Inleiding:dit voorbeeld demonstreert een oudere methode van het gebruik van IRI RowGen voor het genereren en vullen van grote of complexe collectieprototypes voor testen of systeemcapaciteit met behulp van platte bestanden. Zoals u zult lezen, zou RowGen de benodigde testgegevens maken en een CSV-bestand maken dat in MongoDB zou worden geladen met behulp van de Mongo Import Utility.
update 2019:IRI biedt nu ook JSON en directe driverondersteuning om gegevens te verplaatsen tussen MongoDB-verzamelingen en SortCL-compatibele IRI-softwareproducten zoals RowGen of FieldShield. Dit betekent dat je RowGen kunt gebruiken om test-JSON-bestanden te genereren voor import in MongoDB (niet anders dan de methode die hieronder in dit artikel wordt getoond), of FieldShield kunt gebruiken om gegevens in Mongo-tabellen te maskeren in testdoelen.
Houd er rekening mee dat zowel FieldShield als RowGen zijn opgenomen in het IRI Voracity-gegevensbeheerplatform, dat vier manieren biedt om testgegevens te maken.
Hoewel MongoDB een prima platformonafhankelijke, documentgeoriënteerde NoSQL-database is, heeft het geen handige manier om grote of complexe verzamelingsprototypes te genereren en te vullen die kunnen worden gebruikt om query's te testen of capaciteit te plannen. In dit artikel wordt uitgelegd hoe u testgegevens maakt die MongoDB kan gebruiken via IRI RowGen, waarbij de parameters worden gespecificeerd voor een synthetisch, maar realistisch CSV-bestand dat MongoDB kan importeren voor functionele en prestatietests.
U moet eerst nadenken over de structuur en inhoud van de testgegevens voor uw verzameling (MongoDB-tabel) behoeften. Zie dit artikel voor typische planningsoverwegingen.
In het voorbeeld weten we dat onze collectie zal bestaan uit klanten die allemaal gebruikersnamen hebben , Voor- en achternaam , E-mailadressen , en Creditcardnummers .
Om onze testgegevens te maken, moeten we eerst enkele setbestanden genereren. Een setbestand is een lijst met een of meer door tabs gescheiden waarden die mogelijk al bestaan, of handmatig of automatisch moeten worden gegenereerd uit databasekolommen via de wizard 'Nieuw setbestand genereren' in IRI RowGen.
Namen genereren
1) Maak een samengestelde gegevenswaarde (voor- en achternaam gecombineerd) taakscript met de naam 'CreateNamesSet.rcl' dat RowGen kan uitvoeren om een setbestand te produceren; noem de uitvoer 'User.set' omdat deze namen ook worden gebruikt als basis voor onze gebruikersnamen.
2) Maak drie velden die moeten worden gegenereerd in Names.set:achternaam, tabscheidingsteken en voornaam. Geef het eerste veld de naam 'Achternaam' en kies de methode waarmee waarden worden geselecteerd uit een door IRI geleverd setbestand met de naam 'names_last.set'. Voeg de letterlijke waarde '\t' toe om een tab-scheidingsteken toe te voegen en herhaal vervolgens het proces dat wordt gebruikt voor de waarden voor Achternaam en Voornaam met name_first.set.
3) Voer CreateNamesSet.rcl uit met RowGen, op de opdrachtregel of vanuit de IRI Workbench GUI, om het door tabs gescheiden User.set-bestand met voor- en achternaam te maken, dat zal worden gebruikt in zowel het genereren van gebruikersnamen als in het uiteindelijke testbestand dat onze prototypeverzameling vult.

Gebruikersnamen genereren
Voor Gebruikersnamen maken we een setbestand dat gebruikmaakt van het hierboven gegenereerde Users.set-bestand. Gebruikersnamen voor dit voorbeeld combineren achternaam, voorletter en een willekeurig gegenereerd getal tussen 100 en 999.
1) Maak een nieuw RowGen-taakscript met de wizard Samengestelde gegevens, noem het 'CreateUsernamesSet.rcl' en noem het uitvoersetbestand 'Usernames.set'.
2) Stel samengestelde gebruikersnaamwaarden samen met drie componenten genaamd Part1, Part2 en Part3.
3) Kies voor Part1 de methode die waarden selecteert uit (blader naar) het eerder gegenereerde User.set-bestand en specificeer 'ALL' voor het selectietype om de associatie tussen gebruikers te behouden, gebruikersnamen en e-mailadressen. Stel de grootte in op 5.
4) Voor Part2 herhaalt u het proces dat voor Part1 is gebruikt, behalve voor Selectietype, selecteert u 'Rij' en stelt u Kolomindex in op 2. Stel de grootte in op 1. Dit garandeert dat alle achternamen worden gebruikt in de generatie, en dat de eerste letter van de voornaam in dezelfde rij wordt toegevoegd aan de gebruikersnaam.
5) Geef voor Deel 3 het genereren van een numerieke waarde tussen 100 en 999 op om een willekeurig geheel getal achter elke gebruikersnaam te voegen.
Bij uitvoering van CreateUsernamesSet.rcl zien we dat elke gebruikersnaam de eerste vijf letters van hun achternaam bevat, vervolgens hun eerste initiaal en vervolgens een willekeurig getal van drie cijfers:
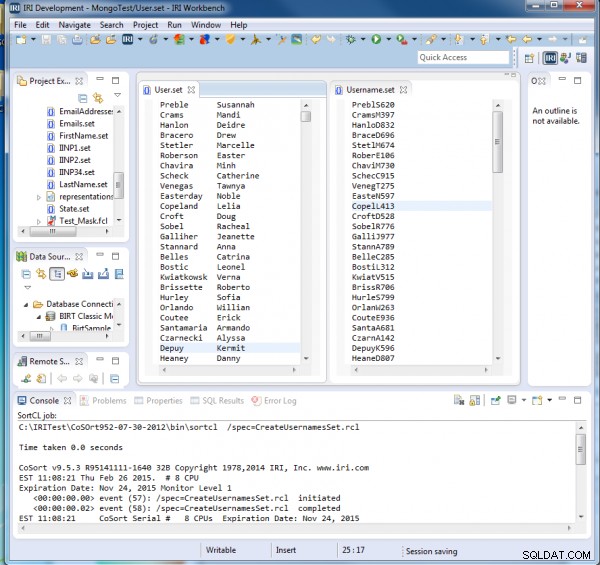
E-mails genereren
Vervolgens maken we een e-mailsetbestand dat de gebruikersnaamwaarden toevoegt aan willekeurig geselecteerde domeinnamen. Omdat sommige e-mailservices populairder zijn dan andere, zullen we ook een wegingssysteem maken om een hogere frequentie van Yahoo- en Gmail-domeinen weer te geven.
1) Voer de taakwizard 'Nieuwe aangepaste testgegevens' van RowGen uit om een taak met de naam "CreateEmailsSet" te maken die een setbestand met de naam "Emails.set" produceert.
2) Maak het gebruikersnaamgedeelte van de e-mail. Klik in het dialoogvenster Testgegevensdefinitie op Nieuw veld en hernoem het eerste veld Gebruikersnamen. Dubbelklik erop om het dialoogvenster Generatieveld te starten en "Definieer ..." het Stel het bestand in als Gebruikersnamen.set. Stel de grootte in op 9 en klik op OK.
3) Produceer het domeingedeelte van de e-mail (inclusief het @-symbool). Klik in het dialoogvenster Lay-outvelden op Nieuw veld, hernoem het naar "adres" en dubbelklik erop. Geef in het dialoogvenster Generatieveld een " " op met een positie van 10 en een grootte van 20. Klik in het gedeelte Gegevensgeneratie / gegevensdistributie hieronder op "Definiëren ..." om een nieuwe gegevensdistributie van items "WeightedEmails" te noemen.
4) Kies in de wizard Nieuwe distributie de optie 'Gewogen distributie van items' en voer deze items in respectievelijk in de verhoudings- en letterlijke tekstvakken in, en voeg ze vervolgens toe aan de lijst.
(32 | @gmail.com), (32 | @yahoo.com), (2 | @ibm.com), (4 | @msn.com), (2 | @ymail.com), (2 | @inmail.com), (2 | @cnet.net), (2 | @chase.org), (1 | @iri.com), (1 | @gdic.com), (1 | @aci.com), (2 | @oracle.net), (1 | @gmx.org), (4 | @aol.com), (2 | @inbox.com), (2 | @hushmail.com), (2 | @outlook.com), (2 | @zoho.com), (2 | @yandex.net), (2 | @mail.com)
Nadat u deze waarden heeft ingevoerd, klikt u in de oorspronkelijke wizard op Volgende om naar het dialoogvenster Gegevensdoelen te gaan. Gebruik "Gegevensdoel toevoegen ..." om het uitvoerbestand "Email.set" op te geven. Dit wordt ook gebruikt tijdens het opbouwen van de collectie.
De e-mail waarvoor we het hoogste gewicht hebben ingesteld (gmail en yahoo) wordt het vaakst weergegeven, terwijl andere regelmatig worden weergegeven.

Creditcardnummers genereren
Ten slotte maken we rekenkundig geldige kaartnummers in de indeling XXXX-XXXX-XXXX-XXXX. De eerste vier cijfers geven de werkelijke uitgifte-identificatienummers (IIN) van verschillende creditcardmaatschappijen weer en het laatste cijfer verifieert de authenticiteit van de kaarten.
Om dit te doen, maakt u een nieuwe (lege) taak aan en voert u deze uit. Noem het "CreateCCNSet.rcl" (of .scl) en vul het met het onderstaande script om "CCN.set" te maken. De waarde /INCOLLECT in RowGen-scripts bepaalt het aantal gegenereerde rijen.

De speciaal gebouwde CCN-generatiefunctie van RowGen, ccn_gen(“ANY, “-“) wordt aangeroepen om dit veld in te vullen. Merk op dat soortgelijke functies bestaan voor Amerikaanse en Koreaanse burgerservicenummers en de nationale ID's van Italië en Nederland.
Het definitieve testbestand maken
Nu alle setbestanden zijn gebouwd, is het tijd om ze te gebruiken in het test-CSV-bestand dat we maken en exporteren naar een MongoDB-verzameling.
1) Voer de taakwizard 'Nieuwe aangepaste testgegevens' van RowGen uit om een taak te maken met de naam 'CreateMongoUserData.rcl' die het bestand Customers.csv genereert, het bestand dat we vervolgens naar MongoDB exporteren.
2) Klik op 'Lay-outvelden ..." om het dialoogvenster Lay-outvelden te openen. Klik op Nieuw veld en hernoem het eerste veld naar Gebruikersnamen. Dubbelklik erop om het dialoogvenster Generatieveld te openen en "Definieer ..." het Stel het bestand in als Gebruikersnamen.set; selecteer dan ALLE als selectietype.
3) Klik op Nieuw veld en wijzig de naam van het tweede veld in LastNames. Dubbelklik erop om het dialoogvenster Generatieveld te starten en "Definieer ..." het Stel het bestand in als Users.set; selecteer dan ALLE als selectietype.
4) Klik op Nieuw veld en wijzig de naam van het derde veld in Voornamen. Dubbelklik erop om het dialoogvenster Generatieveld te starten en "Definieer ..." het Stel het bestand in als Users.set; selecteer vervolgens RIJEN als selectietype en stel de kolomindex in op 2.
5) Klik op Nieuw veld en wijzig de naam van het vierde veld in E-mail. Dubbelklik erop om het dialoogvenster Generatieveld te openen en "Definieer ..." het Stel het bestand in als Emails.set; selecteer dan ALLE als selectietype.
6) Klik op Nieuw veld en wijzig de naam van het vijfde veld in CreditCardNumbers. Dubbelklik erop om het dialoogvenster Generatieveld te starten en "Definieer ..." het Stel het bestand in als CCN.set; selecteer dan ALLE als selectietype.
7) Nadat u deze waarden heeft ingevoerd, klikt u op Volgende in de oorspronkelijke wizard om naar het dialoogvenster Gegevensdoelen te gaan. Gebruik "Gegevensdoel toevoegen ..." om het uitvoerbestand Customers.csv op te geven; voer vervolgens het script uit in de Workbench of op de opdrachtregel om dat bestand te genereren:
rowgen /spec=CreateMongoUserData.rcl

Merk op dat RowGen, naast het produceren van dit CSV-bestand tijdens runtime, ook meerdere, andere bestanden, databases, geformatteerde rapporten, named-pipes, procedurele en zelfs realtime BIRT-weergaven had kunnen produceren , met velden uit de gegenereerde testgegevens, allemaal tegelijk.
Importeren naar MongoDB
Om het CSV-bestand in uw Mongo-database te importeren, roept u het 'mongoimport-hulpprogramma' op en voert u de volgende opdracht uit:
--db <Database Name> --collection <Collection Name> --type csv --fields <fieldname1,fieldname2,...> --file <File path to the CSV file to import>

Dit zijn de records in de testverzameling (weergegeven met MongoVUE), die MongoDB automatisch indexeert met gegenereerde ID-waarden voor elke invoer:
MongoDB wijst een unieke ID-waarde toe aan elke verzamelingsvermelding.
U kunt testgegevens ook rechtstreeks in de Mongo-database laden met de DataDirect ODBC-driver voor MongoDB van Progress Software. Voordat ik de RowGen-taak in de Workbench uitvoerde, had ik een lege verzameling met de naam CUSTOMERS_CNN in MYDB om de gegevens te ontvangen.
Ik heb de taak eerst uitgevoerd met stdout, om een voorbeeld van mijn testgegevens in het consolevenster te bekijken:

Nadat ik het script in de Workbench heb uitgevoerd, kan ik nu mijn gegevens zien met behulp van de Data Source Explorer en het DataDirect JDBC-stuurprogramma.

Zie de Testbestandsdoelen . voor meer informatie over de beschikbare generatie-opties sectie op: https://www.iri.com/products/rowgen/technical-details.