Lezen uit het geheugen zal altijd beter presteren dan naar de schijf gaan, dus voor alle databasetechnologieën zou je zoveel mogelijk geheugen willen gebruiken. Als u niet zeker bent van de configuratie, of als u een fout heeft, kan dit leiden tot een hoog geheugengebruik of zelfs een probleem met onvoldoende geheugen.
In deze blog bekijken we hoe u uw PostgreSQL-geheugengebruik kunt controleren en met welke parameter u rekening moet houden om deze af te stemmen. Laten we hiervoor beginnen met een overzicht van de architectuur van PostgreSQL.
PostgreSQL-architectuur
De architectuur van PostgreSQL is gebaseerd op drie fundamentele onderdelen:processen, geheugen en schijf.
Het geheugen kan in twee categorieën worden ingedeeld:
- Lokaal geheugen :Het wordt door elk backend-proces geladen voor eigen gebruik voor het verwerken van query's. Het is onderverdeeld in subgebieden:
- Werkgeheugen:het werkgeheugen wordt gebruikt voor het sorteren van tuples op ORDER BY- en DISTINCT-bewerkingen, en voor het samenvoegen van tabellen.
- Onderhoudswerkmem:Sommige soorten onderhoudswerkzaamheden maken gebruik van dit gebied. Bijvoorbeeld VACUUM, als u geen autovacuum_work_mem opgeeft.
- Temp buffers:het wordt gebruikt om tijdelijke tabellen op te slaan.
- Gedeeld geheugen :Het wordt toegewezen door de PostgreSQL-server wanneer het wordt gestart, en het wordt gebruikt door alle processen. Het is onderverdeeld in subgebieden:
- Gedeelde bufferpool:waar PostgreSQL pagina's met tabellen en indexen van schijf laadt, om direct vanuit het geheugen te werken, waardoor de schijftoegang wordt verminderd.
- WAL-buffer:de WAL-gegevens zijn het transactielogboek in PostgreSQL en bevatten de wijzigingen in de database. WAL-buffer is het gebied waar de WAL-gegevens tijdelijk worden opgeslagen voordat ze naar schijf in de WAL-bestanden worden geschreven. Dit wordt gedaan om de vooraf gedefinieerde tijd die checkpoint wordt genoemd. Dit is erg belangrijk om het verlies van informatie in het geval van een serverstoring te voorkomen.
- Logboek vastleggen:het slaat de status van alle transacties op voor gelijktijdigheidscontrole.
Weten wat er aan de hand is
Als u veel geheugen gebruikt, moet u eerst controleren welk proces het verbruik genereert.
Het "Top" Linux-commando gebruiken
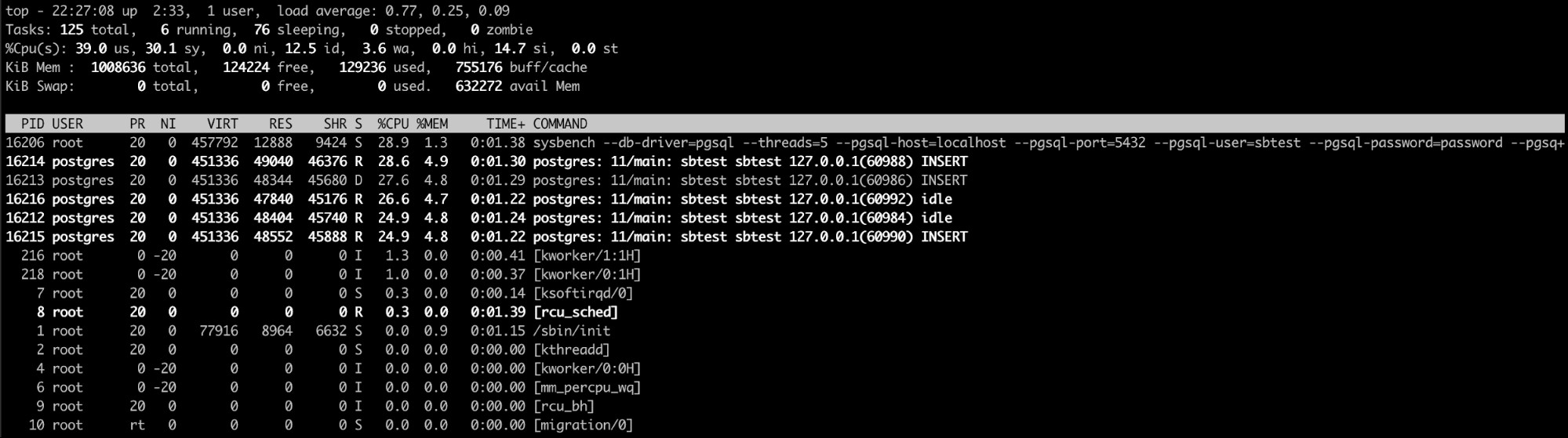
Het bovenste linux-commando is hier waarschijnlijk de beste optie (of zelfs een vergelijkbare een zoals htop). Met deze opdracht kunt u het proces/de processen zien die te veel geheugen in beslag nemen.
Als u bevestigt dat PostgreSQL verantwoordelijk is voor dit probleem, is de volgende stap om te controleren waarom.
Het PostgreSQL-logboek gebruiken
Het controleren van zowel de PostgreSQL- als de systeemlogboeken is zeker een goede manier om meer informatie te krijgen over wat er in uw database/systeem gebeurt. U kunt berichten zien als:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childAls je niet genoeg vrij geheugen hebt.
Of zelfs meerdere fouten in databaseberichten zoals:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedAls u onverwacht gedrag vertoont aan de databasezijde. De logboeken zijn dus handig om dit soort problemen en zelfs meer op te sporen. U kunt deze controle automatiseren door de logbestanden te ontleden op zoek naar werken als "FATAL", "ERROR" of "Kill", zodat u een waarschuwing ontvangt wanneer dit gebeurt.
Pg_top gebruiken
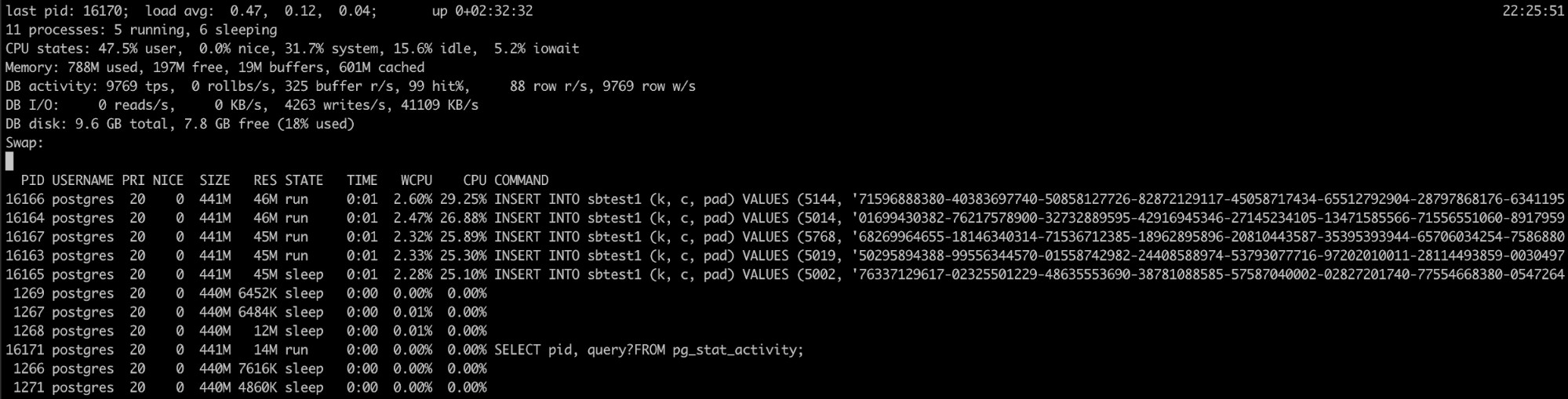
Als u weet dat het PostgreSQL-proces veel geheugen gebruikt, maar de logs hebben niet geholpen, je hebt een ander hulpmiddel dat hier nuttig kan zijn, pg_top.
Deze tool is vergelijkbaar met de top-linux-tool, maar is specifiek voor PostgreSQL. Dus als je het gebruikt, heb je meer gedetailleerde informatie over wat er in je database draait, en je kunt zelfs query's doden of een explain-taak uitvoeren als je iets verkeerds ontdekt. U kunt hier meer informatie over deze tool vinden.
Maar wat gebeurt er als je geen enkele fout kunt ontdekken en de database nog steeds veel RAM-geheugen gebruikt? U zult dus waarschijnlijk de databaseconfiguratie moeten controleren.
Met welke configuratieparameters rekening moet worden gehouden
Als alles er goed uitziet, maar je hebt nog steeds het probleem met hoge belasting, moet je de configuratie controleren om te bevestigen of deze correct is. De volgende parameters zijn dus parameters waarmee u in dit geval rekening moet houden.
gedeelde_buffers
Dit is de hoeveelheid geheugen die de databaseserver gebruikt voor gedeelde geheugenbuffers. Als deze waarde te laag is, zou de database meer schijf gebruiken, wat meer traagheid zou veroorzaken, maar als deze waarde te hoog is, zou dit een hoog geheugengebruik kunnen veroorzaken. Volgens de documentatie is 25% van het geheugen in uw systeem een redelijke startwaarde voor shared_buffers als u een speciale databaseserver met 1 GB of meer RAM heeft.
werk_mem
Het specificeert de hoeveelheid geheugen die zal worden gebruikt door ORDER BY, DISTINCT en JOIN voordat naar de tijdelijke bestanden op schijf wordt geschreven. Net als bij de shared_buffers, kunnen we, als we deze parameter te laag configureren, meer bewerkingen naar de schijf laten gaan, maar te hoog is gevaarlijk voor het geheugengebruik. De standaardwaarde is 4 MB.
max_connections
Work_mem gaat ook hand in hand met de waarde max_connections, aangezien elke verbinding deze bewerkingen tegelijkertijd zal uitvoeren en elke bewerking zoveel geheugen mag gebruiken als gespecificeerd door deze waarde ervoor begint gegevens in tijdelijke bestanden te schrijven. Deze parameter bepaalt het maximale aantal gelijktijdige verbindingen met onze database. Als we een groot aantal verbindingen configureren en hier geen rekening mee houden, kunt u bronproblemen krijgen. De standaardwaarde is 100.
temp_buffers
De tijdelijke buffers worden gebruikt om de tijdelijke tabellen op te slaan die in elke sessie worden gebruikt. Deze parameter stelt de maximale hoeveelheid geheugen in voor deze taak. De standaardwaarde is 8 MB.
onderhoud_werk_mem
Dit is het maximale geheugen dat een bewerking zoals Stofzuigen, het toevoegen van indexen of externe sleutels kan verbruiken. Het goede ding is dat er maar één bewerking van dit type in een sessie kan worden uitgevoerd, en het is niet gebruikelijk om meerdere van deze tegelijkertijd in het systeem uit te voeren. De standaardwaarde is 64 MB.
autovacuum_work_mem
Het vacuüm gebruikt standaard de maintenance_work_mem, maar we kunnen deze scheiden met deze parameter. We kunnen hier de maximale hoeveelheid geheugen specificeren die door elke autovacuümwerker moet worden gebruikt.
wal_buffers
De hoeveelheid gedeeld geheugen die wordt gebruikt voor WAL-gegevens die nog niet naar de schijf zijn geschreven. De standaardinstelling is 3% van shared_buffers, maar niet minder dan 64 kB en niet meer dan de grootte van één WAL-segment, doorgaans 16 MB.
Conclusie
Er zijn verschillende redenen voor een hoog geheugengebruik en het detecteren van het rootprobleem kan een tijdrovende taak zijn. In deze blog hebben we verschillende manieren genoemd om uw PostgreSQL-geheugengebruik te controleren en met welke parameter u rekening moet houden om het af te stemmen, om overmatig geheugengebruik te voorkomen.