Productstoringen zullen vrijwel zeker op een gegeven moment optreden. Als u dit feit accepteert en de tijdlijn en het faalscenario van uw databasestoring analyseert, kunt u zich beter voorbereiden, diagnosticeren en herstellen van de volgende. Om de impact van downtime te beperken, hebben organisaties een geschikt noodherstelplan (DR) nodig. DR-planning is een kritieke taak voor veel SysOps/DevOps, maar ook al is het voorzien; vaak bestaat het niet.
In deze blogpost analyseren we verschillende back-up- en storingsscenario's in MongoDB-databasesystemen. We zullen u ook door de herstel- en failover-procedures voor elk respectievelijk scenario leiden. Deze gebruiksscenario's variëren van het herstellen van een enkel knooppunt, het herstellen van een knooppunt in een bestaande replicaSet en het zaaien van een nieuw knooppunt in een replicaSet. Hopelijk geeft dit u een goed begrip van de risico's waarmee u te maken kunt krijgen en waarmee u rekening moet houden bij het ontwerpen van uw infrastructuur.
Laten we, voordat we mogelijke storingsscenario's gaan bespreken, eens kijken hoe MongoDB gegevens opslaat en welke soorten back-up beschikbaar zijn.
Hoe MongoDB gegevens opslaat
MongoDB is een documentgeoriënteerde database. In plaats van uw gegevens op te slaan in tabellen die zijn gemaakt van afzonderlijke rijen (zoals een relationele database doet), slaat het gegevens op in verzamelingen die zijn gemaakt van afzonderlijke documenten. In MongoDB is een document een grote JSON-blob zonder een bepaald formaat of schema. Bovendien kunnen gegevens worden verspreid over verschillende clusterknooppunten met delen of worden gerepliceerd naar slaveservers met replicaSet.
MongoDB zorgt standaard voor zeer snelle schrijf- en updates. Het nadeel is dat u vaak niet expliciet op de hoogte wordt gesteld van storingen. Standaard doen de meeste stuurprogramma's asynchrone, onveilige schrijfbewerkingen. Dit betekent dat het stuurprogramma niet direct een fout retourneert, vergelijkbaar met INSERT DELAYED met MySQL. Als je wilt weten of iets is gelukt, moet je handmatig controleren op fouten met getLastError.
Voor optimale prestaties verdient het de voorkeur om SSD in plaats van HDD te gebruiken voor opslag. Het is noodzakelijk om ervoor te zorgen dat uw opslag lokaal of op afstand is en dienovereenkomstig maatregelen te nemen. Het is beter om RAID te gebruiken voor de bescherming van hardwaredefecten en herstelschema's, maar vertrouw er niet volledig op omdat het geen bescherming biedt tegen nadelige storingen. De juiste hardware is de bouwsteen voor uw applicatie om de prestaties te optimaliseren en een groot debacle te voorkomen.
Beschadiging van gegevens op schijfniveau of ontbrekende gegevensbestanden kunnen ertoe leiden dat mongod-instanties niet starten, en journaalbestanden kunnen onvoldoende zijn om automatisch te herstellen.
Als je werkt met journaling ingeschakeld, is het bijna nooit nodig om een reparatie uit te voeren, aangezien de server de journaalbestanden kan gebruiken om de gegevensbestanden automatisch in een schone staat te herstellen. Het is echter mogelijk dat u nog steeds een reparatie moet uitvoeren in gevallen waarin u gegevenscorruptie op schijfniveau moet herstellen.
Als het bijhouden van een dagboek niet is ingeschakeld, is de enige optie mogelijk het uitvoeren van een reparatieopdracht. mongod --repair mag alleen worden gebruikt als u geen andere opties heeft, aangezien de bewerking eventuele corrupte gegevens verwijdert (en niet opslaat) tijdens het reparatieproces. Dit type bewerking moet altijd worden voorafgegaan door een back-up.
MongoDB-noodherstelscenario
In een herstelplan voor storingen is uw Recovery Point Objective (RPO) een belangrijke herstelparameter die bepaalt hoeveel gegevens u zich kunt veroorloven te verliezen. RPO wordt weergegeven in tijd, van milliseconden tot dagen en is direct afhankelijk van uw back-upsysteem. Het houdt rekening met de ouderdom van uw back-upgegevens die u moet herstellen om de normale werking te hervatten.
Om de RPO te schatten, moet je jezelf een paar vragen stellen. Wanneer wordt er een back-up van mijn gegevens gemaakt? Wat is de SLA die is gekoppeld aan het ophalen van de gegevens? Is het terugzetten van een back-up van de gegevens acceptabel of moeten de gegevens online zijn en op elk moment kunnen worden opgevraagd?
Antwoorden op deze vragen helpen u bepalen welk type back-upoplossing u nodig heeft.
MongoDB-back-upoplossingen
Back-uptechnieken hebben verschillende effecten op de prestaties van de actieve database. Sommige back-upoplossingen verslechteren de databaseprestaties zodanig dat u mogelijk back-ups moet plannen om piekgebruik of onderhoudsperiodes te voorkomen. U kunt besluiten om nieuwe secundaire servers in te zetten, alleen om back-ups te ondersteunen.
De drie meest voorkomende oplossingen om een back-up te maken van uw MongoDB-server/cluster zijn...
- Mongodump/Mongorestore - logische back-up.
- Mongo Management System (Cloud) - Van productiedatabases kan een back-up worden gemaakt met MongoDB Ops Manager of als u de MongoDB Atlas-service gebruikt, kunt u een volledig beheerde back-upoplossing gebruiken.
- Snapshots van database (back-up op schijfniveau)
Mongodump/Mongorestore
Bij het uitvoeren van een mongodump worden alle collecties binnen de aangewezen databases gedumpt als BSON-uitvoer. Als er geen database is opgegeven, dumpt MongoDB alle databases, behalve de admin-, test- en lokale databases, aangezien deze zijn gereserveerd voor intern gebruik.
Standaard zal mongodump een map maken met de naam dump, met een map voor elke database die een BSON-bestand per verzameling in die database bevat. Als alternatief kunt u mongodump vertellen om de back-up op te slaan in één enkel archiefbestand. De archiefparameter voegt de uitvoer van alle databases en verzamelingen samen tot één enkele stroom binaire gegevens. Bovendien kan de gzip-parameter dit archief natuurlijk comprimeren met behulp van gzip. In ClusterControl streamen we al onze back-ups, dus we schakelen zowel de archive- als de gzip-parameters in.
Vergelijkbaar met mysqldump met MySQL, als u een back-up maakt in MongoDB, worden de verzamelingen bevroren en wordt de inhoud naar het back-upbestand gedumpt. Aangezien MongoDB geen transacties ondersteunt (gewijzigd in 4.2), kunt u geen 100% volledig consistente back-up maken, tenzij u de back-up maakt met de parameter oplog. Dit inschakelen op de back-up omvat de transacties van de oplog die werden uitgevoerd tijdens het maken van de back-up.
Voor betere automatisering en U kunt MongoDB uitvoeren vanaf de opdrachtregel of externe tools gebruiken zoals ClusterControl. ClusterControl is een aanbevolen optie voor back-upbeheer en back-upautomatisering, omdat het geavanceerde back-upstrategieën voor verschillende open-source databasesystemen mogelijk maakt.
ClusterControl stelt u in staat uw back-up naar de cloud te uploaden. Het ondersteunt volledige back-up en herstelt de codering van mongodump. Als je wilt zien hoe het werkt, staat er een demo op onze website.
MongoDB herstellen vanaf een back-up
Er zijn in principe twee manieren waarop u een dump in BSON-indeling kunt gebruiken:
- Voer mongod rechtstreeks uit vanuit de back-upmap
- Voer mongorestore uit en herstel de back-up
Mongod rechtstreeks uitvoeren vanaf een back-up
Een vereiste voor het rechtstreeks uitvoeren van mongod vanuit de back-up is dat het back-updoel een standaarddump is en niet is gezipt.
De MongoDB-daemon controleert vervolgens de integriteit van de gegevensmap, voegt de beheerdersdatabase, tijdschriften, collectie- en indexcatalogi en enkele andere bestanden toe die nodig zijn om MongoDB uit te voeren. Als u eerder WiredTiger als opslagengine had uitgevoerd, zal het nu de bestaande collecties als MMAP uitvoeren. Voor eenvoudige gegevensdumps of integriteitscontroles werkt dit prima.
Mongorestore actief
Een betere manier om te herstellen zou natuurlijk zijn door het knooppunt te herstellen met behulp van een mongorestore.
mongorestore dump/Hiermee wordt de back-up teruggezet naar de standaard serverinstellingen (localhost, poort 27017) en worden alle databases in de back-up die zich op deze server bevinden, overschreven. Nu zijn er talloze parameters om het herstelproces te manipuleren, en we zullen enkele van de belangrijkste behandelen.
In ClusterControl wordt dit gedaan met de optie back-up terugzetten. U kunt de machine kiezen wanneer de back-up wordt hersteld en verwerken en voor de rest zorgen. Dit omvat een versleutelde back-up waar u normaal gesproken ook uw back-up zou moeten ontsleutelen.
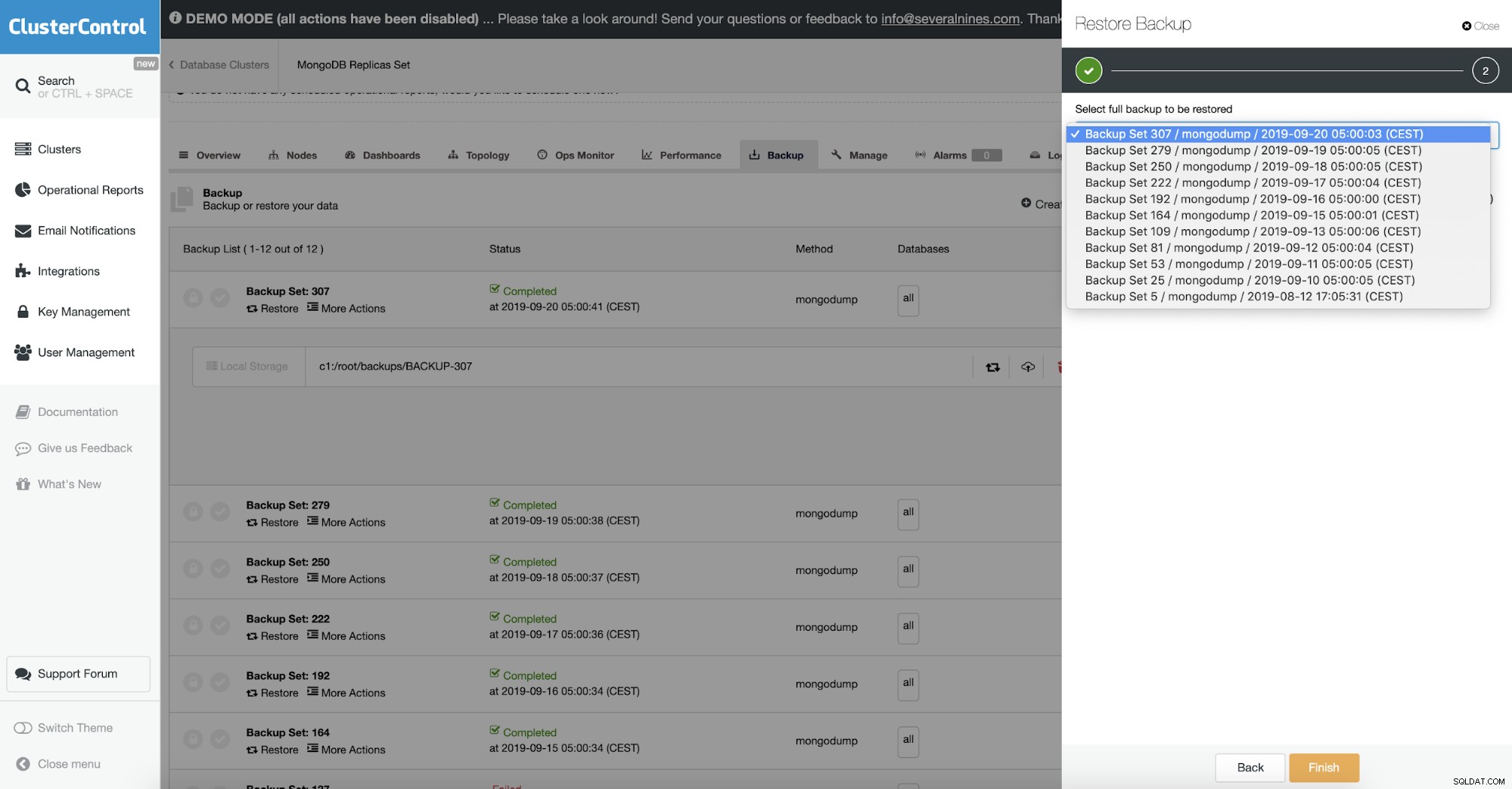
Objectvalidatie
Omdat de back-up BSON-gegevens bevat, zou je verwachten dat de inhoud van de back-up correct is. Het kan echter zo zijn geweest dat het document dat werd gedumpt, om te beginnen een verkeerde vorm had. Mongodump controleert de integriteit van de gegevens die het dumpt niet.
Om dat gebruik aan te pakken -- objcheck die mongorestore dwingt om alle verzoeken van klanten bij ontvangst te valideren om ervoor te zorgen dat klanten nooit ongeldige documenten in de database invoegen. Het kan een kleine impact hebben op de prestaties.
Oplog opnieuw afspelen
Oplog naar uw back-up stelt u in staat om een consistente back-up uit te voeren en een point-in-time-recovery uit te voeren. Schakel de parameter oplogReplay in om de oplog toe te passen tijdens het herstelproces. Om te bepalen hoe ver de oplog moet worden afgespeeld, kunt u een tijdstempel definiëren in de parameter oplogLimit. Alleen transacties tot het tijdstempel worden dan toegepast.
Een volledige replicaset herstellen vanaf een back-up
Het herstellen van een replicaSet is niet veel anders dan het herstellen van een enkel knooppunt. Ofwel moet u eerst de replicaSet instellen en direct herstellen in de replicaSet. Of u herstelt eerst een enkele node en gebruikt vervolgens deze herstelde node om een replicaSet te bouwen.
Herstel eerst het knooppunt en maak vervolgens replicaSet
Nu synchroniseren de tweede en derde node hun gegevens vanaf de eerste node. Nadat de synchronisatie is voltooid, is onze replicaSet hersteld.
Maak eerst een ReplicaSet en herstel dan
Anders dan bij het vorige proces, kunt u eerst de replicaSet maken. Configureer eerst alle drie de hosts met de replicaSet ingeschakeld, start alle drie de daemons op en start de replicaSet op het eerste knooppunt:
Nu we de replicaSet hebben gemaakt, kunnen we onze back-up er direct in herstellen:
Naar onze mening is het herstellen van een replicaSet op deze manier veel eleganter. Het komt dichter in de buurt van de manier waarop u normaal gesproken een nieuwe replicaSet vanaf het begin zou opzetten en deze vervolgens zou vullen met (productie)gegevens.
Een nieuw knooppunt in een ReplicaSet zaaien
Bij het uitschalen van een cluster door een nieuw knooppunt in MongoDB toe te voegen, moet de eerste synchronisatie van de dataset plaatsvinden. Met MySQL-replicatie en Galera zijn we zo gewend aan het gebruik van een back-up om de eerste synchronisatie te seeden. Met MongoDB is dit mogelijk, maar alleen door een binaire kopie van de datadirectory te maken. Als u niet over de middelen beschikt om een momentopname van het bestandssysteem te maken, zult u te maken krijgen met downtime op een van de bestaande knooppunten. Het proces, met downtime, wordt hieronder beschreven.
Seeding met een back-up
Dus wat zou er gebeuren als je in plaats daarvan het nieuwe knooppunt herstelt vanuit een mongodump-back-up en het vervolgens laat deelnemen aan een replicaSet? Terugzetten vanaf een back-up zou in theorie dezelfde dataset moeten opleveren. Omdat dit nieuwe knooppunt is hersteld vanaf een back-up, zal het de replicaSetId missen en MongoDB zal het merken. Omdat MongoDB dit knooppunt niet als onderdeel van de replicaSet ziet, zal de opdracht rs.add() altijd de initiële synchronisatie van MongoDB activeren. De eerste synchronisatie leidt altijd tot verwijdering van alle bestaande gegevens op het MongoDB-knooppunt.
De replicaSetId wordt gegenereerd bij het starten van een replicaSet en kan helaas niet handmatig worden ingesteld. Dat is jammer, want herstellen van een back-up (inclusief het opnieuw afspelen van de oplog) zou ons in theorie een 100% identieke dataset opleveren. Het zou leuk zijn als de initiële synchronisatie optioneel was in MongoDB om aan deze use case te voldoen.