In mijn vorige blog hebben we verschillende manieren besproken om gegevens uit een enkele tabel te selecteren of te scannen. Maar in de praktijk is het niet voldoende om gegevens uit een enkele tabel op te halen. Het vereist het selecteren van gegevens uit meerdere tabellen en deze vervolgens correleren. Correlatie van deze gegevens tussen tabellen wordt samenvoegen van tabellen genoemd en kan op verschillende manieren worden gedaan. Omdat het samenvoegen van tabellen invoergegevens vereist (bijvoorbeeld van de tabelscan), kan het nooit een bladknooppunt in het gegenereerde plan zijn.
Bijv. beschouw een eenvoudig queryvoorbeeld als SELECT * FROM TBL1, TBL2 waarbij TBL1.ID> TBL2.ID; en stel dat het gegenereerde plan als volgt is:
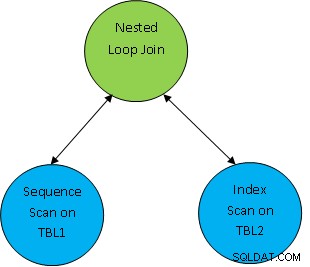
Dus hier worden eerst beide tabellen gescand en vervolgens worden ze samengevoegd als volgens de correlatievoorwaarde als TBL.ID> TBL2.ID
Naast de join-methode is ook de join-volgorde erg belangrijk. Beschouw het onderstaande voorbeeld:
SELECTEER * VAN TBL1, TBL2, TBL3 WAAR TBL1.ID=TBL2.ID EN TBL2.ID=TBL3.ID;
Bedenk dat TBL1, TBL2 EN TBL3 respectievelijk 10, 100 en 1000 records hebben.
De voorwaarde TBL1.ID=TBL2.ID retourneert slechts 5 records, terwijl TBL2.ID=TBL3.ID 100 records retourneert, dan is het beter om eerst TBL1 en TBL2 samen te voegen zodat er minder records worden samen met TBL3. Het plan ziet er als volgt uit:
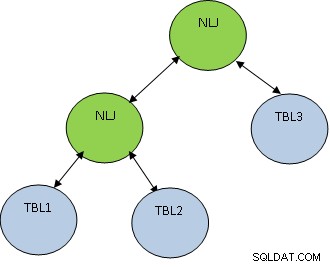
PostgreSQL ondersteunt de onderstaande soorten joins:
- Nested Loop Join
- Hash Join
- Aanmelden samenvoegen
Elk van deze Join-methoden is even nuttig, afhankelijk van de query en andere parameters, b.v. query, tabelgegevens, join-clausule, selectiviteit, geheugen enz. Deze join-methoden worden geïmplementeerd door de meeste relationele databases.
Laten we een vooraf ingestelde tabel maken en deze vullen met enkele gegevens, die vaak zullen worden gebruikt om deze scanmethoden beter uit te leggen.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEIn al onze volgende voorbeelden houden we rekening met de standaardconfiguratieparameter, tenzij specifiek anders aangegeven.
Nested Loop Join
Nested Loop Join (NLJ) is het eenvoudigste join-algoritme waarbij elk record van uiterlijke relatie wordt gematcht met elk record van innerlijke relatie. De Join tussen relatie A en B met conditie A.ID Nested Loop Join (NLJ) is de meest gebruikte methode voor samenvoegen en kan bijna op elke dataset met elk type samenvoegingsclausule worden gebruikt. Aangezien dit algoritme alle tupels van innerlijke en uiterlijke relaties scant, wordt het beschouwd als de duurste join-operatie. Volgens de bovenstaande tabel en gegevens resulteert de volgende zoekopdracht in een geneste lusverbinding zoals hieronder weergegeven: Aangezien de join-clausule "<" is, is de enige mogelijke join-methode hier Nested Loop Join. Let hier op een nieuw soort knooppunt als Materialize; dit knooppunt fungeert als tussenliggende resultaatcache, d.w.z. in plaats van alle tuples van een relatie meerdere keren op te halen, wordt het eerste opgehaalde resultaat in het geheugen opgeslagen en bij het volgende verzoek om tuple te krijgen uit het geheugen in plaats van opnieuw uit de relatiepagina's te halen . In het geval dat niet alle tuples in het geheugen passen, gaan overloop-tupels naar een tijdelijk bestand. Het is vooral handig in het geval van Nested Loop Join en tot op zekere hoogte in het geval van Merge Join, omdat ze afhankelijk zijn van het opnieuw scannen van de innerlijke relatie. Materialise Node is niet alleen beperkt tot het cachen van het resultaat van een relatie, maar het kan de resultaten van elk knooppunt hieronder in de planboom cachen. TIP:In het geval dat de join-clausule “=” is en geneste loop join is gekozen tussen een relatie, dan is het echt belangrijk om te onderzoeken of een efficiëntere join-methode zoals hash of merge join kan worden gekozen door afstemmingsconfiguratie (bijv. work_mem maar niet beperkt tot ) of door een index toe te voegen, enz. Sommige van de zoekopdrachten hebben mogelijk geen join-clausule, in dat geval is Nested Loop Join ook de enige keuze om mee te doen. bijv. overweeg de onderstaande vragen volgens de pre-configuratiegegevens: De join in het bovenstaande voorbeeld is slechts een Cartesiaans product van beide tabellen. Dit algoritme werkt in twee fasen: De join tussen relatie A en B met voorwaarde A.ID =B.ID kan als volgt worden weergegeven: Volgens bovenstaande pre-setup tabel en data, zal de volgende query resulteren in een Hash Join zoals hieronder getoond: Hier wordt de hashtabel gemaakt op de tabel blogtable2 omdat het de kleinere tabel is, zodat het minimale geheugen dat nodig is voor de hashtabel en de hele hashtabel in het geheugen past. Merge Join is een algoritme waarin elk record van een uiterlijke relatie wordt gematcht met elk record van een innerlijke relatie totdat er een mogelijkheid is om de join-clausule te matchen. Dit join-algoritme wordt alleen gebruikt als beide relaties zijn gesorteerd en de operator van de join-clausule "=" is. De join tussen relatie A en B met voorwaarde A.ID =B.ID kan als volgt worden weergegeven: De voorbeeldquery die resulteerde in een Hash Join, zoals hierboven weergegeven, kan resulteren in een Merge Join als de index op beide tabellen wordt gemaakt. Dit komt omdat de tabelgegevens in gesorteerde volgorde kunnen worden opgehaald vanwege de index, wat een van de belangrijkste criteria is voor de Merge Join-methode: Dus, zoals we zien, gebruiken beide tabellen indexscan in plaats van sequentiële scan, waardoor beide tabellen gesorteerde records uitzenden. PostgreSQL ondersteunt verschillende planner-gerelateerde configuraties, die kunnen worden gebruikt om de query-optimizer te hinten om een bepaald soort join-methoden niet te selecteren. Als de door de optimizer gekozen join-methode niet optimaal is, kunnen deze configuratieparameters worden uitgeschakeld om de query-optimizer te dwingen een ander soort join-methoden te kiezen. Al deze configuratieparameters zijn standaard "aan". Hieronder staan de configuratieparameters van de planner die specifiek zijn voor join-methoden. Er zijn veel plangerelateerde configuratieparameters die voor verschillende doeleinden worden gebruikt. In deze blog wordt het beperkt tot alleen join-methoden. Deze parameters kunnen vanaf een bepaalde sessie worden gewijzigd. Dus als we willen experimenteren met het plan van een bepaalde sessie, dan kunnen deze configuratieparameters worden gemanipuleerd en blijven andere sessies werken zoals ze zijn. Beschouw nu de bovenstaande voorbeelden van merge join en hash join. Zonder een index selecteerde de query-optimizer een hash-join voor de onderstaande query, zoals hieronder weergegeven, maar na gebruik te hebben gemaakt van de configuratie, schakelt deze over naar merge-join, zelfs zonder index: Aanvankelijk is voor Hash Join gekozen omdat gegevens uit tabellen niet worden gesorteerd. Om het Merge Join Plan te kiezen, moet het eerst alle records sorteren die uit beide tabellen zijn opgehaald en vervolgens de merge join toepassen. De sorteerkosten zullen dus extra zijn en dus zullen de totale kosten stijgen. Dus mogelijk zijn in dit geval de totale (inclusief verhoogde) kosten hoger dan de totale kosten van Hash Join, dus is Hash Join gekozen. Zodra de configuratieparameter enable_hashjoin is gewijzigd in "off", betekent dit dat de query-optimizer direct kosten voor hash-join toewijst als uitschakelkosten (=1,0e10, d.w.z. 10000000000,00). De kosten van een eventuele deelname zullen lager zijn dan dit. Dus hetzelfde zoekresultaat in Samenvoegen samenvoegen nadat enable_hashjoin is gewijzigd in "uit", omdat zelfs inclusief de sorteerkosten, de totale kosten van samenvoegen lager zijn dan de kosten voor het uitschakelen. Beschouw nu het onderstaande voorbeeld: Zoals we hierboven kunnen zien, ook al is de geneste loop join-gerelateerde configuratieparameter gewijzigd in "off", toch kiest het geneste loop join omdat er geen alternatieve mogelijkheid is om een andere soort join-methode te krijgen geselecteerd. In eenvoudiger bewoordingen, aangezien Nested Loop Join de enige mogelijke join is, zal het altijd de winnaar zijn, ongeacht de kosten (hetzelfde als ik vroeger de winnaar was in een race van 100 m als ik alleen rende...:-)). Let ook op het verschil in kosten in het eerste en tweede plan. Het eerste plan toont de werkelijke kosten van Nested Loop Join, maar het tweede toont de kosten voor het uitschakelen ervan. Alle soorten PostgreSQL-join-methoden zijn nuttig en worden geselecteerd op basis van de aard van de query, gegevens, join-clausule, enz. In het geval dat de query niet werkt zoals verwacht, d.w.z. join-methoden zijn niet geselecteerd zoals verwacht, kan de gebruiker spelen met verschillende beschikbare configuratieparameters van het plan en kijken of er iets ontbreekt.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Hash Join
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Aanmelden samenvoegen
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Configuratie
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Conclusie