Het beheren van een PostgreSQL-installatie omvat inspectie en controle over een breed scala aan aspecten in de software/infrastructuurstack waarop PostgreSQL draait. Dit moet betrekking hebben op:
- Toepassing afstemmen met betrekking tot databasegebruik/transacties/verbindingen
- Databasecode (query's, functies)
- Databasesysteem (prestaties, HA, back-ups)
- Hardware/infrastructuur (schijven, CPU/geheugen)
De PostgreSQL-kern biedt de databaselaag waarop we vertrouwen dat onze gegevens worden opgeslagen, verwerkt en geserveerd. Het biedt ook alle technologie voor een echt modern, efficiënt, betrouwbaar en veilig systeem. Maar vaak is deze technologie niet beschikbaar als een gebruiksklaar, verfijnd business/enterprise class-product in de kerndistributie van PostgreSQL. In plaats daarvan zijn er veel producten/oplossingen van de PostgreSQL-gemeenschap of commerciële aanbiedingen die aan deze behoeften voldoen. Die oplossingen komen ofwel als gebruiksvriendelijke verfijningen van de kerntechnologieën, of uitbreidingen van de kerntechnologieën of zelfs als integratie tussen PostgreSQL-componenten en andere componenten van het systeem. In onze vorige blog getiteld Tien tips om met PostgreSQL in productie te gaan, hebben we gekeken naar enkele van die tools die kunnen helpen bij het beheren van een PostgreSQL-installatie in productie. In deze blog gaan we dieper in op de aspecten die aan bod moeten komen bij het beheren van een PostgreSQL-installatie in productie, en de meest gebruikte tools daarvoor. We zullen de volgende onderwerpen behandelen:
- Implementatie
- Beheer
- Schaal
- Bewaking
Implementatie
Vroeger downloadden en compileerden mensen PostgreSQL met de hand en configureerden ze vervolgens de runtime-parameters en gebruikerstoegangscontrole. Er zijn nog steeds gevallen waarin dit nodig kan zijn, maar naarmate systemen volwassener werden en begonnen te groeien, ontstond de behoefte aan meer gestandaardiseerde manieren om Postgresql te implementeren en te beheren. De meeste besturingssystemen bieden pakketten voor het installeren, implementeren en beheren van PostgreSQL-clusters. Debian heeft zijn eigen systeemlay-out gestandaardiseerd en ondersteunt veel Postgresql-versies en tegelijkertijd veel clusters per versie. postgresql-common debian-pakket biedt de benodigde hulpmiddelen. Om bijvoorbeeld een nieuw cluster te maken (i18n_cluster genaamd) voor PostgreSQL versie 10 in Debian, kunnen we dit doen door de volgende opdrachten te geven:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsVernieuw vervolgens het systeem:
$ sudo systemctl daemon-reloaden tenslotte start en gebruik je het nieuwe cluster:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(merk op dat Debian verschillende clusters verwerkt door het gebruik van verschillende poorten 5432, 5433 enzovoort)
Naarmate de behoefte aan meer geautomatiseerde en massale implementaties groeit, gebruiken steeds meer installaties automatiseringstools zoals Ansible, Chef en Puppet. Naast automatisering en reproduceerbaarheid van implementaties, zijn automatiseringstools geweldig omdat ze een leuke manier zijn om de implementatie en configuratie van een cluster te documenteren. Aan de andere kant is automatisering geëvolueerd tot een groot vakgebied op zich, waarvoor bekwame mensen nodig zijn om geautomatiseerde scripts te schrijven, te beheren en uit te voeren. Meer informatie over PostgreSQL-provisioning vindt u in deze blog:Word een PostgreSQL DBA:Provisioning and Deployment.
Beheer
Het beheren van een live-systeem omvat taken als:back-ups plannen en de status ervan bewaken, noodherstel, configuratiebeheer, beheer van hoge beschikbaarheid en automatische failover-afhandeling. Het maken van een back-up van een Postgresql-cluster kan op verschillende manieren. Hulpmiddelen op laag niveau:
- traditionele pg_dump (logische back-up)
- back-ups op bestandssysteemniveau (fysieke back-up)
- pg_basebackup (fysieke back-up)
Of hoger niveau:
- Barman
- PgBackRest
Elk van deze manieren omvat verschillende gebruiksscenario's en herstelscenario's en varieert in complexiteit. PostgreSQL-back-up is nauw verwant aan de begrippen PITR, WAL-archivering en replicatie. Door de jaren heen is de procedure van het maken, testen en uiteindelijk (vingers gekruist!) gebruiken van back-ups met PostgreSQL een complexe taak geworden. Een mooi overzicht van de back-upoplossingen voor PostgreSQL vindt u in deze blog:Top Backup Tools for PostgreSQL.
Wat betreft hoge beschikbaarheid en automatische failover is het absolute minimum dat een installatie moet hebben om dit te implementeren:
- Een werkende primary
- Een hot-standby die WAL accepteert gestreamd vanaf de primaire
- In het geval van een mislukte primaire, een methode om de primaire te vertellen dat deze niet langer de primaire is (soms STONITH genoemd)
- Een hartslagmechanisme om de connectiviteit tussen de twee servers en de gezondheid van de primaire te controleren
- Een methode om de failover uit te voeren (bijvoorbeeld via pg_ctl-promotie of triggerbestand)
- Een geautomatiseerde procedure voor het recupereren van de oude primaire als een nieuwe standby:zodra een storing of storing op de primaire is gedetecteerd, moet een standby worden gepromoot als de nieuwe primaire. De oude primaire is niet langer geldig of bruikbaar. Het systeem moet dus een manier hebben om met deze toestand om te gaan tussen de failover en het opnieuw maken van de oude primaire server als de nieuwe stand-by. Deze staat wordt gedegenereerde staat genoemd en de PostgreSQL biedt een tool met de naam pg_rewind om het proces van het terugbrengen van de oude primary naar de synchrone staat van de nieuwe primary te versnellen.
- Een methode om on-demand/geplande omschakelingen uit te voeren
Een veelgebruikte tool die al het bovenstaande afhandelt, is Repmgr. We zullen de minimale setup beschrijven die een succesvolle omschakeling mogelijk maakt. We beginnen met een werkende primaire PostgreSQL 10.4 die draait op FreeBSD 11.1, handmatig gebouwd en geïnstalleerd, en repmgr 4.0 ook handmatig gebouwd en geïnstalleerd voor deze versie (10.4). We zullen twee hosts gebruiken genaamd fbsd (192.168.1.80) en fbsdclone (192.168.1.81) met identieke versies van PostgreSQL en repmgr. Op de primaire (aanvankelijk fbsd , 192.168.1.80) zorgen we ervoor dat de volgende PostgreSQL-parameters zijn ingesteld:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Vervolgens maken we de repmgr-gebruiker (als superuser) en database aan:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgren stel hostgebaseerde toegangscontrole in pg_hba.conf in door de volgende regels bovenaan te plaatsen:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustWe zorgen ervoor dat we wachtwoordloze login voor gebruiker repmgr instellen in alle knooppunten van het cluster, in ons geval fbsd en fbsdclone door geautoriseerde_sleutels in te stellen in .ssh en vervolgens .ssh te delen. Vervolgens maken we repmrg.conf op de primaire aan als:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Dan registreren we de primaire:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredEn controleer de status van het cluster:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2We werken nu aan de stand-by door repmgr.conf als volgt in te stellen:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'We zorgen er ook voor dat de gegevensdirectory die net in de bovenstaande regel is gespecificeerd, bestaat, leeg is en de juiste rechten heeft:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataWe moeten nu klonen naar onze nieuwe stand-by:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"En start de standby:
example@sqldat.com:~ % pg_ctl -D data startOp dit moment zou de replicatie moeten werken zoals verwacht. Controleer dit door pg_stat_replication (fbsd) en pg_stat_wal_receiver (fbsdclone) op te vragen. De volgende stap is het registreren van de stand-by:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerNu kunnen we de status van het cluster op ofwel de stand-by of de primaire krijgen en controleren of de stand-by is geregistreerd:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Laten we nu aannemen dat we een geplande handmatige omschakeling willen uitvoeren om b.v. om wat administratief werk te doen op node fbsd. Op het standby-knooppunt voeren we de volgende opdracht uit:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyDe omschakeling is succesvol uitgevoerd! Laten we eens kijken wat de clustershow geeft:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2De twee servers hebben van rol gewisseld! Repmgr biedt repmgrd-daemon die bewaking, automatische failover en meldingen/waarschuwingen biedt. Door repmgrd te combineren met pgbouncer, is het mogelijk om automatische update van de verbindingsinformatie van de database te implementeren, waardoor een hekwerk wordt geboden voor de mislukte primaire (waardoor wordt voorkomen dat het defecte knooppunt door de toepassing wordt gebruikt) en voor minimale downtime voor de toepassing. In meer complexe schema's is een ander idee om Keepalived te combineren met HAProxy bovenop pgbouncer en repmgr, om het volgende te bereiken:
- load balancing (schalen)
- hoge beschikbaarheid
Merk op dat ClusterControl ook de failover van PostgreSQL-replicatie-instellingen beheert en HAProxy en VirtualIP integreert om clientverbindingen automatisch om te leiden naar de werkende master. Meer informatie vindt u in deze whitepaper over PostgreSQL-automatisering.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperSchaal
Vanaf PostgreSQL 10 (en 11) is er nog steeds geen manier om multi-master replicatie te hebben, althans niet vanuit de kern van PostgreSQL. Dit betekent dat alleen de select(read-only) activiteit kan worden opgeschaald. Schalen in PostgreSQL wordt bereikt door meer hot-standby's toe te voegen, waardoor er meer bronnen worden geboden voor alleen-lezen-activiteiten. Met repmgr is het eenvoudig om nieuwe standby toe te voegen zoals we eerder zagen via standby clone en stand-by register commando's. Toegevoegde (of verwijderde) stand-by's moeten kenbaar worden gemaakt aan de configuratie van de load-balancer. HAProxy, zoals hierboven vermeld in het beheeronderwerp, is een populaire load balancer voor PostgreSQL. Meestal is het gekoppeld aan Keepalive, dat virtuele IP biedt via VRRP. Een mooi overzicht van het gebruik van HAProxy en Keepalive samen met PostgreSQL vindt u in dit artikel:PostgreSQL Load Balancing Using HAProxy &Keepalive.
Bewaking
Een overzicht van wat u in PostgreSQL moet controleren, vindt u in dit artikel:Belangrijkste dingen om te controleren in PostgreSQL - Analyse van uw werklast. Er zijn veel tools die systeem- en postgresql-monitoring kunnen bieden via plug-ins. Sommige tools bestrijken het gebied van het presenteren van grafische grafieken van historische waarden (munin), andere tools bestrijken het gebied van het monitoren van live gegevens en het geven van live waarschuwingen (nagios), terwijl sommige tools beide gebieden bestrijken (zabbix). Een lijst van dergelijke tools voor PostgreSQL is hier te vinden:https://wiki.postgresql.org/wiki/Monitoring. Een populaire tool voor offline (op logbestanden gebaseerde) monitoring is pgBadger. pgBadger is een Perl-script dat werkt door het PostgreSQL-logboek te ontleden (dat meestal de activiteit van één dag beslaat), informatie te extraheren, statistieken te berekenen en ten slotte een fraaie html-pagina te produceren met de resultaten. pgBadger is niet beperkend voor de instelling log_line_prefix, het kan zich aanpassen aan uw reeds bestaande formaat. Als u bijvoorbeeld iets in uw postgresql.conf hebt ingesteld als:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'dan kan het pgbadger-commando om het logbestand te ontleden en de resultaten te produceren er als volgt uitzien:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger levert rapporten voor:
- Overzichtsstatistieken (voornamelijk SQL-verkeer)
- Verbindingen (per seconde, per database/gebruiker/host)
- Sessies (aantal, sessietijden, per database/gebruiker/host/applicatie)
- Checkpoints (buffers, walbestanden, activiteit)
- Gebruik van tijdelijke bestanden
- Vacuüm/analyse-activiteit (per tabel, tupels/pagina's verwijderd)
- Sloten
- Query's (op type/database/gebruiker/host/toepassing, duur per gebruiker)
- Top (query's:langzaamste, tijdrovende, frequentere, genormaliseerde langzaamste)
- Gebeurtenissen (Fouten, Waarschuwingen, Fatals, enz.)
Het scherm met de sessies ziet er als volgt uit:
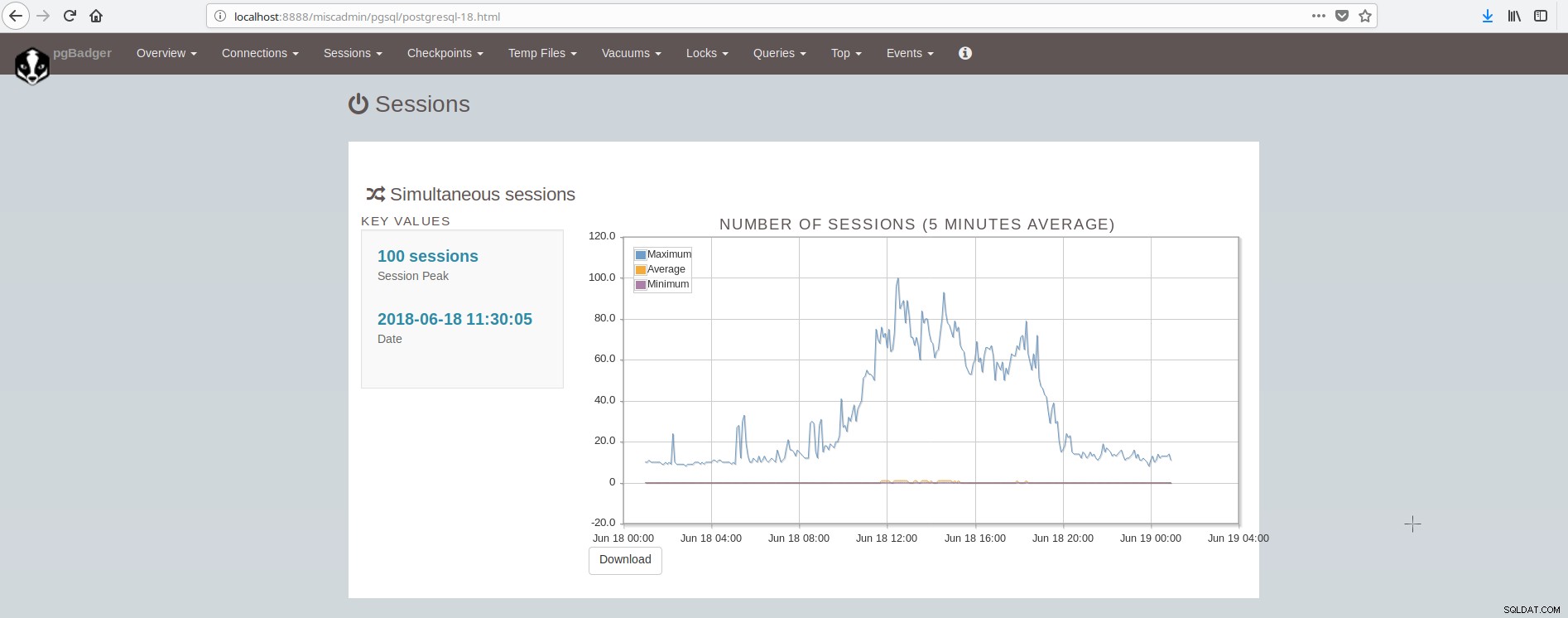
Zoals we kunnen concluderen, moet de gemiddelde PostgreSQL-installatie veel tools integreren en verzorgen om een moderne, betrouwbare en snelle infrastructuur te hebben en dit is vrij complex om te bereiken, tenzij er grote teams betrokken zijn bij postgresql en systeembeheer. Een prima suite die al het bovenstaande en meer doet, is ClusterControl.