Een van de belangrijkste aspecten van hoge beschikbaarheid is de mogelijkheid om snel te reageren op storingen. Het is niet ongebruikelijk om databases handmatig te beheren en monitoringsoftware te hebben om de gezondheid van de database in de gaten te houden. Bij een storing stuurt de monitoringsoftware een waarschuwing naar de oproepkrachten. Dit betekent dat iemand mogelijk wakker moet worden, naar een computer moet gaan en in systemen moet inloggen en logs moet bekijken - dat wil zeggen, er is nogal wat doorlooptijd voordat het herstel kan beginnen. Idealiter zou het hele proces geautomatiseerd moeten zijn.
In deze blog bekijken we hoe we een volledig geautomatiseerd systeem kunnen implementeren dat detecteert wanneer de primaire database faalt en failover-procedures initieert door een secundaire database te promoten. We zullen ClusterControl gebruiken om automatische failover van de Moodle PostgreSQL-database uit te voeren.
Voordeel van automatische failover
- Minder tijd om de databaseservice te herstellen
- Hogere uptime van het systeem
- Minder afhankelijkheid van de DBA of beheerder die hoge beschikbaarheid voor de database heeft ingesteld
Architectuur
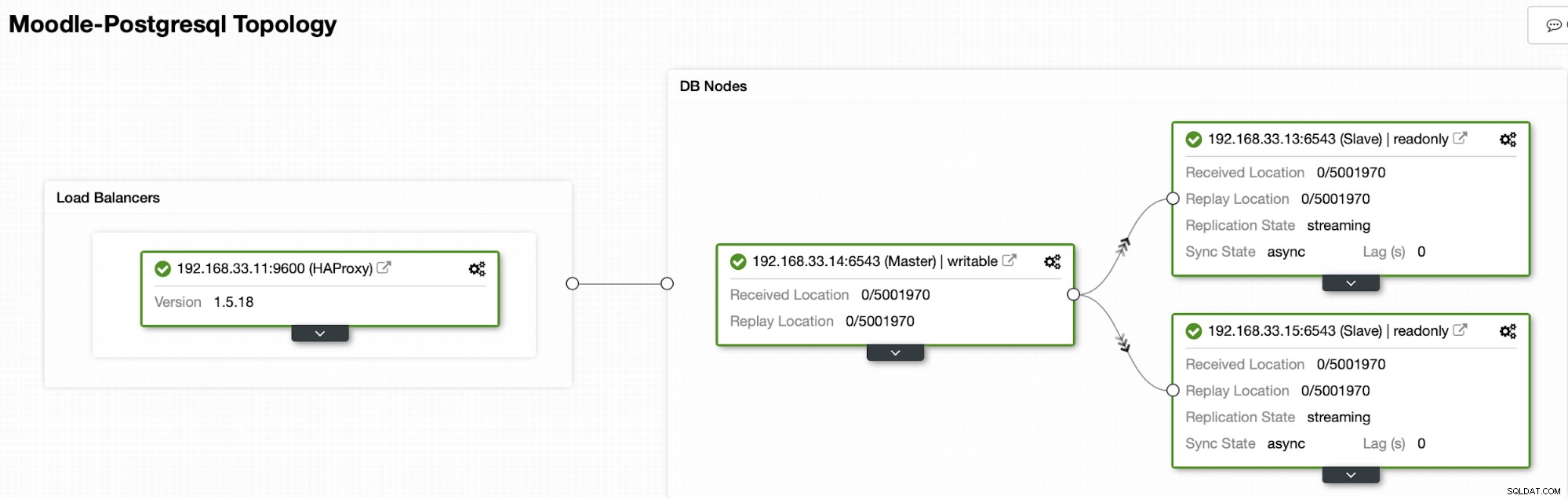
Momenteel hebben we een primaire Postgres-server en twee secundaire servers onder HAProxy-load balancer die het Moodle-verkeer naar het primaire PostgreSQL-knooppunt stuurt. Clusterherstel en automatisch herstel van knooppunten in ClusterControl zijn de belangrijke instellingen om het automatische failoverproces uit te voeren.

Bepalen naar welke server een failover moet worden uitgevoerd
ClusterControl biedt whitelisting en blacklisting van een set servers die u wilt laten deelnemen aan de failover, of die u wilt uitsluiten als kandidaat.
Er zijn twee variabelen die u kunt instellen in de cmon-configuratie,
- replication_failover_whitelist :het bevat een lijst met IP's of hostnamen van secundaire servers die als potentiële primaire kandidaten moeten worden gebruikt. Als deze variabele is ingesteld, worden alleen die hosts in aanmerking genomen.
- replication_failover_blacklist :het bevat een lijst met hosts die nooit als een primaire kandidaat zullen worden beschouwd. U kunt het gebruiken om secundaire servers weer te geven die worden gebruikt voor back-ups of analytische query's. Als de hardware verschilt tussen secundaire servers, kunt u hier de servers plaatsen die langzamere hardware gebruiken.
Automatisch failoverproces
Stap 1
We zijn begonnen met het laden van gegevens op de primaire server (192.168.33.14) met behulp van de sysbench-tool.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Stap 2
We gaan de primaire server van Postgres stoppen (192.168.33.14). In ClusterControl is de parameter (enable_cluster_autorecovery) ingeschakeld, zodat deze de volgende geschikte primaire promoot.
# service postgresql-12 stopStap 3
ClusterControl detecteert fouten in de primaire en bevordert een secundaire met de meest actuele gegevens als een nieuwe primaire. Het werkt ook op de rest van de secundaire servers om ze te laten repliceren vanaf de nieuwe primaire.

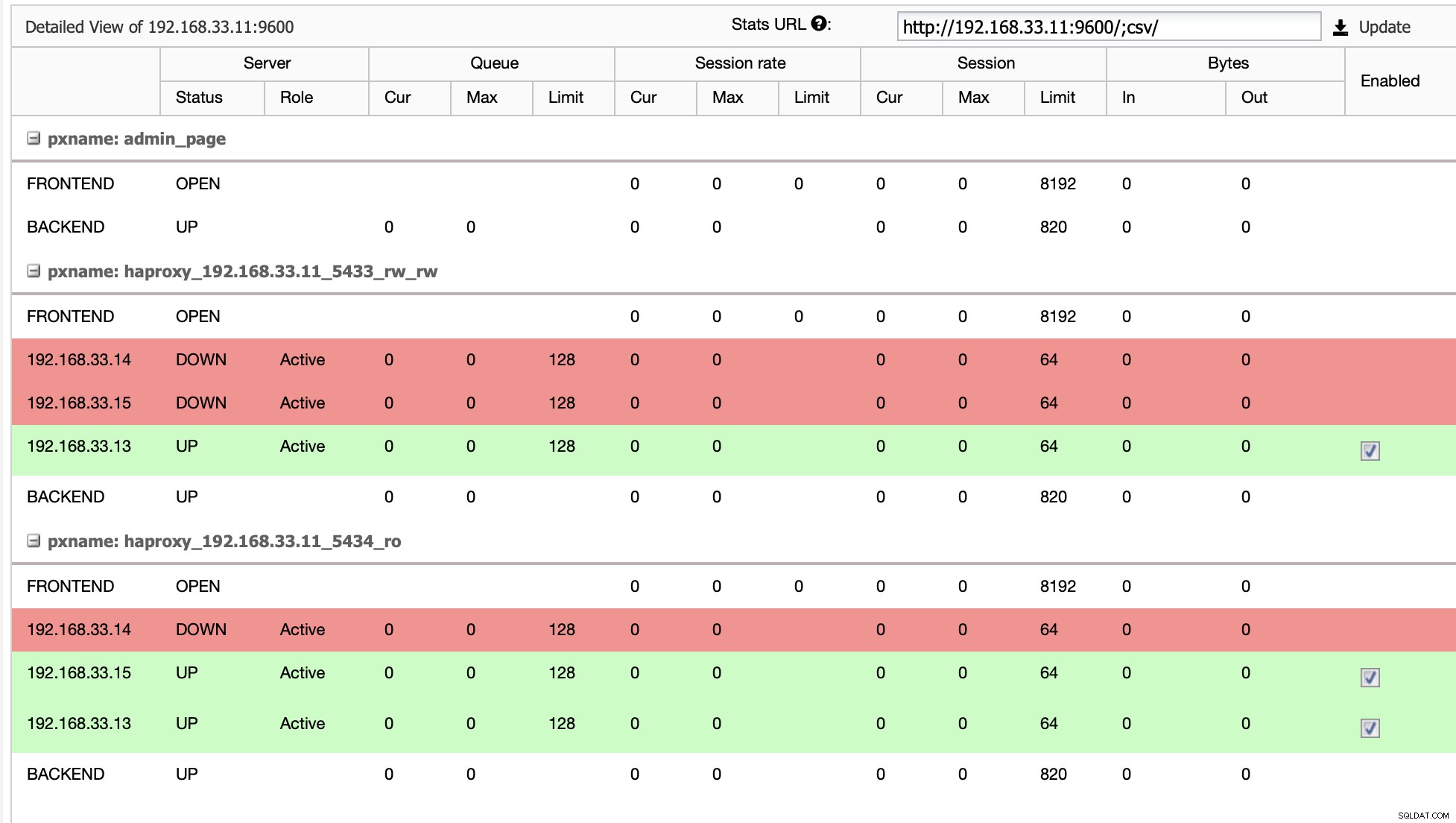
In ons geval is de (192.168.33.13) een nieuwe primaire server en secundaire servers repliceren nu vanaf deze nieuwe primaire server. Nu leidt de HAProxy het databaseverkeer van de Moodle-servers naar de nieuwste primaire server.
Van (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Van (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Huidige topologie
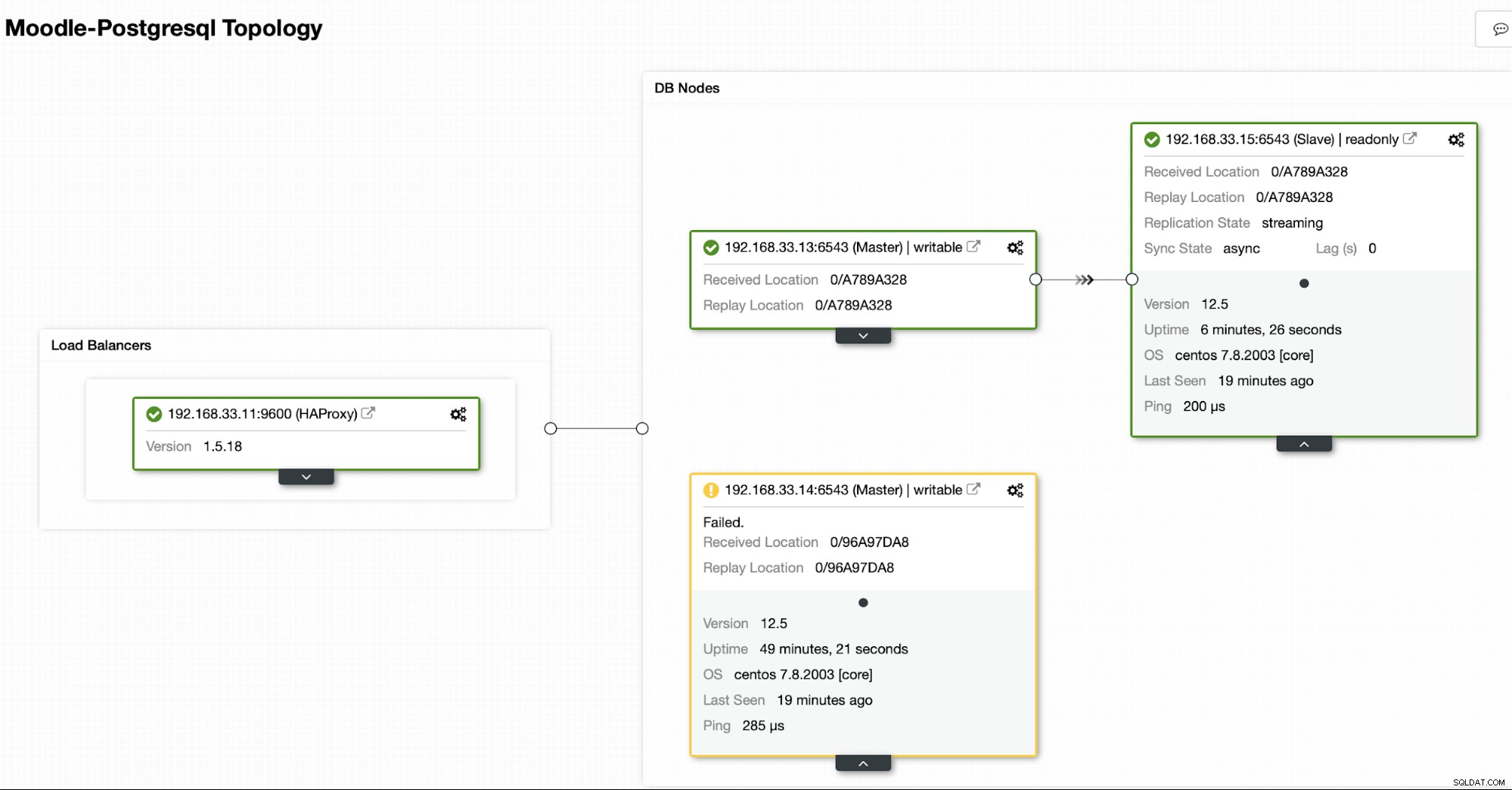
Als HAProxy detecteert dat een van onze nodes, primair of replica, niet toegankelijk is, wordt het automatisch gemarkeerd als offline. HAProxy stuurt geen verkeer van de Moodle-app ernaartoe. Deze controle wordt uitgevoerd door scripts voor gezondheidscontrole die zijn geconfigureerd door ClusterControl op het moment van implementatie.
Zodra ClusterControl een replicaserver naar primair promoot, markeert onze HAProxy de oude primaire als offline en zet het gepromote knooppunt online.
Zodra de oude primaire server weer online is, wordt deze niet automatisch gesynchroniseerd met de nieuwe primaire server. We moeten het terug in de topologie laten, en dat kan via de ClusterControl-interface. Dit voorkomt de mogelijkheid van gegevensverlies of inconsistentie, voor het geval we willen onderzoeken waarom die server in de eerste plaats faalde.
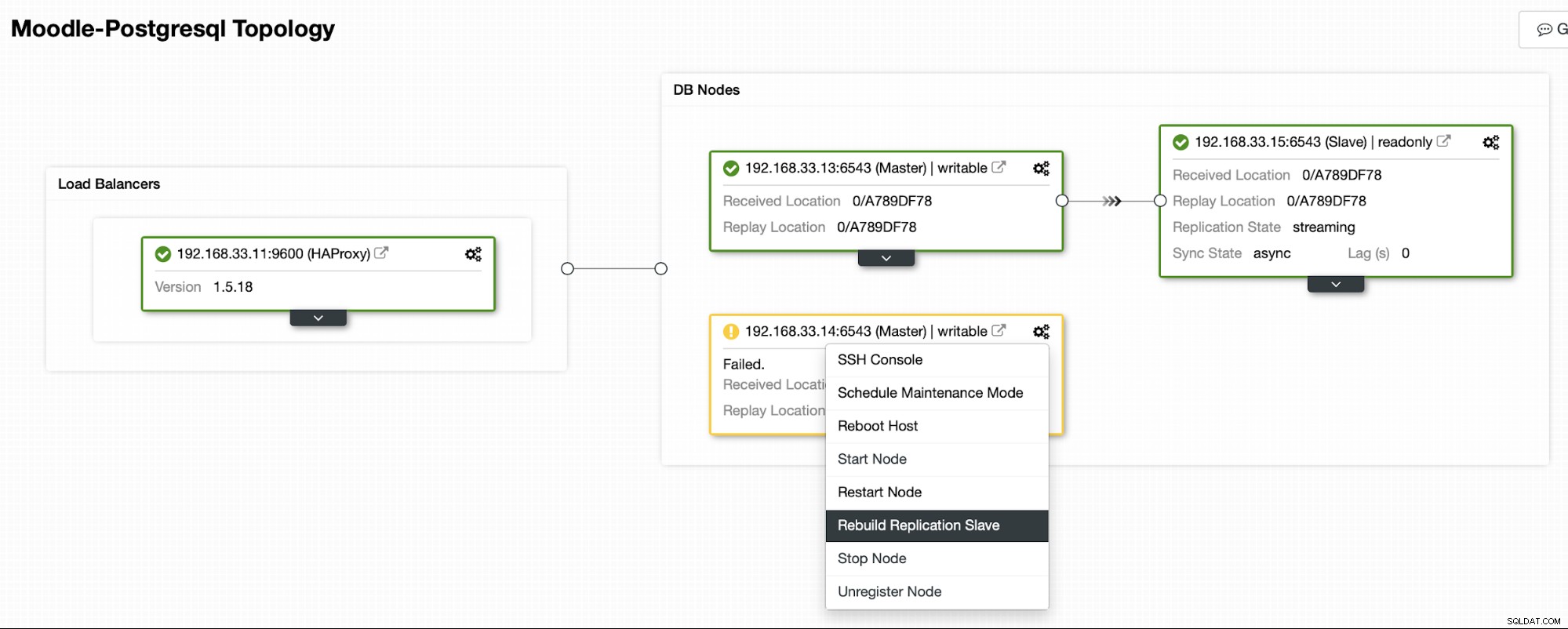
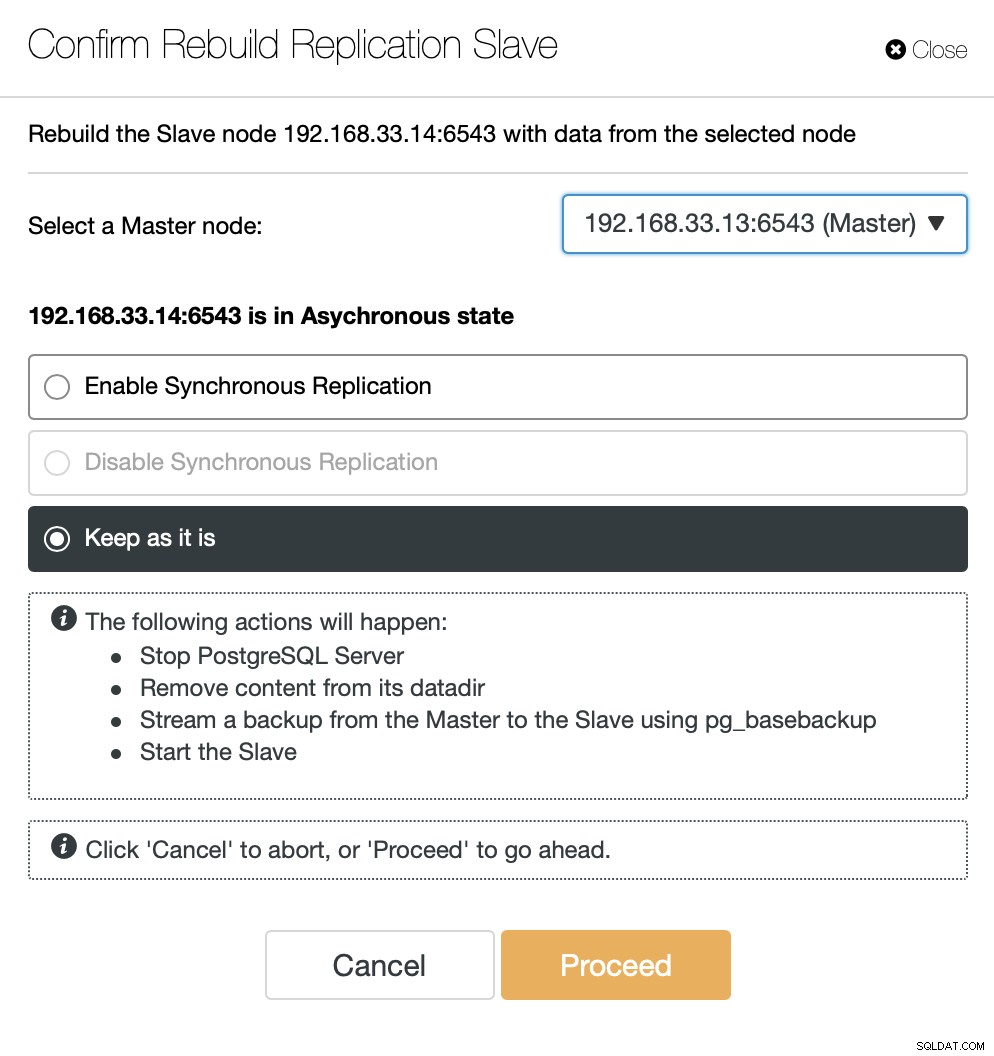
ClusterControl zal een back-up streamen vanaf de nieuwe primaire server en de replicatie configureren.
Conclusie
Automatische failover is een belangrijk onderdeel van elke Moodle-productiedatabase. Het kan downtime verminderen wanneer een server uitvalt, maar ook bij het uitvoeren van algemene onderhoudstaken of migraties. Het is belangrijk om het goed te doen, omdat het belangrijk is dat de failover-software de juiste beslissingen neemt.