Het onderwerp caching verscheen al 22 jaar geleden in PostgreSQL en toen lag de nadruk op databasebetrouwbaarheid.
Snel vooruit naar 2020, de schijfschotels zijn nog dieper verborgen in gevirtualiseerde omgevingen, hypervisors en bijbehorende opslagapparaten. Bovendien schreeuwen onderling verbonden, gedistribueerde applicaties die op wereldwijde schaal werken om verbindingen met lage latentie en plotselinge afstemming van servercaches, en SQL-query's concurreren om ervoor te zorgen dat de resultaten binnen milliseconden aan clients worden geretourneerd. Applicatieniveau en in-memory caches worden geboren en leesquery's worden nu dichtbij de applicatieservers opgeslagen. Als gevolg hiervan worden I/O-bewerkingen beperkt tot alleen schrijven en wordt de netwerklatentie drastisch verbeterd. Met één vangst. Implementaties zijn verantwoordelijk voor hun eigen cachebeheer, wat soms leidt tot prestatievermindering.
Cache schrijven is een veel gecompliceerdere zaak, zoals uitgelegd in de PostgreSQL-wiki.
Deze blog is een overzicht van de in-memory querycaches en load balancers die worden gebruikt met PostgreSQL.
PostgreSQL-taakverdeling
Het idee van load balancing ontstond op hetzelfde moment als caching, in 1999, toen Bruce Momjiam schreef:
[...] het is mogelijk dat we in de nabije toekomst _zeer_ populair zijn.
De basis voor het implementeren van taakverdeling in PostgreSQL wordt geleverd door de ingebouwde Hot Standby-functie. De enige vereiste is dat de toepassing de failover afhandelt en dit is waar oplossingen van derden van pas komen. We zullen enkele van die oplossingen in de volgende secties bekijken.
Uitgebalanceerde query's kunnen alleen consistente resultaten opleveren zolang de vertraging bij synchrone replicatie laag wordt gehouden. In de praktijk kan zelfs de modernste netwerkinfrastructuur, zoals AWS, vertragingen van tientallen milliseconden vertonen:
We observeren meestal vertragingstijden in de 10s van milliseconden. [...] Onder normale omstandigheden is een replicatievertraging van een minuut gebruikelijk. [...]
Replica's in verschillende regio's die logische replicatie gebruiken, worden beïnvloed door de wijzigings-/toepassingssnelheid en vertragingen in de netwerkcommunicatie tussen de specifieke geselecteerde regio's. Replica's tussen regio's die Aurora Global Database gebruiken, hebben een typische vertraging van minder dan een seconde.
Zoals eerder vermeld, zijn de oplossingen van derden afhankelijk van de kernfuncties van PostgreSQL. De taakverdeling van leesquery's wordt bijvoorbeeld bereikt met behulp van meerdere synchrone standbys.
Oplossingen
pgpool-II
pgpool-II is een product met veel functies dat zowel taakverdeling als in-memory querycaching biedt. Het is een drop-in vervanging, er zijn geen wijzigingen aan de applicatiezijde vereist.
Als load balancer onderzoekt pgpool-II elke SQL-query — om load-balanced te zijn, moeten SELECT-query's aan verschillende voorwaarden voldoen.
De installatie kan zo eenvoudig zijn als één knooppunt, hieronder wordt een cluster met twee knooppunten weergegeven:
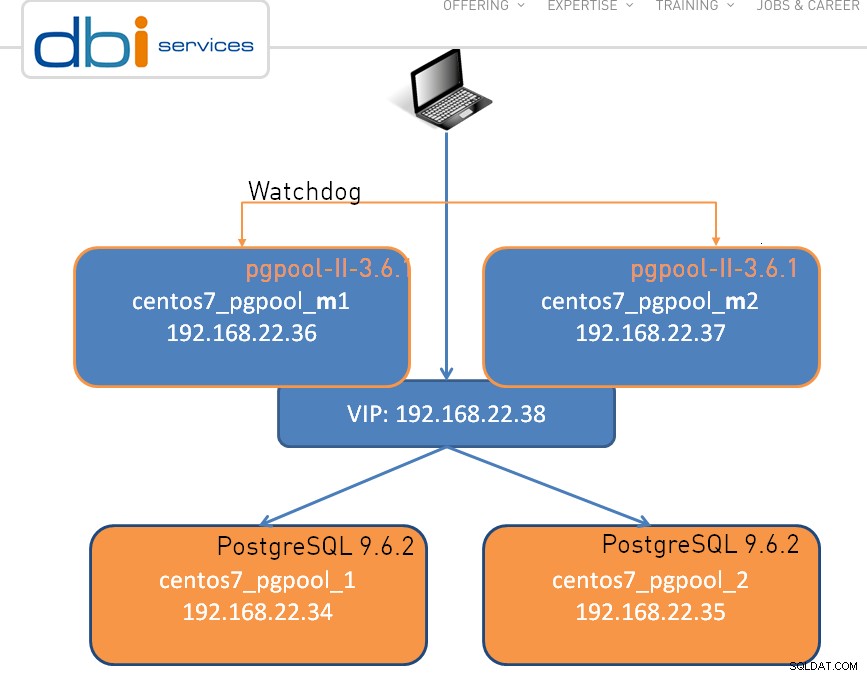
Zoals het geval is met elk geweldig stuk software, zijn er bepaalde beperkingen , en pgpool-II maakt geen uitzondering:
- Het behandelt geen zoekopdrachten met meerdere instructies.
- SELECT-query's op tijdelijke tabellen vereisen het /*NO LOAD BALANCE*/ SQL-commentaar.
Applicaties die worden uitgevoerd in omgevingen met hoge prestaties zullen profiteren van een gemengde configuratie waarbij pgBouncer de pooler voor verbindingen is en pgpool-II de taakverdeling en caching afhandelt. Het resultaat is een indrukwekkende 4 keer snellere doorvoer en een latentiereductie van 40 procent:
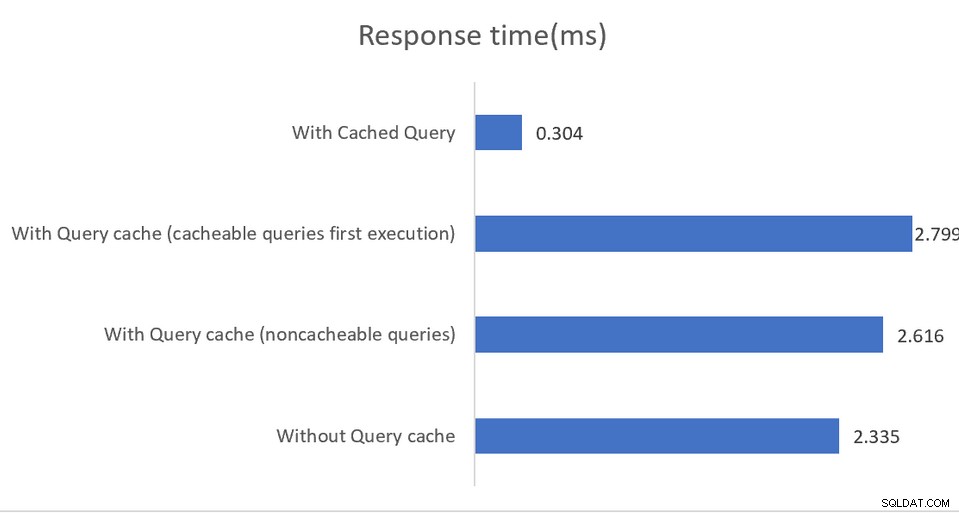
In-memory caching werkt, wederom, alleen bij leesquery's, met cache gegevens worden opgeslagen in het gedeelde geheugen of in een externe memcached-installatie. Hoewel de documentatie redelijk goed is in het uitleggen van de verschillende configuratie-opties, suggereert het indirect dat implementaties de SHOW POOL CACHE-uitvoer moeten controleren om te waarschuwen voor hitratio's die onder de 70% vallen, op welk punt de prestatiewinst die door caching wordt geleverd, verloren gaat.
Bucardo
Bucardo is een PostgreSQL-replicatietool geschreven in Perl en PL/Perl.
Ik heb Bucardo genoemd, omdat load balancing een van de functies is, maar volgens de PostgreSQL-wiki levert een zoekopdracht op internet geen relevante resultaten op. Om te verduidelijken ging ik naar de officiële documentatie die ingaat op de details van hoe de software echt werkt:

Dat maakt het vrij duidelijk, Bucardo is geen load balancer, net zoals werd gewezen door de mensen van Database Soup.
HAProxy
HAProxy is een load balancer voor algemene doeleinden die op TCP-niveau werkt (ten behoeve van databaseverbindingen). Gezondheidscontroles zorgen ervoor dat zoekopdrachten alleen naar actieve knooppunten worden verzonden.
Vergeleken met pgpool-II, moeten toepassingen die HAProxy gebruiken als een load balancer, bewust worden gemaakt van de eindpuntverzendingsverzoeken naar leesknooppunten.
Apache Ignite
Apache Ignite is een cache op het tweede niveau die ANSI-99 SQL begrijpt en ondersteuning biedt voor ACID-transacties. Apache Ignite begrijpt het PostgreSQL Frontend/Backend Protocol niet en daarom moeten applicaties een persistentielaag gebruiken, zoals Hibernate ORM. Als alternatief voor het wijzigen van applicaties biedt Apache Ignite `memcached integratie`_ waarvoor de memcached PostgreSQL-extensie vereist is. Helaas is deze laatste optie niet compatibel met recente versies van PostgreSQL, aangezien de pgmemcache-extensie voor het laatst is bijgewerkt in 2017.
Heimdall-gegevens
Als commercieel product vinkt Heimdall Data beide vakjes aan:load balancing en caching. Het is een volwassen product, dat al in PGCon 2017 werd getoond op PostgreSQL-conferenties:

Meer details en een productdemo zijn te vinden op de Azure for PostgreSQL-blog .
Conclusie
In het huidige gedistribueerde computergebruik zijn Query Caching en Load Balancing net zo belangrijk voor het afstemmen van PostgreSQL-prestaties als de bekende GUC's, OS-kernel, opslag en query-optimalisatie. Hoewel pgpool-II en Heimdall Data de open source en respectievelijk de commerciële voorkeursoplossingen zijn, zijn er gevallen waarin met opzet gemaakte tools kunnen worden gebruikt als bouwstenen om vergelijkbare resultaten te bereiken.