Na een recente upgrade naar 12.1.0.2 heb ik aan een aantal prestatieproblemen gewerkt. Veel van dergelijke problemen zijn gerelateerd aan slechte SQL en een aantal problemen die ik heb opgelost, waarvan ik heb bewezen dat ze problemen waren in de oude 11.2.0.4-release. Dit betekent alleen dat het altijd een probleem is geweest. Maar mensen maken van de upgrade gebruik om mij dingen te laten repareren die al een tijdje kapot zijn.
Terwijl ik naar prestatieproblemen kijk, ben ik twee SQL-instructies tegengekomen die varkens in ons systeem worden. Hier is een screenshot van de twee SQL-statements zoals te zien in Lighty:
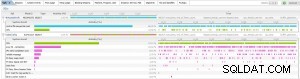
We kunnen zien dat de eerste SQL-instructie (SQL ID 4b4wp0a8dvkf0) CPU verbruikt en wacht op leesbewerkingen uit het controlebestand. De tweede SQL-instructie (SQL ID frjd8zfy2jfdq) gebruikt veel CPU en heeft ook een aantal andere wachtgebeurtenissen. Hier is de SQL-tekst van deze instructies.
SQL-ID:frjd8zfy2jfdq
SELECT
executions
,end_of_fetch_count
,elapsed_time / px_servers elapsed_time
,cpu_time / px_servers cpu_time
,buffer_gets / executions buffer_gets
FROM
(
SELECT
SUM (executions) AS executions
,SUM (
CASE
WHEN px_servers_executions > 0
THEN px_servers_executions
ELSE executions
END
) AS px_servers
,SUM (end_of_fetch_count) AS end_of_fetch_count
,SUM (elapsed_time) AS elapsed_time
,SUM (cpu_time) AS cpu_time
,SUM (buffer_gets) AS buffer_gets
FROM
gv$sql
WHERE
executions > 0
AND sql_id = : 1
AND parsing_schema_name = : 2
SQL-ID:4b4wp0a8dvkf0
SELECT
executions
,end_of_fetch_count
,elapsed_time / px_servers elapsed_time
,cpu_time / px_servers cpu_time
,buffer_gets / executions buffer_gets
FROM
(
SELECT
SUM (executions_delta) AS EXECUTIONS
,SUM (
CASE
WHEN px_servers_execs_delta > 0
THEN px_servers_execs_delta
ELSE executions_delta
END
) AS px_servers
,SUM (end_of_fetch_count_delta) AS end_of_fetch_count
,SUM (elapsed_time_delta) AS ELAPSED_TIME
,SUM (cpu_time_delta) AS CPU_TIME
,SUM (buffer_gets_delta) AS BUFFER_GETS
FROM
DBA_HIST_SQLSTAT s
,V$DATABASE d
,DBA_HIST_SNAPSHOT sn
WHERE
s.dbid = d.dbid
AND bitand (
nvl (
s.flag
,0
)
,1
) = 0
AND sn.end_interval_time > (
SELECT
systimestamp AT TIME ZONE dbtimezone
FROM
dual
) - 7
AND s.sql_id = : 1
AND s.snap_id = sn.snap_id
AND s.instance_number = sn.instance_number
AND s.dbid = sn.dbid
AND parsing_schema_name = : 2
)
)
Beide maken deel uit van de nieuwe Adaptive Query Optimization-functies die nu in 12c beschikbaar zijn. Meer specifiek hebben deze betrekking op het gedeelte Automatische dynamische statistieken van deze functie. SQL ID frjd8zfy2jfdq is Oracle die informatie verkrijgt over de prestaties van SQL-statements van GV$SQL. SQL ID 4b4wp0a8dvkf0 is dat Oracle dezelfde informatie over de prestaties van SQL-statements verkrijgt uit de Active Session History-tabellen.
Bertand Drouvot bespreekt dit hier op zijn blog:https://bdrouvot.wordpress.com/2014/10/17/watch-out-for-optimizer_adaptive_features-as-it-may-have-a-huge-negative-impact/
Daarnaast nam ik deel aan een sessie van Christian Antognini op Oak Table World 2015 waar hij deze SQL-statements noemde. Zijn dia's van OTW zijn vrijwel hetzelfde als deze:
https://www.soug.ch/fileadmin/user_upload/SIGs/SIG_150521_Tuning_R/Christian_Antognini_AdaptiveDynamicSampling_trivadis.pdf
Die links hierboven en de MOS-aantekeningen waarnaar ik hieronder verwijs, vormden een groot deel van de basis van de informatie die ik hier presenteer.
Alle functies van Adaptive Query Optimization zouden het leven van de DBA beter moeten maken. Ze worden verondersteld de Optimizer te helpen betere beslissingen te nemen, zelfs nadat een SQL-instructie is uitgevoerd. In dit specifieke geval worden deze zoekopdrachten verondersteld de CBO te helpen betere statistieken te verkrijgen, zelfs als de statistieken ontbreken. Dit kan de SQL-prestaties helpen verbeteren, maar zoals ik in mijn geval ontdekte, belemmert het de algehele systeemprestaties.
Zie opmerking 2031605.1 voor meer informatie over adaptieve query-optimalisatie. Dit zal u naar andere notities leiden, maar in het bijzonder naar deze discussie, Note 2002108.1 Automatic Dynamic Statistics.
Wat het nog erger maakt, is dat mijn productiesysteem dat dit gedrag ziet Oracle RAC is. Wanneer SQL ID frjd8zfy2jfdq wordt uitgevoerd op Oracle RAC-systemen, wordt een parallelle query gebruikt, wat duidelijk is uit mijn screenshot van de enq:PS - contention en "PX%" wachtgebeurtenissen.
We kunnen dynamische bemonstering als volgt uitschakelen:
verander systeem set optimizer_dynamic_sampling=0 scope=beide;
De standaardwaarde van deze parameter is 2.
Voor mij verbruiken deze query's bronnen en hebben ze invloed op de algehele databaseprestaties. Toch zijn deze functies ontworpen om te verbeteren uitvoering. Er is altijd een risico dat als ik de functie uitschakel om de prestaties op het ene gebied te verbeteren, dit de prestaties op een ander gebied schaadt. Maar sinds optimizer_dynamic_sampling<>11 voor mij, gebruik ik die functie niet ten volle, dus ik krijg niet alle voordelen die ik zou kunnen hebben. Onze code is ook niet afhankelijk van dynamische bemonstering. Het is dus veilig voor mij om dit uit te schakelen.
Nadat ik de parameter had gewijzigd, zag ik een onmiddellijke verandering zoals hieronder weergegeven.

De rode lijn geeft het tijdstip aan waarop ik de wijziging heb aangebracht. Het is duidelijk dat de ASH-versie van deze query niet meer wordt uitgevoerd. De V$SQL-versie wordt nog steeds uitgevoerd, maar ziet geen parallelle wachtgebeurtenissen meer. Het verbruikt nu meestal alleen de CPU. Ik beschouw deze vooruitgang, maar geen volledige oplossing.
Even terzijde:ik had alle functies van Adaptive Query Optimization als volgt kunnen uitschakelen:
alter system set optimizer_adaptive_features=false scope=both;
Maar ik weet wel dat ik vragen heb die "genieten van" Adaptive Join Optimization en ik wil het niet allemaal uitschakelen, alleen dynamische sampling.
Dus wat nu te doen met SQL-ID frjd8zfy2jfdq? Laten we kijken of we het resterende probleem kunnen oplossen. Van een van de MOS-notities die ik hierboven heb gelinkt, weet ik dat we deze verborgen parameter kunnen instellen:
alter system set "_optimizer_dsdir_usage_control"=0 scope=both;wijzigen
De standaardwaarde voor deze verborgen parameter was 126 in mijn 12.1.0.2-systeem. Ik vond de standaardinstelling met het volgende:
select a.ksppinm name, b.ksppstvl value, b.ksppstdf deflt,
from
sys.x$ksppi a,
sys.x$ksppcv b
where a.indx = b.indx
and a.ksppinm like '\_%' escape '\'
and a.ksppinm like '%dsdir%'
order by name;
Deze waarde is belangrijk voor het geval ik hem terug wil zetten zonder de parameter uit de SPFILE te hoeven halen, wat downtime zou vergen.
Ik kan nu doorgaan met het wijzigen van deze verborgen parameter en deze op nul zetten. Hier is hoe die SQL-instructie eruitziet in Lighty na de wijziging:

Het lijkt erop dat de "missie volbracht" is om te voorkomen dat die twee SQL-instructies worden uitgevoerd.
Degenen die 12.1.0.2 op Oracle RAC uitvoeren, willen misschien controleren of deze twee SQL-instructies zelf geen prestatieproblemen veroorzaken.
Dit lijkt een van die gevallen te zijn waarin een functie die de prestaties zou moeten verbeteren, in feite het tegenovergestelde doet.