In de vorige twee blogposts hebben we zowel de implementatie van de vier typen clustering/replicatie (MySQL/Galera, MySQL-replicatie, MongoDB &PostgreSQL) als het beheren/monitoren van uw bestaande databases en clusters behandeld. Dus na het lezen van deze twee eerste blogposts was je in staat om je 20 bestaande replicatie-instellingen toe te voegen aan ClusterControl, ze uit te breiden en bovendien twee nieuwe Galera-clusters te implementeren terwijl je een heleboel andere dingen deed. Of misschien hebt u MongoDB- en/of PostgreSQL-systemen geïmplementeerd. Dus hoe houd je ze nu gezond?
Dat is precies waar deze blogpost over gaat:hoe u de prestatiebewaking en adviseursfunctionaliteit van ClusterControl kunt gebruiken om uw MySQL-, MongoDB- en/of PostgreSQL-databases en clusters gezond te houden. Dus hoe wordt dit gedaan in ClusterControl?
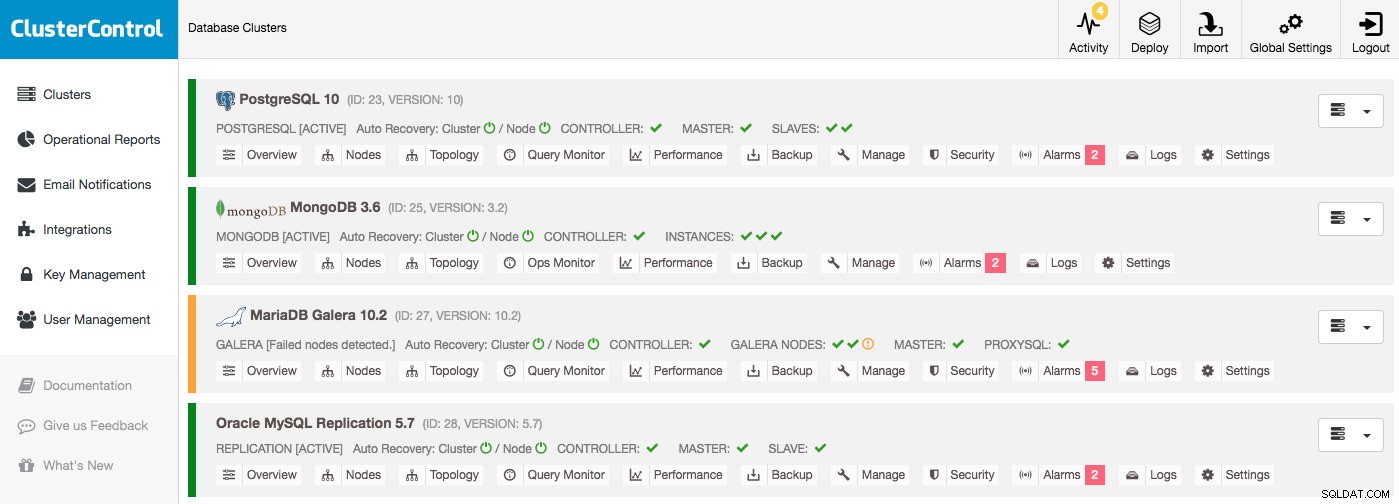
Databaseclusterlijst
De belangrijkste informatie is al te vinden in de clusterlijst:zolang er geen alarmen zijn en er geen hosts worden weergegeven als down, functioneert alles prima. Er wordt alarm geslagen als aan een bepaalde voorwaarde wordt voldaan, b.v. host is aan het wisselen en brengt het probleem onder uw aandacht dat u moet onderzoeken. Dat betekent dat er niet alleen alarm wordt geslagen tijdens een storing, maar ook dat u uw databases proactief kunt beheren.
Stel dat je zou inloggen op ClusterControl en een clusterlijst als deze zou zien, dan heb je zeker iets te onderzoeken:er is bijvoorbeeld een node in het Galera-cluster en elk cluster heeft verschillende alarmen:
Zodra u op een van de alarmen klikt, gaat u naar een gedetailleerde pagina over alle alarmen van het cluster. De alarmdetails verklaren het probleem en geven in de meeste gevallen ook advies over de actie om het probleem op te lossen.
U kunt uw eigen alarmen instellen door aangepaste expressies te maken, maar dat is afgeschaft ten gunste van onze nieuwe Developer Studio, waarmee u aangepaste Javascripts kunt schrijven en deze als adviseurs kunt uitvoeren. We komen later in dit bericht terug op dit onderwerp.
Clusteroverzicht - Dashboards
Bij het openen van het clusteroverzicht zien we in de tabbladen direct de belangrijkste performance metrics voor het cluster. Dit overzicht kan per clustertype verschillen, aangezien Galera bijvoorbeeld andere prestatiestatistieken heeft om naar te kijken dan traditionele MySQL, PostgreSQL of MongoDB.
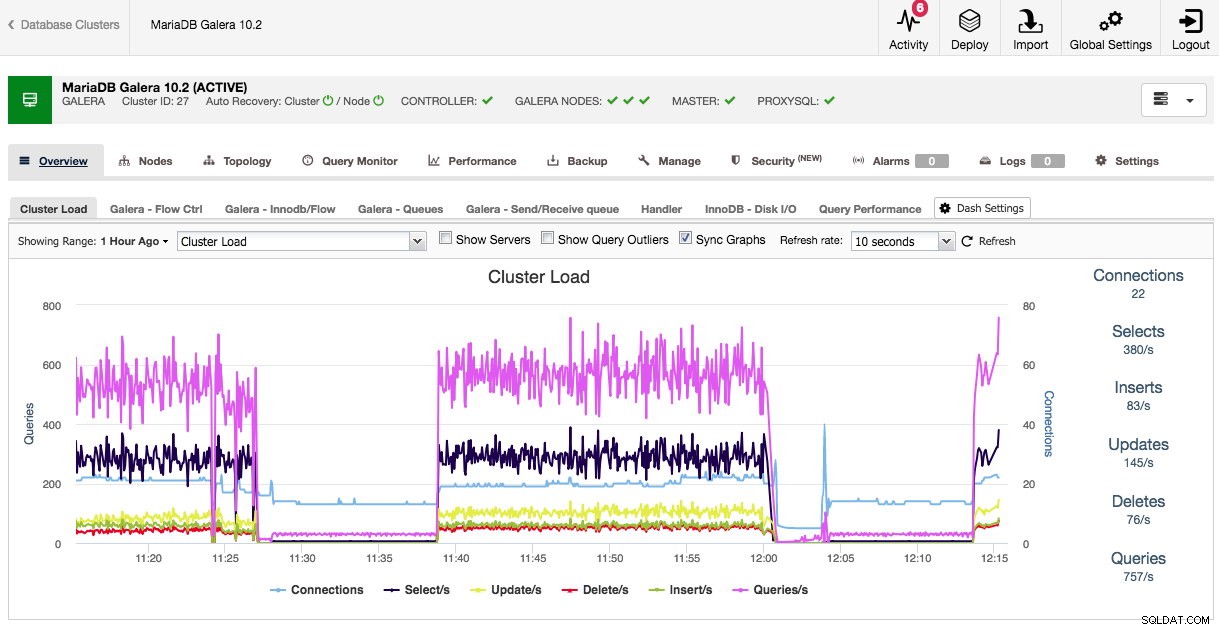
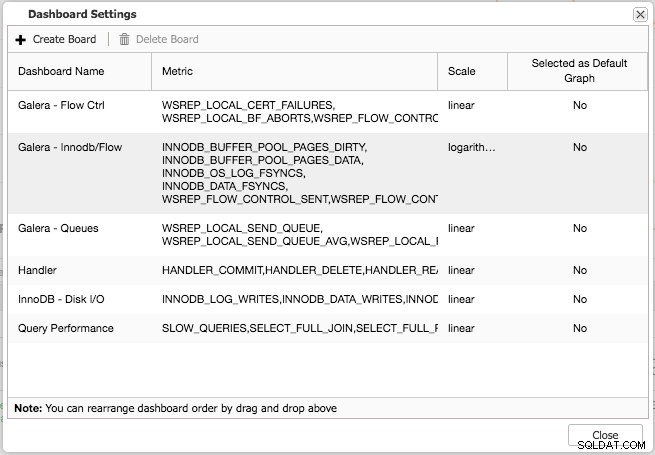
Zowel het standaardoverzicht als de vooraf geselecteerde tabbladen zijn aanpasbaar. Door te klikken op Overzicht -> Dash-instellingen u krijgt een dialoog waarin u het dashboard kunt definiëren:
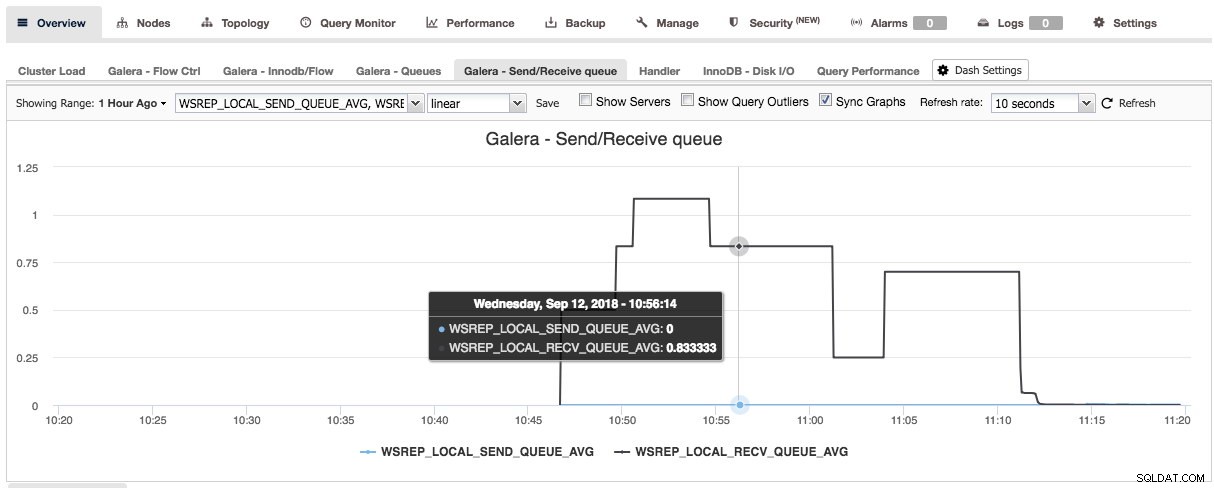
Door op het plusteken te drukken, kunt u uw eigen statistieken toevoegen en definiëren om het dashboard in een grafiek uit te zetten. In ons geval zullen we een nieuw dashboard definiëren met het Galera-specifieke wachtrijgemiddelde voor verzenden en ontvangen:
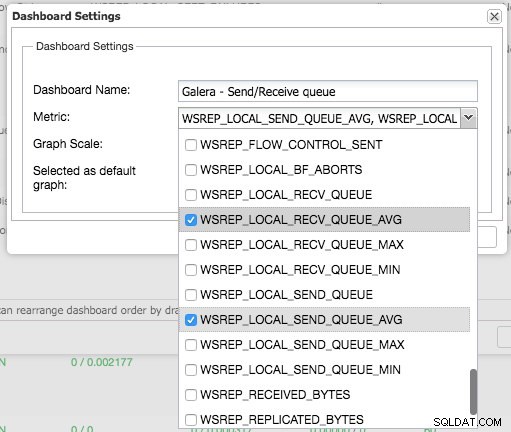
Dit nieuwe dashboard moet ons goed inzicht geven in de gemiddelde wachtrijlengte van ons Galera-cluster.
Nadat u op opslaan heeft gedrukt, wordt het nieuwe dashboard beschikbaar voor dit cluster:
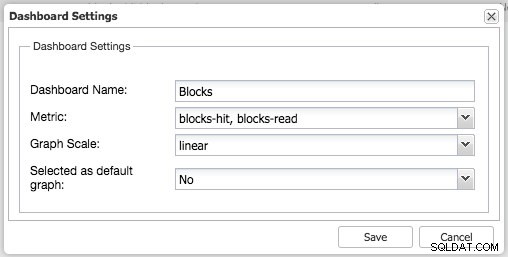
Op dezelfde manier kunt u dit ook voor PostgreSQL doen, we kunnen bijvoorbeeld de gedeelde blokken volgen die worden geraakt versus gelezen blokken:
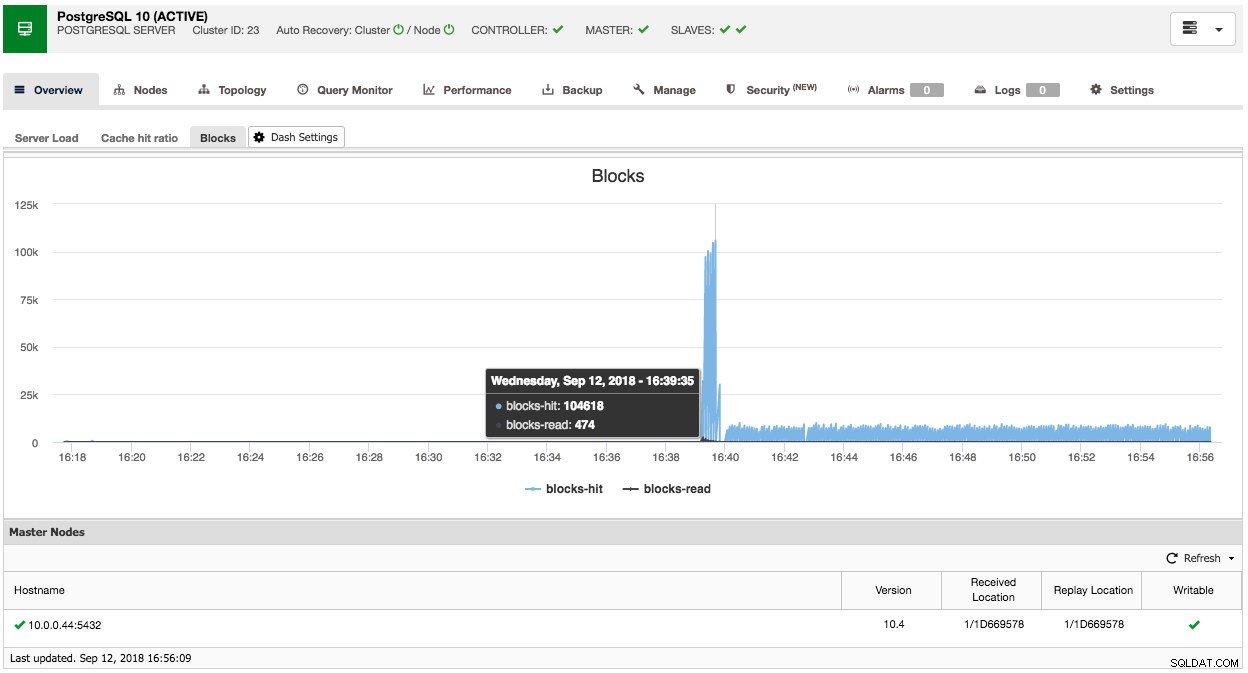
Zoals je kunt zien, is het relatief eenvoudig om je eigen (standaard) dashboard aan te passen.
Clusteroverzicht - Querymonitor
Het tabblad Query Monitor is beschikbaar voor zowel MySQL- als PostgreSQL-gebaseerde setups en bestaat uit drie dashboards:Top Queries, Running Queries en Query Outliers.
In het dashboard Lopende query's vindt u alle huidige query's die worden uitgevoerd. Dit is in feite het equivalent van de instructie SHOW FULL PROCESSLIST in de MySQL-database.
Topquery's en Query-uitbijters zijn beide afhankelijk van de invoer van het trage querylogboek of het prestatieschema. Het gebruik van Prestatieschema wordt altijd aanbevolen en zal automatisch worden gebruikt indien ingeschakeld. Anders gebruikt ClusterControl het MySQL-log met trage query's om de actieve query's vast te leggen. Om te voorkomen dat ClusterControl te opdringerig wordt en het logbestand met trage query's te groot wordt, zal ClusterControl een steekproef nemen van het log met trage query's door het in en uit te schakelen. Deze lus is standaard ingesteld op 1 seconde vastleggen en de long_query_time is ingesteld op 0,5 seconden. Als u deze instellingen voor uw cluster wilt wijzigen, kunt u dit wijzigen via Instellingen -> Query Monitor .
Topquery's zullen, zoals de naam al zegt, de topquery's tonen die zijn gesampled. Je kunt ze sorteren op verschillende kolommen:bijvoorbeeld de frequentie, gemiddelde uitvoeringstijd, totale uitvoeringstijd of standaarddeviatietijd:
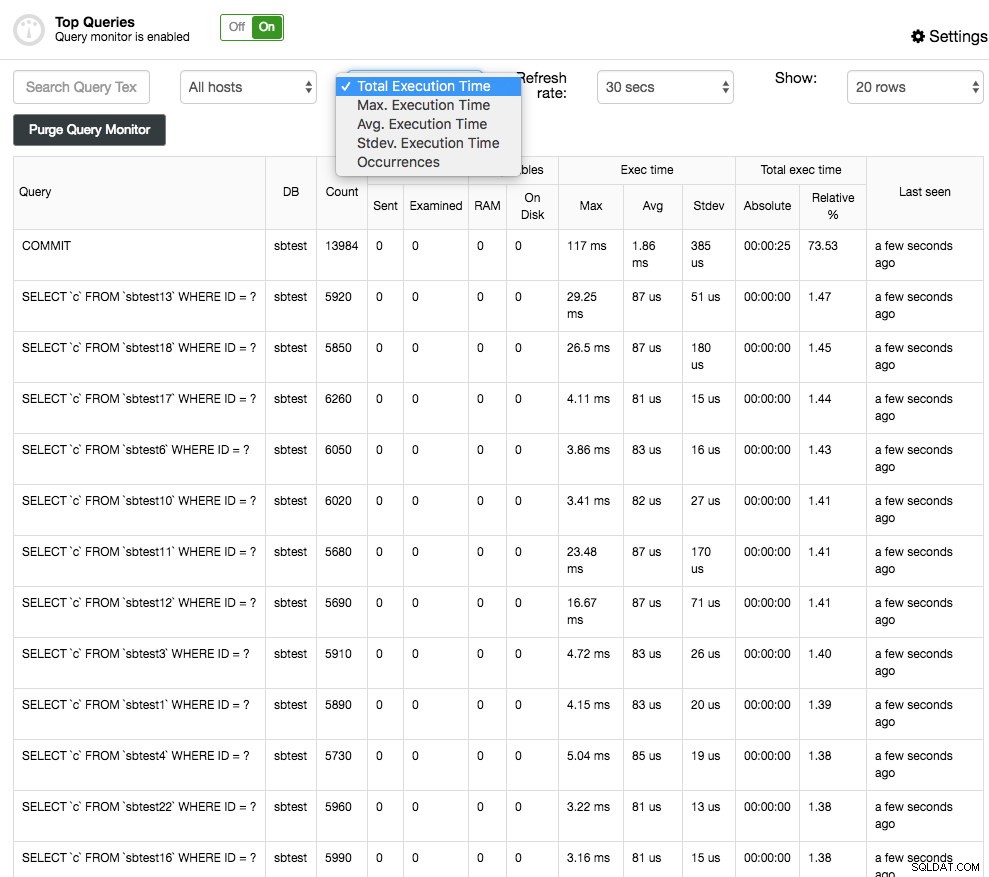
U kunt meer details over de query krijgen door deze te selecteren en dit geeft het uitvoeringsplan voor de query (indien beschikbaar) en optimalisatiehints/adviezen weer. De Query Outliers zijn vergelijkbaar met de Top Queries, maar dan kun je de zoekopdrachten per host filteren en op tijd vergelijken.
Clusteroverzicht - Bewerkingen
Net als de PostgreSQL- en MySQL-systemen hebben de MongoDB-clusters het Operations-overzicht en zijn ze vergelijkbaar met de Running Queries van MySQL. Dit overzicht is vergelijkbaar met het geven van de opdracht db.currentOp() binnen MongoDB.
Clusteroverzicht - Prestaties
MySQL/Galera
Het prestatietabblad is waarschijnlijk de beste plaats om de algehele prestaties en status van uw clusters te vinden. Voor MySQL en Galera bestaat het uit een Overzichtspagina, de Adviseurs, status/variabelenoverzichten, de Schema Analyzer en het Transactielogboek.
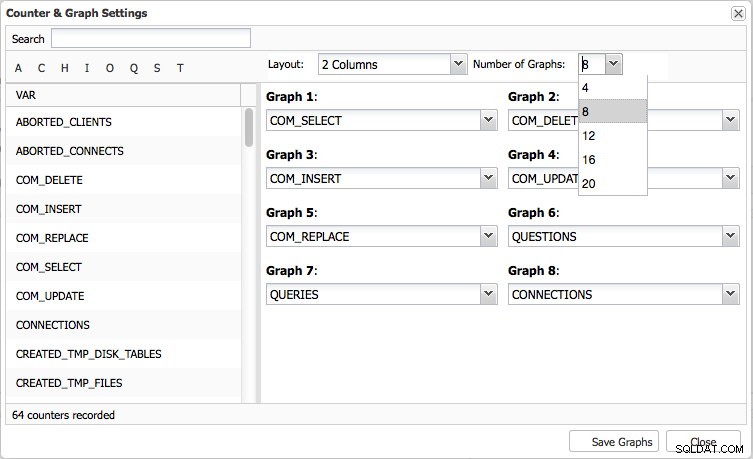
De overzichtspagina geeft u een grafisch overzicht van de belangrijkste metrische gegevens in uw cluster. Dit verschilt uiteraard per clustertype. Er zijn standaard acht statistieken ingesteld, maar u kunt eenvoudig uw eigen statistieken instellen - tot 20 grafieken indien nodig:
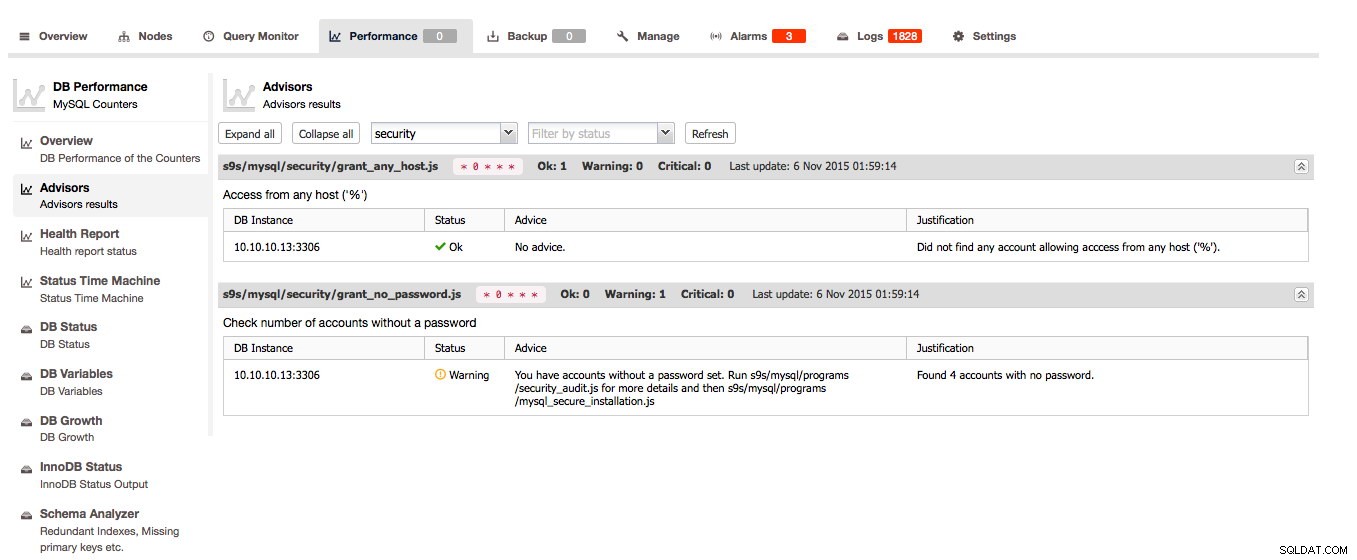
De Advisors is een van de belangrijkste kenmerken van ClusterControl:de Advisors zijn gescripte controles die op aanvraag kunnen worden uitgevoerd. De adviseurs kunnen bijna elk bekend feit over de host en/of cluster evalueren en hun mening geven over de gezondheid van de host en/of cluster en kunnen zelfs advies geven over het oplossen van problemen of het verbeteren van uw hosts!
Het beste moet nog komen:u kunt uw eigen controles maken in de Developer Studio (ClusterControl -> Beheren -> Developer Studio ), voer ze regelmatig uit en gebruik ze opnieuw in de sectie Adviseurs. We hebben eerder dit jaar over deze nieuwe functie geblogd.
We zullen het status-/variabelenoverzicht van MySQL en Galera overslaan, omdat dit nuttig is als referentie, maar niet voor deze blogpost:het is goed genoeg dat u weet dat het hier is.
Stel nu dat uw database groeit, maar u wilt weten hoe snel deze de afgelopen week is gegroeid. U kunt de groei van zowel gegevens als indexgroottes rechtstreeks vanuit ClusterControl volgen:
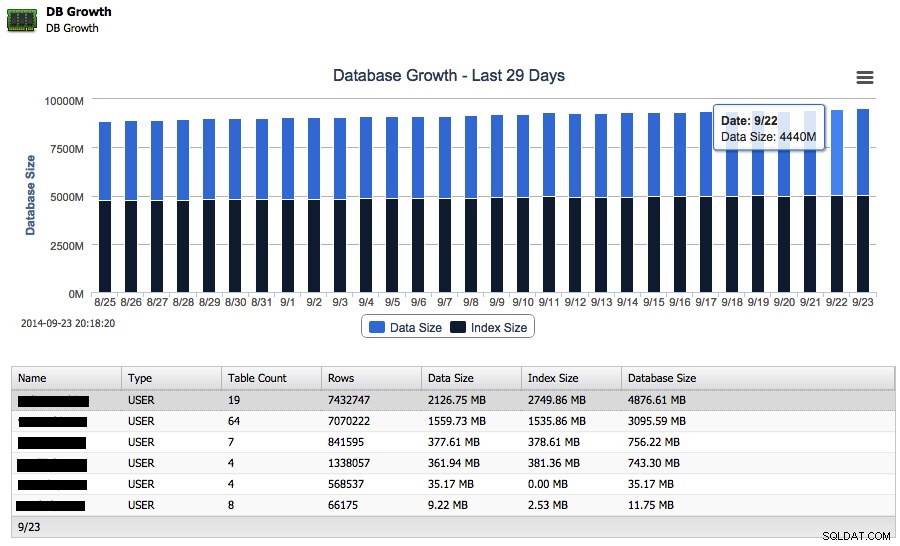
En naast de totale groei op schijf kan het ook de top 25 grootste schema's rapporteren.
Een ander belangrijk kenmerk is de Schema Analyzer binnen ClusterControl:
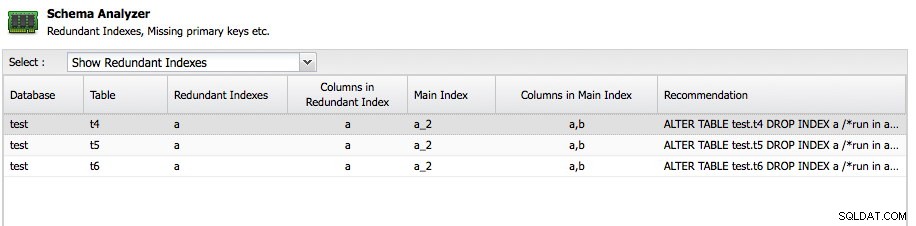
ClusterControl analyseert uw schema's en zoekt naar redundante indexen, MyISAM-tabellen en tabellen zonder primaire sleutel. Natuurlijk is het geheel aan jou om een tabel zonder primaire sleutel bij te houden, omdat een of andere applicatie het op deze manier heeft gemaakt, maar het is in ieder geval geweldig om het advies hier gratis te krijgen. De Schema Analyzer beveelt zelfs de noodzakelijke ALTER-instructie aan om het probleem op te lossen.
PostgreSQL
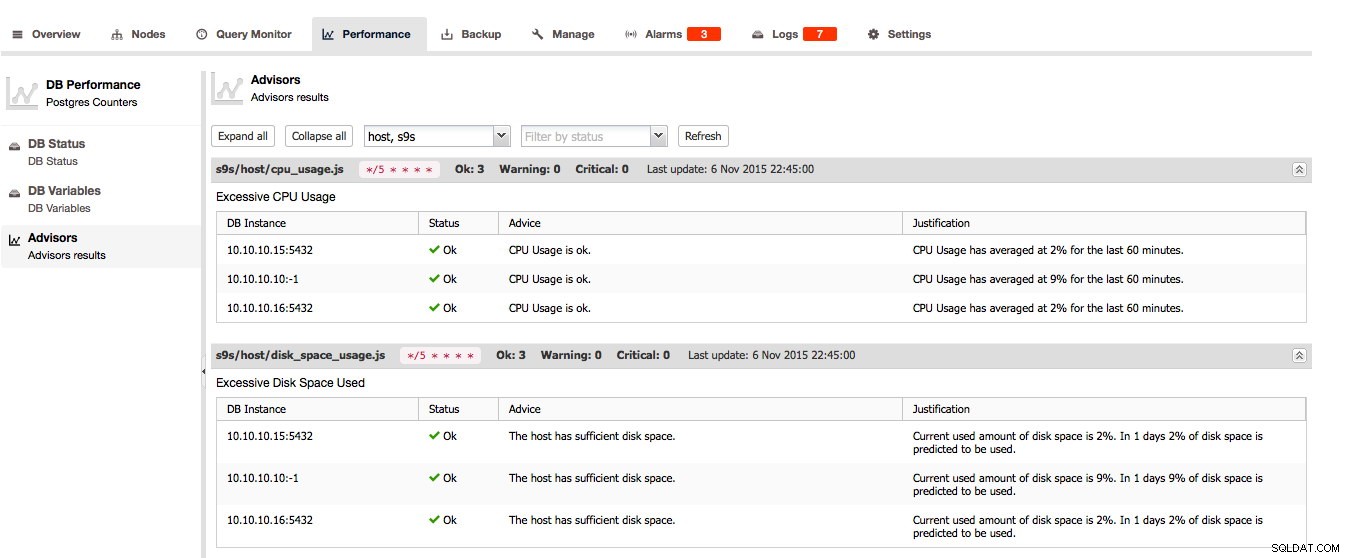
Voor PostgreSQL zijn de Advisors, DB Status en DB Variables hier te vinden:
MongoDB
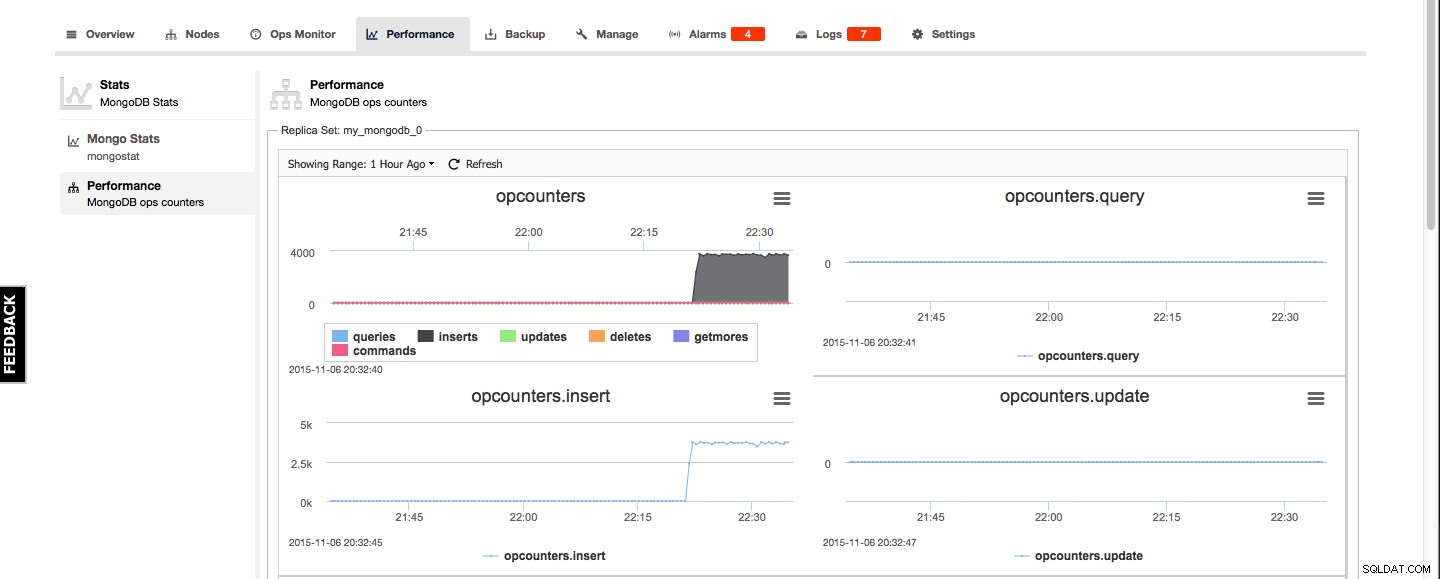
Voor MongoDB zijn de Mongo-statistieken en het prestatieoverzicht te vinden onder het tabblad Prestaties. De Mongo-statistieken is een overzicht van de output van mongostat en het prestatieoverzicht geeft een goed grafisch overzicht van de MongoDB-opcounters:
Laatste gedachten
We hebben u laten zien hoe u uw oog kunt houden op de belangrijkste functies voor monitoring en gezondheidscontrole van ClusterControl. Uiteraard is dit slechts het begin van de reis, aangezien we binnenkort een nieuwe blogreeks zullen starten over de mogelijkheden van Developer Studio en hoe u de meeste van uw eigen controles kunt uitvoeren. Houd er ook rekening mee dat onze ondersteuning voor MongoDB en PostgreSQL niet zo uitgebreid is als onze MySQL-toolset, maar we verbeteren dit continu.
U vraagt zich misschien af waarom we de performance monitoring en health checks van HAProxy, ProxySQL en MaxScale hebben overgeslagen. Dat hebben we bewust gedaan, aangezien de blogserie tot nu toe alleen de inzet van clusters omvatte en niet de inzet van HA-componenten. Dus dat is het onderwerp dat we de volgende keer zullen behandelen.