Een van de belangrijkste vereisten voor elke database is om schaalbaarheid te bereiken. Dit kan alleen worden bereikt als de stelling (vergrendeling) zo veel mogelijk wordt geminimaliseerd, zo niet allemaal tegelijk. Aangezien lezen / schrijven / bijwerken / verwijderen enkele van de belangrijkste frequente bewerkingen zijn die in de database plaatsvinden, is het erg belangrijk dat deze bewerkingen gelijktijdig plaatsvinden zonder geblokkeerd te worden. Om dit te bereiken, gebruiken de meeste grote databases een gelijktijdigheidsmodel genaamd Multi-Version Concurrency Control, wat twist tot een absoluut minimum reduceert.
Wat is MVCC
Gelijktijdigheidscontrole met meerdere versies (hier en verder MVCC) is een algoritme om nauwkeurige gelijktijdigheidscontrole te bieden door meerdere versies van hetzelfde object te onderhouden, zodat de LEES- en SCHRIJF-bewerkingen niet conflicteren. SCHRIJVEN betekent hier BIJWERKEN en VERWIJDEREN, aangezien een nieuw INGEVOEGD record sowieso wordt beschermd volgens het isolatieniveau. Elke WRITE-bewerking produceert een nieuwe versie van het object en elke gelijktijdige leesbewerking leest een andere versie van het object, afhankelijk van het isolatieniveau. Aangezien lezen en schrijven beide op verschillende versies van hetzelfde object werken, hoeft geen van deze bewerkingen volledig te worden vergrendeld en kunnen beide gelijktijdig worden uitgevoerd. Het enige geval waarin de strijd nog kan bestaan, is wanneer twee gelijktijdige transacties proberen hetzelfde record te SCHRIJVEN.
De meeste van de huidige grote databases ondersteunen MVCC. De bedoeling van dit algoritme is het onderhouden van meerdere versies van hetzelfde object, zodat de implementatie van MVCC alleen verschilt van database tot database in termen van hoe meerdere versies worden gemaakt en onderhouden. Dienovereenkomstig veranderen de bijbehorende databasewerking en opslag van gegevens.
De meest erkende benadering om MVCC te implementeren is die welke wordt gebruikt door PostgreSQL en Firebird/Interbase en een andere die wordt gebruikt door InnoDB en Oracle. In de volgende paragrafen zullen we in detail bespreken hoe het is geïmplementeerd in PostgreSQL en InnoDB.
MVCC in PostgreSQL
Om meerdere versies te ondersteunen, onderhoudt PostgreSQL extra velden voor elk object (Tuple in PostgreSQL-terminologie), zoals hieronder vermeld:
- xmin – Transactie-ID van de transactie die de tuple heeft ingevoegd of bijgewerkt. In het geval van UPDATE wordt een nieuwere versie van de tuple toegewezen met deze transactie-ID.
- xmax – Transactie-ID van de transactie die de tuple heeft verwijderd of bijgewerkt. In het geval van UPDATE krijgt een momenteel bestaande versie van tuple deze transactie-ID toegewezen. Op een nieuw aangemaakte tuple is de standaardwaarde van dit veld null.
PostgreSQL slaat alle gegevens op in een primaire opslag genaamd HEAP (pagina met een standaardgrootte van 8 KB). Alle nieuwe tuple krijgt xmin als een transactie die het heeft gemaakt en en oudere versie tuple (die is bijgewerkt of verwijderd) krijgt xmax toegewezen. Er is altijd een link van de oudere versie tuple naar de nieuwe versie. De tuple met een oudere versie kan worden gebruikt om de tuple opnieuw te maken in geval van terugdraaien en om een oudere versie van een tuple te lezen door middel van een READ-instructie, afhankelijk van het isolatieniveau.
Bedenk dat er twee tupels zijn, T1 (met waarde 1) en T2 (met waarde 2) voor een tabel, het maken van nieuwe rijen kan in de onderstaande 3 stappen worden gedemonstreerd:
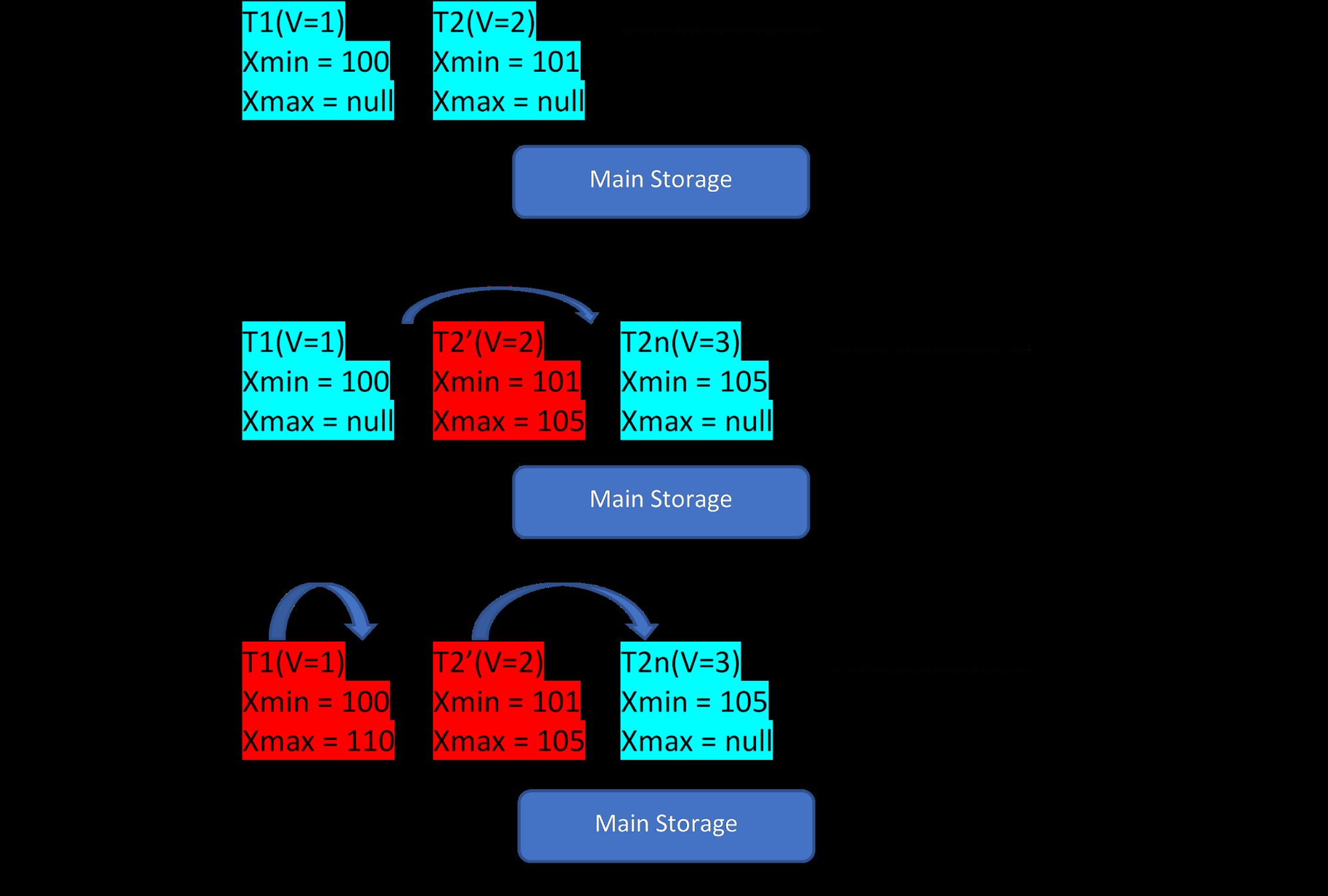 MVCC:opslag van meerdere versies in PostgreSQL
MVCC:opslag van meerdere versies in PostgreSQL Zoals te zien is op de afbeelding, zijn er aanvankelijk twee tuples in de database met waarden 1 en 2.
Vervolgens wordt in de tweede stap de rij T2 met waarde 2 bijgewerkt met de waarde 3. Op dit punt wordt een nieuwe versie gemaakt met de nieuwe waarde en deze wordt gewoon opgeslagen als naast de bestaande tuple in hetzelfde opslaggebied . Daarvoor krijgt de oudere versie xmax toegewezen en verwijst naar de nieuwste versie-tuple.
Evenzo, in de derde stap, wanneer de rij T1 met waarde 1 wordt verwijderd, wordt de bestaande rij virtueel verwijderd (d.w.z. hij heeft zojuist xmax toegewezen aan de huidige transactie) op dezelfde plaats. Hiervoor wordt geen nieuwe versie gemaakt.
Laten we vervolgens eens kijken hoe elke bewerking meerdere versies maakt en hoe het transactie-isolatieniveau wordt gehandhaafd zonder te vergrendelen met enkele echte voorbeelden. In alle onderstaande voorbeelden wordt standaard "READ COMMITTED" isolatie gebruikt.
INSERT
Elke keer dat een record wordt ingevoegd, wordt er een nieuwe tuple gemaakt, die wordt toegevoegd aan een van de pagina's die bij de overeenkomstige tabel horen.
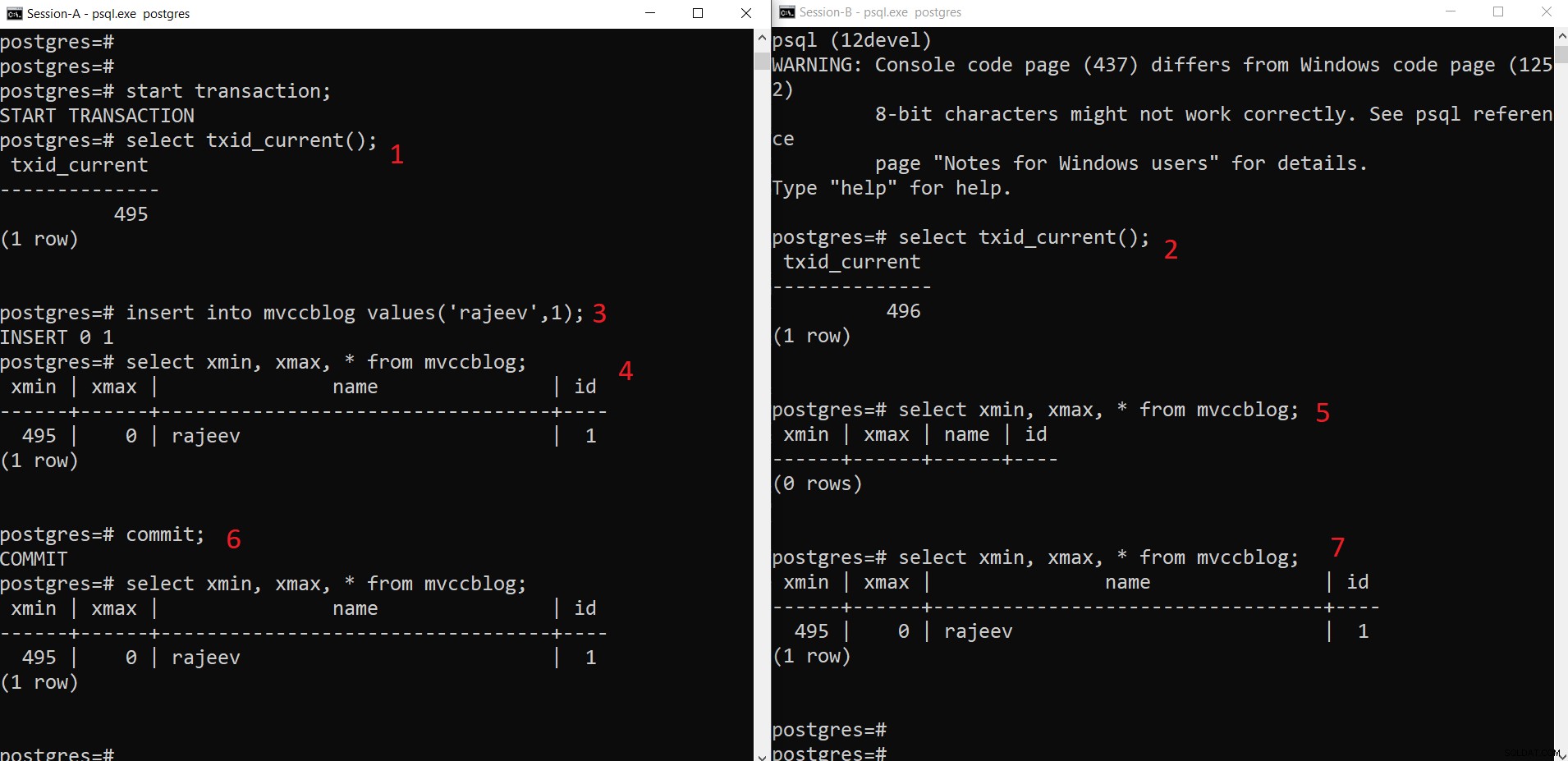 Gelijktijdige INSERT-bewerking van PostgreSQL
Gelijktijdige INSERT-bewerking van PostgreSQL Zoals we hier stapsgewijs kunnen zien:
- Sessie-A start een transactie en krijgt de transactie-ID 495.
- Sessie-B start een transactie en krijgt de transactie-ID 496.
- Sessie-A voegt een nieuwe tuple in (wordt opgeslagen in HEAP)
- Nu wordt de nieuwe tuple met xmin ingesteld op huidige transactie-ID 495 toegevoegd.
- Maar hetzelfde is niet zichtbaar vanuit Sessie-B als xmin (d.w.z. 495) nog steeds niet vastgelegd.
- Eenmaal toegewijd.
- Gegevens zijn zichtbaar voor beide sessies.
UPDATE
PostgreSQL UPDATE is geen "IN-PLACE" update, d.w.z. het wijzigt het bestaande object niet met de vereiste nieuwe waarde. In plaats daarvan wordt een nieuwe versie van het object gemaakt. UPDATE omvat dus in grote lijnen de onderstaande stappen:
- Het markeert het huidige object als verwijderd.
- Vervolgens voegt het een nieuwe versie van het object toe.
- Redirect de oudere versie van het object naar een nieuwe versie.
Dus hoewel een aantal records hetzelfde blijft, neemt HEAP ruimte in beslag alsof er nog een record is ingevoegd.
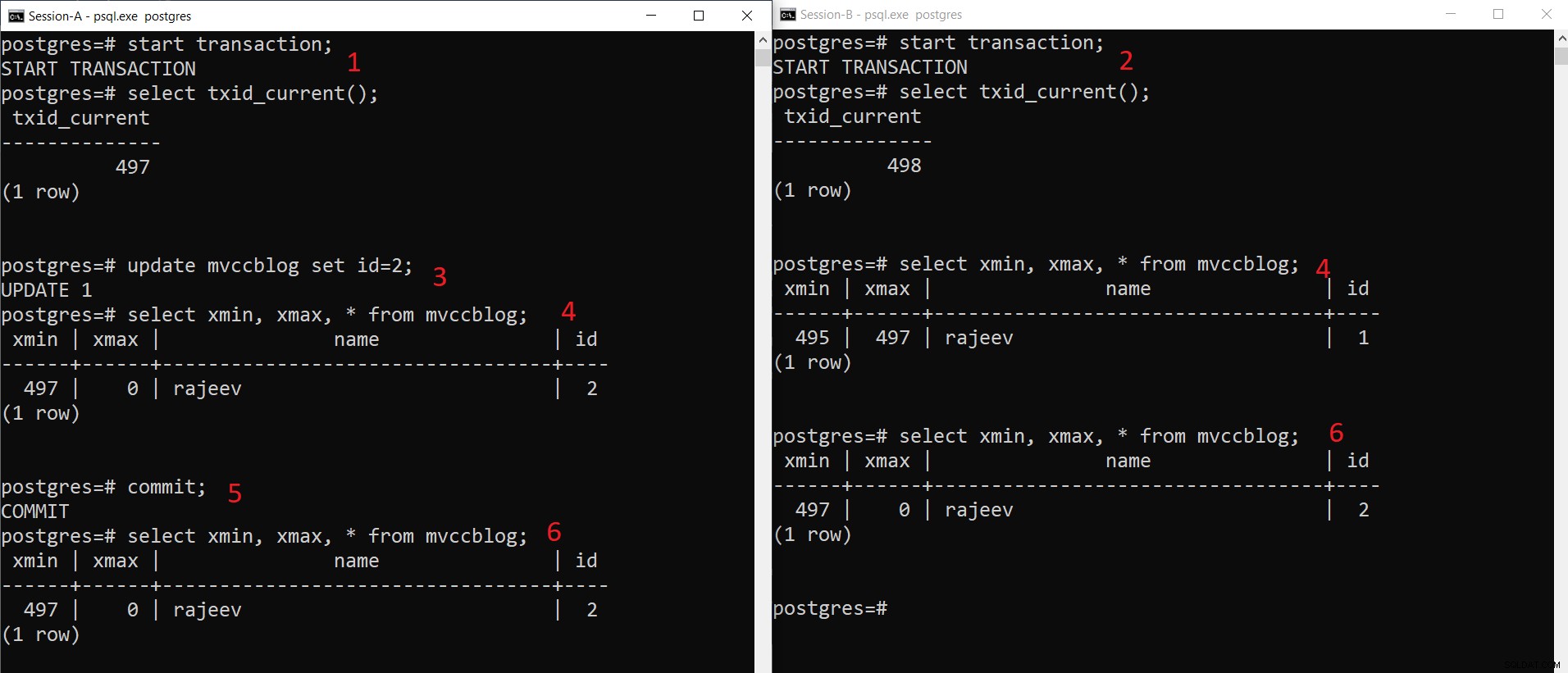 Gelijktijdige INSERT-bewerking van PostgreSQL
Gelijktijdige INSERT-bewerking van PostgreSQL Zoals we hier stapsgewijs kunnen zien:
- Sessie-A start een transactie en krijgt de transactie-ID 497.
- Sessie-B start een transactie en krijgt de transactie-ID 498.
- Sessie-A werkt het bestaande record bij.
- Hier ziet Sessie-A één versie van de tuple (bijgewerkte tuple) terwijl Sessie-B een andere versie ziet (oudere tuple maar xmax ingesteld op 497). Beide tuple-versies worden opgeslagen in de HEAP-opslag (zelfs dezelfde pagina, afhankelijk van de beschikbare ruimte)
- Zodra Sessie-A de transactie heeft uitgevoerd, verloopt de oudere tuple als xmax van de oudere tuple is vastgelegd.
- Nu zien beide sessies dezelfde versie van het record.
VERWIJDEREN
Verwijderen lijkt bijna op de UPDATE-bewerking, behalve dat er geen nieuwe versie hoeft te worden toegevoegd. Het markeert het huidige object gewoon als VERWIJDERD, zoals uitgelegd in het geval UPDATE.
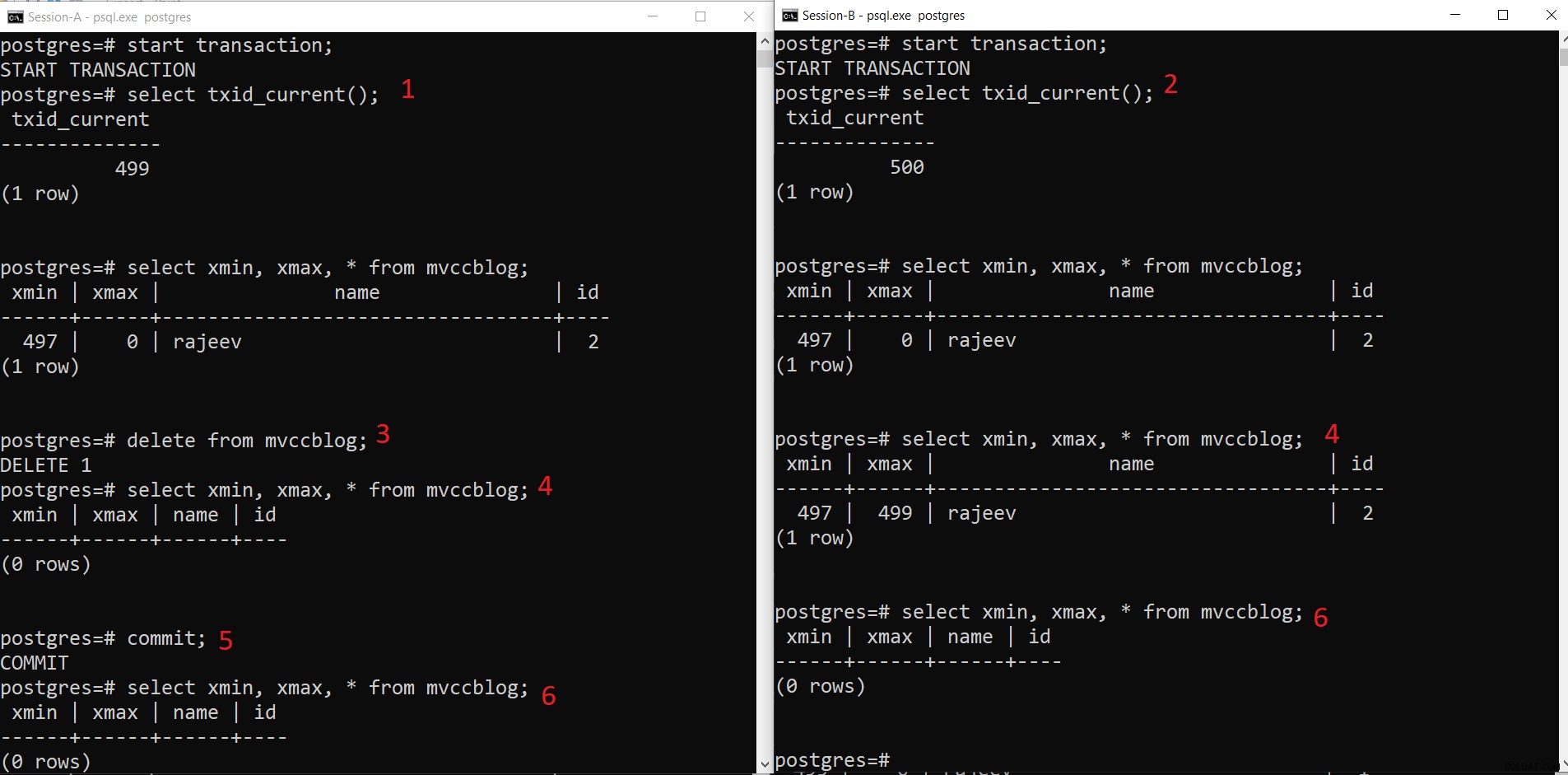 PostgreSQL gelijktijdige DELETE-bewerking
PostgreSQL gelijktijdige DELETE-bewerking - Sessie-A start een transactie en krijgt de transactie-ID 499.
- Sessie-B start een transactie en krijgt de transactie-ID 500.
- Sessie-A verwijdert het bestaande record.
- Hier ziet Session-A geen enkele tuple als verwijderd uit de huidige transactie. Terwijl Session-B een oudere versie van de tuple ziet (met xmax als 499; de transactie die dit record heeft verwijderd).
- Zodra Sessie-A de transactie heeft uitgevoerd, verloopt de oudere tuple als xmax van de oudere tuple is vastgelegd.
- Nu zien beide sessies geen verwijderde tuple.
Zoals we kunnen zien, verwijdert geen van de bewerkingen de bestaande versie van het object rechtstreeks en voegt het waar nodig een extra versie van het object toe.
Laten we nu eens kijken hoe de SELECT-query wordt uitgevoerd op een tuple met meerdere versies:SELECT moet alle versies van de tuple lezen totdat het de juiste tuple vindt volgens het isolatieniveau. Stel dat er een tuple T1 was die werd bijgewerkt en een nieuwe versie T1' creëerde en die op zijn beurt T1'' creëerde bij de update:
- SELECT-bewerking gaat door heap-opslag voor deze tabel en controleert eerst T1. Als T1 xmax-transactie is vastgelegd, gaat het naar de volgende versie van deze tuple.
- Stel nu dat T1' tuple xmax ook gecommit is, dan gaat het weer naar de volgende versie van deze tuple.
- Ten slotte vindt het T1'' en ziet het dat xmax niet is vastgelegd (of null) en dat T1'' xmin zichtbaar is voor de huidige transactie volgens het isolatieniveau. Ten slotte zal het T1''-tupel lezen.
Zoals we kunnen zien, moet het alle 3 versies van de tuple doorlopen om de juiste zichtbare tuple te vinden totdat de verlopen tuple wordt verwijderd door de vuilnisman (VACUUM).
MVCC in InnoDB
Om meerdere versies te ondersteunen, onderhoudt InnoDB extra velden voor elke rij, zoals hieronder vermeld:
- DB_TRX_ID:Transactie-ID van de transactie die de rij heeft ingevoegd of bijgewerkt.
- DB_ROLL_PTR:het wordt ook wel de roll-pointer genoemd en het verwijst naar het ongedaan maken van een logrecord dat naar het rollback-segment is geschreven (hierover verderop meer).
Net als PostgreSQL maakt InnoDB ook meerdere versies van de rij als onderdeel van alle bewerkingen, maar de opslag van de oudere versie is anders.
In het geval van InnoDB wordt de oude versie van de gewijzigde rij bewaard in een aparte tabelruimte/opslag (ongedaan maken segment genoemd). Dus in tegenstelling tot PostgreSQL bewaart InnoDB alleen de nieuwste versie van rijen in het hoofdopslaggebied en de oudere versie wordt bewaard in het ongedaan maken-segment. Rijversies van het ongedaan maken-segment worden gebruikt om de bewerking ongedaan te maken in geval van terugdraaien en voor het lezen van een oudere versie van rijen met een READ-instructie, afhankelijk van het isolatieniveau.
Bedenk dat er twee rijen zijn, T1 (met waarde 1) en T2 (met waarde 2) voor een tabel. Het aanmaken van nieuwe rijen kan in de onderstaande 3 stappen worden gedemonstreerd:
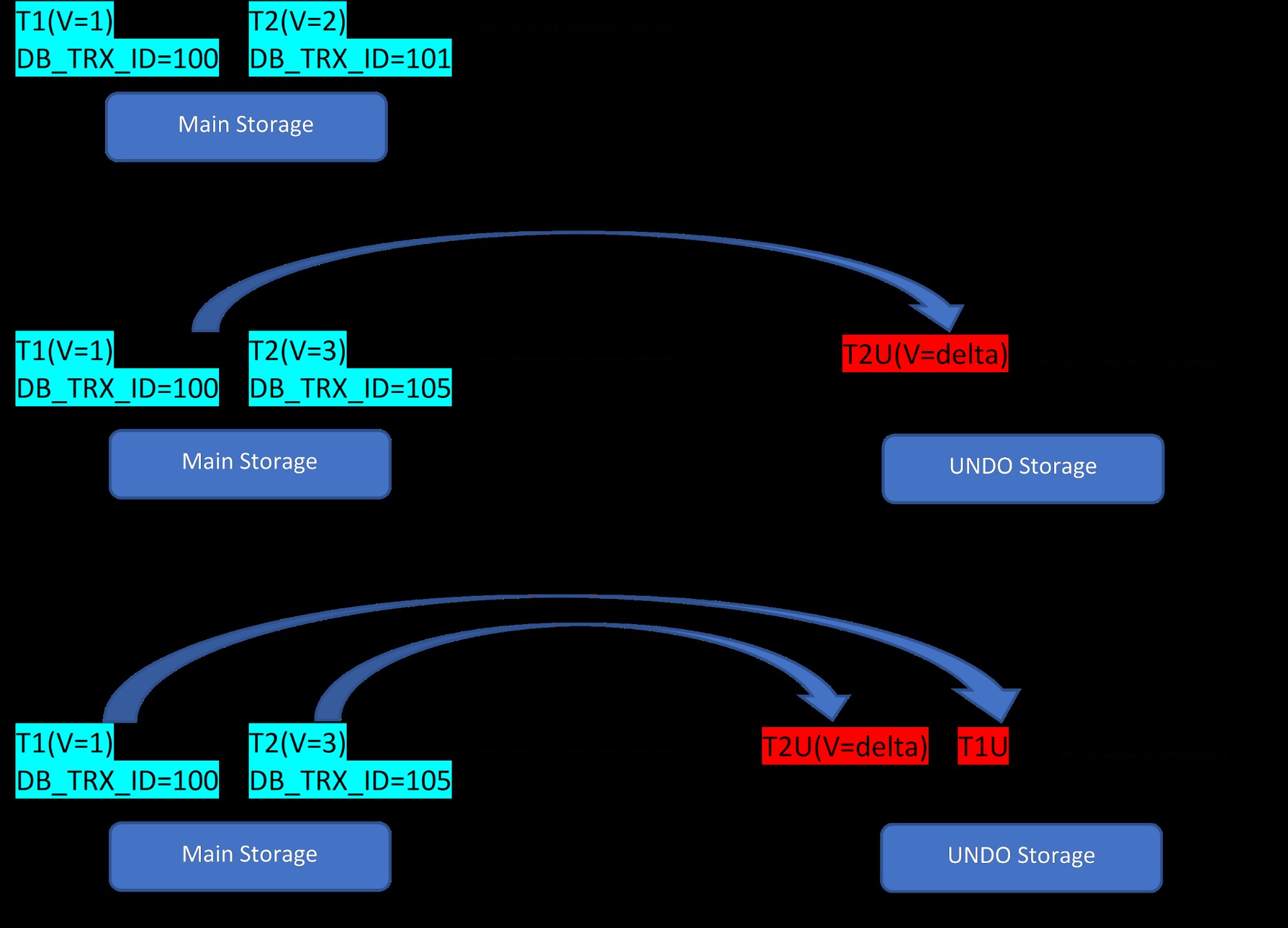 MVCC:opslag van meerdere versies in InnoDB
MVCC:opslag van meerdere versies in InnoDB Zoals te zien is in de afbeelding, zijn er aanvankelijk twee rijen in de database met waarden 1 en 2.
Vervolgens wordt in de tweede fase de rij T2 met waarde 2 bijgewerkt met de waarde 3. Op dit punt wordt een nieuwe versie gemaakt met de nieuwe waarde en deze vervangt de oudere versie. Daarvoor wordt de oudere versie opgeslagen in het undo-segment (merk op dat de UNDO-segmentversie alleen een deltawaarde heeft). Merk ook op dat er één verwijzing is van de nieuwe versie naar de oudere versie in het rollback-segment. Dus in tegenstelling tot PostgreSQL is de InnoDB-update "IN-PLACE".
Evenzo, in de derde stap, wanneer rij T1 met waarde 1 wordt verwijderd, wordt de bestaande rij virtueel verwijderd (d.w.z. het markeert alleen een speciaal bit in de rij) in het hoofdopslaggebied en een nieuwe versie die hiermee overeenkomt wordt toegevoegd in het gedeelte Ongedaan maken. Nogmaals, er is één rolaanwijzer van het hoofdgeheugen naar het ongedaan maken-segment.
Alle bewerkingen gedragen zich op dezelfde manier als in het geval van PostgreSQL van buitenaf gezien. Alleen de interne opslag van meerdere versies verschilt.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperMVCC:PostgreSQL versus InnoDB
Laten we nu eens kijken wat de belangrijkste verschillen zijn tussen PostgreSQL en InnoDB in termen van hun MVCC-implementatie:
-
Grootte van een oudere versie
PostgreSQL werkt alleen xmax bij op de oudere versie van de tuple, dus de grootte van de oudere versie blijft hetzelfde voor het corresponderende ingevoegde record. Dit betekent dat als je 3 versies van een oudere tuple hebt, ze allemaal dezelfde grootte hebben (behalve het verschil in werkelijke gegevensgrootte, indien aanwezig bij elke update).
Terwijl in het geval van InnoDB de objectversie die is opgeslagen in het segment Ongedaan maken doorgaans kleiner is dan het overeenkomstige ingevoegde record. Dit komt omdat alleen de gewijzigde waarden (d.w.z. differentieel) naar het UNDO-logboek worden geschreven.
-
INSERT-bewerking
InnoDB moet één extra record in het UNDO-segment schrijven, zelfs voor INSERT, terwijl PostgreSQL alleen een nieuwe versie maakt in het geval van UPDATE.
-
Een oudere versie herstellen in geval van terugdraaien
PostgreSQL hoeft niets specifieks te doen om een oudere versie te herstellen in geval van terugdraaien. Onthoud dat de oudere versie xmax gelijk heeft aan de transactie die deze tuple heeft bijgewerkt. Dus totdat dit transactie-ID wordt vastgelegd, wordt het beschouwd als een levend tuple voor een gelijktijdige momentopname. Zodra de transactie is teruggedraaid, wordt de bijbehorende transactie automatisch als actief beschouwd voor alle transacties, aangezien het een afgebroken transactie is.
Terwijl het in het geval van InnoDB expliciet vereist is om de oudere versie van het object opnieuw op te bouwen zodra het terugdraaien plaatsvindt.
-
Ruimte terugwinnen die wordt ingenomen door een oudere versie
In het geval van PostgreSQL kan de ruimte die wordt ingenomen door een oudere versie alleen als dood worden beschouwd als er geen parallelle snapshot is om deze versie te lezen. Zodra de oudere versie dood is, kan de VACUUM-bewerking de door hen ingenomen ruimte terugwinnen. VACUUM kan handmatig of als achtergrondtaak worden geactiveerd, afhankelijk van de configuratie.
InnoDB UNDO-logboeken zijn voornamelijk onderverdeeld in INSERT UNDO en UPDATE UNDO. De eerste wordt weggegooid zodra de bijbehorende transactie wordt vastgelegd. De tweede moet worden bewaard totdat deze parallel is aan elke andere momentopname. InnoDB heeft geen expliciete VACUUM-bewerking, maar op een vergelijkbare regel heeft het asynchrone PURGE om UNDO-logboeken te verwijderen die als een achtergrondtaak worden uitgevoerd.
-
Impact van vertraagd vacuüm
Zoals in een eerder punt besproken, is er een enorme impact van vertraagd vacuüm in het geval van PostgreSQL. Het zorgt ervoor dat de tabel opzwelt en de opslagruimte vergroot, ook al worden records voortdurend verwijderd. Het kan ook een punt bereiken waarop VACUM VOL moet worden uitgevoerd, wat zeer kostbare operaties zijn.
-
Sequentiële scan in geval van opgeblazen tafel
De sequentiële PostgreSQL-scan moet alle oudere versies van een object doorlopen, ook al zijn ze allemaal dood (totdat ze worden verwijderd met behulp van vacuüm). Dit is het typische en meest besproken probleem in PostgreSQL. Onthoud dat PostgreSQL alle versies van een tuple opslaat in dezelfde opslag.
Terwijl in het geval van InnoDB het Undo-record niet hoeft te lezen, tenzij dit vereist is. Als alle ongedaanmakingsrecords dood zijn, is het alleen voldoende om de nieuwste versie van de objecten te lezen.
-
Index
PostgreSQL slaat index op in een aparte opslag die één link naar actuele gegevens in HEAP bewaart. Dus PostgreSQL moet het INDEX-gedeelte ook updaten, ook al was er geen verandering in INDEX. Hoewel dit probleem later werd opgelost door de HOT-update (Heap Only Tuple) te implementeren, maar het heeft nog steeds de beperking dat als een nieuwe heap-tuple niet op dezelfde pagina kan worden ondergebracht, deze terugvalt naar de normale UPDATE.
InnoDB heeft dit probleem niet omdat ze een geclusterde index gebruiken.
Conclusie
PostgreSQL MVCC heeft weinig nadelen, vooral in termen van opgeblazen opslag als uw werklast regelmatig UPDATE/DELETE heeft. Dus als u besluit PostgreSQL te gebruiken, moet u zeer voorzichtig zijn met het verstandig configureren van VACUUM.
De PostgreSQL-gemeenschap heeft dit ook erkend als een groot probleem en ze zijn al begonnen te werken aan de UNDO-gebaseerde MVCC-aanpak (voorlopige naam als ZHEAP) en we zouden hetzelfde kunnen zien in een toekomstige release.