Dit is een veel voorkomend probleem.
Effen B-Tree indexen zijn niet goed voor dit soort zoekopdrachten:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Een index is goed om de waarden binnen de gegeven grenzen te zoeken, zoals deze:
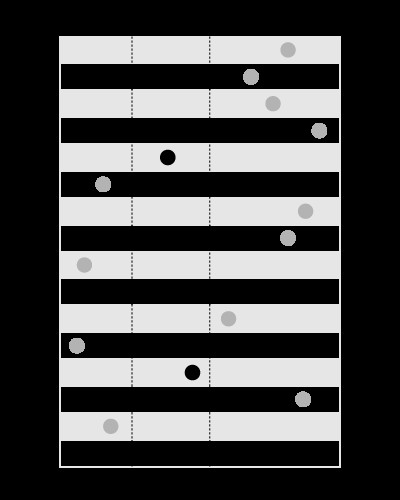
, maar niet om de grenzen te zoeken die de gegeven waarde bevatten, zoals dit:
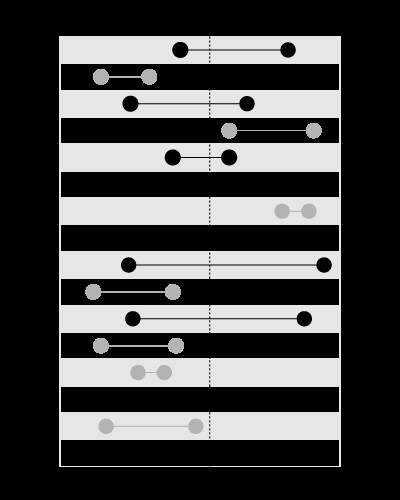
Dit artikel in mijn blog legt het probleem in meer detail uit:
(het geneste sets-model behandelt het vergelijkbare type predikaat).
U kunt de index maken op time , op deze manier de intervals leidend zal zijn in de join, wordt de afstandstijd gebruikt binnen de geneste lussen. Dit vereist sorteren op time .
U kunt een ruimtelijke index maken op intervals (beschikbaar in MySQL met behulp van MyISAM opslag) die start . zou bevatten en end in één geometriekolom. Op deze manier measures kan leiden in de samenvoeging en sorteren is niet nodig.
De ruimtelijke indexen zijn echter langzamer, dus dit is alleen efficiënt als je weinig maten maar veel intervallen hebt.
Aangezien je weinig intervallen hebt maar veel maten, zorg er dan voor dat je een index hebt op measures.time :
CREATE INDEX ix_measures_time ON measures (time)
Bijwerken:
Hier is een voorbeeldscript om te testen:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
Deze vraag:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
gebruikt NESTED LOOPS en keert terug in 1.7 seconden.
Deze vraag:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
gebruikt MERGE JOIN en ik moest ermee stoppen na 5 minuten.
Update 2:
U zult hoogstwaarschijnlijk de engine moeten forceren om de juiste tabelvolgorde in de join te gebruiken met een hint als deze:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Het Oracle 's optimizer is niet slim genoeg om te zien dat de intervallen elkaar niet kruisen. Daarom zal het hoogstwaarschijnlijk measures . gebruiken als een leidende tabel (wat een verstandige beslissing zou zijn als de intervallen elkaar kruisen).
Update 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
Deze query splitst de tijdas in de bereiken en gebruikt een HASH JOIN om de metingen en tijdstempels op de bereikwaarden samen te voegen, met later fijn filteren.
Zie dit artikel in mijn blog voor meer gedetailleerde uitleg over hoe het werkt: