Inleiding tot MongoDB
MongoDB werd in 2009 geïntroduceerd door een bedrijf met de naam 10gen. 10gen werd later omgedoopt tot MongoDB Inc., het bedrijf dat verantwoordelijk is voor de ontwikkeling van de software, en verkoopt de enterprise-versie van deze database. MongoDB Inc. verzorgt de hele dag door alle ondersteuning met zijn uitstekende ondersteuningsteam op ondernemingsniveau. Ze zetten zich in om levenslange ondersteuning te bieden, wat betekent dat klanten ervoor kiezen om elke versie van MongoDB te gebruiken, en als ze willen upgraden, wordt deze op elk moment ondersteund. Het biedt hen ook de mogelijkheid om op de hoogte te blijven van alle beveiligingsoplossingen die het bedrijf de klok rond aanbiedt.
MongoDB is een bekende NoSQL-database die de afgelopen tien jaar een enorme groei heeft doorgemaakt, aangewakkerd door de explosieve groei van het web en mobiele applicaties die in de cloud draaien. Deze nieuwe soort van internet-verbonden toepassingen vereist snelle, fouttolerante en schaalbare schemaloze gegevensopslag die NoSQL-databases kunnen bieden. MongoDB gebruikt JSON om gegevens zoals documenten op te slaan die kunnen variëren in structuuraanbiedingen, een dynamisch, flexibel schema. MongoDB ontworpen voor hoge beschikbaarheid en schaalbaarheid met auto-sharding. MongoDB is een van de populaire open-sourcedatabases die ontstaan onder de NoSQL-database, die wordt gebruikt voor gegevensopslag met grote volumes. MongoDB heeft de rijen die documenten worden genoemd en waarvoor geen schema hoeft te worden gedefinieerd, omdat de velden on-the-fly worden gemaakt. Het datamodel dat beschikbaar is binnen MongoDB maakt het mogelijk om hiërarchische relaties weer te geven, om arrays en andere meer complexe structuren efficiënter op te slaan.
Inleiding tot Cassandra
Apache Cassandra is een andere bekende gratis en open-source, gedistribueerde, brede kolomwinkel. Cassandra werd in 2008 geïntroduceerd door een aantal ontwikkelaars van Facebook, dat later werd uitgebracht als een open-sourceproject. Het wordt momenteel ondersteund door de Apache Software Foundation en Apache onderhoudt dit project momenteel voor eventuele verdere verbeteringen.
Cassandra is een NoSQL-databasebeheersysteem dat is ontworpen om grote hoeveelheden gegevens op veel basisservers te verwerken en een hoge beschikbaarheid te bieden zonder één storingspunt. Cassandra biedt zeer robuuste ondersteuning voor clusters die meerdere datacenters omspannen, met asynchrone masterless replicatie waardoor bewerkingen met lage latentie voor alle klanten mogelijk zijn. Cassandra ondersteunt het distributieontwerp van Amazon Dynamo met het datamodel van Google's Bigtable.
Overeenkomsten tussen MongoDB en Cassandra
Laten we bij de korte introductie van deze twee NoSQL-databases eens kijken naar enkele overeenkomsten tussen deze twee databases:
Zowel MongoDB als Cassandra zijn NoSQL-databasetypes en open-sourcedistributie.
- Geen van deze databases is een vervanging voor de traditionele RDBMS-databasetypes.
- Beide databases voldoen niet aan ACID (Atomicity, Consistency, Isolation, Durability), wat verwijst naar eigenschappen van databasetransacties die garanderen dat databasetransacties betrouwbaar worden verwerkt.
- Beide databases ondersteunen sharding horizontale partitionering.
- Consistentie en normalisatie zijn twee concepten waaraan deze twee databasetypen niet voldoen (omdat deze meer leunen op de RDBMS-databasetypen)
MongoDB vs. Cassandra:functies
Beide technologieën spelen een cruciale rol in hun vakgebied, met hun overeenkomsten tussen MongoDB en Cassandra die hun gemeenschappelijke kenmerken laten zien en verschillen laten het unieke karakter van deze technologieën zien.
 Figuur 1 MongoDB vs. Cassandra – 8 belangrijke factoren van verschil
Figuur 1 MongoDB vs. Cassandra – 8 belangrijke factoren van verschil Expressief gegevensmodel
MongoDB biedt een rijk en expressief datamodel dat bekend staat als 'object-georiënteerd' of 'data-georiënteerd'. Dit datamodel kan eenvoudig elke datastructuur in het domein van de gebruiker ondersteunen en representeren. De gegevens kunnen eigenschappen hebben en voor meerdere niveaus in elkaar genest zijn. Cassandra is meer een traditioneel gegevensmodel met een tabelstructuur, rijen en specifieke kolommen van het gegevenstype. Dit type wordt gedefinieerd tijdens het maken van de tabel. Hoe dan ook, wanneer we beide modellen vergelijken, heeft MongoDB de neiging om een rijk datamodel te bieden. De onderstaande afbeelding beschrijft de typische high-level architecturen van beide databases in termen van opslag- en replicatieniveaus.
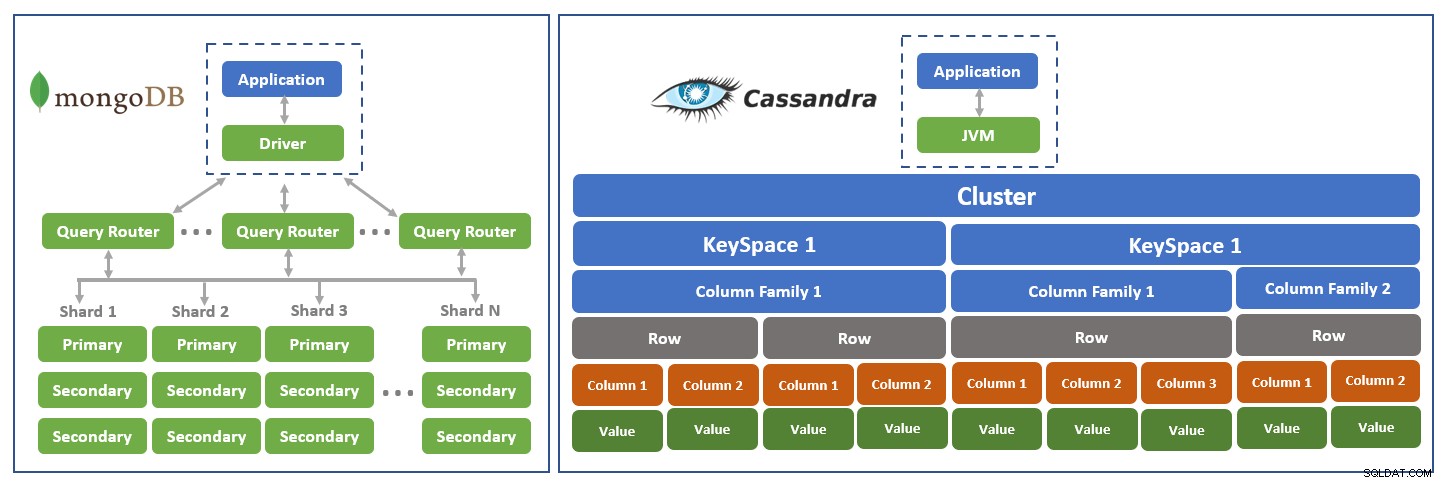 Figuur 2:Architectuurdiagram MongoDB vs. Cassandra
Figuur 2:Architectuurdiagram MongoDB vs. Cassandra Hoofdknooppunt met hoge beschikbaarheid
MongoDB ondersteunt één master-node in een cluster, die een set slave-nodes bestuurt. Als het masterknooppunt uitvalt, wordt een slave als master gekozen en duurt het ongeveer 20-30 seconden. Tijdens deze vertragingstijd is het cluster niet beschikbaar en kan het geen invoer accepteren. Cassandra ondersteunt meerdere masternodes in een cluster, en in het geval dat een van de masternodes offline gaat, wordt zijn plaats ingenomen door een andere masternode. Ter vergelijking:Cassandra ondersteunt een hogere beschikbaarheid via MongoDB omdat het geen invloed heeft op het cluster en altijd beschikbaar is.
Secundaire indexen
MongoDB heeft meer voordelen vergeleken met Cassandra als een applicatie secundaire indexen vereist, samen met flexibiliteit in het datamodel. Hierdoor is MongoDB veel gemakkelijker om elke eigenschap van de gegevens die in de database zijn opgeslagen te indexeren. Deze eigenschap maakt het gemakkelijk om te zoeken. Cassandra heeft cursorondersteuning voor de secundaire indexen, die beperkt zijn tot enkele kolommen en gelijkheidsvergelijkingen
Schrijfschaalbaarheid
MongoDB ondersteunt slechts één hoofdknooppunt. Dit hoofdknooppunt in MongoDB accepteert alleen de invoer en de rest van de knooppunten in MongoDB worden als uitvoer gebruikt; daarom, als de gegevens in de slave-knooppunten moeten worden geschreven en door het masterknooppunt moeten gaan. Cassandra ondersteunt meerdere master nodes in een cluster, wat het geschikt maakt in het geval van Scalability.
Ondersteuning voor querytaal
Momenteel ondersteunt MongoDB geen querytaal. De queries in MongoDB zijn gestructureerd als JSON-fragmenten. Cassandra daarentegen heeft een gebruiksvriendelijke reeks zoekopdrachten die bekend staat als CQL (Cassandra Query Language) en die gemakkelijk kan worden aangepast door de ontwikkelaars die voorkennis van SQL hebben. Waarin verschillen hun vragen?
Records selecteren uit de klantentabel:
Cassandra:
SELECT * FROM customer;MongoDB:
db.customer.find()Records invoegen in de klantentabel:
Cassandra:
INSERT INTO customer (custid, branch, status) VALUES('appl01', 'headquarters', 'A');MongoDB:
db.customer.insert({ cust_id: 'appl01', branch: 'headquarters', status: 'A' })Records in de klantentabel bijwerken:
Cassandra:
UPDATE Customer SET branch = ‘headquarters' WHERE custage > 2;MongoDB:
db.customer.update( { custage: { $gt: 2 } }, { $set: { branch: 'headquarters' } }, { multi: true } )Native aggregatie
MongoDB heeft een ingebouwd aggregatieraamwerk dat wordt gebruikt om een ETL-pijplijn uit te voeren om de gegevens die in de database zijn opgeslagen te transformeren en ondersteunt ook zowel klein als middelgroot gegevensverkeer. Wanneer de complexiteit toeneemt, wordt het ook moeilijker om fouten in het raamwerk te debuggen, terwijl Cassandra geen geïntegreerd aggregatieraamwerk heeft. Cassandra gebruikte externe tools zoals Hadoop, Apache Spark, enz. Daarom is MongoDB beter dan Cassandra als het gaat om het ingebouwde aggregatieframework.
Schemaloos model
MongoDB biedt de mogelijkheid voor een gebruiker om de handhaving van elk schema in de database te wijzigen. Elke database kan een andere structuur hebben. Het hangt allemaal af van het programma of de toepassing om de gegevens te interpreteren. Terwijl Cassandra niet de mogelijkheid biedt om schema's te wijzigen, maar statische typen biedt waarbij de gebruiker in het begin het type van de kolom moet definiëren.
Prestatiebenchmark
Cassandra overweegt om beter te presteren in toepassingen die een zware gegevensbelasting vereisen, omdat het meerdere hoofdknooppunten in een cluster kan ondersteunen. Terwijl MongoDB niet ideaal is voor toepassingen met een zware gegevensbelasting, omdat het niet kan worden geschaald met de prestaties. Gebaseerd op de industriestandaard benchmark gemaakt door Yahoo! genaamd YCSB, MongoDB levert betere prestaties dan Cassandra in alle tests die ze hebben uitgevoerd, in sommige gevallen tot wel 25x. Wanneer geoptimaliseerd voor een balans tussen doorvoer en duurzaamheid tussen Cassandra en MongoDB, biedt MongoDB meer dan 50% hogere doorvoer in gemengde werkbelastingen en 2,5x grotere doorvoer in lees-dominante werkbelastingen in vergelijking met Cassandra.
MongoDB biedt de meeste flexibiliteit om duurzaamheid voor specifieke bewerkingen te garanderen:gebruikers kunnen kiezen voor de voor duurzaamheid geoptimaliseerde configuratie voor specifieke bewerkingen die als kritiek worden beschouwd, maar waarvoor de extra latentie acceptabel is. Voor Cassandra vereist deze wijziging het bewerken van een serverconfiguratiebestand en een volledige herstart van de database.
Conclusie
MongoDB staat vooral bekend om workloads met veel zeer ongestructureerde gegevens. De schaal en soorten gegevens waarmee u gaat werken met de flexibele gegevensstructuren van MongoDB zullen u beter bevallen dan Cassandra. Om MongoDB effectief te gebruiken, moet u kunnen omgaan met de mogelijkheid van enige downtime als het hoofdknooppunt uitvalt, evenals met beperkte schrijfsnelheden. En vergeet niet dat je ook een nieuwe zoektaal moet leren. In MongoDB kunnen de complexe gegevens eenvoudig worden beheerd met behulp van de ondersteuningsmogelijkheden voor JSON-indeling. Dit is een belangrijke onderscheidende factor voor MongoDB wanneer je het vergelijkt met Cassandra. In sommige situaties kan Cassandra worden beschouwd als de beste database om te implementeren bij grote hoeveelheden gegevens, snelheidsoptimalisatie en het uitvoeren van query's. Uit de vergelijkingsresultaten van Cassandra en MongoDB zullen we zien dat ze hun respectieve voordelen hebben, afhankelijk van de implementatievereisten en de hoeveelheid gegevens die moeten worden verwerkt.