Hoewel er verschillende manieren zijn om uw PostgreSQL-database te herstellen, is dit een van de handigste manieren om uw gegevens te herstellen vanaf een logische back-up. Logische back-ups spelen een belangrijke rol voor Disaster and Recovery Planning (DRP). Logische back-ups zijn back-ups die bijvoorbeeld worden gemaakt met pg_dump of pg_dumpall, die SQL-instructies genereren om alle tabelgegevens te verkrijgen die naar een binair bestand zijn geschreven.
Het wordt ook aanbevolen om periodieke logische back-ups uit te voeren voor het geval uw fysieke back-ups mislukken of niet beschikbaar zijn. Voor PostgreSQL kan herstellen problematisch zijn als u niet zeker weet welke tools u moet gebruiken. De back-uptool pg_dump wordt gewoonlijk gecombineerd met de hersteltool pg_restore.
pg_dump en pg_restore werken samen als zich een ramp voordoet en u uw gegevens moet herstellen. Hoewel ze het primaire doel van dump en herstel dienen, vereist het dat u enkele extra taken uitvoert wanneer u uw cluster moet herstellen en een failover moet uitvoeren (als uw actieve primaire of master sterft als gevolg van hardwarestoringen of beschadiging van het VM-systeem). U zult uiteindelijk tools van derden vinden en gebruiken die failover of automatisch clusterherstel aankunnen.
In deze blog bekijken we hoe pg_restore werkt en vergelijken we dit met hoe ClusterControl omgaat met back-up en herstel van uw gegevens voor het geval er een ramp optreedt.
Mechanismen van pg_restore
pg_restore is handig bij het verkrijgen van de volgende taken:
- in combinatie met pg_dump voor het genereren van door SQL gegenereerde bestanden met gegevens, toegangsrollen, database- en tabeldefinities
- herstel een PostgreSQL-database uit een archief gemaakt door pg_dump in een van de niet-platte tekst-indelingen.
- Het zal de commando's geven die nodig zijn om de database te reconstrueren naar de staat waarin deze zich bevond op het moment dat deze werd opgeslagen.
- heeft de mogelijkheid om selectief te zijn of zelfs om de items opnieuw te ordenen voordat ze worden hersteld op basis van het archiefbestand
- De archiefbestanden zijn ontworpen om over verschillende architecturen te worden overgedragen.
- pg_restore kan in twee modi werken.
- Als een databasenaam is opgegeven, maakt pg_restore verbinding met die database en herstelt de archiefinhoud rechtstreeks in de database.
- of er wordt een script gemaakt dat de SQL-commando's bevat die nodig zijn om de database opnieuw op te bouwen en naar een bestand of standaarduitvoer geschreven. De uitvoer van het script is gelijkwaardig aan het formaat dat wordt gegenereerd door pg_dump
- Sommige van de opties die de uitvoer regelen, zijn daarom analoog aan pg_dump-opties.
Als je de gegevens eenmaal hebt hersteld, is het het beste en raadzaam om ANALYSE op elke herstelde tabel uit te voeren, zodat de optimizer bruikbare statistieken heeft. Hoewel het READ LOCK verkrijgt, moet u dit mogelijk uitvoeren tijdens weinig verkeer of tijdens uw onderhoudsperiode.
Voordelen van pg_restore
pg_dump en pg_restore hebben samen mogelijkheden die handig zijn voor een DBA om te gebruiken.
- pg_dump en pg_restore kunnen parallel worden uitgevoerd door de optie -j op te geven. Met behulp van de -j/--jobs
kunt u specificeren hoeveel actieve jobs parallel kunnen lopen, met name voor het laden van gegevens, het maken van indexen of het creëren van beperkingen met behulp van meerdere gelijktijdige jobs. - Het is best handig om te gebruiken, je kunt selectief specifieke databases of tabellen dumpen of laden
- Het staat en biedt een gebruiker flexibiliteit over welke specifieke database, schema of herschikking van de procedures die moeten worden uitgevoerd op basis van de lijst. U kunt de reeks SQL zelfs losjes genereren en laden, zoals het voorkomen van acls of privileges in overeenstemming met uw behoeften. Er zijn tal van opties om aan uw behoeften te voldoen.
- Het biedt je de mogelijkheid om SQL-bestanden te genereren, net als pg_dump vanuit een archief. Dit is erg handig als u naar een andere database of host wilt laden om een aparte omgeving in te richten.
- Het is gemakkelijk te begrijpen op basis van de gegenereerde reeks SQL-procedures.
- Het is een handige manier om gegevens in een replicatieomgeving te laden. U hoeft uw replica niet opnieuw op te bouwen, aangezien de instructies SQL zijn die zijn gerepliceerd naar de stand-by- en herstelknooppunten.
Beperkingen van pg_restore
Voor logische back-ups zijn de duidelijke beperkingen van pg_restore samen met pg_dump de prestaties en snelheid bij het gebruik van de tools. Het kan handig zijn wanneer u een test- of ontwikkeldatabaseomgeving wilt inrichten en uw gegevens wilt laden, maar het is niet van toepassing wanneer uw dataset enorm is. PostgreSQL moet uw gegevens één voor één dumpen of uw gegevens opeenvolgend uitvoeren en toepassen door de database-engine. Hoewel je dit losjes flexibel kunt maken om te versnellen, zoals het specificeren van -j of het gebruik van --single-transaction om impact op je database te voorkomen, moet het laden met SQL nog steeds door de engine worden geparseerd.
Bovendien vermeldt de PostgreSQL-documentatie de volgende beperkingen, met onze toevoegingen zoals we deze tools hebben waargenomen (pg_dump en pg_restore):
- Bij het herstellen van gegevens naar een reeds bestaande tabel en de optie --disable-triggers wordt gebruikt, zendt pg_restore opdrachten uit om triggers op gebruikerstabellen uit te schakelen voordat de gegevens worden ingevoegd, en zendt vervolgens opdrachten uit om ze opnieuw in te schakelen nadat de gegevens zijn ingevoerd. Als het herstel halverwege wordt gestopt, kunnen de systeemcatalogi in de verkeerde staat blijven.
- pg_restore kan grote objecten niet selectief herstellen; bijvoorbeeld alleen die voor een specifieke tabel. Als een archief grote objecten bevat, worden alle grote objecten hersteld, of geen ervan als ze zijn uitgesloten via -L, -t of andere opties.
- Beide tools zullen naar verwachting een enorme hoeveelheid grootte genereren (bestanden, directory of tar-archief), vooral voor een enorme database.
- Voor pg_dump, bij het dumpen van een enkele tabel of als platte tekst, verwerkt pg_dump geen grote objecten. Grote objecten moeten met de hele database worden gedumpt met behulp van een van de niet-tekstarchiefindelingen.
- Als je tar-archieven hebt die door deze tools zijn gegenereerd, houd er dan rekening mee dat tar-archieven beperkt zijn tot een grootte van minder dan 8 GB. Dit is een inherente beperking van het tar-bestandsformaat. Daarom kan dit formaat niet worden gebruikt als de tekstuele weergave van een tabel die grootte overschrijdt. De totale grootte van een tar-archief en alle andere uitvoerformaten is niet beperkt, behalve mogelijk door het besturingssysteem.
Pg_restore gebruiken
Het gebruik van pg_restore is best handig en gemakkelijk te gebruiken. Omdat het gekoppeld is aan pg_dump, werken beide tools voldoende goed zolang de doeloutput bij de andere past. De volgende pg_dump is bijvoorbeeld niet nuttig voor pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Dit resultaat zal een psql-compatibel zijn die er als volgt uitziet:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Maar dit zal mislukken voor pg_restore omdat er geen duidelijk formaat is om te volgen:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerLaten we nu naar meer nuttige termen gaan voor pg_restore.
pg_restore:verwijderen en herstellen
Overweeg een eenvoudig gebruik van pg_restore waarvoor je een database hebt neergezet, bijvoorbeeld
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Herstellen met pg_restore is heel eenvoudig,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump De -C/--create hier geeft aan dat de database wordt gemaakt zodra deze in de header wordt aangetroffen. De -d postgres verwijst naar de postgres-database, maar dit betekent niet dat het de tabellen naar de postgres-database zal maken. Het vereist dat de database bestaat. Als -C niet is opgegeven, worden tabel(len) en records opgeslagen in die database waarnaar wordt verwezen met het argument -d.
Selectief herstellen per tabel
Het herstellen van een tabel met pg_restore is gemakkelijk en eenvoudig. U hebt bijvoorbeeld twee tabellen, namelijk "b" en "d" tabellen. Laten we zeggen dat u de volgende pg_dump-opdracht hieronder uitvoert,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Waar de inhoud van deze map er als volgt uit zal zien,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Als je een tabel wilt herstellen (namelijk "d" in dit voorbeeld),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Zal hebben,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:databasetabellen kopiëren naar een andere database
Je mag zelfs de inhoud van je bestaande database kopiëren en op je doeldatabase zetten. Ik heb bijvoorbeeld de volgende databases,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)De paultest-database is een lege database, terwijl we gaan kopiëren wat zich in de maxtest-database bevindt,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Om het te kopiëren, moeten we de gegevens uit de maxtest-database als volgt dumpen,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Laad of herstel het dan als volgt,
We hebben nu gegevens over de paultest-database en de tabellen zijn dienovereenkomstig opgeslagen.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Genereer een SQL-bestand met opnieuw bestellen
Ik heb veel gebruik gezien van pg_restore, maar het lijkt erop dat deze functie meestal niet wordt getoond. Ik vond deze aanpak erg interessant omdat je hiermee kunt bestellen op basis van wat je niet wilt opnemen en vervolgens een SQL-bestand kunt genereren op basis van de volgorde waarin je wilt doorgaan.
We gebruiken bijvoorbeeld het voorbeeld pgdump_data.tar dat we eerder hebben gegenereerd en maken een lijst. Voer hiervoor de volgende opdracht uit:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listHiermee wordt een bestand gegenereerd zoals hieronder weergegeven:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresLaten we het nu opnieuw ordenen of zullen we zeggen dat ik de aanmaak van SEQUENCE en ook de aanmaak van de beperking heb verwijderd. Dit zou er als volgt uitzien,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresAls u het bestand in SQL-indeling wilt genereren, doet u het volgende:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Het bestand /tmp/selective_data.out zal een door SQL gegenereerd bestand zijn en dit is leesbaar als je psql gebruikt, maar niet pg_restore. Het mooie hiervan is dat je een SQL-bestand kunt genereren in overeenstemming met je sjabloon waarop alleen gegevens kunnen worden hersteld uit een bestaand archief of een back-up die is gemaakt met pg_dump met behulp van pg_restore.
PostgreSQL-herstel met ClusterControl
ClusterControl maakt geen gebruik van pg_restore of pg_dump als onderdeel van zijn functieset. We gebruiken pg_dumpall om logische back-ups te maken en helaas is de uitvoer niet compatibel met pg_restore.
Er zijn verschillende andere manieren om een back-up te maken in PostgreSQL, zoals hieronder te zien is.
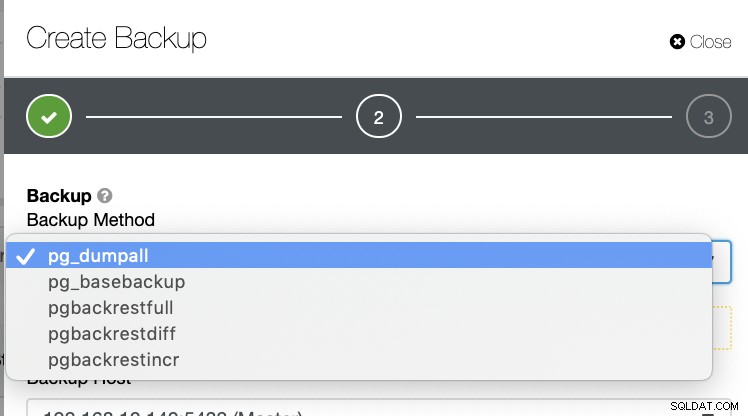
Er is geen dergelijk mechanisme waarmee u selectief een tabel, een database, of kopieer van de ene database naar een andere database.
ClusterControl ondersteunt wel Point-in-Time Recovery (PITR), maar hierdoor kunt u gegevensherstel niet zo flexibel beheren als met pg_restore. Voor de hele lijst met back-upmethoden zijn alleen pg_basebackup en pgbackrest geschikt voor PITR.
Hoe ClusterControl het herstel afhandelt, is dat het de mogelijkheid heeft om een mislukt cluster te herstellen zolang Auto Recovery is ingeschakeld, zoals hieronder wordt weergegeven.

Zodra de master faalt, kan de slave het cluster automatisch herstellen zoals ClusterControl doet de failover (die automatisch wordt gedaan). Voor het gegevensherstelgedeelte is uw enige optie een clusterbreed herstel, wat betekent dat het afkomstig is van een volledige back-up. Er is geen mogelijkheid om selectief te herstellen op de doeldatabase of -tabel die u alleen wilde herstellen. Wil je dat toch doen, zet dan de volledige back-up terug, dit kan eenvoudig met ClusterControl. U kunt naar de Back-up-tabbladen gaan zoals hieronder weergegeven,
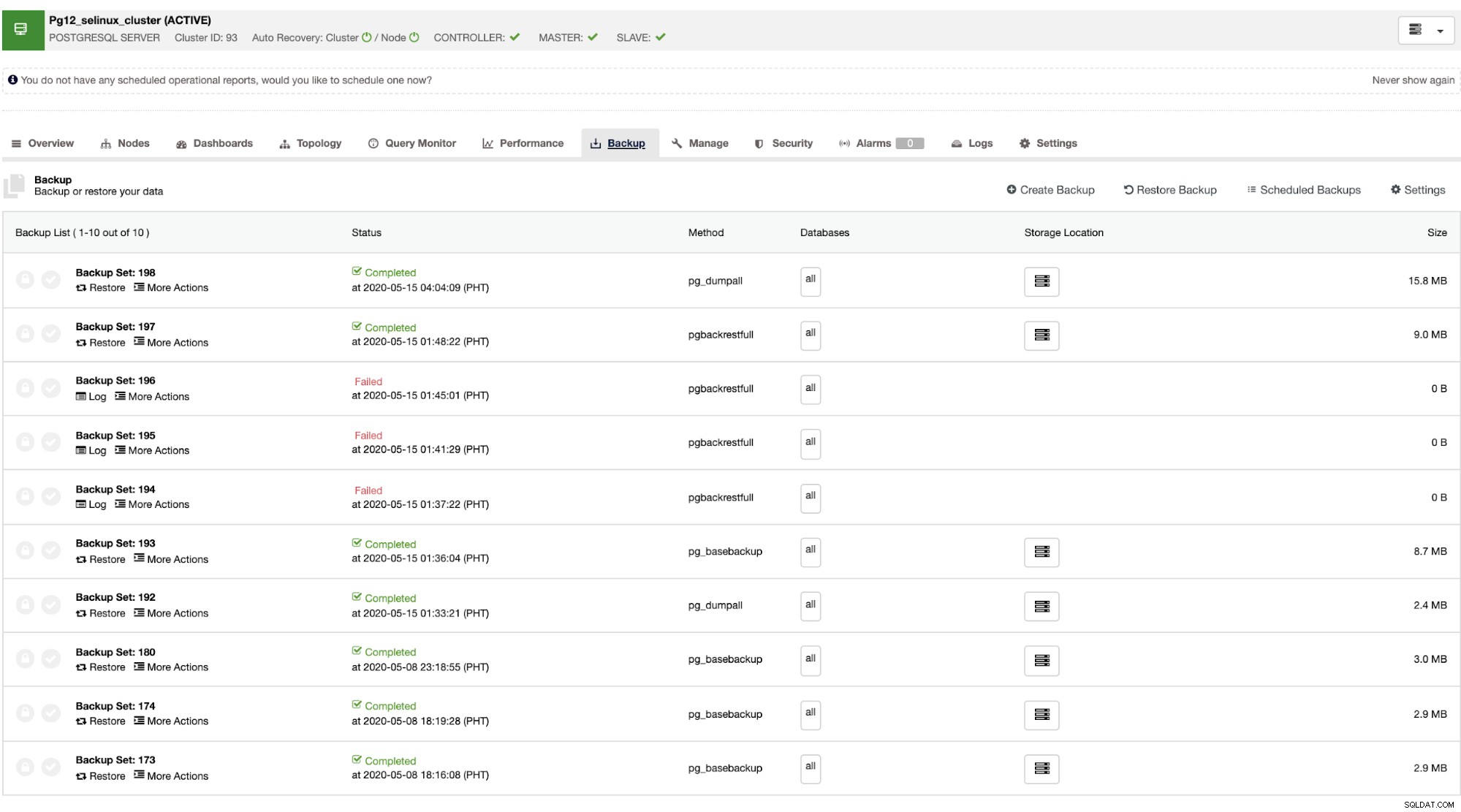
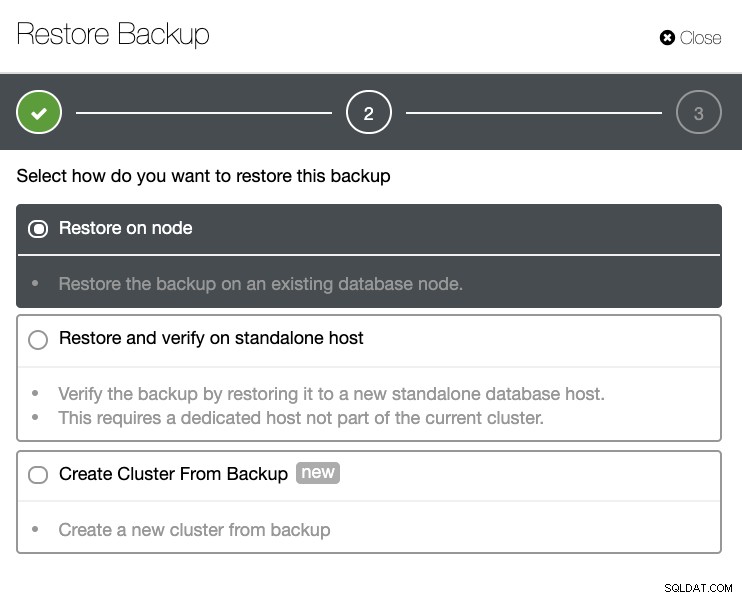
Je hebt een volledige lijst met geslaagde en mislukte back-ups. Vervolgens kan het herstellen worden gedaan door de doelback-up te kiezen en op de knop "Herstellen" te klikken. Hiermee kunt u herstellen op een bestaande node die is geregistreerd in ClusterControl, of verifiëren op een stand-alone node, of een cluster maken van de back-up.
Conclusie
Het gebruik van pg_dump en pg_restore vereenvoudigt de back-up/dump- en herstelaanpak. Voor een grootschalige databaseomgeving is dit echter mogelijk geen ideaal onderdeel voor noodherstel. Voor een minimale selectie- en herstelprocedure biedt het gebruik van de combinatie van pg_dump en pg_restore u de mogelijkheid om uw gegevens te dumpen en te laden volgens uw behoeften.
Voor productieomgevingen (vooral voor enterprise-architecturen) kunt u de ClusterControl-aanpak gebruiken om een back-up te maken en terug te zetten met automatisch herstel.
Een combinatie van benaderingen is ook een goede benadering. Dit helpt u uw RTO en RPO te verlagen en tegelijkertijd te profiteren van de meest flexibele manier om uw gegevens te herstellen wanneer dat nodig is.