Werkend in de IT-industrie hebben we het woord "failover" waarschijnlijk vaak gehoord, maar het kan ook vragen oproepen als:wat is eigenlijk een failover? Waar kunnen we het voor gebruiken? Is het belangrijk om het te hebben? Hoe kunnen we het doen?
Hoewel het vrij basale vragen lijken, is het belangrijk om er in elke databaseomgeving rekening mee te houden. En vaker wel dan niet, houden we geen rekening met de basis...
Laten we om te beginnen eens kijken naar enkele basisconcepten.
Wat is failover?
Failover is het vermogen van een systeem om te blijven functioneren, zelfs als er een storing optreedt. Het suggereert dat de functies van het systeem worden overgenomen door secundaire componenten als de primaire componenten falen.
In het geval van PostgreSQL zijn er verschillende tools waarmee u een databasecluster kunt implementeren die bestand is tegen storingen. Een redundantiemechanisme dat native beschikbaar is in PostgreSQL is replicatie. En de nieuwigheid in PostgreSQL 10 is de implementatie van logische replicatie.
Wat is replicatie?
Het is het proces van het kopiëren en bijwerken van de gegevens in een of meer databaseknooppunten. Het maakt gebruik van een concept van een hoofdknooppunt dat de wijzigingen ontvangt, en slaafknooppunten waar ze worden gerepliceerd.
We hebben verschillende manieren om replicatie te categoriseren:
- Synchrone replicatie:er is geen verlies van gegevens, zelfs niet als onze master-node verloren gaat, maar de commits in de master moeten wachten op een bevestiging van de slave, wat de prestaties kan beïnvloeden.
- Asynchrone replicatie:er is een mogelijkheid van gegevensverlies als we ons hoofdknooppunt verliezen. Als de replica om de een of andere reden niet wordt bijgewerkt op het moment van het incident, kan de informatie die niet is gekopieerd, verloren gaan.
- Fysieke replicatie:schijfblokken worden gekopieerd.
- Logische replicatie:streaming van de gegevenswijzigingen.
- Warme standby-slaves:ze ondersteunen geen verbindingen.
- Hot Standby Slaves:ondersteuning voor alleen-lezen verbindingen, handig voor rapporten of vragen.
Waar wordt failover voor gebruikt?
Er zijn verschillende mogelijke toepassingen van failover. Laten we wat voorbeelden bekijken.
Migratie
Als we van het ene datacenter naar het andere willen migreren door onze downtime te minimaliseren, kunnen we failover gebruiken.
Stel dat onze master zich in datacenter A bevindt, en we willen onze systemen migreren naar datacenter B.
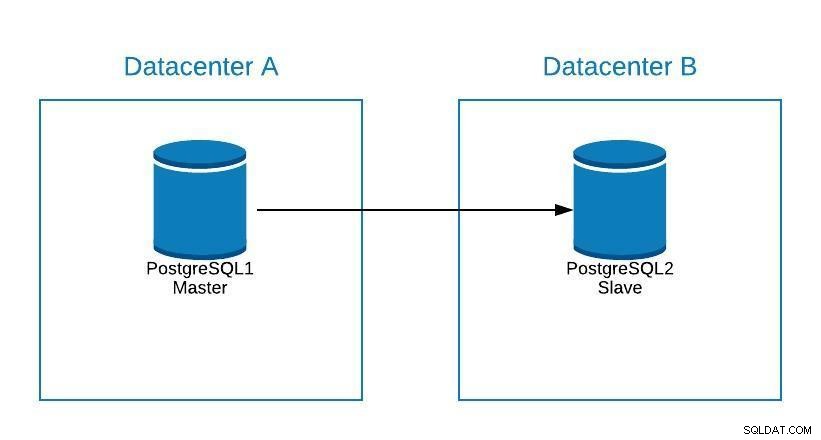 Migratiediagram 1
Migratiediagram 1 We kunnen een replica maken in datacenter B. Als het eenmaal is gesynchroniseerd, moeten we ons systeem stoppen, onze replica promoveren naar een nieuwe master en failover, voordat we ons systeem naar de nieuwe master in datacenter B verwijzen.
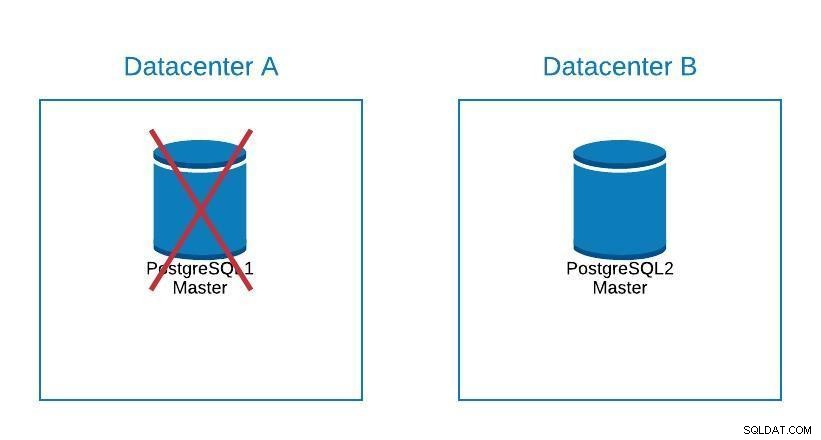 Migratiediagram 2
Migratiediagram 2 Failover gaat niet alleen over de database, maar ook over de applicatie(s). Hoe weten ze met welke database ze verbinding moeten maken? We willen onze applicatie zeker niet moeten wijzigen, omdat dit onze downtime alleen maar zal verlengen. We kunnen dus een load balancer configureren zodat wanneer we onze master uitschakelen, deze automatisch naar de volgende server verwijst die wordt gepromoveerd.
Een andere optie is het gebruik van DNS. Door de masterreplica in het nieuwe datacenter te promoten, wijzigen we direct het IP-adres van de hostnaam die naar de master verwijst. Op deze manier vermijden we dat we onze applicatie moeten aanpassen, en hoewel het niet automatisch kan, is het een alternatief als we geen load balancer willen implementeren.
Het hebben van een enkele load balancer-instantie is niet geweldig, omdat het een single point of failure kan worden. Daarom kunt u ook een failover voor de load balancer implementeren met een service zoals keepalive. Op deze manier, als we een probleem hebben met onze primaire load balancer, is keepalive verantwoordelijk voor het migreren van het IP naar onze secundaire load balancer, en blijft alles transparant werken.
Onderhoud
Als we onderhoud moeten uitvoeren aan onze postgreSQL-masterdatabaseserver, kunnen we onze slave promoten, de taak uitvoeren en een slave reconstrueren op onze oude master.
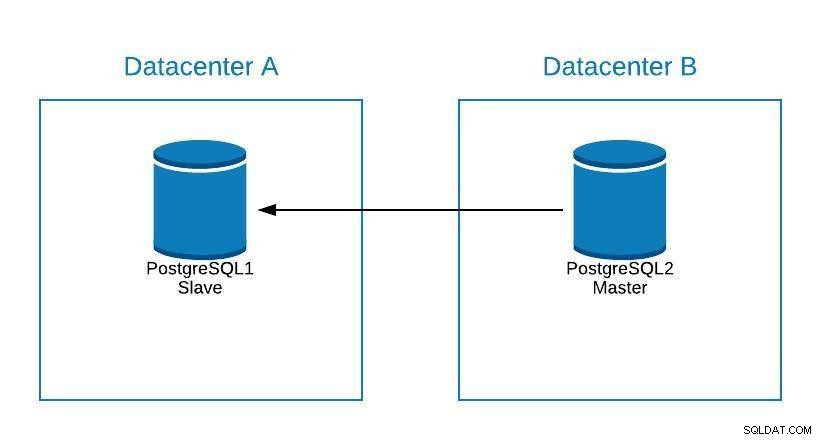 Onderhoudsdiagram 1
Onderhoudsdiagram 1 Hierna kunnen we de oude master opnieuw promoten en het reconstructieproces van de slave herhalen, waarbij we terugkeren naar de oorspronkelijke staat.
Onderhoudsdiagram 2 Op deze manier konden we op onze server werken, zonder het risico te lopen offline te zijn of informatie te verliezen tijdens het uitvoeren van onderhoud.
Upgraden
Hoewel PostgreSQL 11 nog niet beschikbaar is, zou het technisch mogelijk zijn om te upgraden van PostgreSQL versie 10, met behulp van logische replicatie, zoals dat wel kan met andere engines.
De stappen zouden hetzelfde zijn als om te migreren naar een nieuw datacenter (zie Migratiesectie), alleen dat onze slaaf zich in PostgreSQL 11 zou bevinden.
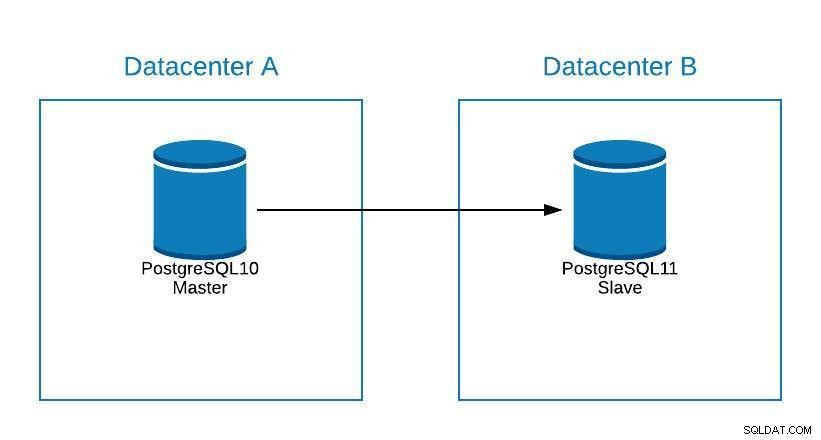 Diagram 1 upgraden
Diagram 1 upgraden Problemen
De belangrijkste functie van de failover is om onze downtime te minimaliseren of verlies van informatie te voorkomen als u een probleem heeft met onze hoofddatabase.
Als we om de een of andere reden onze masterdatabase kwijtraken, kunnen we een failover uitvoeren om onze slave naar master te promoten en onze systemen draaiende te houden.
Om dit te doen, biedt PostgreSQL ons geen geautomatiseerde oplossing. We kunnen het handmatig doen, of automatiseren door middel van een script of een externe tool.
Om onze slaaf tot meester te promoveren:
-
Voer pg_ctl-promotie uit
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Maak een bestand trigger_file dat we moeten hebben toegevoegd in de recovery.conf van onze datadirectory.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Om een failover-strategie te implementeren, moeten we deze plannen en grondig testen door middel van verschillende faalscenario's. Omdat storingen op verschillende manieren kunnen gebeuren, zou de oplossing idealiter moeten werken voor de meeste veelvoorkomende scenario's. Als we op zoek zijn naar een manier om dit te automatiseren, kunnen we eens kijken wat ClusterControl te bieden heeft.
ClusterControl voor PostgreSQL-failover
ClusterControl heeft een aantal functies met betrekking tot PostgreSQL-replicatie en geautomatiseerde failover.
Slaaf toevoegen
Als we een slave in een ander datacenter willen toevoegen, hetzij als een noodgeval of om uw systemen te migreren, kunnen we naar Clusteracties gaan en Replicatieslave toevoegen selecteren.
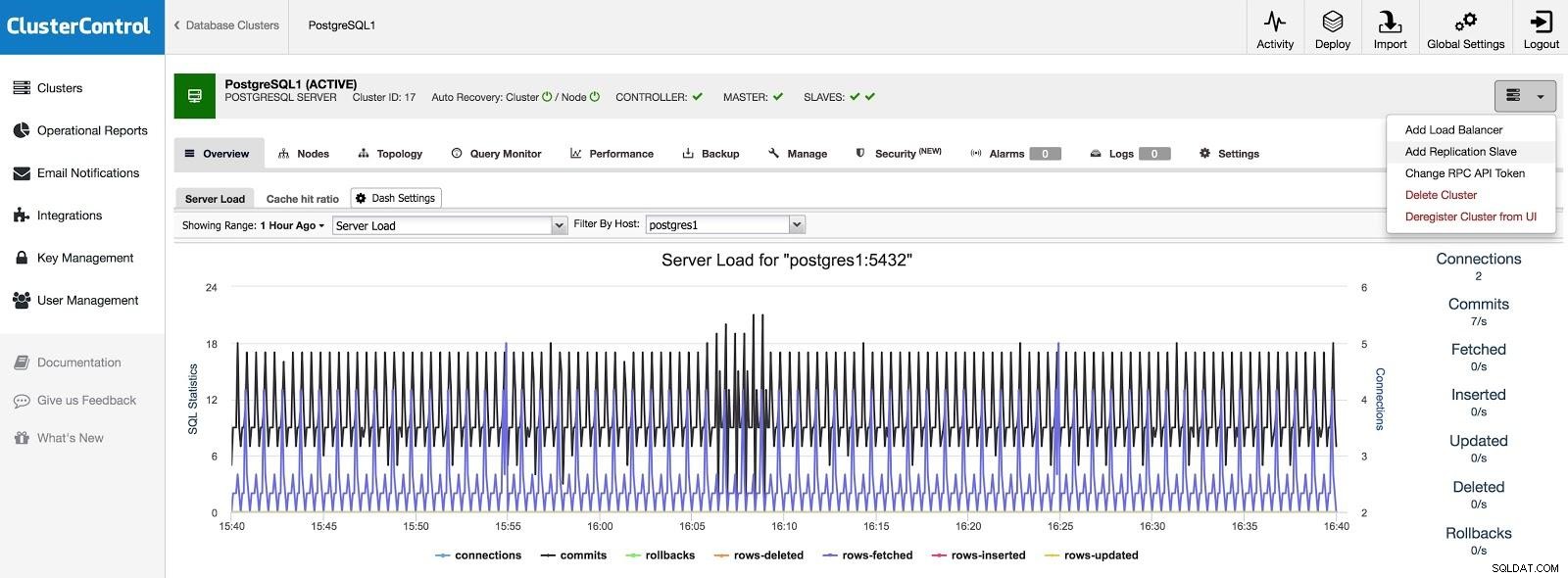 ClusterControl Slave 1 toevoegen
ClusterControl Slave 1 toevoegen We moeten enkele basisgegevens invoeren, zoals IP of hostnaam, gegevensmap (optioneel), synchrone of asynchrone slave. We zouden onze slaaf na een paar seconden aan de gang moeten hebben.
In het geval van gebruik van een ander datacenter, raden we aan om een asynchrone slave te maken, omdat anders de latentie de prestaties aanzienlijk kan beïnvloeden.
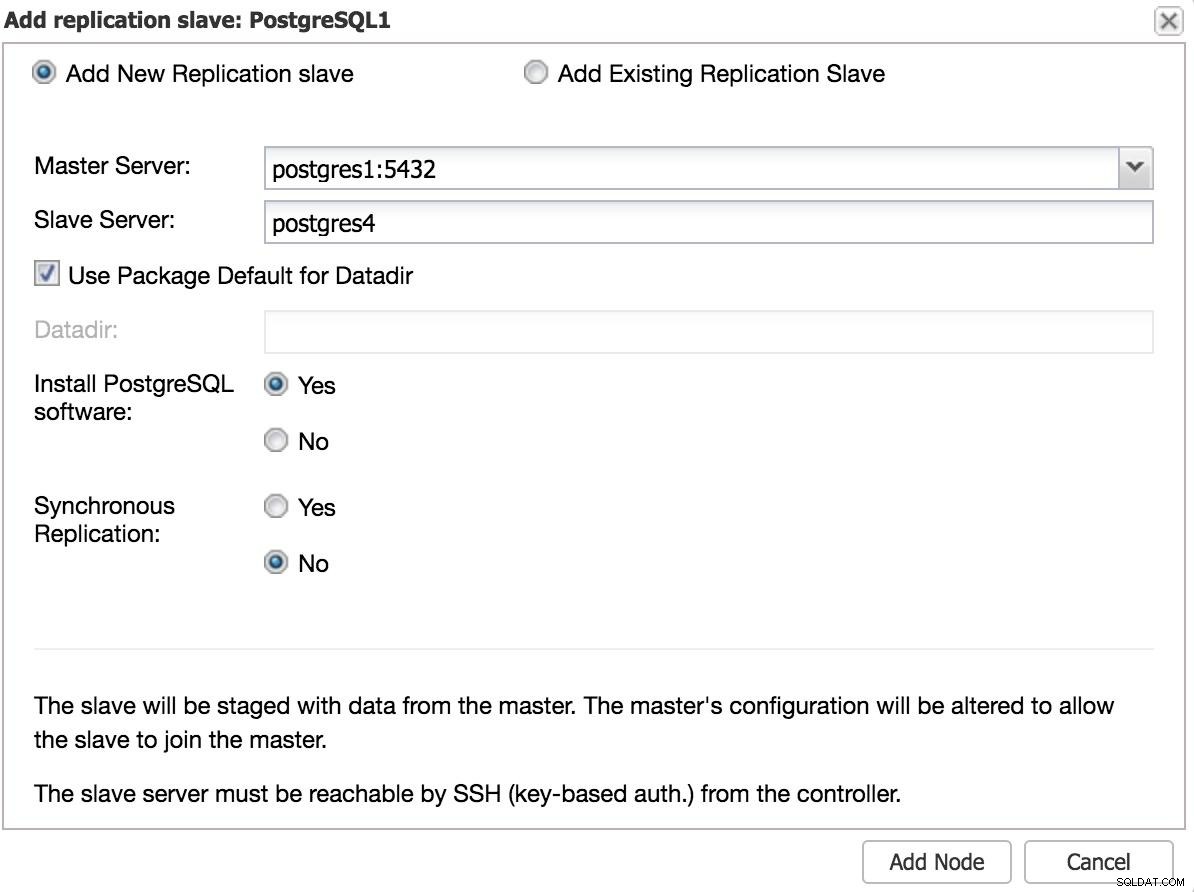 ClusterControl Slave 2 toevoegen
ClusterControl Slave 2 toevoegen Handmatige failover
Met ClusterControl kan failover handmatig of automatisch worden uitgevoerd.
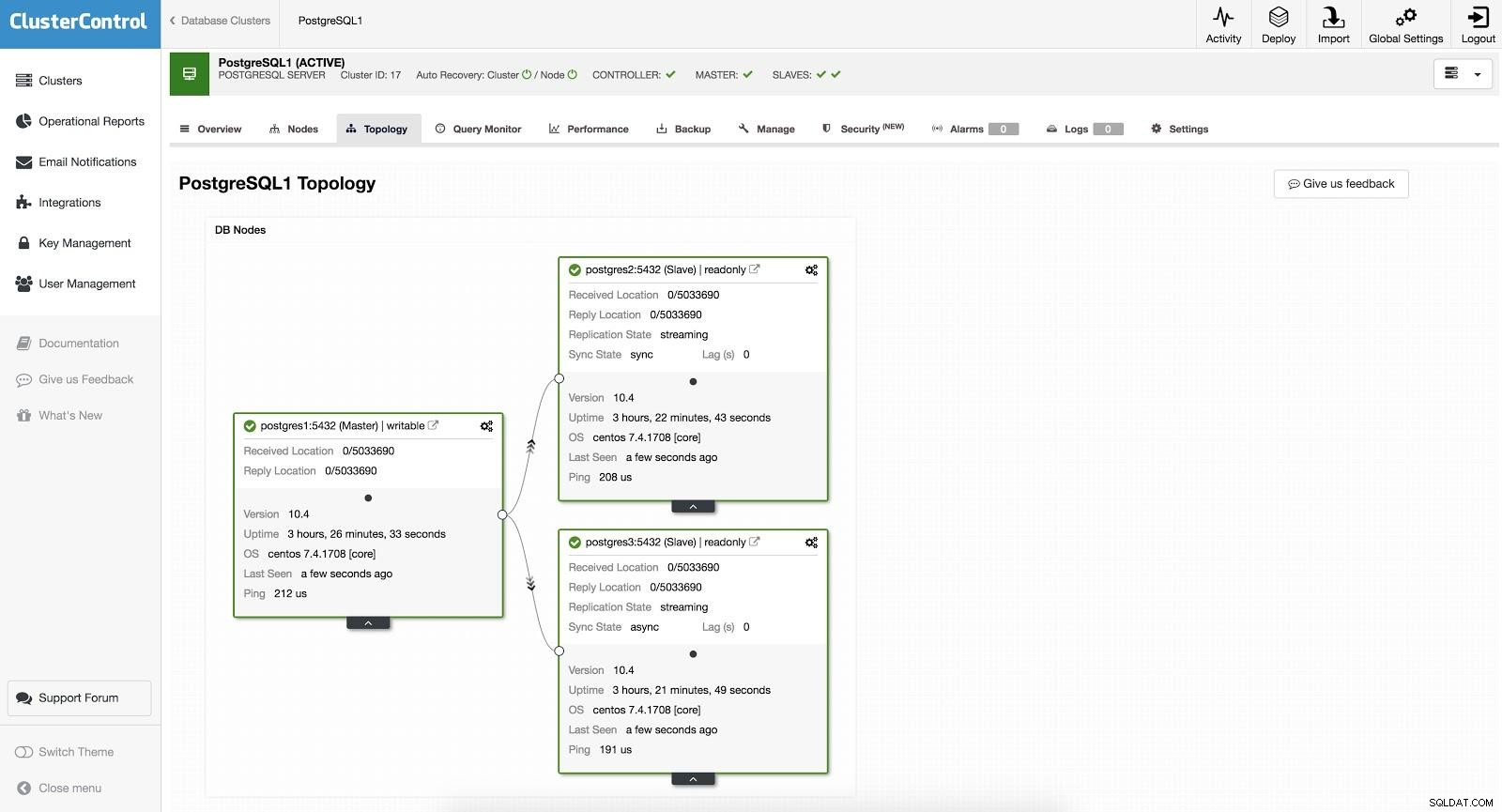 ClusterControl-failover 1
ClusterControl-failover 1 Om een handmatige failover uit te voeren, gaat u naar ClusterControl -> Cluster selecteren -> Nodes en selecteert u in de Action Node van een van onze slaves "Slaaf promoten". Op deze manier wordt onze slaaf na een paar seconden meester en wat voorheen onze meester was, wordt een slaaf.
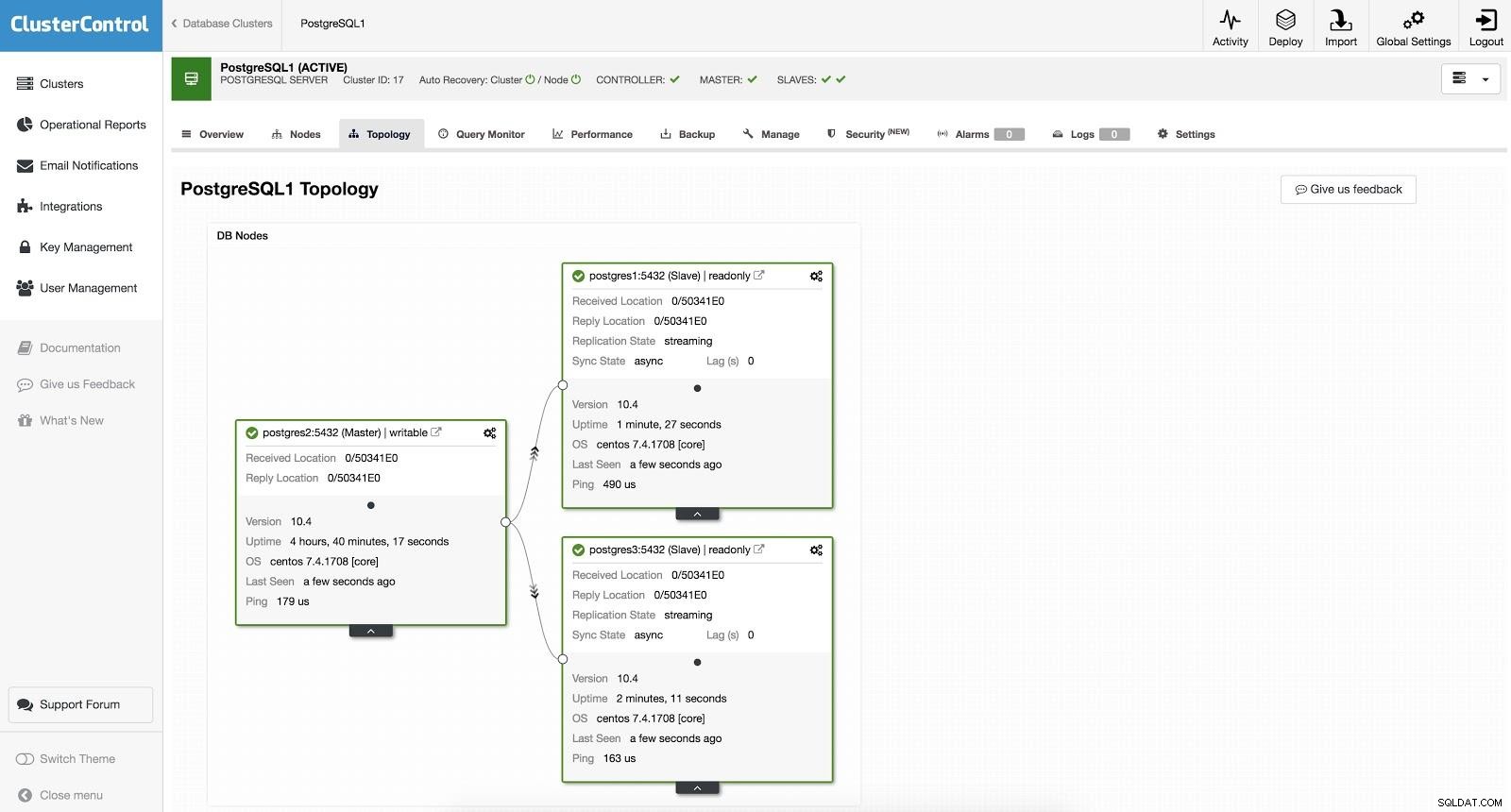 ClusterControl-failover 2
ClusterControl-failover 2 Het bovenstaande is handig voor de taken van migratie, onderhoud en upgrades die we eerder zagen.
Automatische failover
Bij automatische failover detecteert ClusterControl storingen in de master en promoveert een slave met de meest actuele gegevens als nieuwe master. Het werkt ook op de rest van de slaven om ze te repliceren van de nieuwe master.
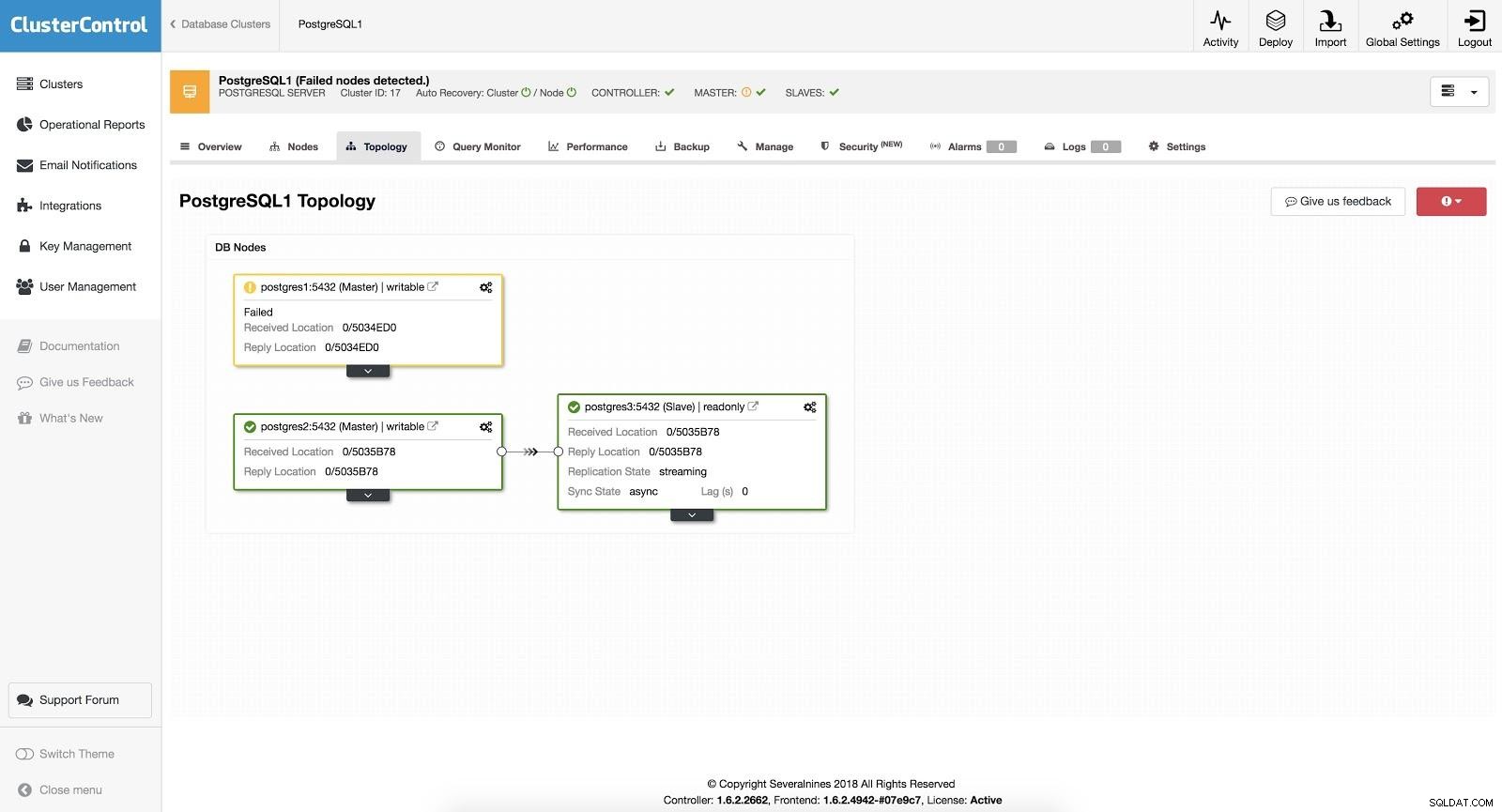 ClusterControl-failover 3
ClusterControl-failover 3 Met de optie "Autorecovery" AAN, zal onze ClusterControl een automatische failover uitvoeren en ons op de hoogte stellen van het probleem. Op deze manier kunnen onze systemen binnen enkele seconden en zonder onze tussenkomst herstellen.
Cluster Control biedt ons de mogelijkheid om een whitelist/blacklist in te stellen om te bepalen hoe we willen dat onze servers al dan niet in aanmerking worden genomen bij het kiezen van een masterkandidaat.
Van degene die beschikbaar zijn volgens de bovenstaande configuratie, zal ClusterControl de meest geavanceerde slave kiezen, voor dit doel gebruikend de pg_current_xlog_location (PostgreSQL 9+) of pg_current_wal_lsn (PostgreSQL 10+), afhankelijk van de versie van onze database.
ClusterControl voert ook verschillende controles uit op het failoverproces om enkele veelvoorkomende fouten te voorkomen. Een voorbeeld is dat als het ons lukt om onze oude mislukte master te herstellen, deze NIET automatisch opnieuw in het cluster wordt geïntroduceerd, noch als master noch als slave. We moeten het handmatig doen. Dit voorkomt de mogelijkheid van gegevensverlies of inconsistentie in het geval dat onze slaaf (die we hebben gepromoot) werd vertraagd op het moment van de storing. We willen het probleem misschien ook in detail analyseren, maar als we het aan ons cluster toevoegen, zouden we mogelijk diagnostische informatie verliezen.
Als de failover mislukt, worden er geen verdere pogingen ondernomen en is handmatige tussenkomst vereist om het probleem te analyseren en de bijbehorende acties uit te voeren. Dit om te voorkomen dat ClusterControl, als high availability manager, de volgende slave en de volgende probeert te promoten. Er kan een probleem zijn en we willen de zaken niet erger maken door meerdere failovers te proberen.
Loadbalancers
Zoals we eerder vermeldden, is de load balancer een belangrijk hulpmiddel om te overwegen voor onze failover, vooral als we automatische failover willen gebruiken in onze databasetopologie.
Om de failover transparant te maken voor zowel de gebruiker als de applicatie, hebben we een component daartussen nodig, aangezien het niet voldoende is om een master naar een slave te promoveren. Hiervoor kunnen we HAProxy + Keepalive gebruiken.
Wat is HAProxy?
HAProxy is een load balancer die verkeer van de ene herkomst naar een of meer bestemmingen verdeelt en voor deze taak specifieke regels en/of protocollen kan definiëren. Als een van de bestemmingen niet meer reageert, wordt deze gemarkeerd als offline en wordt het verkeer naar de overige beschikbare bestemmingen gestuurd. Dit voorkomt dat verkeer naar een ontoegankelijke bestemming wordt gestuurd en voorkomt het verlies van dit verkeer door het naar een geldige bestemming te leiden.
Wat is Keepalive?
Met Keepalived kunt u een virtueel IP configureren binnen een actieve/passieve groep servers. Dit virtuele IP-adres wordt toegewezen aan een actieve "primaire" server. Als deze server uitvalt, wordt het IP automatisch gemigreerd naar de "Secundaire" server die passief bleek te zijn, waardoor deze op een transparante manier voor onze systemen met hetzelfde IP kan blijven werken.
Om deze oplossing met ClusterControl te implementeren, zijn we begonnen alsof we een slave gingen toevoegen. Ga naar Clusteracties en selecteer Load Balancer toevoegen (zie ClusterControl Slave 1-afbeelding toevoegen).
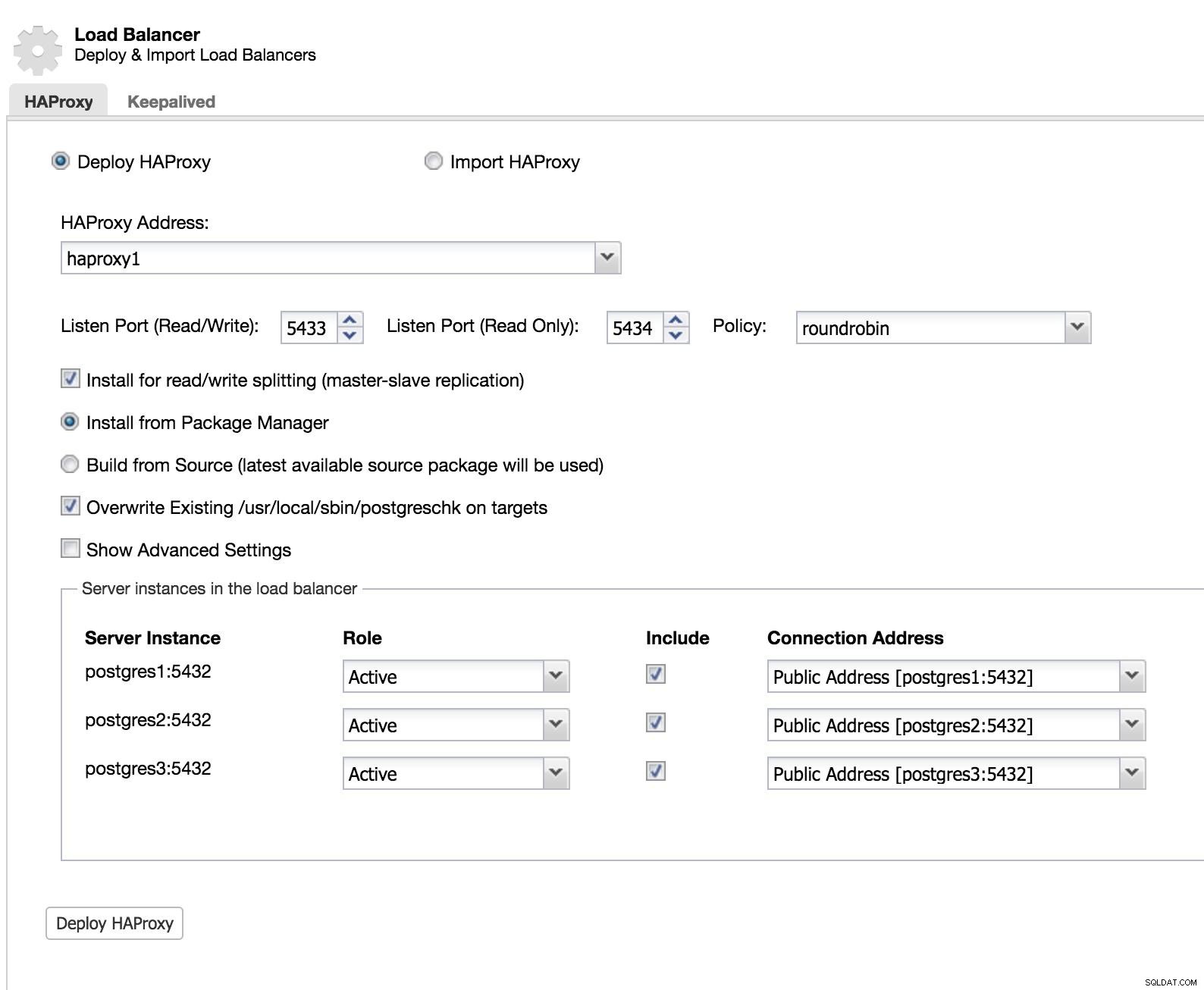 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 We voegen de informatie van onze nieuwe load balancer toe en hoe we willen dat deze zich gedraagt (beleid).
Als we een failover voor onze load balancer willen implementeren, moeten we ten minste twee instanties configureren.
Vervolgens kunnen we Keepalive configureren (Selecteer Cluster -> Beheren -> Load Balancer -> Keepalive).
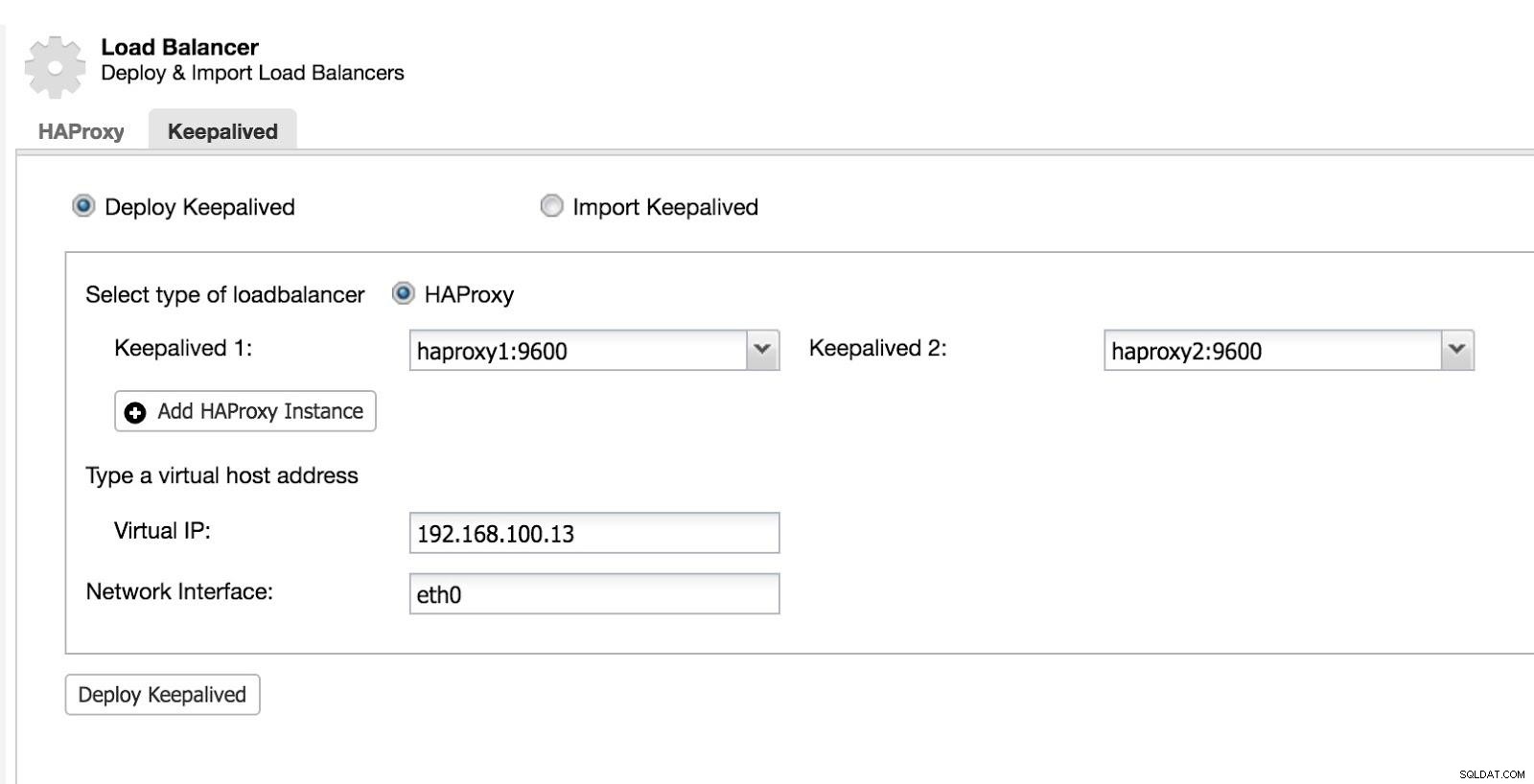 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Hierna hebben we de volgende topologie:
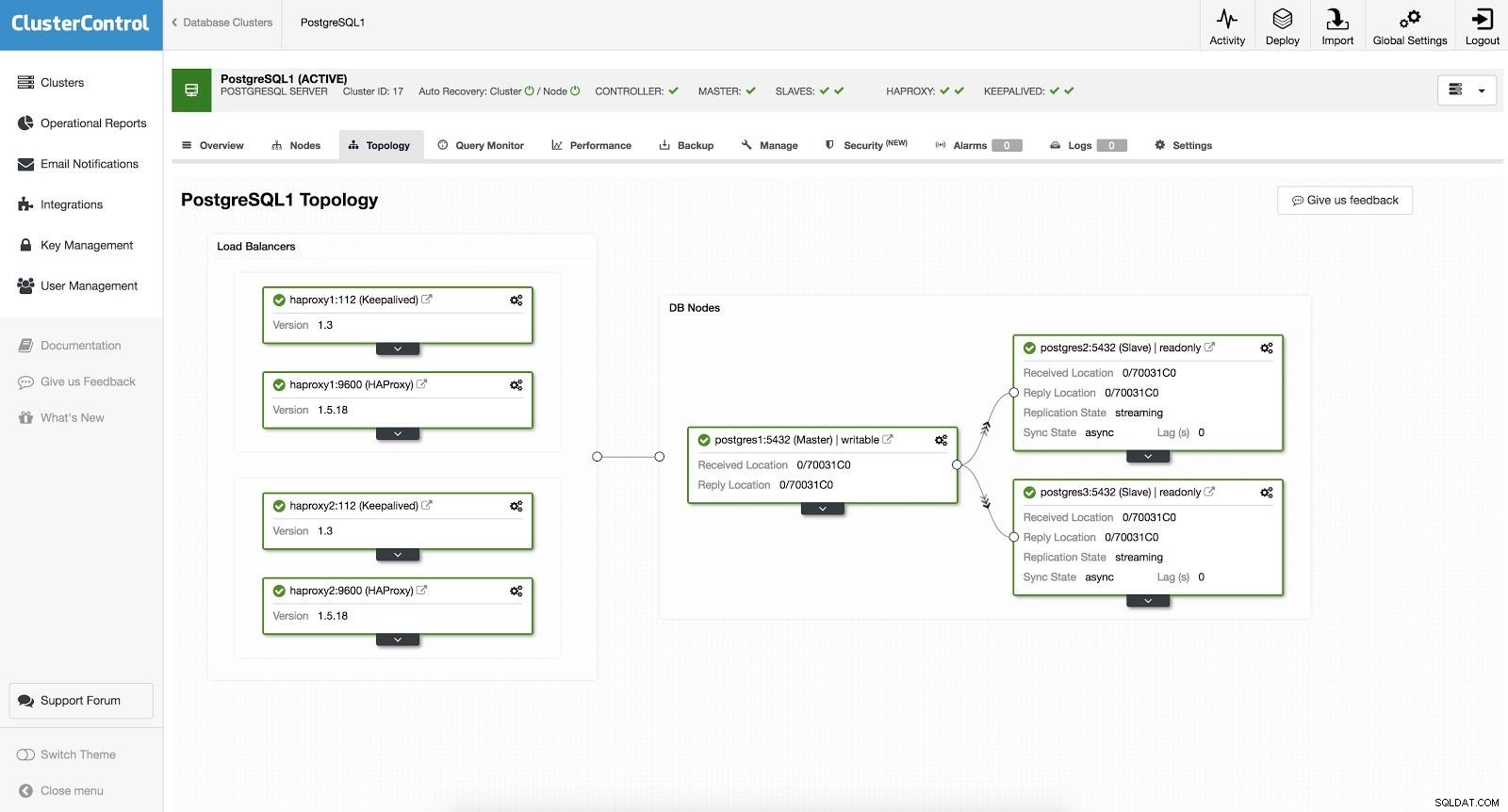 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy is geconfigureerd met twee verschillende poorten, een lezen-schrijven en een alleen-lezen.
In onze lees-schrijfpoort hebben we onze hoofdserver als online en de rest van onze knooppunten als offline. In de read-only poort hebben we zowel de master als de slaves online. Op deze manier kunnen we het leesverkeer tussen onze nodes balanceren. Bij het schrijven wordt de lees-schrijfpoort gebruikt, die naar de master wijst.
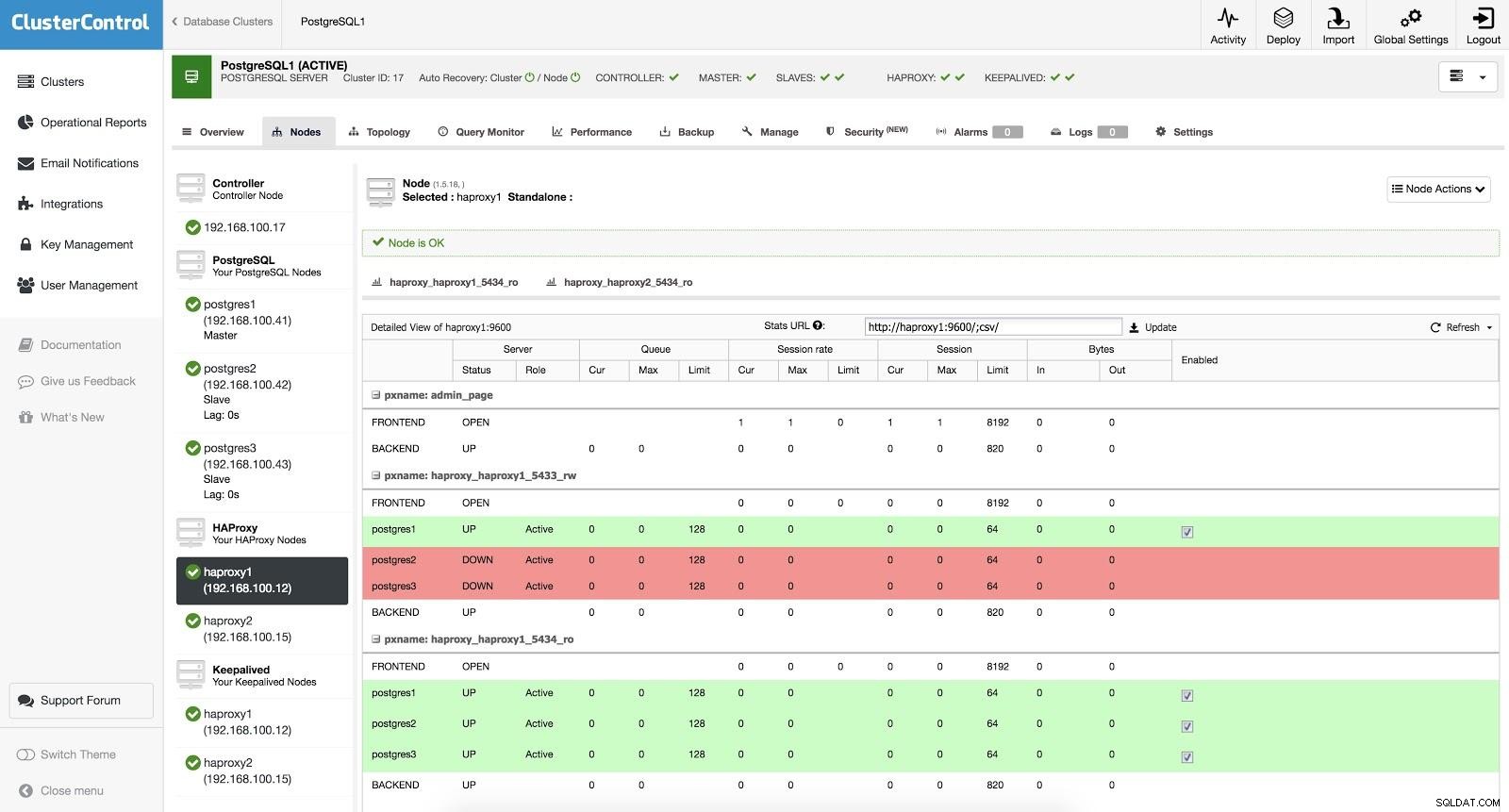 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Wanneer HAProxy detecteert dat een van onze nodes, master of slave, niet toegankelijk is, markeert het deze automatisch als offline. HAProxy zal er geen verkeer naartoe sturen. Deze controle wordt uitgevoerd door scripts voor gezondheidscontrole die zijn geconfigureerd door ClusterControl op het moment van implementatie. Deze controleren of de instanties actief zijn, of ze worden hersteld of alleen-lezen zijn.
Wanneer ClusterControl een slave tot master promoveert, markeert onze HAProxy de oude master als offline (voor beide poorten) en zet het gepromote knooppunt online (in de lees-schrijfpoort). Op deze manier blijven onze systemen normaal werken.
Als onze actieve HAProxy (waaraan een virtueel IP-adres is toegewezen waarmee onze systemen verbinding maken) faalt, migreert Keepalive dit IP automatisch naar onze passieve HAProxy. Dit betekent dat onze systemen dan normaal kunnen blijven functioneren.
Conclusie
Zoals we konden zien, is failover een fundamenteel onderdeel van elke productiedatabase. Het kan handig zijn bij het uitvoeren van algemene onderhoudstaken of migraties. We hopen dat deze blog nuttig is geweest als inleiding tot het onderwerp, zodat u verder kunt gaan met onderzoeken en uw eigen failover-strategieën kunt maken.