TL;DR:mongoengine besteedt veel tijd aan het converteren van alle geretourneerde arrays naar dicts
Om dit te testen heb ik een collectie gebouwd met een document met een DictField met een groot genest dict . Het document bevindt zich ongeveer in uw bereik van 5-10 MB.
We kunnen dan timeit.timeit gebruiken
om het verschil in uitlezingen te bevestigen met pymongo en mongoengine.
We kunnen dan pycallgraph gebruiken en GraphViz om te zien wat Mongoengine zo verdomd lang duurt.
Hier is de volledige code:
import datetime
import itertools
import random
import sys
import timeit
from collections import defaultdict
import mongoengine as db
from pycallgraph.output.graphviz import GraphvizOutput
from pycallgraph.pycallgraph import PyCallGraph
db.connect("test-dicts")
class MyModel(db.Document):
date = db.DateTimeField(required=True, default=datetime.date.today)
data_dict_1 = db.DictField(required=False)
MyModel.drop_collection()
data_1 = ['foo', 'bar']
data_2 = ['spam', 'eggs', 'ham']
data_3 = ["subf{}".format(f) for f in range(5)]
m = MyModel()
tree = lambda: defaultdict(tree) # https://stackoverflow.com/a/19189366/3271558
data = tree()
for _d1, _d2, _d3 in itertools.product(data_1, data_2, data_3):
data[_d1][_d2][_d3] = list(random.sample(range(50000), 20000))
m.data_dict_1 = data
m.save()
def pymongo_doc():
return db.connection.get_connection()["test-dicts"]['my_model'].find_one()
def mongoengine_doc():
return MyModel.objects.first()
if __name__ == '__main__':
print("pymongo took {:2.2f}s".format(timeit.timeit(pymongo_doc, number=10)))
print("mongoengine took", timeit.timeit(mongoengine_doc, number=10))
with PyCallGraph(output=GraphvizOutput()):
mongoengine_doc()
En de output bewijst dat mongoengine erg traag is in vergelijking met pymongo:
pymongo took 0.87s
mongoengine took 25.81118331072267
De resulterende oproepgrafiek illustreert vrij duidelijk waar de bottleneck zit:
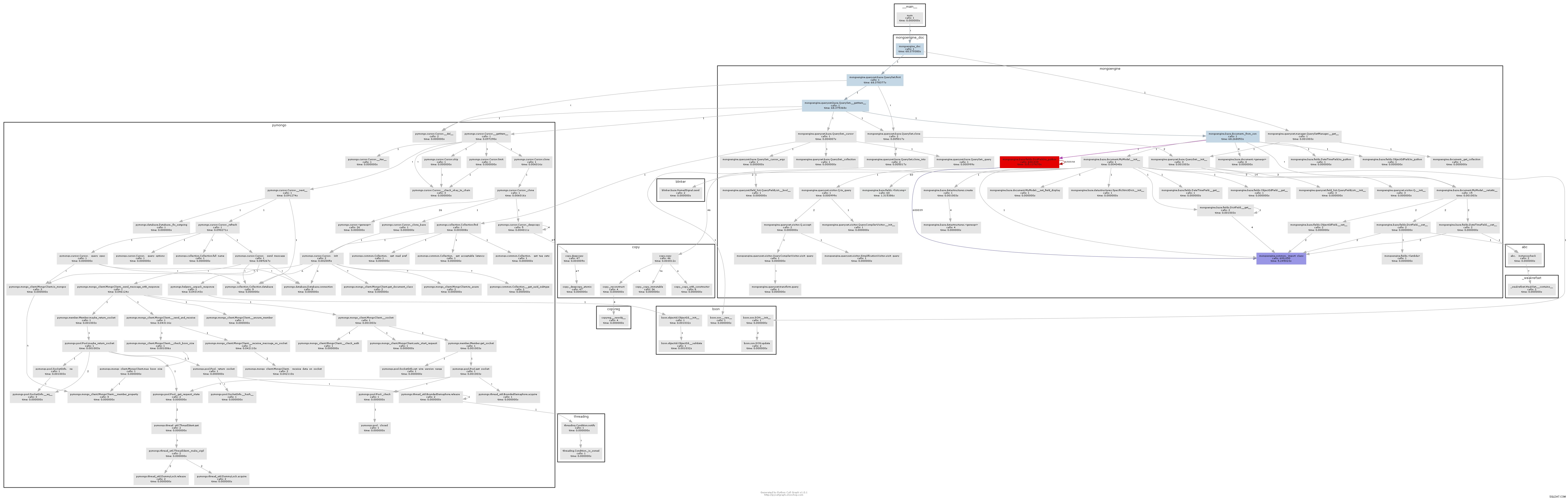
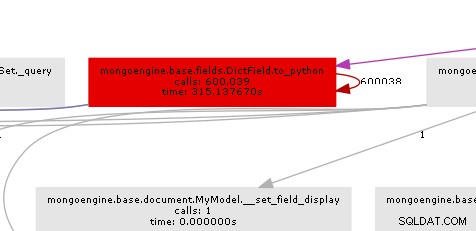
In wezen roept mongoengine de to_python-methode aan op elk DictField dat het terugkomt van de db. to_python is vrij traag en in ons voorbeeld wordt het een waanzinnig aantal keren genoemd.
Mongoengine wordt gebruikt om uw documentstructuur op elegante wijze toe te wijzen aan python-objecten. Als je erg grote ongestructureerde documenten hebt (waar mongodb geweldig voor is), dan is mongoengine niet echt de juiste tool en moet je gewoon pymongo gebruiken.
Als u echter de structuur kent, kunt u EmbeddedDocument . gebruiken velden om iets betere prestaties van mongoengine te krijgen. Ik heb een vergelijkbare maar niet gelijkwaardige test code in deze gist
uitgevoerd en de uitvoer is:
pymongo with dict took 0.12s
pymongo with embed took 0.12s
mongoengine with dict took 4.3059175412661075
mongoengine with embed took 1.1639373211854682
Dus je kunt mongoengine sneller maken, maar pymongo is nog veel sneller.
UPDATE
Een goede snelkoppeling naar de pymongo-interface hier is om het aggregatieraamwerk te gebruiken:
def mongoengine_agg_doc():
return list(MyModel.objects.aggregate({"$limit":1}))[0]