties -> Onderhoudsmodus plannen :
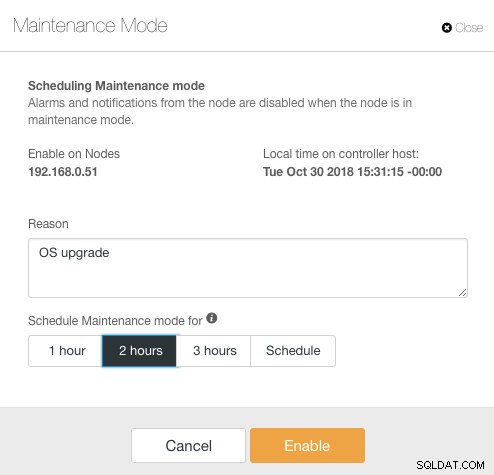
Hier kan men de onderhoudsperiode voor een vooraf gedefinieerde tijd instellen of dienovereenkomstig plannen. U kunt ook de reden voor het plannen van de upgrade opschrijven, handig voor controledoeleinden. U zou de volgende melding moeten zien wanneer de onderhoudsmodus actief is:
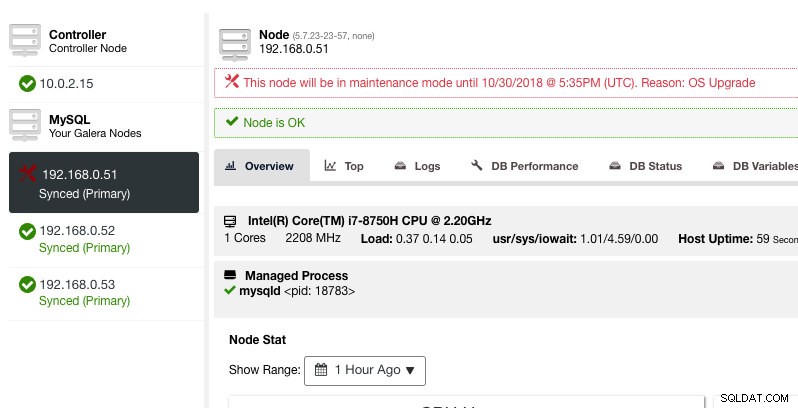
ClusterControl zal het knooppunt niet degraderen, daarom blijft de status van het knooppunt zoals het is, tenzij u een actie uitvoert die de status wijzigt. Alarmen en meldingen voor dit knooppunt worden opnieuw geactiveerd zodra de onderhoudsperiode voorbij is, of de operator schakelt het expliciet uit door naar Knooppuntacties -> Onderhoudsmodus uitschakelen te gaan .
Houd er rekening mee dat als automatisch herstel van knooppunten is ingeschakeld, ClusterControl altijd een knooppunt herstelt, ongeacht de status van de onderhoudsmodus. Vergeet niet om het herstel van knooppunten uit te schakelen om te voorkomen dat ClusterControl uw onderhoudstaken verstoort, dit kan worden gedaan vanaf de bovenste overzichtsbalk.
De onderhoudsmodus kan ook worden geconfigureerd via ClusterControl CLI of "s9s". U kunt de opdracht "s9s maintenance" gebruiken om de onderhoudsperioden op te sommen en te manipuleren. De volgende opdrachtregel plant morgen een onderhoudsvenster van één uur voor node 192.168.1.121:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Zie de s9s-onderhoudsdocumentatie voor meer details en voorbeelden.
Clusterbrede onderhoudsmodus
Op het moment van schrijven moet de configuratie van de onderhoudsmodus per beheerd knooppunt worden geconfigureerd. Voor clusterbreed onderhoud moet men het planningsproces herhalen voor elk beheerd knooppunt van het cluster. Dit kan onpraktisch zijn als u een groot aantal nodes in uw cluster heeft, of als het onderhoudsinterval tussen twee taken erg kort is.
Gelukkig kan ClusterControl CLI (ook bekend als s9s) worden gebruikt als een tijdelijke oplossing om deze beperking te omzeilen. U kunt 's9s-knooppunten' gebruiken om de beheerde knooppunten in een cluster weer te geven en te manipuleren. Deze lijst kan worden herhaald om op een bepaald moment een clusterbrede onderhoudsmodus te plannen met de opdracht "s9s maintenance".
Laten we een voorbeeld bekijken om dit beter te begrijpen. Beschouw de volgende Percona XtraDB-cluster met drie knooppunten die we hebben:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Het cluster heeft in totaal 4 knooppunten - 3 databaseknooppunten met één ClusterControl-knooppunt. De eerste kolom, STAT, toont de rol en status van het knooppunt. Het eerste teken is de rol van het knooppunt - "c" betekent controller en "g" betekent Galera-databaseknooppunt. Stel dat we alleen de databaseknooppunten willen plannen voor onderhoud, dan kunnen we de uitvoer eruit filteren om de hostnaam of het IP-adres te krijgen waar de gerapporteerde STAT "g" heeft aan het begin:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Met een eenvoudige iteratie kunnen we vervolgens een clusterbreed onderhoudsvenster plannen voor elk knooppunt in het cluster. De volgende opdracht herhaalt het maken van het onderhoud op basis van alle IP-adressen die in het cluster zijn gevonden met behulp van een for-lus, waarbij we van plan zijn de onderhoudsbewerking morgen op dezelfde tijd te starten en een uur later af te ronden:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bU zou een afdruk van 3 UUID's moeten zien, de unieke tekenreeks die elke onderhoudsperiode identificeert. We kunnen dan verifiëren met het volgende commando:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Uit de bovenstaande uitvoer hebben we een lijst met geplande onderhoudstijden voor elk databaseknooppunt. Gedurende de geplande tijd zal ClusterControl geen alarm afgeven of een melding sturen als het onregelmatigheden aan het cluster vindt.
Iteratie onderhoudsmodus
Sommige onderhoudsroutines moeten met regelmatige tussenpozen worden uitgevoerd, bijvoorbeeld back-ups, huishoudelijke taken en opruimtaken. Tijdens de onderhoudstijd verwachten we dat de server zich anders gedraagt. Elke servicestoring, tijdelijke ontoegankelijkheid of hoge belasting zou echter zeker schade toebrengen aan ons monitoringsysteem. Voor frequente en korte onderhoudsintervallen kan dit erg vervelend blijken te zijn en het overslaan van de gegenereerde valse alarmen kan u 's nachts een betere nachtrust geven.
Het inschakelen van de onderhoudsmodus kan de server echter ook blootstellen aan een groter risico, aangezien strikte controle gedurende een bepaalde periode wordt genegeerd. Daarom is het waarschijnlijk een goed idee om de aard van de onderhoudsbewerking die we willen uitvoeren te begrijpen voordat u de onderhoudsmodus inschakelt. De volgende checklist zou ons moeten helpen bij het bepalen van ons onderhoudsmodusbeleid:
- Getroffen knooppunten - Welke knooppunten zijn betrokken bij het onderhoud?
- Consequenties - Wat gebeurt er met het knooppunt wanneer de onderhoudsbewerking aan de gang is? Zal het ontoegankelijk, hoogbelast of opnieuw opgestart zijn?
- Duur - Hoeveel tijd kost het om de onderhoudsoperatie te voltooien?
- Frequentie - Hoe vaak moet het onderhoud worden uitgevoerd?
Laten we het in een use-case stoppen. Overweeg dat we een Percona XtraDB-cluster met drie knooppunten hebben met een ClusterControl-knooppunt. Stel dat onze servers allemaal op virtuele machines draaien en het back-upbeleid voor VM's vereist dat er elke dag vanaf 01:00 uur een back-up van alle VM's wordt gemaakt, één knooppunt per keer. Tijdens deze back-upbewerking wordt het knooppunt maximaal ongeveer 10 minuten bevroren en is het knooppunt dat wordt beheerd en bewaakt door ClusterControl niet toegankelijk totdat de back-up is voltooid. Vanuit het perspectief van Galera Cluster brengt deze operatie niet het hele cluster naar beneden, aangezien het cluster in quorum blijft en de primaire component niet wordt beïnvloed.
Op basis van de aard van de onderhoudstaak kunnen we deze als volgt samenvatten:
- Getroffen knooppunten - Alle knooppunten voor cluster-ID 1 (3 databaseknooppunten en 1 ClusterControl-knooppunt).
- Gevolg - De VM waarvan een back-up wordt gemaakt, is niet toegankelijk totdat deze is voltooid.
- Duur:elke VM-back-upbewerking duurt ongeveer 5 tot 10 minuten.
- Frequentie - De VM-back-up is gepland om dagelijks te worden uitgevoerd, vanaf 01:00 uur op het eerste knooppunt.
We kunnen dan met een uitvoeringsplan komen om onze onderhoudsmodus in te plannen:
Aangezien we willen dat alle knooppunten in het cluster worden geback-upt door de VM-manager, geeft u eenvoudig de knooppunten op voor de bijbehorende cluster-ID:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53De bovenstaande output kan worden gebruikt om onderhoud over het hele cluster te plannen. Als u bijvoorbeeld de volgende opdracht uitvoert, activeert ClusterControl de onderhoudsmodus voor alle knooppunten onder cluster-ID 1 vanaf nu tot de volgende 50 minuten:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneMet behulp van de bovenstaande opdracht kunnen we het converteren naar een uitvoeringsbestand door het in een script te plaatsen. Maak een bestand:
$ vim /usr/local/bin/enable_maintenance_modeEn voeg de volgende regels toe:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneSla het op en zorg ervoor dat de bestandsrechten uitvoerbaar zijn:
$ chmod 755 /usr/local/bin/enable_maintenance_modeGebruik vervolgens cron om te plannen dat het script dagelijks om 5 minuten tot 01:00 uur wordt uitgevoerd, net voordat de VM-back-up begint om 01:00 uur:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeLaad de cron-daemon opnieuw om ervoor te zorgen dat ons script in de wachtrij wordt geplaatst:
$ systemctl reload crond # or service crond reloadDat is het. We kunnen nu onze dagelijkse onderhoudswerkzaamheden uitvoeren zonder lastiggevallen te worden door valse alarmen en e-mailmeldingen totdat het onderhoud is voltooid.
Bonusonderhoudsfunctie - Knooppuntherstel overslaan
Als automatisch herstel is ingeschakeld, is ClusterControl slim genoeg om een storing van een knooppunt te detecteren en zal het proberen een defect knooppunt te herstellen na een respijtperiode van 30 seconden, ongeacht de status van de onderhoudsmodus. Wist u dat ClusterControl kan worden geconfigureerd om knooppuntherstel voor een bepaald knooppunt opzettelijk over te slaan? Dit kan erg handig zijn wanneer u een dringend onderhoud moet uitvoeren zonder de tijdspanne en het resultaat van het onderhoud te kennen.
Stel je bijvoorbeeld voor dat er een beschadiging van het bestandssysteem is opgetreden en dat controle en reparatie van het bestandssysteem vereist zijn na een harde herstart. Het is moeilijk om van tevoren te bepalen hoeveel tijd het zou kosten om deze bewerking uit te voeren. We kunnen dus eenvoudig een vlagbestand gebruiken om ClusterControl aan te geven het herstel voor het knooppunt over te slaan.
Voeg eerst de volgende regel toe in /etc/cmon.d/cmon_X.cnf (waarbij X de cluster-ID is) op het ClusterControl-knooppunt:
node_recovery_lock_file=/root/do_not_recoverStart dan de cmon-service opnieuw om de wijziging te laden:
$ systemctl restart cmon # service cmon restartZorg er ten slotte voor dat het opgegeven bestand aanwezig is op het knooppunt dat we willen overslaan voor ClusterControl-herstel:
$ touch /root/do_not_recoverOngeacht de status van de automatische herstel- en onderhoudsmodus, herstelt ClusterControl het knooppunt alleen als dit vlagbestand niet bestaat. De beheerder is dan verantwoordelijk voor het maken en verwijderen van het bestand op het databaseknooppunt.
Dat is het, mensen. Veel plezier met onderhoud!