In onze vorige Hybrid Cloud-blogs vermelden we vaak dat een van de belangrijkste opties om gebruik te maken van de Hybrid Cloud-topologie-configuratie is om dit als doel voor herstel na noodgevallen te gebruiken. Het is gebruikelijk voor een organisatiestructuur dat een Disaster Recovery Plan (DRP) altijd wordt aangepakt vóór de architecturale implementatie van uw databaseconfiguratie, hetzij in de cloud of op locatie. U zou kunnen denken dat alles onvoorspelbaar zal mislukken en uw bedrijf tragische gevolgen kan hebben als het niet correct wordt aangepakt en begrepen. Het overwinnen van deze uitdagingen vereist een effectief DRP (Disaster Recovery Plan), waarvoor uw systeem goed is geconfigureerd volgens uw applicatie, infrastructuur en zakelijke vereisten. De sleutel tot succes in dit soort situaties is hoe snel we het probleem kunnen oplossen of herstellen.
Terwijl DRP de rampsituaties aanpakt, zorgt Business Continuity ervoor dat DRP te allen tijde wordt getest en operationeel is wanneer dat nodig is. Uw Disaster Recovery-opties voor uw databases moeten continue operaties en grenzen aan de verwachtingen garanderen. Het moet in lijn zijn met uw gewenste RTO en RPO. Het is absoluut noodzakelijk om ervoor te zorgen dat productiedatabases beschikbaar zijn voor de applicaties, zelfs tijdens calamiteiten; anders kan het een dure deal worden. DBA's, de architecten, moeten ervoor zorgen dat databaseomgevingen rampen kunnen doorstaan en voldoen aan de SLA-normen voor herstel na noodgevallen. Database-implementaties moeten correct worden geconfigureerd om ervoor te zorgen dat rampen de beschikbaarheid van de database en de bedrijfscontinuïteit niet beïnvloeden.
Opties voor noodherstel
Uw PostgreSQL-cluster moet worden geconfigureerd met een systematische aanpak die voldoet aan de beste werkwijzen en acceptabel is voor de industriestandaarden. Naast de systematische benaderingen, helpen de volgende processen of mechanismen u ervoor te zorgen dat uw PostgreSQL die is geïmplementeerd in een hybride cloud, deze aanwezigheid heeft:
-
Failover/Switchover
-
Geautomatiseerde back-up
-
Zeer beschikbaar
-
Load Balancing
-
Zeer gedistribueerde omgeving
Failover/Switchover
Failover is een geautomatiseerd proces voor het geval je master faalt; ofwel hot standby of warme standby-server wordt gepromoveerd tot de rol van primair/master. Het is een best practice die een omgeving met hoge beschikbaarheid biedt om ten minste een secundair knooppunt te hebben dat kan fungeren als kandidaat voor een failover-knooppunt. Zodra de primaire server uitvalt, moet de standby-server beginnen met de failover-procedures, waarna de secundaire of standby-server de rol van master op zich neemt. Een failover-systeem gebruikt in de praktijk minimaal twee servers, die als primaire en standby dienen. De verbindingscontrole wordt ondersteund door een hartslagmechanisme dat non-stop controles uitvoert en verifieert of beide in goede staat verkeren en of de communicatie actief is. In sommige gevallen kan de connectiviteit echter een vals alarm geven. Daarom ligt in sommige opstellingen en omgevingen de aanwezigheid van een derde systeem, zoals een monitoringknooppunt, op een apart netwerk of datacenter. Dit is een onfeilbare optie om ongepaste of ongewenste failover te voorkomen. Een onfeilbaar verificatieknooppunt kan extra functies en controles hebben, wat de complexiteit verhoogt. Deze setup vereist volledige en rigoureuze tests om ervoor te zorgen dat de failover correct wordt uitgevoerd wanneer er een wijziging in de implementatie is. Dit is ook belangrijk om verslechtering van uw PostgreSQL te voorkomen
Stel dat u uw secundaire of stand-bycluster op een ander datacenter met een andere hardwareconfiguratie hebt staan; u wilt misschien niet abrupt een failover uitvoeren, vooral als het geen ideaal geval is vanwege slechts een vals positief. In dit scenario moet uw doelknooppunt of cluster voor gegevensherstel echter dezelfde bronnen en specificaties hebben als uw primaire knooppunt of cluster. Als uw doel voor gegevensherstel zich in een openbare cloud bevindt en het primaire doel op locatie is, zorg er dan voor dat dit al is behandeld in uw capaciteitsplanning en dat resources bijna dezelfde specificaties hebben om ongewenste resultaten te voorkomen.
Als u uw failover-mechanisme in uw PostgreSQL-cluster in een hybride cloud gebruikt en voorbereidt, moet u ervoor zorgen dat uw tool perfect geschikt is om de taak uit te voeren die moet worden bereikt. Er zijn tools van derden die niet zijn gebundeld in PostgreSQL met betrekking tot geavanceerde failover. Er is bijvoorbeeld ClusterControl, pg_auto_failover door CitusData (c/o Microsoft), Pgpool-II, Bucardo en anderen. Deze geavanceerde hulpprogramma's bieden node fencing of bekend als STONITH (schiet de andere node in het hoofd). Dit zorgt ervoor dat uw mislukte primaire of hoofdknooppunt geen schrijfbewerkingen accepteert of terug online komt als de vorige status om normale transacties uit te voeren. Dit probleem staat algemeen bekend als een split-brain-scenario. Het verliest gegevenssynchronisatie als gevolg van een storing (hardware- of bronniveau), maar toch gedragen uw primaire servers, die zogenaamd slechts één primaire server zijn, zich alsof ze normale ontvangers van gegevensschrijfverzoeken doen, wat clusterbrede gegevenscorruptie veroorzaakt.
Geautomatiseerde back-up
Back-ups bieden altijd een hoge mate van zekerheid en waarborgen tegen gegevensverlies. Back-up maximaliseert uw RPO omdat het helpt om gegevensverlies te minimaliseren wanneer zich een ramp voordoet. Dingen die u moet overwegen en voorbereiden voor uw geautomatiseerde back-up, zijn uw back-upapparaat/hardware, back-upgegevensredundantie, beveiliging, prestaties, snelheid en gegevensopslag.
Back-upapparaat
U moet hier de beste keuze voor uw back-upapparaat hebben. Snelheid, aanzienlijk opslagvolume en hoge beschikbaarheid kunnen uw gewenste keuze zijn. Sommigen vertrouwen op SAN- of NAS-opslag of verspreiden hun gegevens naar andere externe leveranciers van back-upopslag. Het is essentieel dat uw back-upapparaat snelheid biedt voor het schrijven en lezen van gegevens, vooral als u compressie en versleuteling toepast op uw gegevens in rust. Decompressie en decodering vereisen bronnen, dus u moet overwegen wanneer u gegevensherstel moet gebruiken. Tijdens deze status moet u bepalen dat u uw maximale RPO moet behalen en de haalbare SLA (Service Level Agreement) aan uw klanten binden. Het is ook ideaal dat u uw back-up mogelijk moet isoleren van uw lokale netwerk of op een externe locatie moet opslaan. Een alternatieve benadering is om met externe providers in zee te gaan. Het opslaan van uw back-up in de cloud kan bijvoorbeeld een optie zijn, en hun faciliteit is zeer geavanceerd en voldoet aan uw eisen.
Back-upgegevensredundantie
Het verspreiden van uw gegevens op meerdere locaties is een ideale oplossing. Dit vergroot uw kansen op gegevensherstel, bijvoorbeeld een menselijke fout of een logische softwarefout waardoor u oude back-upkopieën verwijdert, maar per ongeluk de hele cruciale back-upkopieën verwijdert. In sommige geavanceerde omgevingen, zoals opslag in een cloudomgeving zoals Amazon S3, biedt Cloud Storage van Google of Azure Blob Storage replicatie van uw opgeslagen bestand. Dit zorgt voor meer redundantie en kan op een flexibele manier worden ingesteld die past bij uw vereisten.
Zeer beschikbaar
Een PostgreSQL-cluster met hoge beschikbaarheid in een Hybrid Cloud zorgt er altijd voor dat uw databasecommunicatie uptime garandeert. Het ideale geval van hoge beschikbaarheid hangt af van de meting van uw beschikbaarheid. In dit geval kan een algemene opstelling voor een PostgreSQL die in een hybride cloud wordt geïmplementeerd zijn, ofwel uw database die wordt gehost in een openbare cloud, ofwel uw secundaire cluster zijn die fungeert als uw gegevensherstelcluster in het geval dat het primaire cluster uitvalt of een netwerkramp ondervindt en veel stilstand. Bij sommige instellingen is het mogelijk dat het secundaire cluster in de openbare cloud niet precies zo geavanceerd is als de primaire, laten we zeggen dat dit uw on-premise of privécloud is. Uw toepassing kan spelen om de bezoekers of het verkeer dat verbinding kan maken met uw database te beperken. Dit type scenario kan uw installatiekosten verlagen, maar dit hangt natuurlijk alleen af van uw vereisten. Als uw toepassingstype enorm is en non-stop normale tot drukke verkeerssituaties moet ontvangen, zorg er dan voor dat uw secundaire clusterbronnen even krachtig moeten zijn als de primaire om een hoge beschikbaarheid te garanderen, d.w.z. 99,9999999%.
Om een PostgreSQL-cluster met hoge beschikbaarheid in een hybride cloudomgeving te realiseren, hebt u een failover-mechanisme nodig. In het geval van een storing en een primaire cluster of primaire server uitvalt, kan een secundaire of standby-server de rol van master op zich nemen, ongeacht de locatie ervan. Het belangrijkste is de functionaliteit en de prestaties, vooral vanuit het oogpunt van de applicatie of de klant, worden helemaal niet of op zijn minst zeer minimaal beïnvloed.
Load Balancing
Loadbalanceringsmechanisme voor uw PostgreSQL-cluster helpt uw hybride cloudconfiguratie, die beter beheersbaar en minder risicovol is, vooral wanneer er veel verkeer is. In veel situaties wordt een server zwaar belast, waardoor de server in paniek raakt. Dit leidt tot een onbruikbare serverstatus vanwege drukke bronnen die worden verbruikt door veel threads die op de achtergrond worden uitgevoerd. Deze situatie kan worden verbeterd door slechte query's en de ontwerparchitectuur van uw database op te lossen. Dit moet omvatten hoe u de lees-tegen-schrijfbelasting verdeelt en een diepgaand begrip van uw toepassingsvereisten, zoals master-masterconfiguratie of slechts één master, maar verticaal schalen om hogere computer- en geheugenbronnen te bieden. Er is ook een grote selectie tools van derden, zoals pgbouncer en Pgpool II, om uw PostgreSQL-implementatie in een hybride cloudomgeving te ondersteunen.
Zeer gedistribueerde omgeving
Wat betreft schaalbaarheid, sterk gedistribueerd op meerdere locaties of verschillende cloudproviders (on-prem of private en public cloud) biedt meer flexibiliteit en verdraagbaarheid in een hybride cloudomgeving en dit is geweldig voor noodherstel. Het is flexibel wanneer het een failover moet uitvoeren op een bepaalde cloudlocatie die gunstig is voor natuurrampen of catastrofes, vooral als uw aangewezen regio waar uw primaire cluster zich bevindt, momenteel is verwoest of getroffen door een natuurlijke oorzaak. Dit is een onvermijdelijke oorzaak die u moet begrijpen en betrouwbaar moet zijn voor de huidige situatie. Uw applicatie en klanten moeten continu non-stop bediend worden. Dit dient om openbaar beschikbaar te zijn in de cloud en tegelijkertijd te dienen in een privé- of on-premise-omgeving. Deze opzet voegt meer complexiteit toe en vereist geavanceerde kennis op het gebied van databases en beveiliging en netwerken. Optimalisatie en afstemming zijn hier cruciaal voor succes, omdat het erg belangrijk is dat, hoewel het een strengere beveiliging biedt om uw gegevens in te kapselen terwijl u op internet reist, de prestaties moeten worden bewezen te stabiliseren en niet worden beïnvloed door de geïmplementeerde configuratie.
Vanwege de complexiteit van de installatie is het hebben van een tool ideaal voor het beheren van de implementatie en het vergemakkelijken van de algehele status van uw databases, waarbij toezicht wordt gehouden op het ene aspect van uw cluster, maar op het hele niveau van on-prem, private cloud, en op het publieke cloud-aspect. Alle instellingen moeten op een beheersbaar en duidelijk niveau worden gehouden, zodat in geval van alarmen en waarschuwingen het probleem eenvoudig kan worden opgelost en tijdig kan worden opgelost.
ClusterControl voor noodherstel in een hybride cloudomgeving
ClusterControl stelt de organisatie of bedrijven in staat om de database flexibel te beheren en de algehele complexiteit van de installatie te verminderen. ClusterControl biedt failover, geautomatiseerde back-up, een zeer beschikbare setup, taakverdeling en ondersteunt een gedistribueerde omgevingsimplementatie, waardoor het gemakkelijker wordt om nodes toe te voegen in een openbare cloud of privé of op locatie.
ClusterControl automatisch herstel
Het automatische herstel van ClusterControl vertegenwoordigt talloze failover-mechanismen en herstelkenmerken, vooral wanneer een knooppunt uitvalt of een cluster in een gedegradeerde staat raakt. Dit kan eenvoudig worden gedaan, zoals weergegeven in de onderstaande schermafbeelding:
Back-up maken en herstellen
ClusterControl heeft ook een back-up- en herstelfunctie waarmee u uw back-up kunt beheren, een back-up kunt maken, een back-up kunt plannen en een back-up kunt herstellen. Het beheren van uw back-up is heel eenvoudig en het maken of plannen van een back-up is eenvoudig, maar biedt ook geavanceerde opties. Het biedt ook cloudback-upopties waarmee u back-upgegevensredundantie kunt hebben, waardoor uw Disaster Recovery-opties worden versterkt. Zie hieronder:
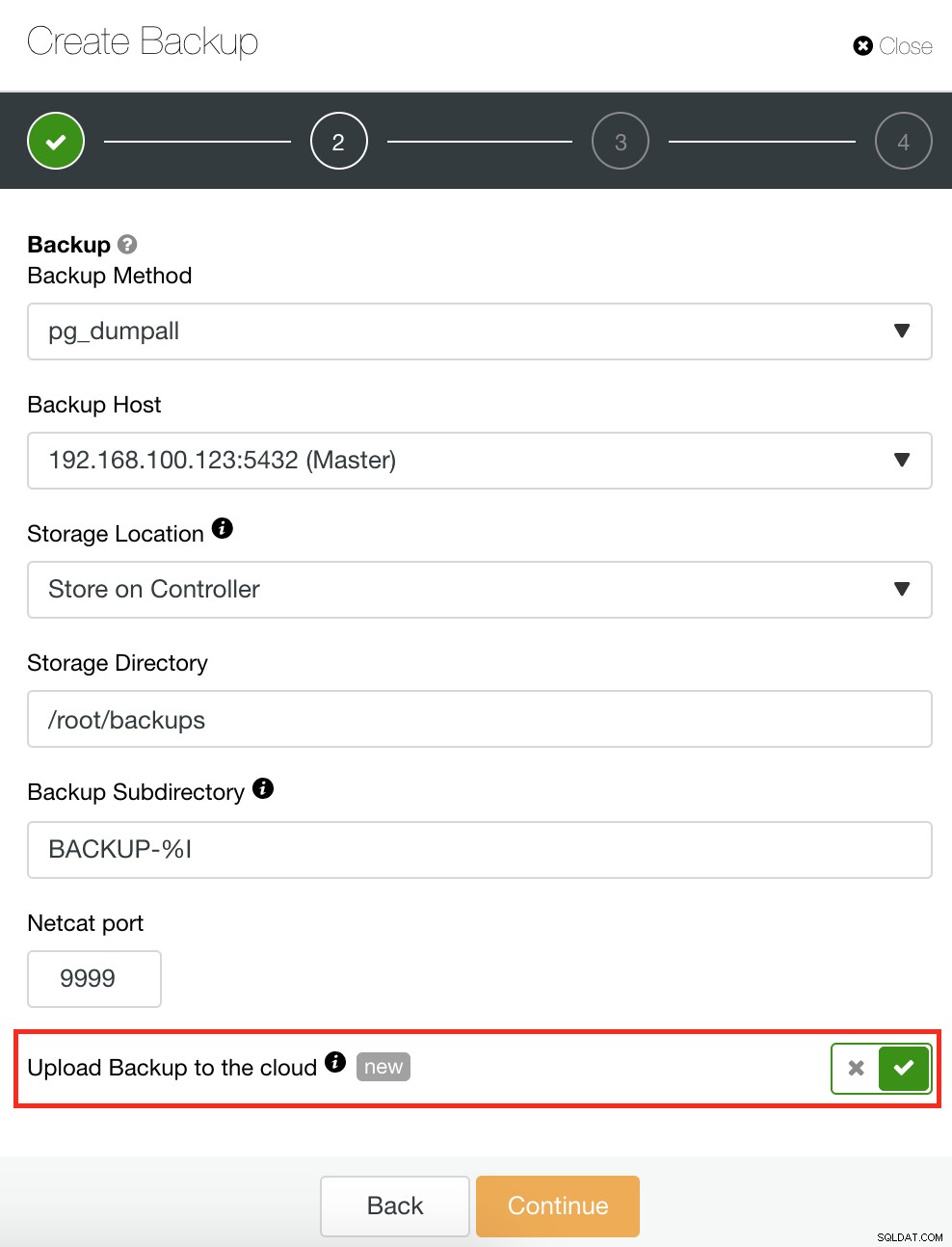
Zoals hieronder wordt getoond, biedt het beheren van uw back-up een eenvoudige gebruikersinterface waarmee u kunt selecteren welke back-up u wilt herstellen, of die u misschien moet laten vallen. Met ClusterControl-back-up kunt u een bewaarperiode kiezen, dus als u een lange lijst heeft, kunnen sommige hiervan worden verwijderd wanneer de bewaartermijn is bereikt. 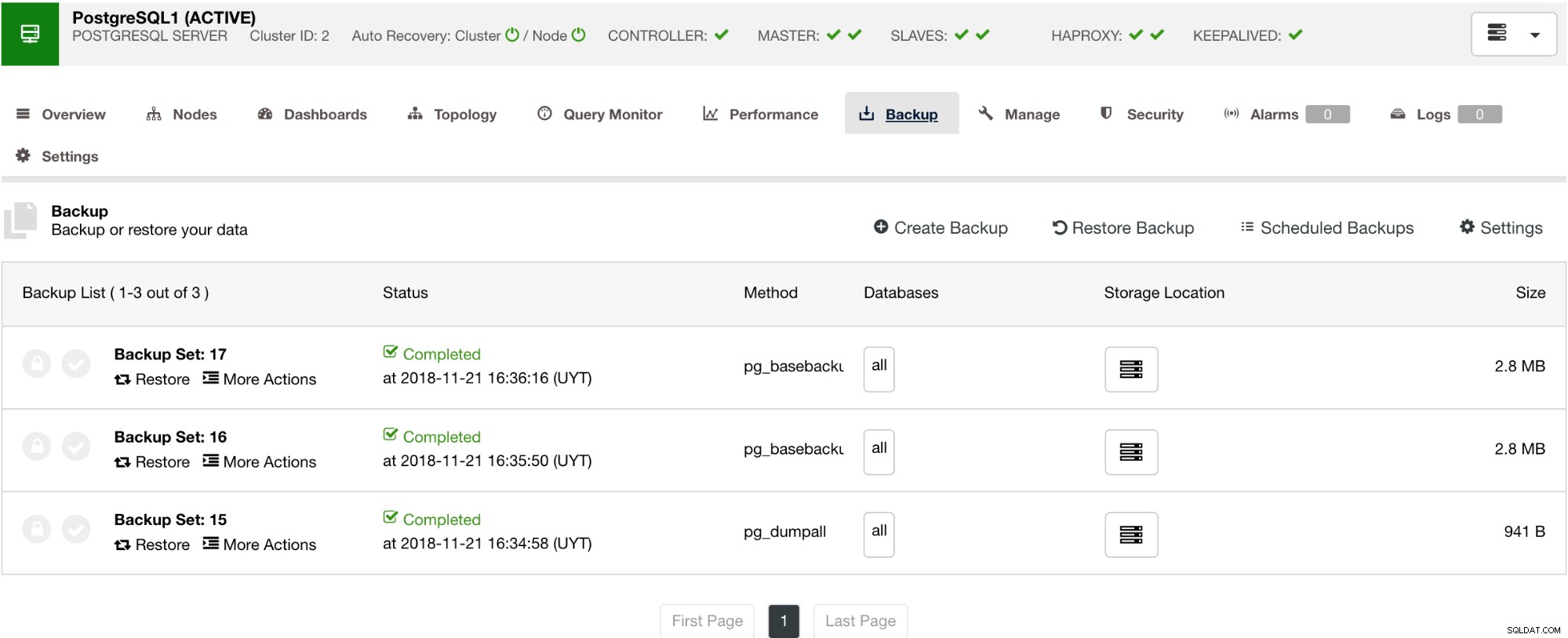
Ondersteunt mechanismen voor hoge beschikbaarheid (HA) en taakverdeling (LB)
U hoeft niet handmatig in te stellen of zelfs maar enkele manieren te onderzoeken om hoge beschikbaarheid toe te voegen aan uw PostgreSQL-cluster. Er is een gemakkelijke en handige manier om de klus te klaren met ClusterControl. Als u de voorbeeldscreenshot kunt zien, heeft deze een HAProxy- en Keepalive-configuratie. Zie screenshot hieronder:
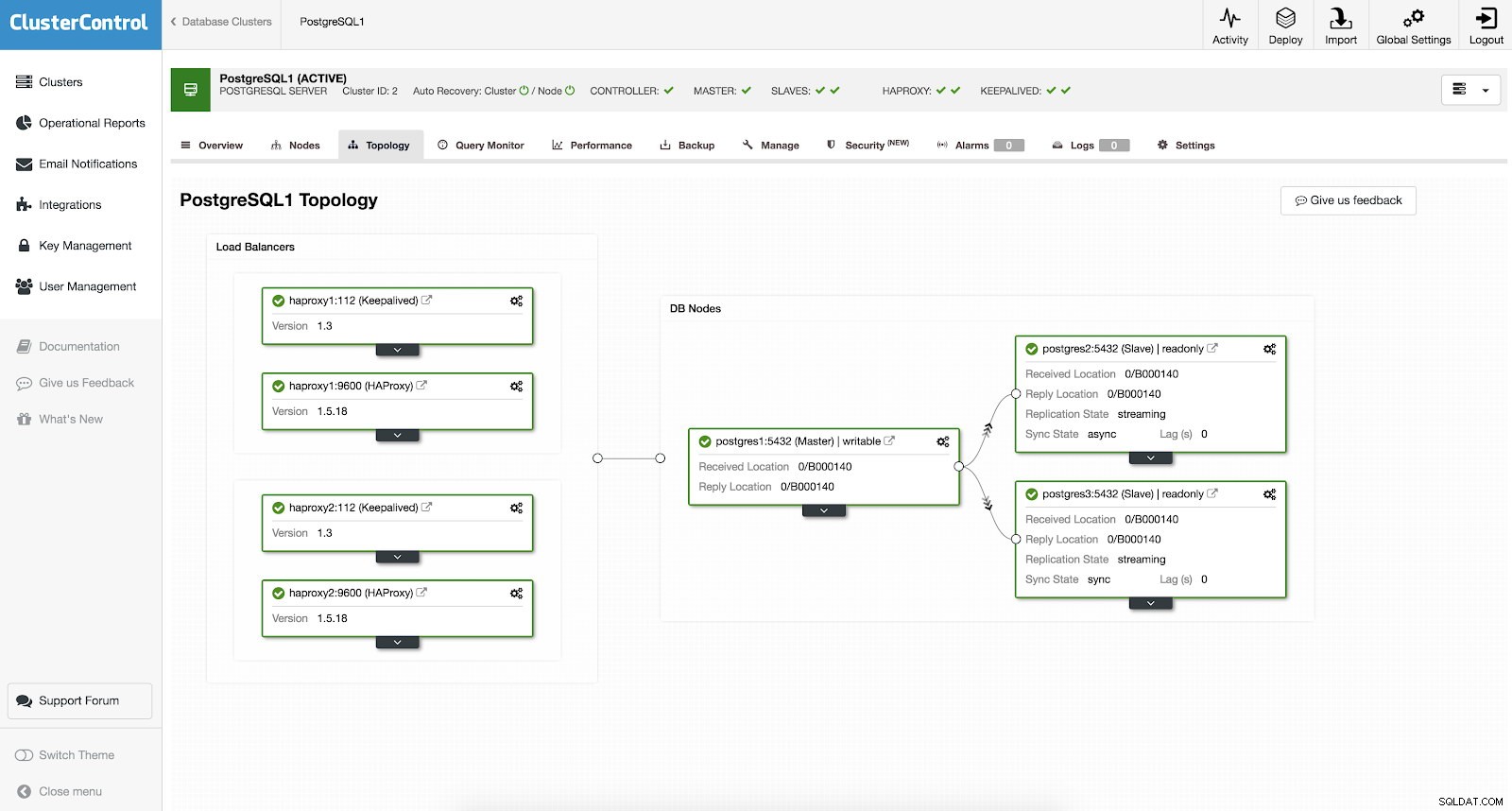
Het instellen van een hoge beschikbaarheid met ClusterControl kan worden gedaan door
Ondersteunt gedistribueerde omgeving
Als u een gelijkmatige distributie wilt hebben van on-prem of private cloud naar public cloud, ondersteunt ClusterControl ook cloudimplementatie. Maar voor een PostgreSQL-cluster en u van plan bent een secundaire slave in een andere cloud te hebben, kunt u een slave-cluster maken zoals hieronder weergegeven,
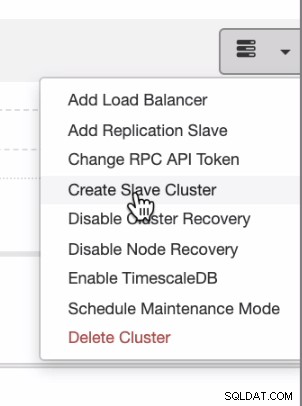
en je kunt aankomen met het eindresultaat zoals hieronder weergegeven,

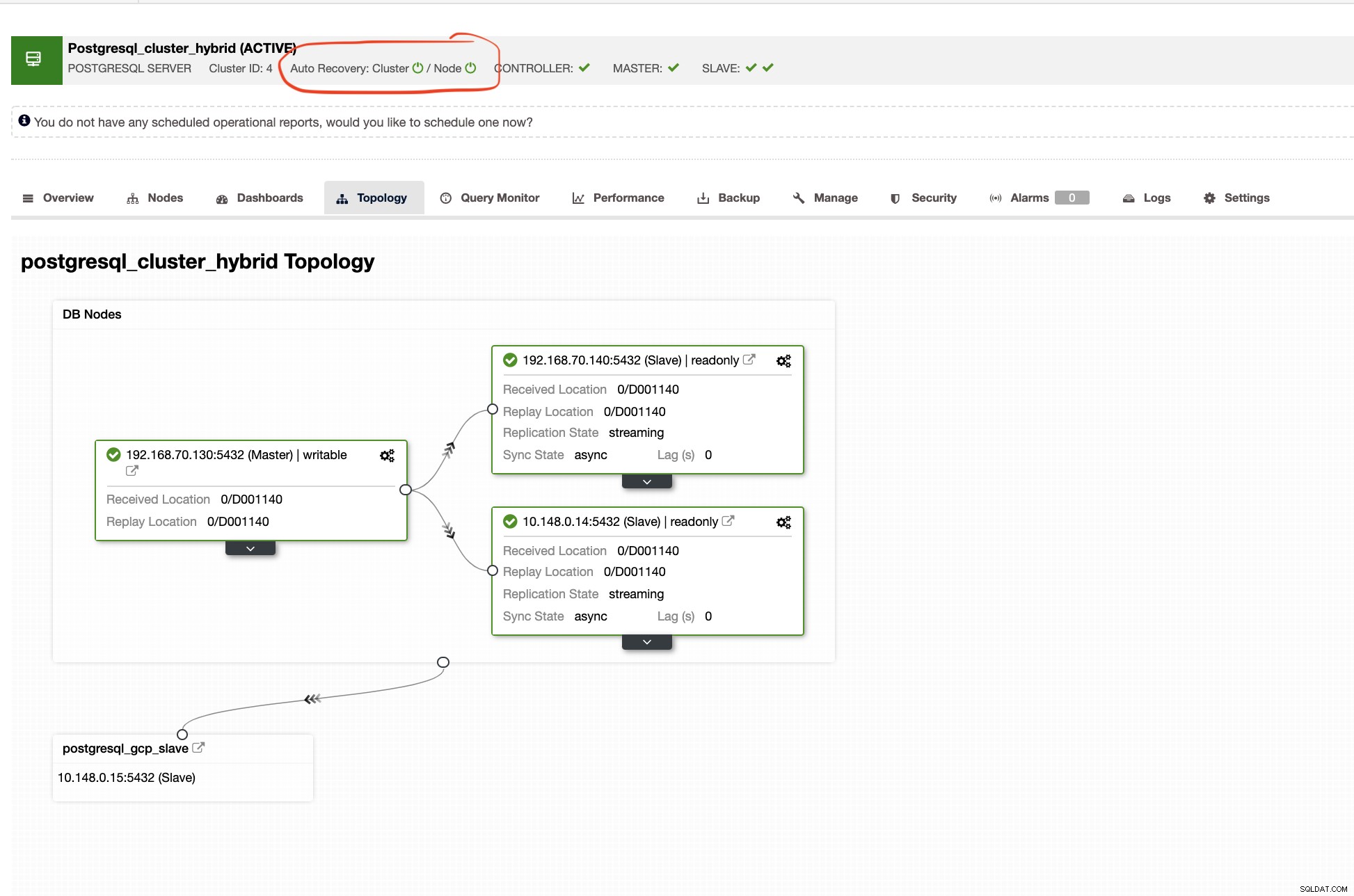
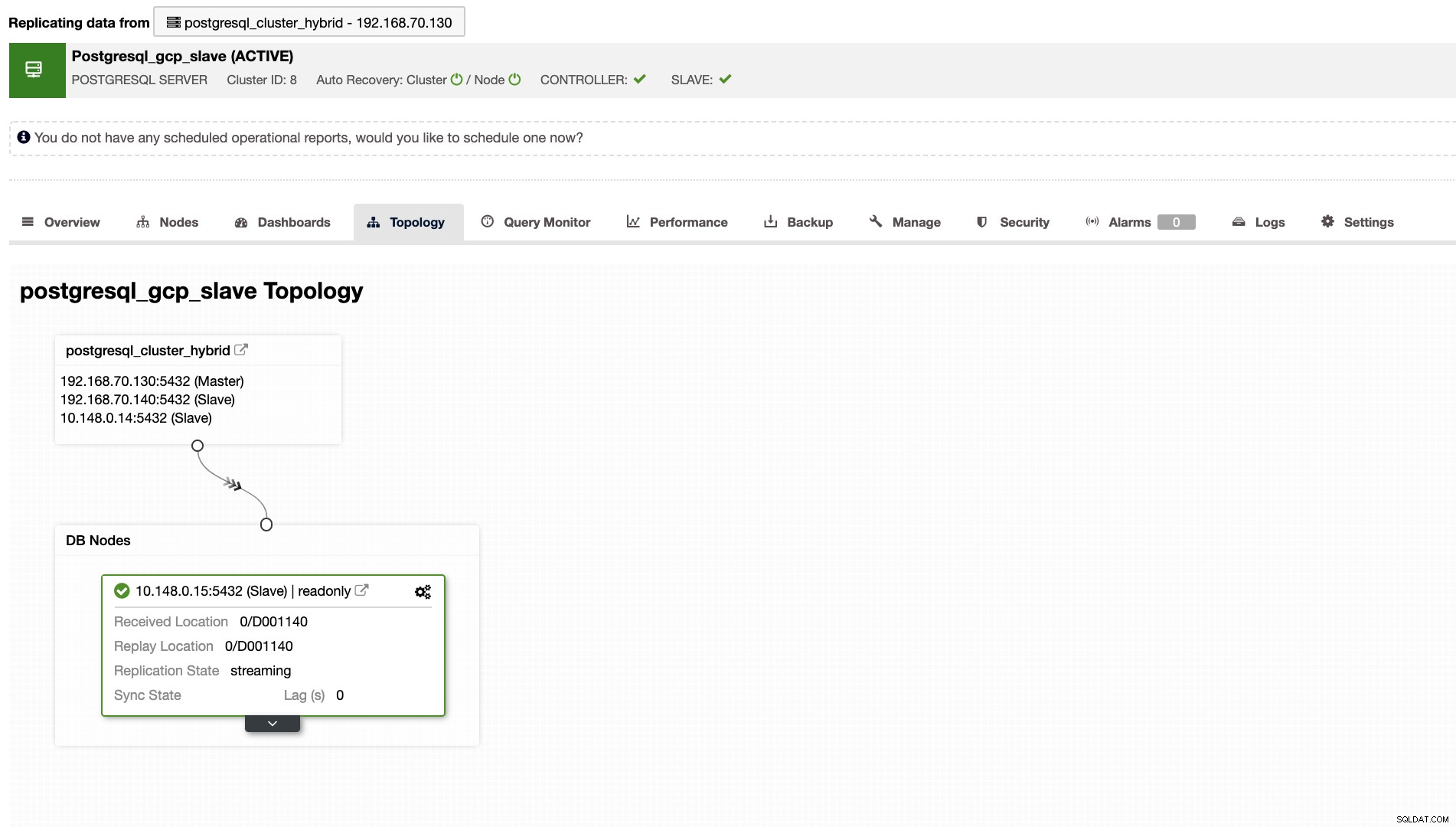
ClusterControl laat je ook de juiste topologie van je cluster zien wanneer je een hybride cloudomgeving hebt ingesteld. Zie het volgende hieronder,
Terwijl in het slave-cluster de topologie de oorsprongsboom toont en de master onthult. De slave wordt hier weergegeven omdat deze zich in een apart netwerk bevindt dat zich voornamelijk in Google Cloud bevindt, terwijl de master op locatie is.
Conclusie
Het is acceptabel om toe te geven dat een hybride cloudconfiguratie, vooral met PostgreSQL-cluster, complexiteit toevoegt. U moet de juiste tool met opties hebben om uw rampherstelplanning te ondersteunen. Deze zijn erg belangrijk om uw bedrijf te redden van de mogelijke catastrofe van financiële schade en het verliezen van het vertrouwen van de klant. Investeer in de juiste tools en vaardigheden van uw technologie en u bespaart uw bedrijf negatieve gevolgen.