Databasesystemen zijn cruciale componenten in de cyclus van elke succesvol draaiende applicatie. Elke organisatie waarbij ze betrokken zijn, heeft daarom het mandaat om te zorgen voor soepele prestaties van deze DBM's door middel van consistente monitoring en het afhandelen van kleine tegenslagen voordat ze escaleren tot enorme complicaties die kunnen leiden tot uitvaltijd van applicaties of trage prestaties.
U kunt zich afvragen hoe u kunt zien of de database echt een probleem zal hebben terwijl deze normaal werkt? Welnu, dat is wat we in dit artikel gaan bespreken en we noemen het benchmarking. Benchmarking is in feite het uitvoeren van een reeks query's met enkele testgegevens en enige bronvoorziening om te bepalen of deze parameters voldoen aan het verwachte prestatieniveau.
MongoDB heeft geen standaard benchmarking-methodologie, daarom moeten we oplossen bij het testen van vragen op eigen hardware. Hoezeer u ook indrukwekkende cijfers haalt uit het benchmarkproces, u moet voorzichtig zijn, aangezien dit een ander geval kan zijn wanneer u uw database uitvoert met echte query's.
Het idee achter benchmarking is om een algemeen idee te krijgen van hoe verschillende configuratie-opties de prestaties beïnvloeden, hoe je sommige van deze configuraties kunt aanpassen om maximale prestaties te krijgen en om een schatting te maken van de kosten van het verbeteren van deze implementatie. Bovendien groeien applicaties met de tijd in termen van gebruikers en waarschijnlijk de hoeveelheid gegevens die moet worden bediend, dus moet vóór die tijd wat capaciteitsplanning worden uitgevoerd. Nadat u een stijgende trend van gegevens heeft gerealiseerd, moet u een aantal benchmarks uitvoeren om te bepalen hoe u aan de vereisten van deze enorm groeiende gegevens kunt voldoen.
Overwegingen bij het benchmarken van MongoDB
- Selecteer workloads die typisch zijn voor de moderne applicaties van vandaag. Moderne applicaties worden met de dag complexer en dit wordt doorgegeven aan de datastructuren. Dit wil zeggen dat de gegevenspresentatie in de loop van de tijd ook is veranderd, bijvoorbeeld door eenvoudige velden op te slaan in objecten en arrays. Het is niet zo eenvoudig om met deze gegevens te werken met standaard of liever ondermaatse databaseconfiguraties, omdat dit kan escaleren tot problemen zoals slechte latentie en slechte doorvoerbewerkingen met betrekking tot de complexe gegevens. Wanneer u een benchmark uitvoert, moet u daarom gegevens gebruiken die een duidelijke presentatie van uw toepassing zijn.
- Dubbele controle op schrijfacties. Zorg er altijd voor dat het schrijven van alle gegevens zo is uitgevoerd dat er geen gegevens verloren gaan. Dit is bedoeld om de gegevensintegriteit te verbeteren door ervoor te zorgen dat de gegevens consistent zijn en het meest van toepassing zijn, vooral in de productieomgeving.
- Gebruik datavolumes die een representatie zijn van "big data" datasets die zeker de RAM-capaciteit voor een individueel knooppunt zullen overschrijden. Wanneer de testwerkbelasting groot is, kunt u hiermee toekomstige verwachtingen van uw databaseprestaties voorspellen en daarom vroeg genoeg beginnen met capaciteitsplanning.
Methodologie
Onze benchmarktest omvat enkele grote locatiegegevens die hier kunnen worden gedownload en we zullen Robo3t-software gebruiken om onze gegevens te manipuleren en de informatie te verzamelen die we nodig hebben. Het bestand heeft meer dan 500 documenten die voldoende zijn voor onze test. We gebruiken MongoDB versie 4.0 op een Ubuntu Linux 12.04 Intel Xeon-SandyBridge E3-1270-Quadcore 3.4GHz dedicated server met 32GB RAM, Western Digital WD Caviar RE4 1TB draaiende schijf en Smart XceedIOPS 256GB SSD. We hebben de eerste 500 documenten ingevoegd.
We hebben de onderstaande invoegopdrachten uitgevoerd
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:0})
db.getCollection('location').insertMany([<document1, <document2>…<document500>],{w:1})Bezorgdheid schrijven
Schrijfzorg beschrijft het door MongoDB gevraagde bevestigingsniveau voor schrijfbewerkingen in dit geval naar een zelfstandige MongoDB. Voor een bewerking met hoge doorvoer, als deze waarde is ingesteld op laag, zullen de schrijfaanroepen zo snel zijn, waardoor de latentie van het verzoek wordt verminderd. Aan de andere kant, als de waarde hoog is ingesteld, zijn de schrijfaanroepen traag en nemen daardoor de latentie van de query toe. Een eenvoudige verklaring hiervoor is dat wanneer de waarde laag is, u zich geen zorgen hoeft te maken over de mogelijkheid om sommige schrijfacties te verliezen in het geval van een mongod-crash, netwerkfout of anonieme systeemstoring. Een beperking in dit geval is dat u niet zeker weet of deze schrijfacties succesvol waren. Aan de andere kant, als de schrijfzorg groot is, is er een foutafhandelingsprompt en dus zullen de schrijfacties worden bevestigd. Een bevestiging is gewoon een ontvangstbewijs dat de server het schrijven heeft geaccepteerd om te verwerken.
 Als de schrijfzorg groot is
Als de schrijfzorg groot is  Als de zorg voor schrijven laag is ingesteld
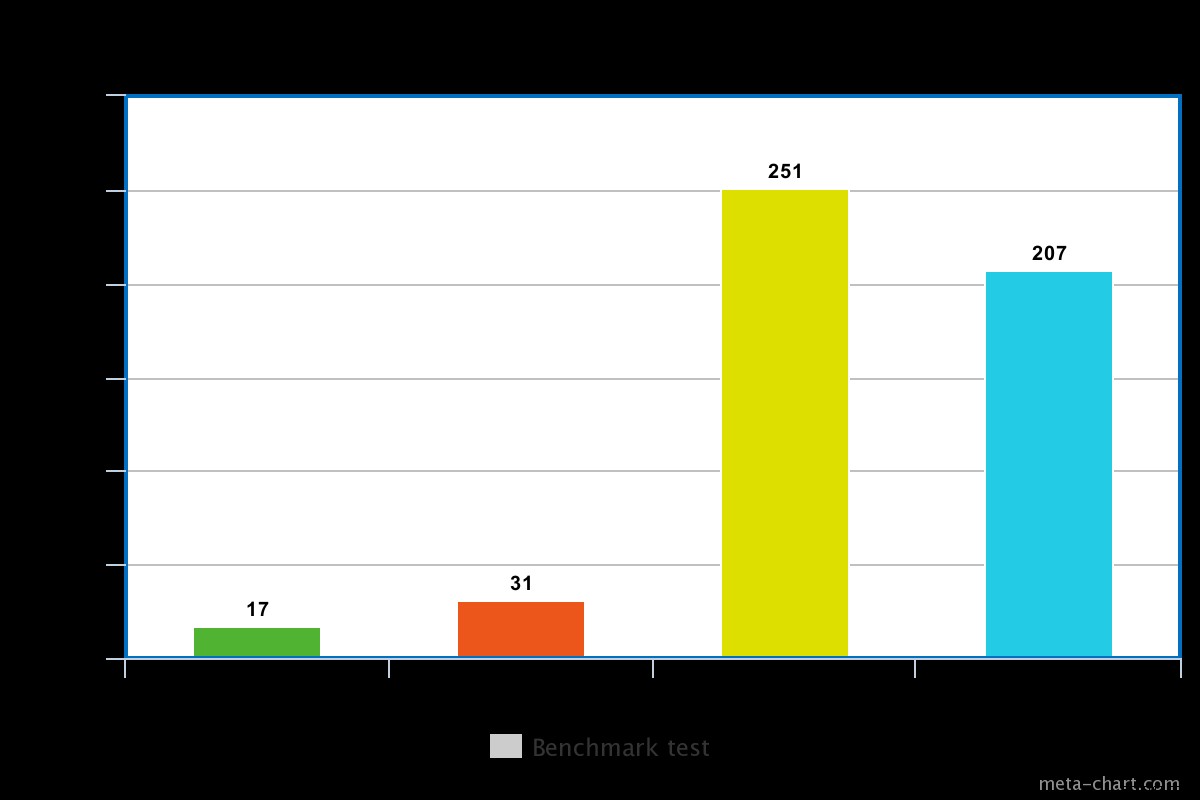
Als de zorg voor schrijven laag is ingesteld In onze test resulteerde de schrijfzorg die op laag was ingesteld erin dat de query werd uitgevoerd in min van 0,013 ms en max van 0,017 ms. In dit geval is de basisbevestiging van schrijven uitgeschakeld, maar u kunt nog steeds informatie krijgen over socketuitzonderingen en eventuele netwerkfouten die mogelijk zijn geactiveerd.
Wanneer de schrijfzorg hoog is ingesteld, duurt het bijna twee keer zo lang om terug te keren met een uitvoeringstijd van 0,027 ms min en 0,031 ms max. De bevestiging is in dit geval gegarandeerd, maar niet 100% dat het schijfjournaal heeft bereikt. In dit geval is de kans op schrijfverlies dus 50% vanwege het 100 ms-venster waarin het journaal mogelijk niet naar de schijf wordt leeggemaakt.
Journaling
Dit is een techniek om ervoor te zorgen dat er geen gegevens verloren gaan door duurzaamheid te bieden in geval van storing. Dit wordt bereikt door een vooruitschrijvende logging naar on-disk journaalbestanden. Het is het meest efficiënt wanneer de schrijfzorg hoog is ingesteld.
Voor een draaiende schijf is de uitvoeringstijd met journaal ingeschakeld een beetje hoog, bijvoorbeeld in onze test was het ongeveer 0,251 ms voor dezelfde bewerking hierboven.

De uitvoeringstijd voor een SSD is echter iets lager voor hetzelfde commando. In onze test was het ongeveer 0,207 ms, maar afhankelijk van de aard van de gegevens kan dit soms 3 keer sneller zijn dan een draaiende schijf.

Wanneer journaling is ingeschakeld, bevestigt het dat er naar het journaal is geschreven en zorgt zo voor duurzaamheid van de gegevens. Bijgevolg zal de schrijfoperatie een Mongod-shutdown overleven en ervoor zorgen dat de schrijfoperatie duurzaam is.
Voor een bewerking met hoge doorvoer kunt u de querytijden halveren door w=0 in te stellen. Anders moet u, als u er zeker van wilt zijn dat de gegevens zijn vastgelegd, of beter gezegd zullen zijn in het geval van een herstel na een storing, de w=1 instellen.
 Verschillende soorten Word een MongoDB DBA - MongoDB naar productie brengenLeer over wat u moet weten om te implementeren, bewaken, beheren en schaal MongoDBGratis downloaden
Verschillende soorten Word een MongoDB DBA - MongoDB naar productie brengenLeer over wat u moet weten om te implementeren, bewaken, beheren en schaal MongoDBGratis downloaden Replicatie
Erkenning van een schrijfprobleem kan worden ingeschakeld voor meer dan één knooppunt dat het primaire en een aantal secundaire binnen een replicaset is. Dit wordt gekenmerkt door welk geheel getal wordt gewaardeerd aan de schrijfparameter. Als w =3 bijvoorbeeld, moet Mongod ervoor zorgen dat de query een bevestiging ontvangt van het hoofdknooppunt en 2 slaves. Als u een waarde groter dan één probeert in te stellen en het knooppunt is nog niet gerepliceerd, geeft het een foutmelding dat de host moet worden gerepliceerd.
Replicatie gaat gepaard met een vertraging van de latentie, zodat de uitvoeringstijd wordt verlengd. Voor de eenvoudige query hierboven, als w=3, neemt de gemiddelde uitvoeringstijd toe tot 270 ms. Een drijvende factor hiervoor is het bereik in responstijd tussen knooppunten die worden beïnvloed door netwerklatentie, communicatie-overhead tussen de 3 knooppunten en congestie. Bovendien wachten alle drie de knooppunten tot elkaar klaar zijn voordat ze het resultaat retourneren. Bij een productie-implementatie hoef je dus niet zoveel nodes te betrekken als je de performance wilt verbeteren. MongoDB is verantwoordelijk voor het selecteren van welke knooppunten moeten worden bevestigd, tenzij er een specificatie in het configuratiebestand is met behulp van tags.
Spinning Disk vs Solid State Disk
Zoals hierboven vermeld, is SSD-schijf vrij snel dan draaiende schijf, afhankelijk van de betrokken gegevens. Soms kan het 3 keer sneller zijn, dus het is het waard om voor te betalen als dat nodig is. Het zal echter duurder zijn om een SSD te gebruiken, vooral als het om enorme gegevens gaat. MongoDB heeft de verdienste dat het het opslaan van databases in mappen ondersteunt die kunnen worden aangekoppeld, vandaar een kans om een SSD te gebruiken. Het gebruik van een SSD en het inschakelen van journaling is een geweldige optimalisatie.
Conclusie
Het experiment was er zeker van dat een schrijfprobleem dat is uitgeschakeld resulteert in een kortere uitvoeringstijd van een query ten koste van de kans op gegevensverlies. Aan de andere kant, wanneer de schrijfzorg is ingeschakeld, is de uitvoeringstijd bijna 2 keer wanneer deze is uitgeschakeld, maar er is een zekerheid dat gegevens niet verloren gaan. Bovendien kunnen we rechtvaardigen dat SSD sneller is dan een draaiende schijf. Om de duurzaamheid van de gegevens te garanderen in het geval van een systeemstoring, is het echter raadzaam om het schrijfprobleem in te schakelen. Wanneer u de schrijfzorg voor een replicaset inschakelt, moet u het aantal niet te groot instellen, zodat dit kan leiden tot verslechterde prestaties vanaf het einde van de toepassing.