
Dit bericht maakt deel uit van de Oracle SQL-zelfstudie en we zouden analytische functies in Oracle (Over per partitie) bespreken met voorbeelden, gedetailleerde uitleg.
We hebben al gestudeerd over Oracle Aggregate-functies zoals avg,sum,count. Laten we een voorbeeld nemen
Laten we eerst de voorbeeldgegevens maken
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Nu wordt het voorbeeld van geaggregeerde functies gegeven zoals hieronder
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Hier kunnen we zien dat het het aantal rijen in elk van de query's vermindert. Nu komen er vragen wat we moeten doen als we alle rijen moeten teruggeven met count(*) ook
Want dat orakel heeft een reeks analytische functies verschaft. Dus om het laatste probleem op te lossen, kunnen we schrijven als
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
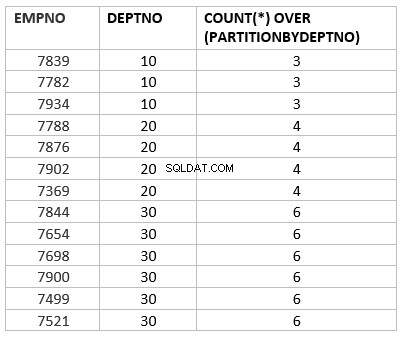
Hier is count(*) over (partition by dept_no) de analytische versie van de count-aggregatiefunctie. Het belangrijkste sleutelwerk dat per aggregatiefunctie verschilt, is over partitie door
Analytische functies berekenen een totale waarde op basis van een groep rijen. Ze verschillen van geaggregeerde functies doordat ze meerdere rijen voor elke groep retourneren. De groep rijen wordt een venster genoemd en wordt gedefinieerd door de analytic_clause.
Hier is de algemene syntaxis
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Voorbeeld
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Laten we elk onderdeel doornemen
query_partition_clause
Het definieerde de groep rijen. Het kan zoals hieronder
partitie door deptno :groep rijen van dezelfde deptno
of
() :Alle rijen
SQL> select empno ,deptno , count(*) over () from emp;
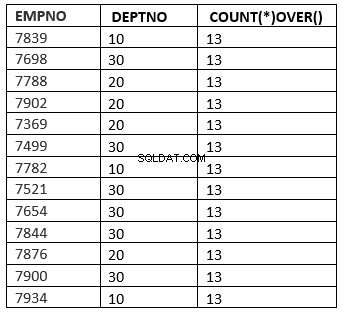
[ order_by_clause [ windowing_clause ] ]
Deze clausule wordt gebruikt wanneer u de rijen in de partitie wilt ordenen. Dit is vooral handig als u wilt dat de analytische functie rekening houdt met de volgorde van de rijen.
Voorbeeld is de functie row_number
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
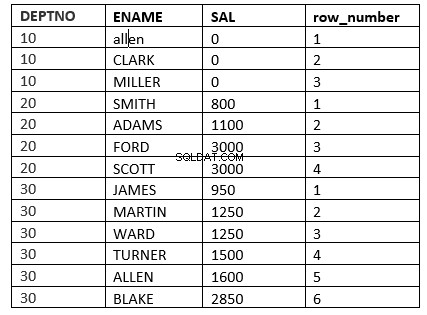
Een ander voorbeeld zou zijn
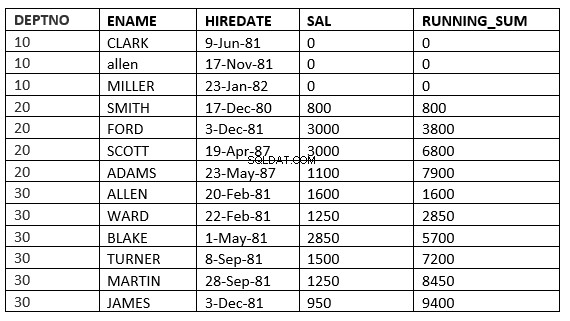
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
Dit wordt altijd gebruikt met volgorde per clausule en geeft meer controle over de reeks rijen in de groep
Met Windowing-clausule wordt voor elke rij een glijdend venster met rijen gedefinieerd. Het venster bepaalt het rijbereik dat wordt gebruikt om de berekeningen voor de huidige rij uit te voeren. Venstergroottes kunnen gebaseerd zijn op een fysiek aantal rijen of op een logisch interval zoals tijd.
Bij gebruik van de volgorde per clausule en er wordt niets gegeven voor windowing_clause, wordt onder de standaardwaarde van de windowing_clause genomen
BEREIK TUSSEN UNBOUNDED VOORAFGAANDE EN HUIDIGE RIJ of RANGE UNBOUNDED PRECEDING
Het betekent "De huidige en vorige rijen in de huidige partitie zijn de rijen die in de berekening moeten worden gebruikt”
Onderstaand voorbeeld geeft dit duidelijk weer. Dit is het lopende gemiddelde op de afdeling
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
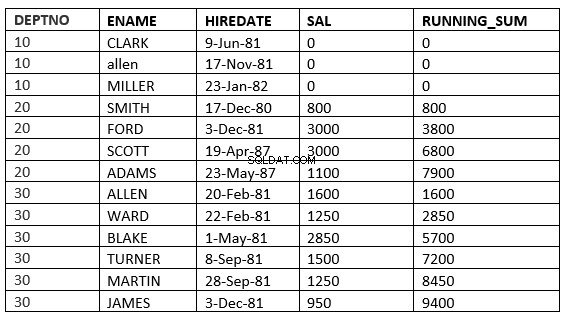
Nu kan windowing_clause op een aantal manieren worden gedefinieerd
Laten we eerst de terminologie begrijpen
RIJEN specificeert het venster in fysieke eenheden (rijen).
RANGE specificeert het venster als een logische offset. de vensterclausule RANGE kan alleen worden gebruikt met ORDER BY-clausules die kolommen of uitdrukkingen van numerieke of datumgegevenstypen bevatten
VOORGAANDE – krijg rijen voor de huidige.
VOLGENDE – krijg rijen na de huidige.
UNBOUNDED – wanneer gebruikt met PRECEDING of FOLLOWING, keert het allemaal terug voor of na. HUIDIGE RIJ
Dus het wordt over het algemeen gedefinieerd als
RIJEN ONGEBONDEN VOORAFGAANDE :De huidige en vorige rijen in de huidige partitie zijn de rijen die moeten worden gebruikt in de berekening
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
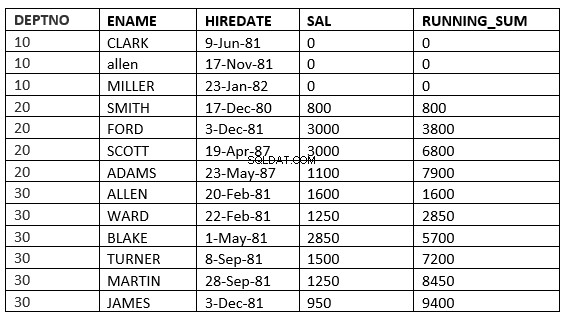
BEREIK ONGEBONDEN VOORAFGAANDE :De huidige en vorige rijen in de huidige partitie zijn de rijen die in de berekening moeten worden gebruikt. Omdat het bereik is opgegeven, worden alle waarden gebruikt die gelijk zijn aan de huidige rijen.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
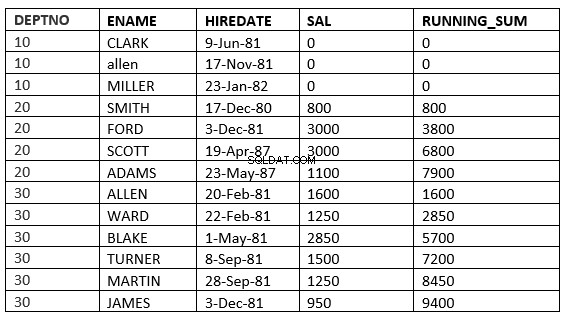
Het is mogelijk dat u het verschil tussen het bereik en de rijen niet ziet, aangezien de huurdatum voor iedereen anders is. Het verschil wordt duidelijker als we sal gebruiken als volgorde per clausule
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
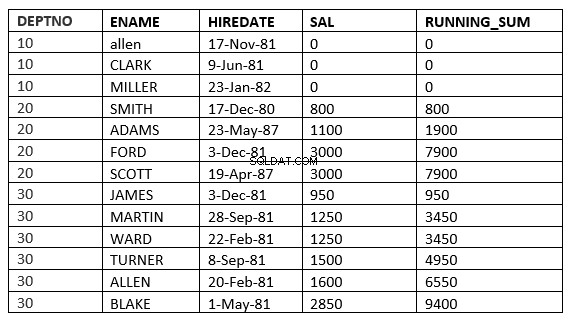
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
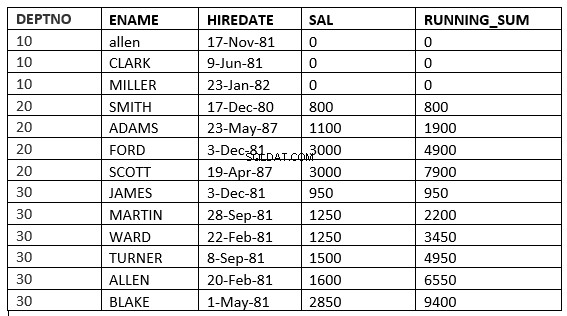
Je kunt het verschil vinden op regel 6
BEREIK value_expr VOORAFGAAND aan :Het venster begint met de rij waarvan de ORDER BY-waarde een numerieke uitdrukkingsrij is die kleiner is dan of voorafgaat aan de huidige rij en eindigt met de huidige rij die wordt verwerkt.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
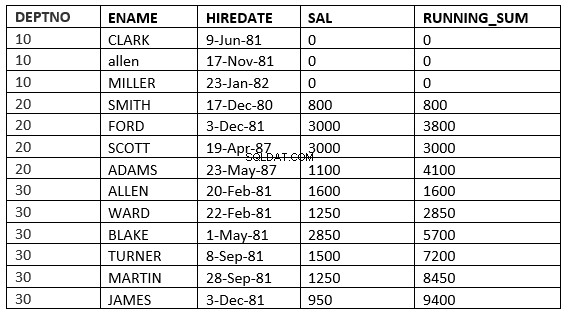
Hier zijn alle rijen nodig waar de huurwaarde valt binnen 365 dagen voorafgaand aan de huurprijs van de huidige rij
ROWS value_expr PRECEDING :Het venster begint met de gegeven rij en eindigt met de huidige rij die wordt verwerkt
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
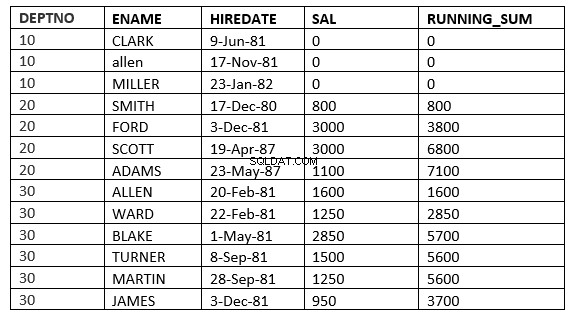
Hier begint het venster vanaf 2 rijen voorafgaand aan de huidige rij
BEREIK TUSSEN HUIDIGE RIJ en value_expr VOLGENDE :Het venster begint met de huidige rij en eindigt met de rij waarvan de ORDER BY-waarde een numerieke uitdrukkingsrij is die kleiner is dan of volgt
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
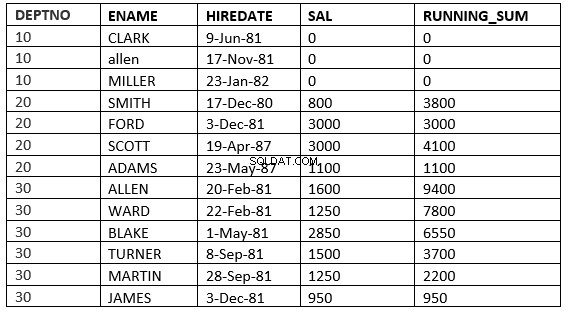
RIJEN TUSSEN DE HUIDIGE RIJ en value_expr VOLGENDE :Het venster begint met de huidige rij en eindigt met de rijen na de huidige
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
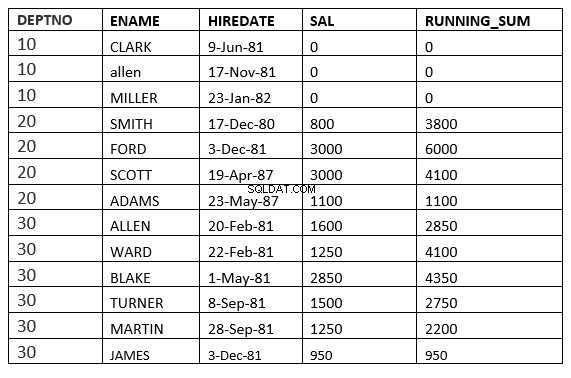
BEREIK TUSSEN ONGEBONDEN VOORAFGAANDE en ONGEBONDEN VOLGENDE
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
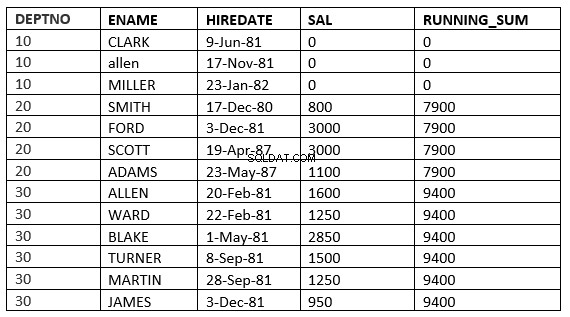
BEREIK TUSSEN value_expr PRECEDING en value_expr VOLGENDE
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Enkele belangrijke opmerkingen
(1)Analytische functies zijn de laatste reeks bewerkingen die in een query worden uitgevoerd, behalve de laatste ORDER BY-clausule. Alle joins en alle WHERE-, GROUP BY- en HAVING-clausules zijn voltooid voordat de analytische functies worden verwerkt. Daarom kunnen analytische functies alleen voorkomen in de select list of ORDER BY-clausule.
(2)Analytische functies worden vaak gebruikt om cumulatieve, bewegende, gecentreerde en rapportage-aggregaten te berekenen.
Ik hoop dat je deze gedetailleerde uitleg van analytische functies in orakel leuk vindt (over by Partition Clause)
Gerelateerde artikelen
LEAD-functie in Oracle
DENSE-functie in Oracle
Oracle LISTAGG-functie
Aggregatiegegevens met groepsfuncties
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm