Aangezien je de lente gebruikt. U kunt MultipartFile . gebruiken om het bestand in je controller te krijgen en gebruik dan Binary van org.bson om het bestand op MongoDB op te slaan, als uw afbeeldingsgrootte <16 MB (als afbeeldingsgrootte> 16 MB kunt u GridFs
).
U hoeft slechts één afhankelijkheid aan uw project toe te voegen - spring-data-mongoDB
Laten we een voorbeeld nemen van een gebruikersverzameling die er als volgt uitziet:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Hier zie je Binary image die uw afbeeldingsbestand vertegenwoordigt.
Maak nu een repository voor deze gebruikersverzameling met behulp van MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Maak een controller voor demo-doeleinden. Gebruik @RequestParam MultipartFile file om het bestand naar uw controller te krijgen, haalt u bytes uit het bestand en stelt u het in op gebruikersobject user.setImage(new Binary(file.getBytes())); compleet voorbeeld staat hieronder:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Start de server en raak het eindpunt zoals getoond in onderstaande postbode screenshot
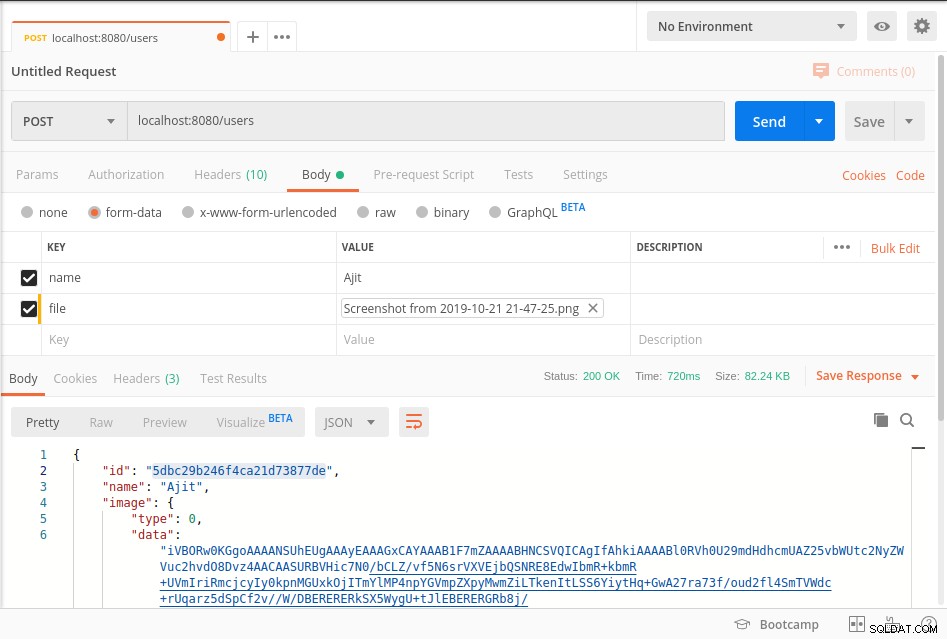
Uw gegevens worden opgeslagen in mongoDb in BinData formaat en om de gegevens uit de database te halen, raadpleegt u getImage methode van bovenstaande code.
BEWERKEN:
De vraagsteller gebruikt tess4j bibliotheek voor het extraheren van tekst uit afbeelding en doOCR is een methode in deze bibliotheek. Ik heb deze stappen gevolgd om tekst uit een afbeelding te extraheren in mijn lente-opstarttoepassing.
-
Installeer
tesseract-ocrin uw systeem:sudo apt-get install tesseract-ocr -
Download
eng.traineddatatrainingsgegevens van https://github.com/tesseract-ocr/tessdata en verplaats het naar de hoofdmap van het project. -
Voeg onderstaande afhankelijkheid toe aan uw project:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Voeg de onderstaande code toe aan een bestaand project:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}