Deze blog is het tweede deel van het implementeren van een Multi-Datacenter Setup voor PostgreSQL. In deze klap laten we zien hoe PostgreSQL in dit type omgeving kan worden geïmplementeerd en hoe een failover kan worden uitgevoerd in het geval van een masterfout met behulp van de ClusterControl-functie voor automatisch herstel.
Op dit punt gaan we ervan uit dat je verbinding hebt tussen de datacenters (zoals we in het eerste deel van deze blog hebben gezien) en dat je over de benodigde servers voor deze taak beschikt (zoals we ook vermeldden in de vorig deel).
Een PostgreSQL-cluster implementeren
We gebruiken ClusterControl voor deze taak, dus we gaan ervan uit dat u het hebt geïnstalleerd (het zou op dezelfde Load Balancer-server kunnen worden geïnstalleerd, maar als u een andere nog beter kunt gebruiken).
/P>
Ga naar uw ClusterControl-server en selecteer de optie 'Deploy'. Als er al een PostgreSQL-instantie actief is, moet u in plaats daarvan 'Bestaande server/database importeren' selecteren.
Als u PostgreSQL selecteert, moet u Gebruiker, Sleutel of Wachtwoord en poort opgeven maak via SSH verbinding met onze PostgreSQL-hosts. Je hebt ook de naam van je nieuwe cluster nodig en als je wilt dat ClusterControl de bijbehorende software en configuraties voor je installeert.
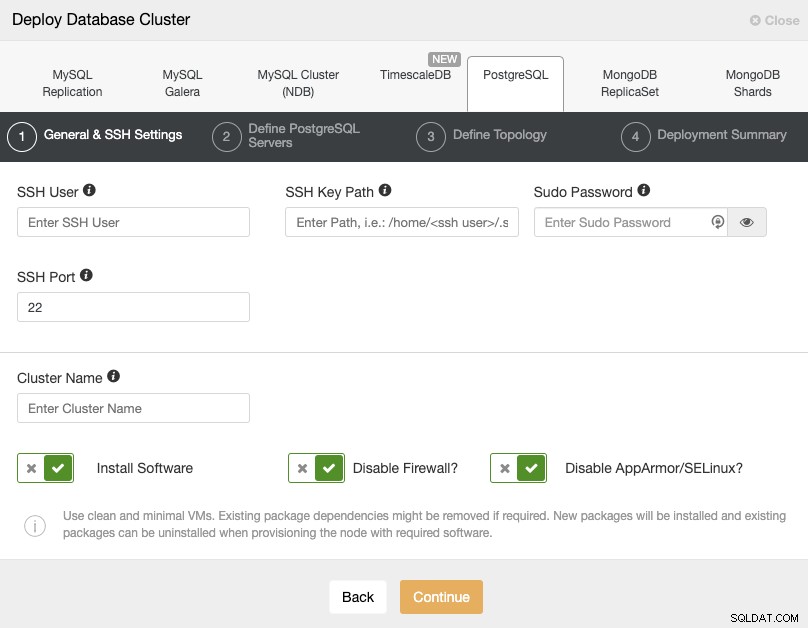
Controleer de gebruikersvereisten van ClusterControl voor deze taak hier, maar als u de de vorige blog, moet je hier de 'externe' gebruiker en de juiste SSH-poort gebruiken (zoals we al zeiden, wordt aanbevolen om een andere te gebruiken als je het openbare IP-adres gebruikt om toegang te krijgen in plaats van een VPN).
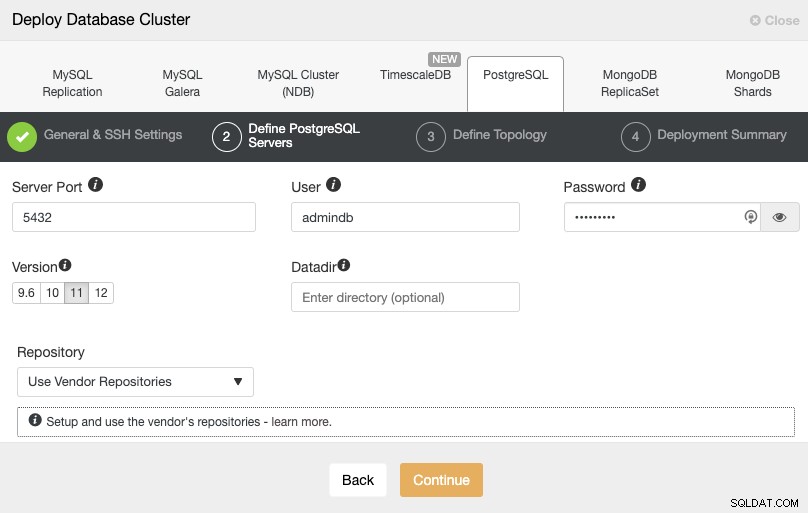
Na het instellen van de SSH-toegangsinformatie, moet u de databasegebruiker definiëren, versie en datadir (optioneel). U kunt ook aangeven welke repository u wilt gebruiken. In de volgende stap moet u uw servers toevoegen aan het cluster dat u gaat maken.
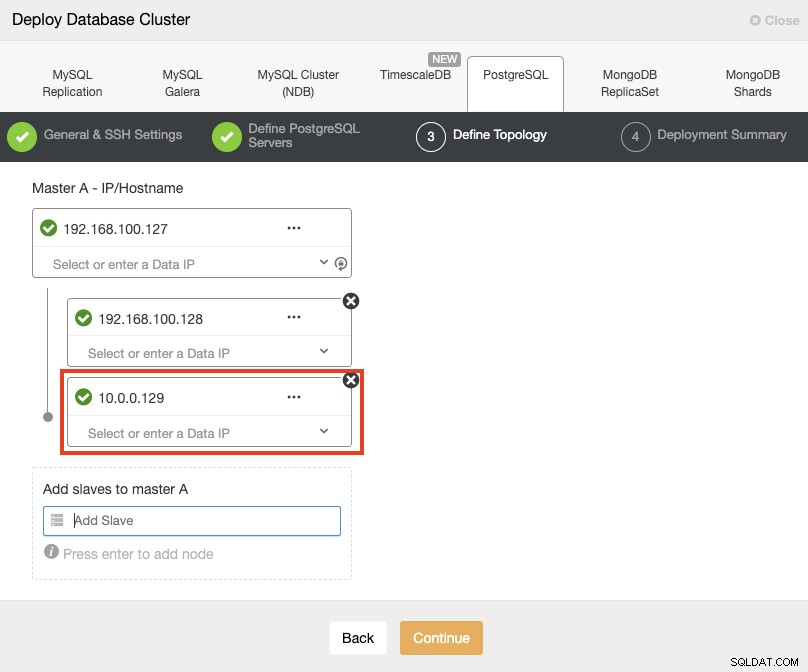
Bij het toevoegen van uw servers kunt u IP of hostnaam invoeren. In dit deel gebruik je de openbare IP-adressen van je servers, en zoals je kunt zien in het rode vak, gebruik ik een ander netwerk voor het tweede standby-knooppunt. ClusterControl heeft geen beperkingen met betrekking tot het te gebruiken netwerk. De enige vereiste hiervoor is om SSH-toegang tot het knooppunt te hebben.
Dus in navolging van ons vorige voorbeeld, zouden dit IP-adres moeten zijn:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)In de laatste stap kunt u kiezen of uw replicatie synchroon of asynchroon zal zijn.
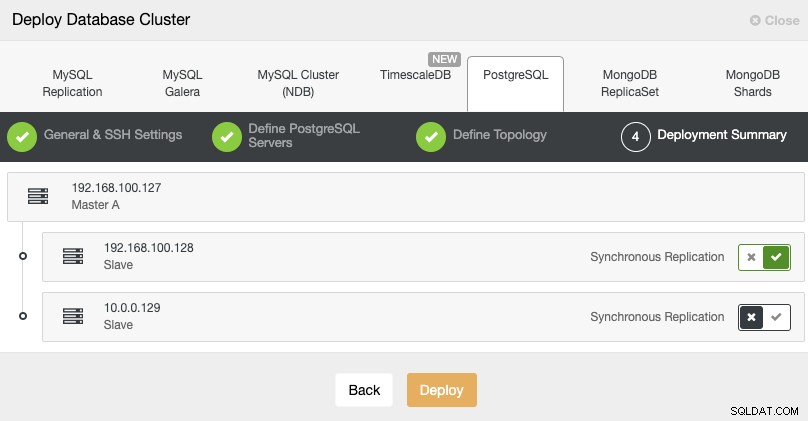
In dit geval is het belangrijk om asynchrone replicatie te gebruiken voor uw externe knooppunt , zo niet, dan kan uw cluster worden beïnvloed door de latentie of netwerkproblemen.
U kunt de status van het maken van uw nieuwe cluster volgen via de ClusterControl-activiteitenmonitor.
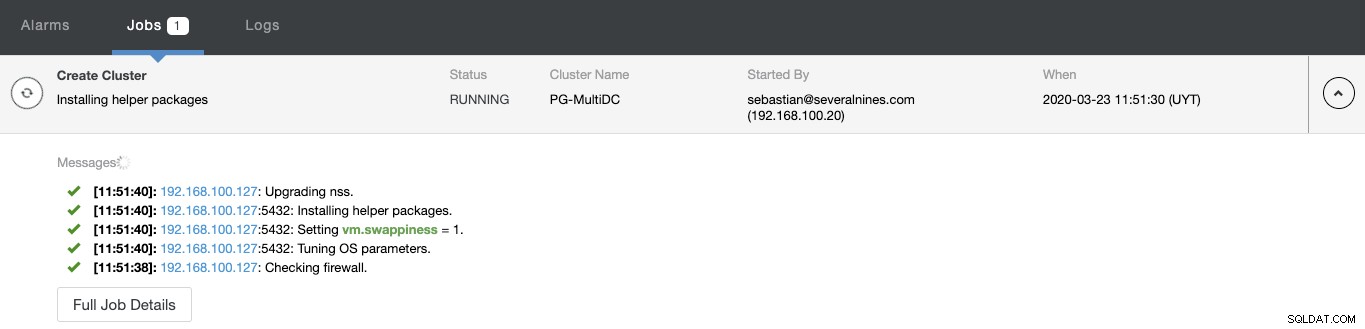
Zodra de taak is voltooid, ziet u uw nieuwe PostgreSQL-cluster in de hoofdscherm van ClusterControl.

Een PostgreSQL Load Balancer (HAProxy) toevoegen
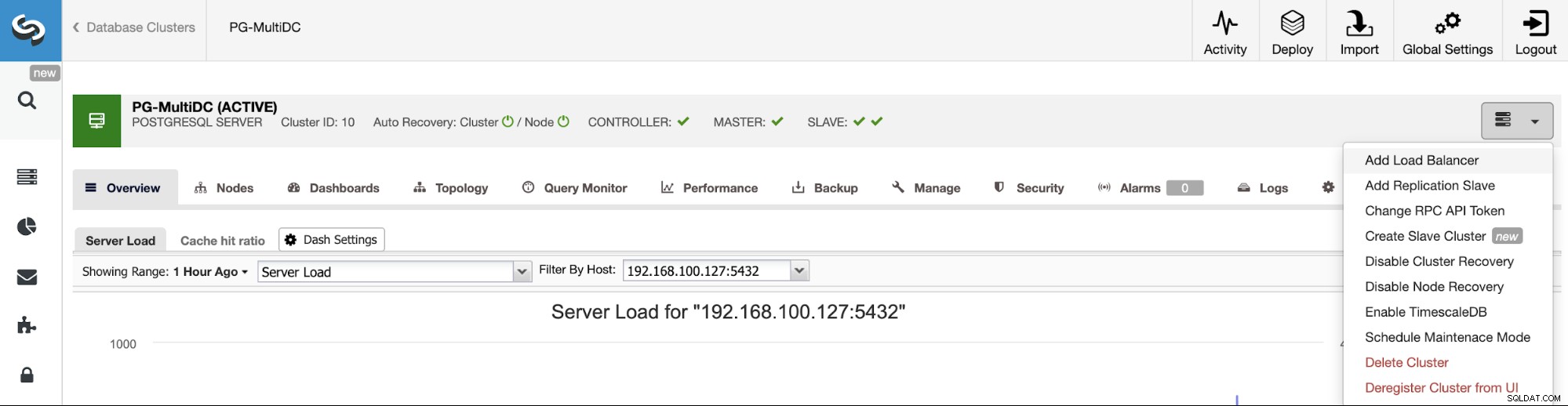
Zodra je je cluster hebt gemaakt, kun je er verschillende taken op uitvoeren, zoals het toevoegen van een load balancer (HAProxy) of een nieuwe replica.
Laten we, om ons vorige voorbeeld te volgen, een load balancer toevoegen die, zoals we al zeiden, u zal helpen bij het beheren van uw HA-omgeving. Ga hiervoor naar ClusterControl -> Selecteer PostgreSQL-cluster -> Clusteracties -> Load Balancer toevoegen.
Hier moet u de informatie toevoegen die ClusterControl zal gebruiken om uw HAProxy-load balancer. Deze Load Balancer kan op dezelfde ClusterControl-server worden geïnstalleerd, maar als u een andere kunt gebruiken, nog beter.
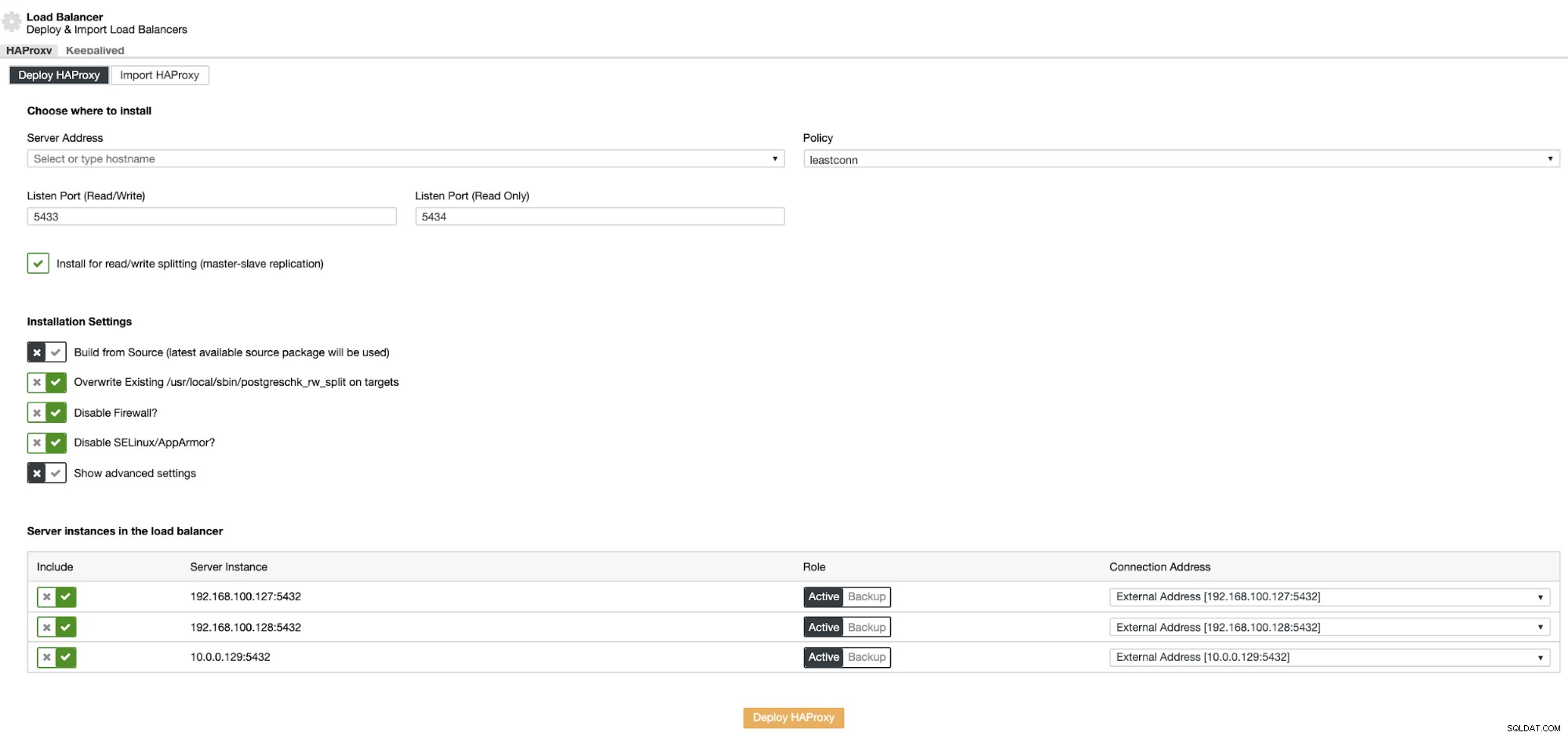
De informatie die u moet invoeren is:
Actie:implementeren of importeren.
Serveradres:IP-adres voor uw HAProxy-server (dit kan hetzelfde ClusterControl IP-adres zijn).
Luisterpoort (lezen/schrijven):Poort voor lees-/schrijfmodus.
Luisterpoort (alleen-lezen):poort voor alleen-lezen modus.
Beleid:het kan zijn:
- leastconn:de server met het laagste aantal verbindingen ontvangt de verbinding.
- roundrobin:elke server wordt om de beurt gebruikt, op basis van hun gewicht.
- bron:het bron-IP-adres wordt gehasht en gedeeld door het totale gewicht van de actieve servers om aan te geven welke server het verzoek zal ontvangen.
Installeren voor splitsen van lezen/schrijven:voor master-slave-replicatie.
Build from Source:u kunt kiezen voor Installeren vanuit een pakketbeheerder of bouwen vanaf source.
En je moet selecteren welke servers je wilt toevoegen aan de HAProxy-configuratie.
U kunt ook geavanceerde instellingen configureren, zoals Admin User, Backend Name, Time-outs en meer.
Wanneer u de configuratie voltooit en de implementatie bevestigt, kunt u de voortgang volgen in het gedeelte Activiteit in de gebruikersinterface van ClusterControl.
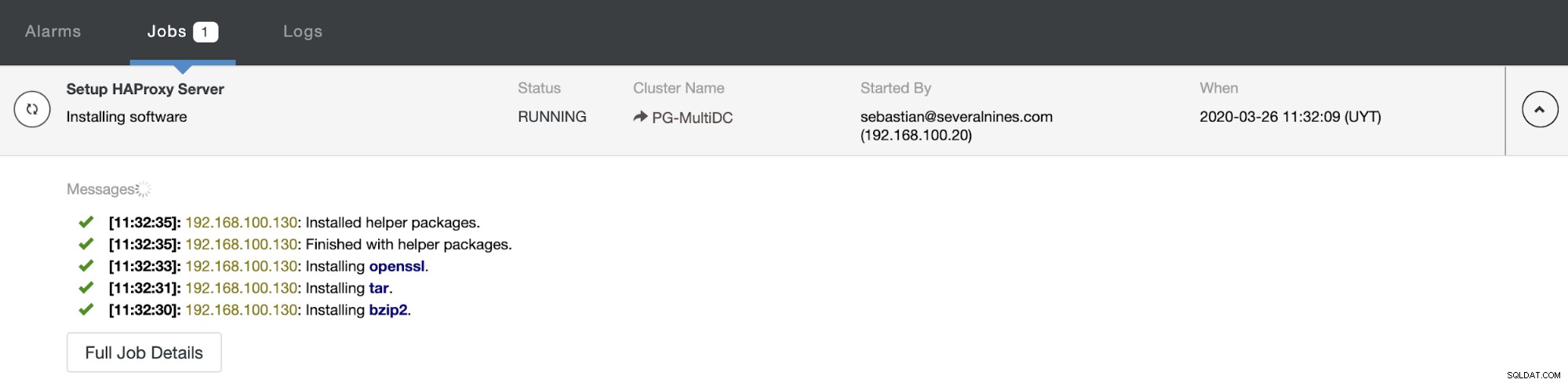
En als dit klaar is, kun je naar ClusterControl -> Nodes -> HAProxy-knooppunt en controleer de huidige status.
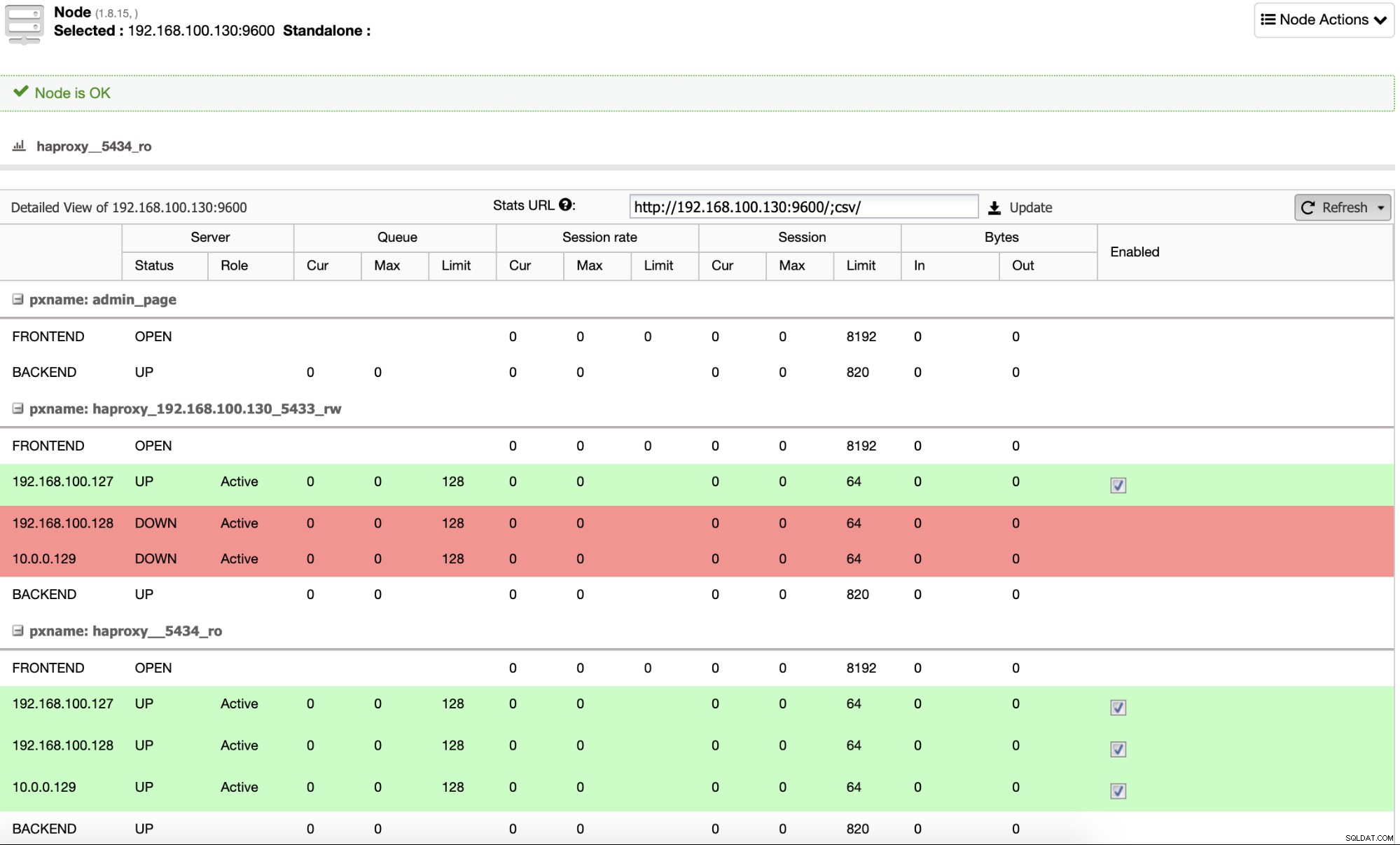
ClusterControl configureert HAProxy standaard met twee verschillende poorten, één voor Read- Write, dat zal worden gebruikt voor de toepassing of gebruiker om gegevens te schrijven (en te lezen), en een andere voor Read-Only, dat zal worden gebruikt voor het balanceren van het leesverkeer tussen alle knooppunten. In de Read-Write-poort is alleen de master-node ingeschakeld en in het geval van een master-fout, zal ClusterControl de meest geavanceerde slave tot master promoveren en deze poort opnieuw configureren om de oude master uit te schakelen en de nieuwe in te schakelen. Op deze manier kan uw applicatie nog steeds werken in het geval van een masterdatabasefout, aangezien het verkeer door de Load Balancer wordt omgeleid naar het juiste knooppunt.
U kunt uw HAProxy-servers ook controleren door de Dashboard-sectie te raadplegen.
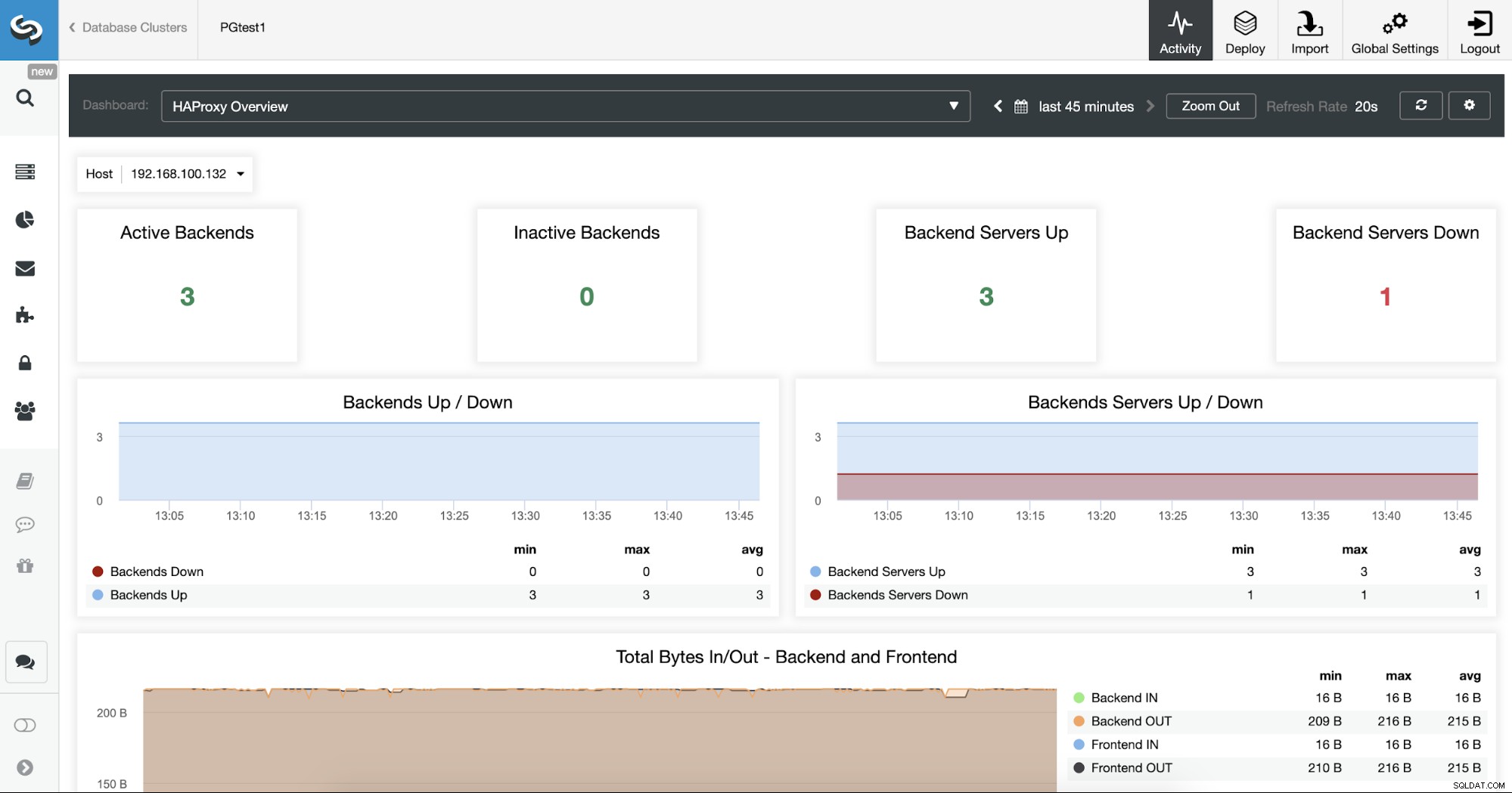
Nu kunt u uw HA-ontwerp verbeteren door een nieuw HAProxy-knooppunt in de externe datacenter en het configureren van de Keepalive-service tussen hen. Met Keepalived kunt u een virtueel IP-adres gebruiken dat is toegewezen aan het actieve Load Balancer-knooppunt. Als dit knooppunt uitvalt, wordt dit virtuele IP-adres gemigreerd naar het secundaire HAProxy-knooppunt, dus als dit IP-adres in uw toepassing is geconfigureerd, kunt u alles werkend houden in het geval van een probleem met de Load Balancer.
Al deze configuratie kan worden uitgevoerd met ClusterControl.
Conclusie
Door deze tweedelige blog te volgen, kunt u een multi-datacenterconfiguratie implementeren voor PostgreSQL met High Availability en SSH-connectiviteit tussen het datacenter, om de complexiteit van een VPN-configuratie te vermijden.
Door asynchrone replicatie voor het externe knooppunt te gebruiken, vermijdt u elk probleem met betrekking tot de latentie en netwerkprestaties, en met ClusterControl heeft u automatische (of handmatige) failover in geval van storing (naast andere verschillende functies). Dit zou de eenvoudigste manier kunnen zijn om deze topologie te bereiken en we hopen dat dit nuttig voor u zou zijn.