Er is geen perfect systeem, hardware of topologie om alle mogelijke problemen te vermijden die zich in een productieomgeving kunnen voordoen. Het overwinnen van deze uitdagingen vereist een effectief DRP (Disaster Recovery Plan), geconfigureerd volgens uw applicatie, infrastructuur en zakelijke vereisten. De sleutel tot succes in dit soort situaties is altijd hoe snel we het probleem kunnen oplossen of herstellen.
In deze blog bekijken we de meest voorkomende PostgreSQL-foutscenario's en laten we zien hoe u de problemen kunt oplossen of oplossen. We bekijken ook hoe ClusterControl ons kan helpen weer online te gaan
De gemeenschappelijke PostgreSQL-topologie
Om veelvoorkomende storingsscenario's te begrijpen, moet u eerst beginnen met een algemene PostgreSQL-topologie. Dit kan elke applicatie zijn die is verbonden met een PostgreSQL Primary Node waaraan een replica is gekoppeld.
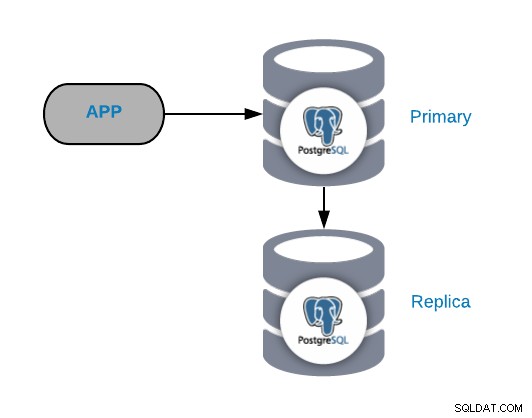
U kunt deze topologie altijd verbeteren of uitbreiden door meer knooppunten of load balancers toe te voegen , maar dit is de basistopologie waarmee we gaan werken.
Primaire PostgreSQL-knooppuntfout
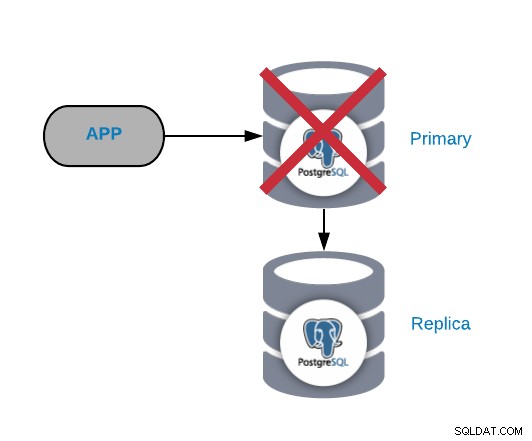
Dit is een van de meest kritieke fouten, aangezien we deze zo snel mogelijk moeten repareren als we willen onze systemen online houden. Voor dit type storing is het belangrijk om een soort automatisch failover-mechanisme te hebben. Na de storing kunt u de oorzaak van de problemen onderzoeken. Na het failoverproces zorgen we ervoor dat het defecte primaire knooppunt niet nog steeds denkt dat het het primaire knooppunt is. Dit is om inconsistentie in de gegevens te voorkomen wanneer u ernaar schrijft.
De meest voorkomende oorzaken van dit soort problemen zijn een storing in het besturingssysteem, een hardwarestoring of een schijfstoring. In ieder geval moeten we de database en de logbestanden van het besturingssysteem controleren om de reden te vinden.
De snelste oplossing voor dit probleem is het uitvoeren van een failover-taak om de downtime te verminderen. Om een replica te promoten, kunnen we het pg_ctl promote-commando gebruiken op het slave-databaseknooppunt, en dan moeten we het verkeer van de toepassing op het nieuwe primaire knooppunt. Voor deze laatste taak kunnen we een load balancer implementeren tussen onze applicatie en de databaseknooppunten, om elke wijziging van de applicatiezijde in geval van storing te voorkomen. We kunnen de load balancer ook configureren om de storing van het knooppunt te detecteren en in plaats van verkeer naar hem te sturen, het verkeer naar het nieuwe primaire knooppunt te sturen.
Na het failover-proces en ervoor te zorgen dat het systeem weer werkt, kunnen we het probleem onderzoeken en we raden aan om altijd ten minste één slave-knooppunt te laten werken, dus in het geval van een nieuwe primaire fout, we kunnen de failover-taak opnieuw uitvoeren.
Defect PostgreSQL-replicaknooppunt
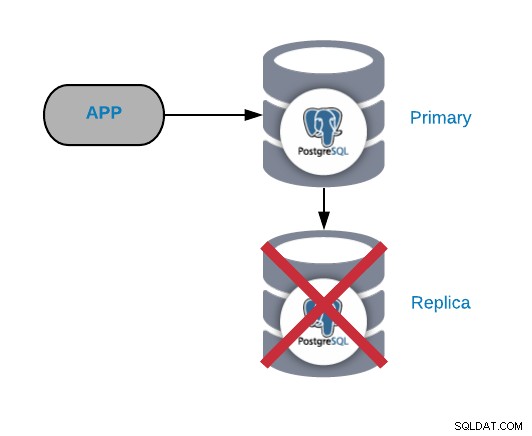
Dit is normaal gesproken geen kritiek probleem (zolang u meer dan één replica en gebruiken deze niet om het gelezen productieverkeer te verzenden). Als u problemen ondervindt op het primaire knooppunt en uw replica niet up-to-date hebt, heeft u een echt kritiek probleem. Als u onze replica gebruikt voor rapportage of big data-doeleinden, wilt u dit waarschijnlijk toch snel repareren.
De meest voorkomende oorzaken van dit soort problemen zijn dezelfde die we hebben gezien voor het primaire knooppunt, een storing in het besturingssysteem, een hardwarestoring of een schijfstoring. U moet de database en de logboeken van het besturingssysteem controleren om de reden te vinden.
Het wordt niet aanbevolen om het systeem zonder replica te laten werken, omdat u in geval van een storing geen snelle manier hebt om weer online te gaan. Als je maar één slaaf hebt, moet je het probleem zo snel mogelijk oplossen; de snelste manier is door een geheel nieuwe replica te maken. Hiervoor moet je een consistente back-up maken en deze terugzetten naar het slave-knooppunt, en vervolgens de replicatie configureren tussen dit slave-knooppunt en het primaire knooppunt.
Als u de reden van de storing wilt weten, moet u een andere server gebruiken om de nieuwe replica te maken en vervolgens in de oude kijken om deze te ontdekken. Wanneer u deze taak voltooit, kunt u ook de oude replica opnieuw configureren en beide laten werken als een toekomstige failover-optie.
Als je de replica gebruikt voor rapportage of voor big data-doeleinden, moet je het IP-adres wijzigen om verbinding te maken met de nieuwe. Net als in het vorige geval, is een manier om deze wijziging te voorkomen het gebruik van een load balancer die de status van elke server kent, zodat u naar wens replica's kunt toevoegen/verwijderen.
PostgreSQL-replicatiefout
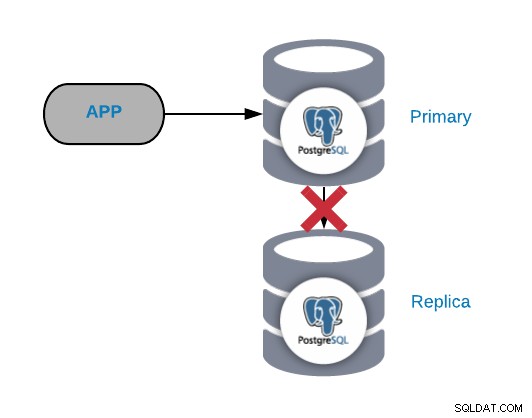
Over het algemeen wordt dit soort probleem veroorzaakt door een netwerk of configuratie kwestie. Het is gerelateerd aan een WAL-verlies (Write-Ahead Logging) in het primaire knooppunt en de manier waarop PostgreSQL de replicatie beheert.
Als u belangrijk verkeer heeft, voert u te vaak controlepunten uit of slaat u WALS slechts een paar minuten op; als je een netwerkprobleem hebt, heb je weinig tijd om het op te lossen. Uw WAL's worden verwijderd voordat u ze kunt verzenden en toepassen op de replica.
Als de WAL die de replica nodig heeft om te blijven werken is verwijderd, moet u deze opnieuw opbouwen, dus om deze taak te vermijden, moeten we onze databaseconfiguratie controleren om de wal_keep_segments (hoeveelheden WALS die in de pg_xlog directory) of de max_wal_senders (maximaal aantal gelijktijdig draaiende WAL-afzenderprocessen) parameters.
Een andere aanbevolen optie is om archive_mode te configureren en de WAL-bestanden naar een ander pad te sturen met de parameter archive_command. Op deze manier, als PostgreSQL de limiet bereikt en het WAL-bestand verwijdert, hebben we het hoe dan ook in een ander pad.
PostgreSQL-gegevenscorruptie / gegevensinconsistentie / onbedoelde verwijdering

Dit is een nachtmerrie voor elke DBA en waarschijnlijk het meest complexe probleem opgelost, afhankelijk van hoe wijdverbreid het probleem is.
Als sommige van deze problemen uw gegevens beïnvloeden, is de meest gebruikelijke manier om dit op te lossen (en waarschijnlijk de enige) door een back-up te herstellen. Daarom zijn back-ups de basisvorm van elk rampherstelplan en is het raadzaam om ten minste drie back-ups op verschillende fysieke plaatsen op te slaan. Best practice schrijft voor dat back-upbestanden één lokaal op de databaseserver moeten hebben (voor een sneller herstel), een andere op een gecentraliseerde back-upserver en de laatste in de cloud.
We kunnen ook een mix van volledige/incrementele/differentiële PITR-compatibele back-ups maken om onze Recovery Point-doelstelling te verminderen.
PostgreSQL-fout beheren met ClusterControl
Nu we deze veelvoorkomende PostgreSQL-foutscenario's hebben bekeken, gaan we kijken wat er zou gebeuren als we uw PostgreSQL-databases zouden beheren vanuit een gecentraliseerd databasebeheersysteem. Een die geweldig is in termen van een snelle en gemakkelijke manier om het probleem zo snel mogelijk op te lossen in het geval van een storing.
ClusterControl biedt automatisering voor de meeste van de hierboven beschreven PostgreSQL-taken; allemaal op een gecentraliseerde en gebruiksvriendelijke manier. Met dit systeem kunt u eenvoudig dingen configureren die handmatig tijd en moeite kosten. We zullen nu enkele van de belangrijkste functies bekijken die verband houden met PostgreSQL-foutscenario's.
Een PostgreSQL-cluster implementeren/importeren
Zodra we de ClusterControl-interface openen, moeten we eerst een nieuw cluster implementeren of een bestaande importeren. Om een implementatie uit te voeren, selecteert u gewoon de optie Databasecluster implementeren en volgt u de instructies die verschijnen.
Uw PostgreSQL-cluster schalen
Als u naar Clusteracties gaat en Replicatieslave toevoegen selecteert, kunt u een geheel nieuwe replica maken of een bestaande PostgreSQL-database als replica toevoegen. Op deze manier kunt u uw nieuwe replica binnen een paar minuten laten draaien en kunnen we zoveel replica's toevoegen als we willen; spreiden van leesverkeer tussen hen met behulp van een load balancer (die we ook kunnen implementeren met ClusterControl).
Automatische PostgreSQL-failover
ClusterControl beheert de failover van uw replicatie-installatie. Het detecteert masterstoringen en promoot een slave met de meest actuele gegevens als de nieuwe master. Het faalt ook automatisch over de rest van de slaves om te repliceren vanaf de nieuwe master. Wat betreft clientverbindingen, het maakt gebruik van twee tools voor de taak:HAProxy en Keepalive.
HAProxy is een load balancer die verkeer van de ene oorsprong naar een of meer bestemmingen verdeelt en specifieke regels en/of protocollen voor de taak kan definiëren. Als een van de bestemmingen niet meer reageert, wordt deze gemarkeerd als offline en wordt het verkeer naar een van de beschikbare bestemmingen gestuurd. Dit voorkomt dat verkeer naar een ontoegankelijke bestemming wordt gestuurd en dat deze informatie verloren gaat door het naar een geldige bestemming te leiden.
Keepalived stelt je in staat een virtueel IP-adres te configureren binnen een actieve/passieve groep servers. Dit virtuele IP-adres wordt toegewezen aan een actieve “Hoofd”-server. Als deze server uitvalt, wordt het IP automatisch gemigreerd naar de "Secundaire" server die passief bleek te zijn, waardoor deze op een transparante manier voor onze systemen met hetzelfde IP kan blijven werken.
Een PostgreSQL Load Balancer toevoegen
Als u naar Clusteracties gaat en Load Balancer toevoegen selecteert (of vanuit de clusterweergave - ga naar Beheren -> Load Balancer), kunt u load balancers toevoegen aan onze databasetopologie.
De configuratie die nodig is om uw nieuwe load balancer te maken, is vrij eenvoudig. U hoeft alleen IP/Hostnaam, poort, beleid en de knooppunten die we gaan gebruiken toe te voegen. Je kunt twee load balancers met Keepalive ertussen toevoegen, waardoor we een automatische failover van onze load balancer hebben in geval van storing. Keepalived gebruikt een virtueel IP-adres en migreert dit van de ene load balancer naar de andere in geval van storing, zodat onze setup normaal kan blijven functioneren.
PostgreSQL-back-ups
We hebben het belang van het hebben van back-ups al besproken. ClusterControl biedt de functionaliteit om een onmiddellijke back-up te genereren of om er een in te plannen.
Je kunt kiezen uit drie verschillende back-upmethoden:pgdump, pg_basebackup of pgBackRest. U kunt ook aangeven waar de back-ups moeten worden opgeslagen (op de databaseserver, op de ClusterControl-server of in de cloud), het compressieniveau, de vereiste versleuteling en de bewaarperiode.
PostgreSQL-controle en -waarschuwing
Voordat u actie kunt ondernemen, moet u weten wat er gebeurt, dus u moet uw databasecluster in de gaten houden. Met ClusterControl kunt u onze servers realtime monitoren. Er zijn grafieken met basisgegevens zoals CPU, netwerk, schijf, RAM, IOPS, evenals databasespecifieke statistieken die zijn verzameld uit de PostgreSQL-instanties. Databasequery's kunnen ook worden bekeken vanuit de Query Monitor.
Op dezelfde manier waarop u monitoring vanuit ClusterControl inschakelt, kunt u ook waarschuwingen instellen die u informeren over gebeurtenissen in uw cluster. Deze waarschuwingen zijn configureerbaar en kunnen naar behoefte worden gepersonaliseerd.
Conclusie
Iedereen zal uiteindelijk te maken krijgen met PostgreSQL-problemen en -fouten. En aangezien u het probleem niet kunt vermijden, moet u het zo snel mogelijk kunnen oplossen en het systeem draaiende kunnen houden. We hebben ook gezien hoe het gebruik van ClusterControl kan helpen bij deze problemen; allemaal vanaf een enkel en gebruiksvriendelijk platform.
Dit zijn volgens ons enkele van de meest voorkomende faalscenario's voor PostgreSQL. We horen graag over je eigen ervaringen en hoe je het hebt opgelost.