De afgelopen maanden hebben we bij 2ndQuadrant gewerkt aan het samenvoegen van PostgreSQL 9.6 in Postgres-XL, wat om verschillende redenen behoorlijk uitdagend bleek te zijn en meer tijd kostte dan aanvankelijk gepland vanwege verschillende invasieve stroomopwaartse wijzigingen. Als je geïnteresseerd bent, kijk dan hier naar de officiële repository (kijk voor nu naar de "master" -branch).
Er is nog heel wat werk aan de winkel – het samenvoegen van een paar resterende bits van upstream, het oplossen van bekende bugs en regressiefouten, testen, enz. Als u overweegt bij te dragen aan Postgres-XL, is dit een ideale kans (stuur me een e-mail en ik help je met de eerste stappen).
Maar over het algemeen is Postgres-XL 9.6 duidelijk een grote stap voorwaarts op een aantal belangrijke gebieden.
Nieuwe functies in Postgres-XL 9.6
Dus, welke nieuwe functies krijgt Postgres-XL door de samenvoeging van PostgreSQL 9.6? Ik zou je gewoon kunnen wijzen op de upstream release-opmerkingen - de meeste verbeteringen zijn rechtstreeks van toepassing op XL 9.6, met uitzondering van die met betrekking tot functies die niet worden ondersteund op XL.
De belangrijkste voor de gebruiker zichtbare verbetering in PostgreSQL 9.6 was duidelijk een parallelle query, en dat geldt ook voor Postgres-XL 9.6.
Intra-node parallellisme
Vóór PostgreSQL 9.6 was Postgres-XL een van de manieren om parallelle zoekopdrachten te krijgen (door meerdere Postgres-XL-knooppunten op dezelfde machine te plaatsen). Sinds PostgreSQL 9.6 is dat niet langer nodig, maar het betekent ook dat Postgres-XL de mogelijkheid tot intra-node parallellisme krijgt.
Ter vergelijking:dit is wat u met Postgres-XL 9.5 kon doen:een zoekopdracht naar meerdere gegevensknooppunten distribueren, maar elk gegevensknooppunt was nog steeds onderworpen aan de limiet van "één backend per zoekopdracht", net als gewone PostgreSQL.
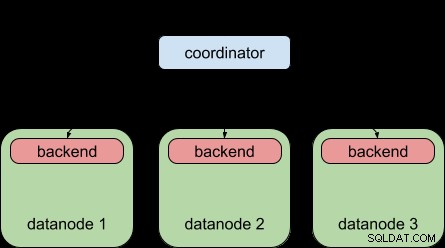
Dankzij de parallelle queryfunctie van PostgreSQL 9.6 kan Postgres-XL 9.6 dit nu doen:
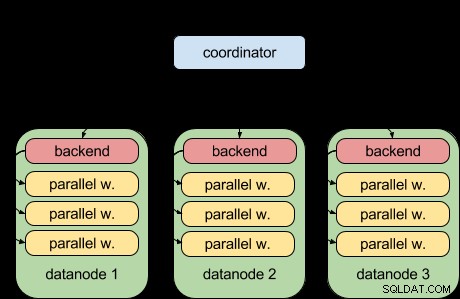
Dat wil zeggen dat elk gegevensknooppunt nu zijn deel van de query parallel kan uitvoeren, met behulp van de upstream parallelle query-infrastructuur. Dat is geweldig en maakt Postgres-XL veel krachtiger als het gaat om analytische workloads.
Een vork onderhouden
Ik zei dat deze samenvoeging om een aantal redenen een grotere uitdaging bleek te zijn dan we aanvankelijk hadden verwacht.
Ten eerste is het onderhouden van vorken in het algemeen moeilijk, vooral wanneer het stroomopwaartse project zo snel gaat als PostgreSQL. U moet specifieke functies voor uw vork ontwikkelen, daarom zijn er in de eerste plaats vorken. Maar je wilt ook stroomopwaarts bijbenen, anders loop je hopeloos achter. Dat is de reden waarom sommige van de bestaande forks nog steeds vastzitten op PostgreSQL 8.x en alle goodies die sindsdien zijn vastgelegd missen.
Ten tweede werd de samenvoeging in één grote brok gedaan, net als alle voorgaande (9.5, 9.2, …). Dat wil zeggen, alle upstream-commits werden samengevoegd in een enkel git merge-commando. Dat zal vrij zeker veel merge-conflicten veroorzaken, in de mate dat de code niet eens compileert, om nog maar te zwijgen van het uitvoeren van regressietests of iets dergelijks.
Dus de eerste batch fixes gaat over het in een compileerbare staat krijgen, de volgende batch gaat over het daadwerkelijk laten werken zonder directe segfaults, en dan begint uiteindelijk de "gewone" fixatie (regressietests uitvoeren, problemen oplossen, spoelen en herhalen) .
Deze complexiteiten zijn inherent aan het onderhoud van de vork (en een reden waarom u waarschijnlijk zou moeten heroverwegen om nog een andere vork te beginnen en in plaats daarvan rechtstreeks zou moeten bijdragen aan Postgres en/of Postgres-XL).
Maar er zijn manieren om de impact aanzienlijk te verminderen - we zijn bijvoorbeeld van plan om de volgende samenvoeging (met PostgreSQL 10) in kleinere delen uit te voeren. Dat zou de omvang van samenvoegconflicten moeten minimaliseren en ons in staat moeten stellen de fouten veel sneller op te lossen.
Dichtbij PostgreSQL
Interessant genoeg stelde het adopteren van parallellisme van de upstream ons ook in staat om veel code uit de XL-codebase te verwijderen - een goed voorbeeld hiervan is de parallelle geaggregeerde code, die gemakkelijk de XL-specifieke code verving.
Een ander voorbeeld van een stroomopwaartse verandering die de XL-code aanzienlijk beïnvloedde, is de "pathificatie" van de hogere planner, die laat in de 9.6-ontwikkelingscyclus werd doorgevoerd. Dit bleek een zeer ingrijpende verandering te zijn (in feite hebben een aantal van de openstaande bugs er waarschijnlijk mee te maken), maar uiteindelijk stelde het ons in staat om de planningscode te vereenvoudigen (in wezen de juiste paden construeren in plaats van het resulterende plan aan te passen).
Als ik zeg dat we door de samenvoeging de XL-code konden vereenvoudigen en dichter bij PostgreSQL konden brengen, wat bedoel ik daar dan mee? De eenvoudigste manier om de verandering te kwantificeren is om "git diff -stat" uit te voeren tegen de overeenkomende stroomopwaartse tak en de getallen te vergelijken. Voor de takken 9.5 en 9.6 zien de resultaten er als volgt uit:
| versie | bestanden gewijzigd | toevoegingen | verwijderingen |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Het is duidelijk dat de 9.6-samenvoeging de delta ten opzichte van stroomopwaarts aanzienlijk vermindert (met in totaal ~ 14%). Waar komt dit verschil vandaan?
Ten eerste is een deel van die vermindering te wijten aan een echte vereenvoudiging van de code. Een goed voorbeeld hiervan is parallel aggregaat, dat vrijwel een 1:1-vervanging is van de originele Postgres-XL-implementatie. Dus we hebben dat er gewoon uitgehaald en in plaats daarvan de upstream-implementatie gebruikt. We hopen in de toekomst meer van dergelijke plaatsen te vinden en stroomopwaartse implementatie te gebruiken in plaats van die van onszelf te onderhouden.
Ten tweede komt veel van de reductie door het verwijderen van dode code. We hebben niet alleen enkele dode/onbereikbare stukjes code verwijderd, we hebben ook heel wat bronbestanden ontdekt die niet eens waren gecompileerd, enzovoort.
Wat nu?
Op dit punt hebben we de wijzigingen samengevoegd tot b5bce6c1, de plaats waar PostgreSQL 9.6 zich van de master splitste. Dus om PostgreSQL 9.6.2 in te halen, moeten we de resterende wijzigingen in de 9.6-tak samenvoegen. Aangezien er meestal alleen bugfixes zouden moeten zijn, zou dat een (hopelijk) redelijk eenvoudig werk moeten zijn in vergelijking met de volledige samenvoeging.
Natuurlijk zullen er bugs zijn. In feite zijn er op dit moment nog steeds een paar falende regressietests. Dat moet worden opgelost voordat een officiële release van XL 9.6 wordt gemaakt. En we moeten meer testen doen, dus als u geïnteresseerd bent om Postgres-XL te helpen, zou dit zeer nuttig zijn.
Een ergernis waar we steeds over horen, zijn pakketten, of het ontbreken ervan. Het is je misschien opgevallen dat de laatste beschikbare pakketten vrij oud zijn en dat er alleen .rpm is, niets anders. We zijn van plan dit aan te pakken en beginnen met het aanbieden van up-to-date pakketten in meerdere smaken (bijv. .rpm en .deb).
We zijn ook van plan om enkele wijzigingen aan te brengen in de manier waarop het ontwikkelingsproces is georganiseerd, om het gemakkelijker te maken om bij te dragen aan en deel te nemen aan het ontwikkelingsproces. Dat is echt een apart onderwerp dat niets met de 9.6-tak te maken heeft, dus ik zal daar over een paar dagen meer details over posten.