Twee ernstige beveiligingsproblemen (codenaam Meltdown en Spectre) werden een paar weken geleden onthuld. De eerste tests suggereerden dat de prestatie-impact van mitigaties (toegevoegd in de kernel) voor sommige workloads tot ~30% zou kunnen zijn, afhankelijk van de syscall-snelheid.
Die vroege schattingen moesten snel worden gedaan en waren dus gebaseerd op beperkte hoeveelheden testen. Verder zijn de in-kernel fixes in de loop van de tijd geëvolueerd en verbeterd, en we hebben nu ook retpoline die Spectre v2. Dit bericht presenteert gegevens van meer grondige tests, hopelijk met betrouwbaardere schattingen voor typische PostgreSQL-workloads.
Vergeleken met de vroege beoordeling van Meltdown-oplossingen die Simon op 10 januari plaatste, zijn de gegevens in dit bericht gedetailleerder, maar komen over het algemeen overeen met de bevindingen in dat bericht.
Dit bericht is gericht op PostgreSQL-workloads, en hoewel het nuttig kan zijn voor andere systemen met hoge syscall/context-wisselsnelheden, is het zeker niet universeel toepasbaar. Als u geïnteresseerd bent in een meer algemene uitleg van de kwetsbaarheden en impactbeoordeling, heeft Brendan Gregg een paar dagen geleden een uitstekend artikel van KPTI/KAISER Meltdown Initial Performance Regressions gepubliceerd. Eigenlijk is het misschien handig om het eerst te lezen en dan verder te gaan met dit bericht.
Opmerking: Dit bericht is niet bedoeld om u te ontmoedigen om de fixes te installeren, maar om u een idee te geven wat de impact op de prestaties kan zijn. Je moet alle fixes installeren zodat je omgeving veilig is, en dit bericht gebruiken om te beslissen of je hardware enz. moet upgraden.
Welke tests gaan we doen?
We zullen kijken naar twee gebruikelijke typen werkbelasting:OLTP (kleine eenvoudige transacties) en OLAP (complexe query's die grote hoeveelheden gegevens verwerken). De meeste PostgreSQL-systemen kunnen worden gemodelleerd als een combinatie van deze twee typen werkbelasting.
Voor OLTP hebben we pgbench gebruikt, een bekende benchmarktool die bij PostgreSQL wordt geleverd. We hebben beide getest in alleen-lezen (-S ) en lezen-schrijven (-N ) modi, met drie verschillende schalen – passend in gedeelde_buffers, in RAM en groter dan RAM.
Voor het OLAP-geval gebruikten we de dbt-3-benchmark, die redelijk dicht bij TPC-H ligt, met twee verschillende gegevensgroottes:10 GB die in RAM past en 50 GB die groter is dan RAM (rekening houdend met indexen enz.).
Alle gepresenteerde cijfers zijn afkomstig van een server met 2x Xeon E5-2620v4, 64GB RAM en Intel SSD 750 (400GB). Het systeem draaide Gentoo met kernel 4.15.3, gecompileerd met GCC 7.3 (nodig om de volledige retpoline in te schakelen repareren). Dezelfde tests werden ook uitgevoerd op een ouder/kleiner systeem met i5-2500k CPU, 8GB RAM en 6x Intel S3700 SSD (in RAID-0). Maar het gedrag en de conclusies zijn vrijwel hetzelfde, dus we gaan de gegevens hier niet presenteren.
Zoals gewoonlijk zijn volledige scripts/resultaten voor beide systemen beschikbaar op github.
Dit bericht gaat over de prestatie-impact van de beperking, dus laten we ons niet concentreren op absolute cijfers en in plaats daarvan kijken naar de prestaties ten opzichte van het niet-gepatchte systeem (zonder de kernelbeperkingen). Alle grafieken in de OLTP-sectie tonen
(throughput with patches) / (throughput without patches)
We verwachten cijfers tussen 0% en 100%, waarbij hogere waarden beter zijn (lagere impact van mitigaties), 100% betekent 'geen impact'.
Opmerking: De y-as begint bij 75%, om de verschillen beter zichtbaar te maken.
OLTP / alleen-lezen
Laten we eerst de resultaten bekijken voor alleen-lezen pgbench, uitgevoerd door dit commando
pgbench -n -c 16 -j 16 -S -T 1800 test
en geïllustreerd door de volgende grafiek:
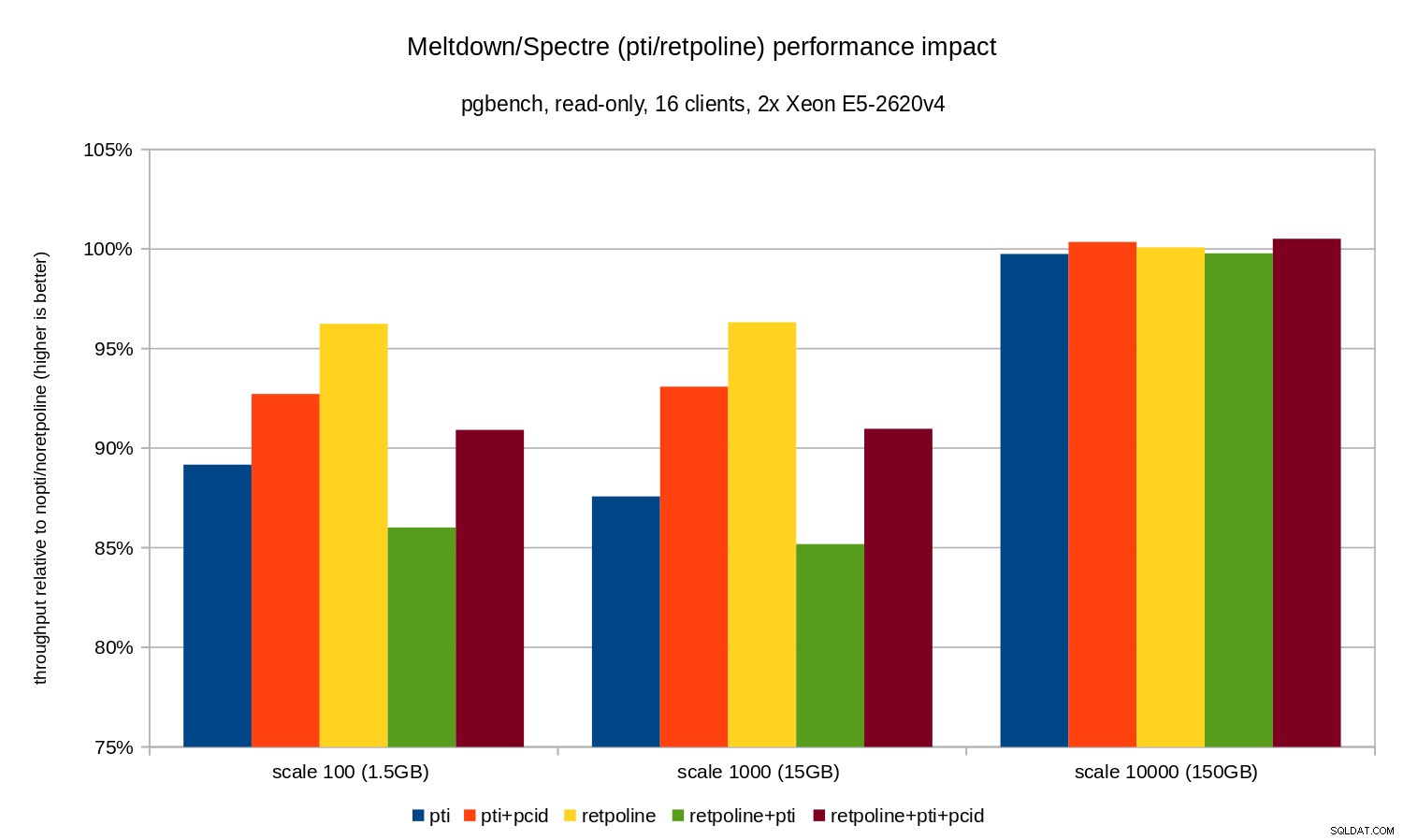
Zoals u kunt zien, is de prestatie-impact van pti voor schalen die in het geheugen passen, is ongeveer 10-12% en bijna niet meetbaar wanneer de werklast I/O-gebonden wordt. Bovendien wordt de regressie aanzienlijk verminderd (of verdwijnt helemaal) wanneer pcid is ingeschakeld. Dit komt overeen met de bewering dat PCID nu een kritieke prestatie-/beveiligingsfunctie is op x86. De impact van retpoline is veel kleiner – minder dan 4% in het ergste geval, wat gemakkelijk te wijten kan zijn aan ruis.
OLTP / lezen-schrijven
De lees-schrijftests zijn uitgevoerd door een pgbench opdracht vergelijkbaar met deze:
pgbench -n -c 16 -j 16 -N -T 3600 test
De duur was lang genoeg om meerdere checkpoints te dekken, en -N werd gebruikt om vergrendelingsconflicten op rijen in de (kleine) vertakkingstabel te elimineren. De relatieve prestatie wordt geïllustreerd door deze grafiek:
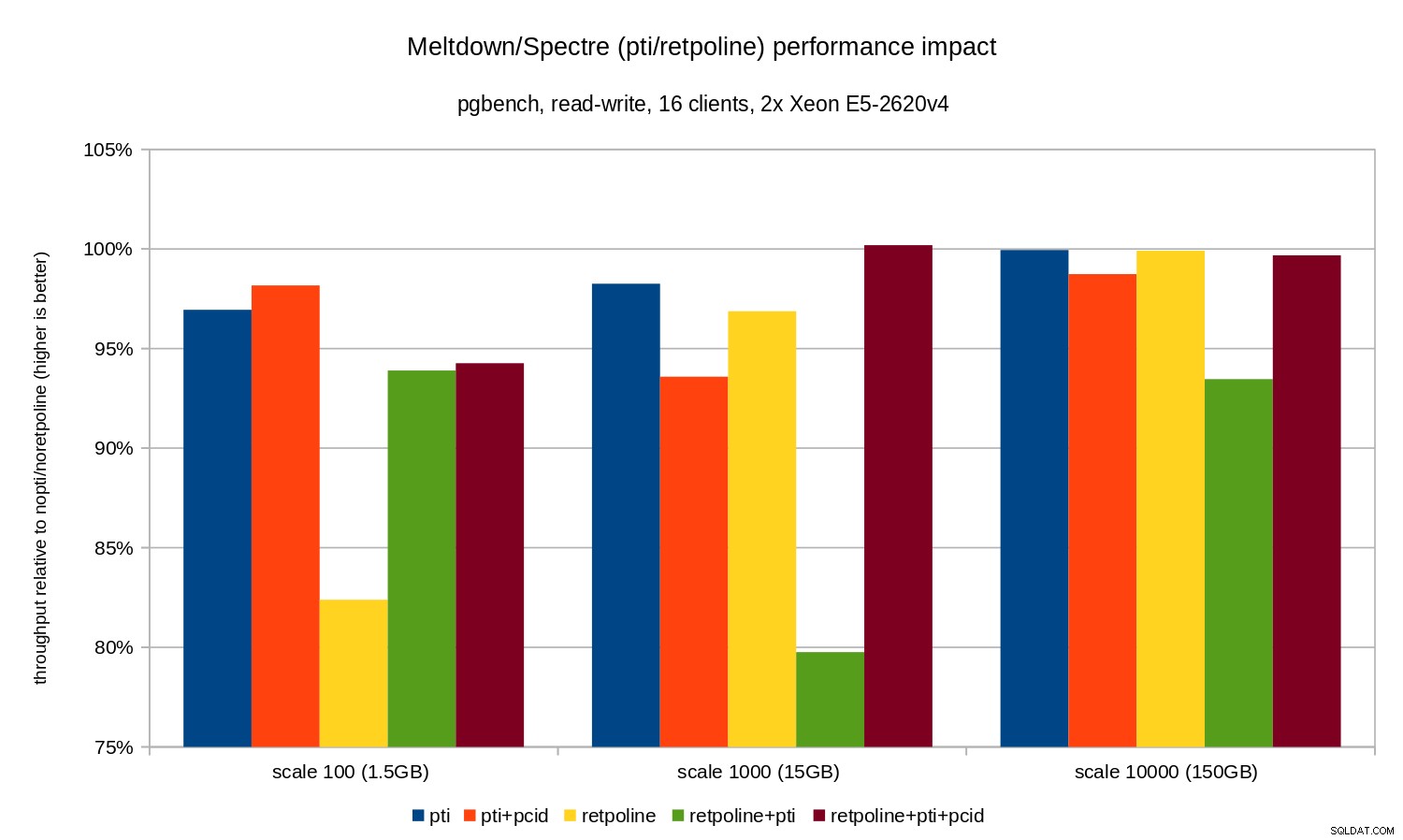
De regressies zijn iets kleiner dan in het alleen-lezen geval – minder dan 8% zonder pcid en minder dan 3% met pcid ingeschakeld. Dit is een natuurlijk gevolg van het meer tijd besteden aan het uitvoeren van I/O tijdens het schrijven van gegevens naar WAL, het leegmaken van gewijzigde buffers tijdens het controlepunt, enz.
Er zijn echter twee vreemde stukjes. Ten eerste, de impact van retpoline is onverwacht groot (bijna 20%) voor schaal 100, en hetzelfde gebeurde voor retpoline+pti op schaal 1000. De redenen zijn niet helemaal duidelijk en vereisen aanvullend onderzoek.
OLAP
De analyse-workload is gemodelleerd door de dbt-3-benchmark. Laten we eerst eens kijken naar de resultaten van 10 GB, die volledig in het RAM passen (inclusief alle indexen enz.). Net als bij OLTP zijn we niet echt geïnteresseerd in absolute aantallen, wat in dit geval de duur van individuele zoekopdrachten zou zijn. In plaats daarvan kijken we naar vertraging vergeleken met de nopti/noretpoline , dat wil zeggen:
(duration without patches) / (duration with patches)
Ervan uitgaande dat de maatregelen leiden tot vertraging, krijgen we waarden tussen 0% en 100%, waarbij 100% "geen impact" betekent. De resultaten zien er als volgt uit:
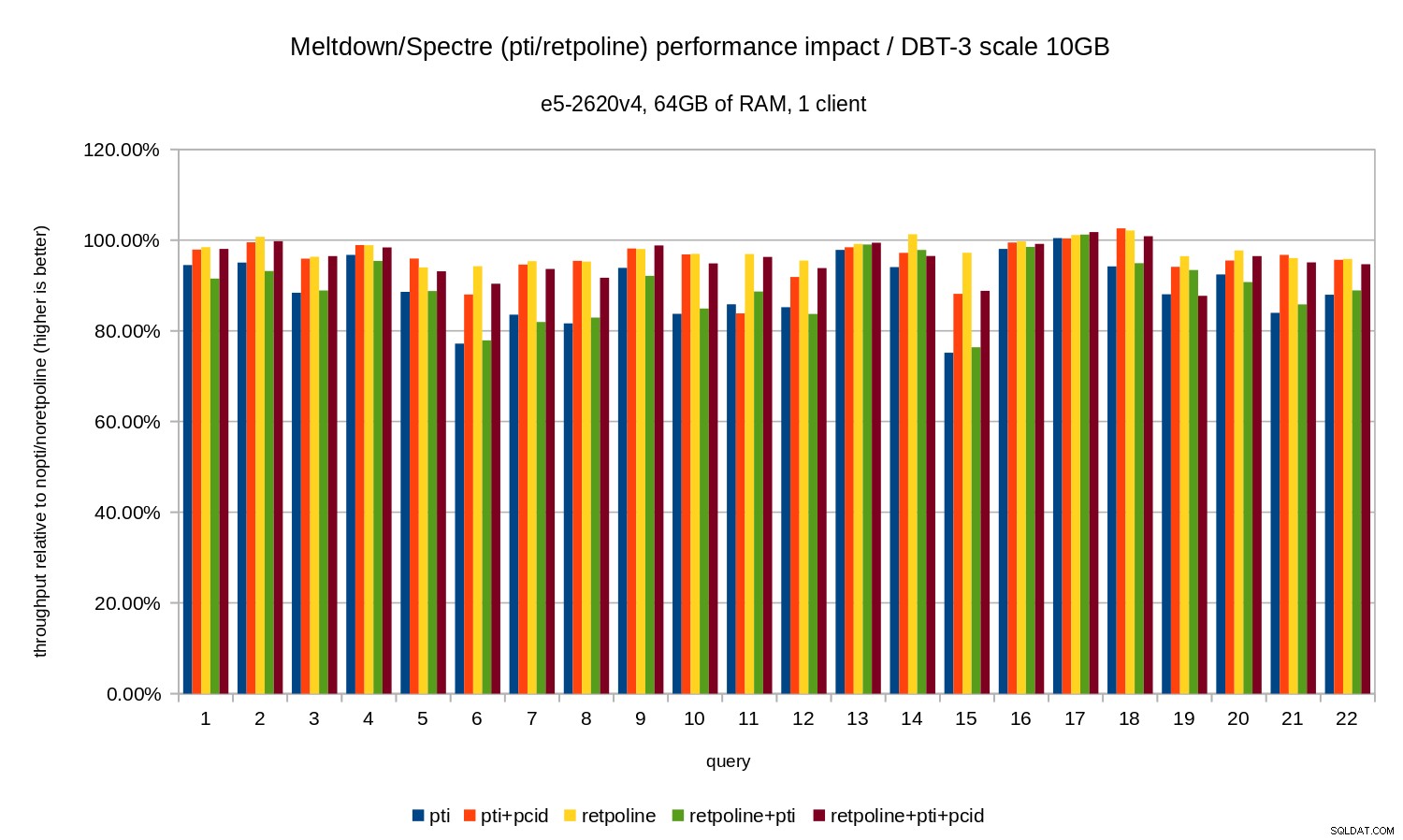
Dat wil zeggen, zonder de pcid de regressie ligt over het algemeen in het bereik van 10-20%, afhankelijk van de zoekopdracht. En met pcid de regressie daalt tot minder dan 5% (en in het algemeen dicht bij 0%). Dit bevestigt nogmaals het belang van pcid functie.
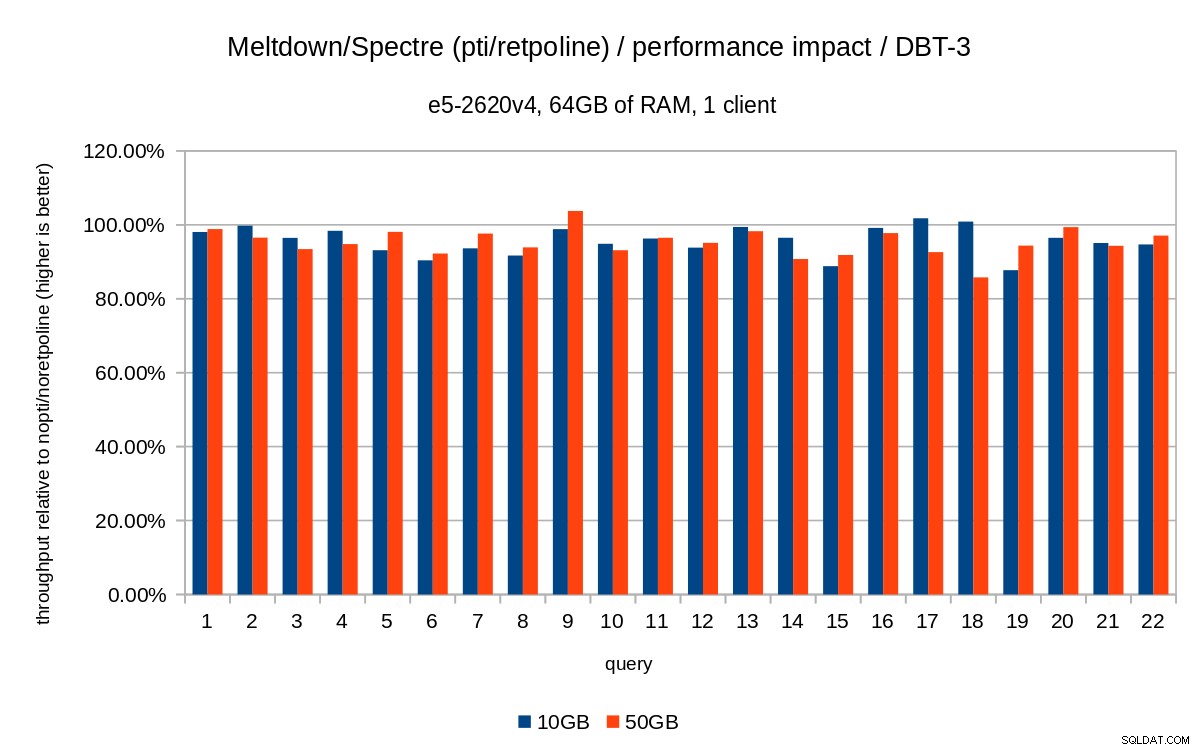
Voor de 50GB dataset (dat is ongeveer 120GB met alle indexen etc.) ziet de impact er als volgt uit:
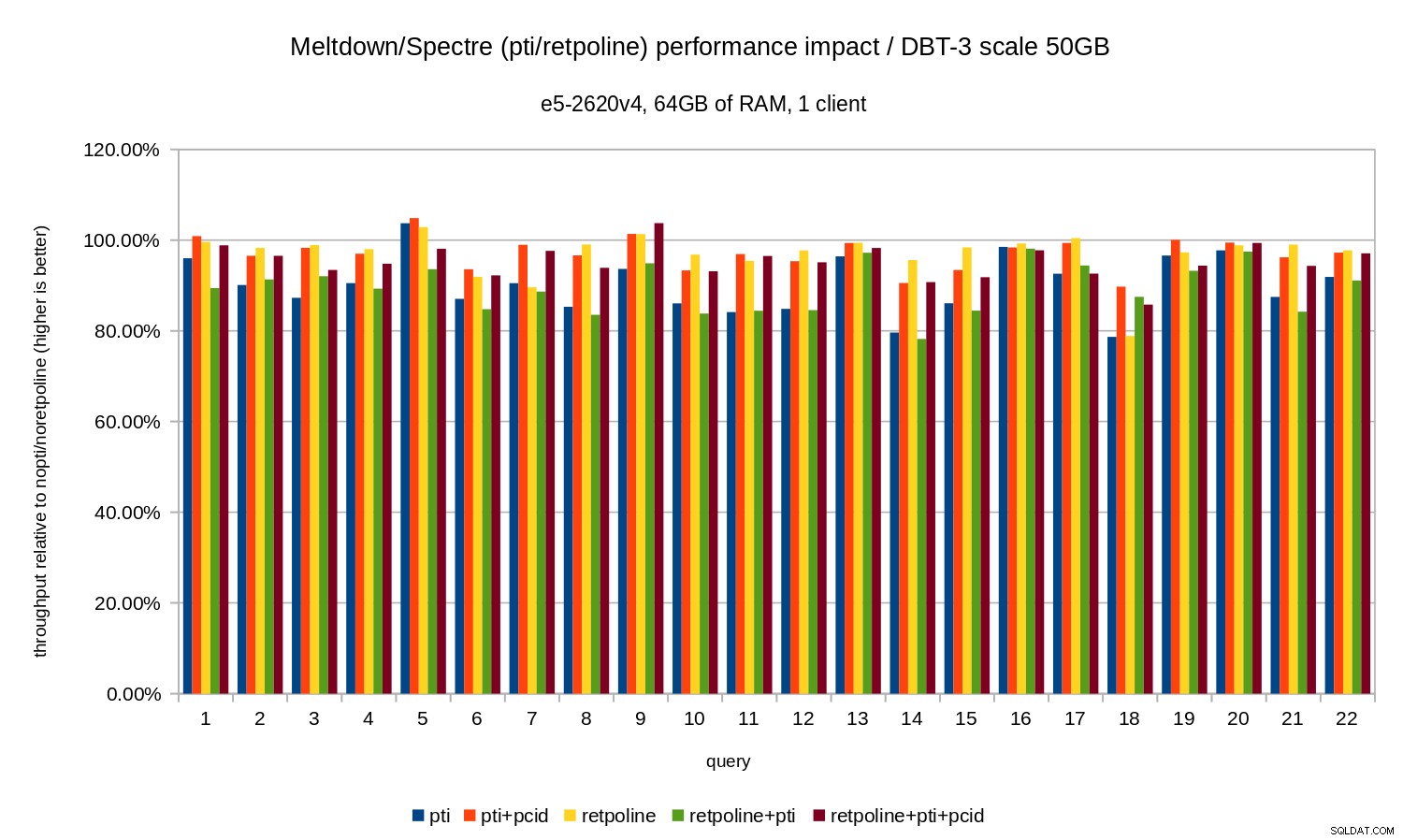
Dus net als in het geval van 10 GB zijn de regressies minder dan 20% en pcid vermindert ze aanzienlijk - bijna 0% in de meeste gevallen.
De vorige grafieken zijn een beetje rommelig - er zijn 22 zoekopdrachten en 5 gegevensreeksen, wat een beetje te veel is voor een enkele grafiek. Dus hier is een grafiek die alleen de impact laat zien voor alle drie de functies (pti , pcid en retpoline ), voor beide datasetgroottes.
Conclusie
Om de resultaten kort samen te vatten:
retpolineheeft zeer weinig invloed op de prestaties- OLTP – de regressie is ongeveer 10-15% zonder de
pcid, en ongeveer 1-5% metpcid. - OLAP – de regressie is tot 20% zonder de
pcid, en ongeveer 1-5% metpcid. - Voor I/O-gebonden workloads (bijv. OLTP met de grootste dataset) heeft Meltdown een verwaarloosbare impact.
De impact lijkt veel lager te zijn dan de eerste schattingen die suggereren (30%), althans voor de geteste werkbelasting. Veel systemen werken op 70-80% CPU tijdens piekperiodes, en de 30% zou de CPU-capaciteit volledig verzadigen. Maar in de praktijk lijkt de impact minder dan 5% te zijn, tenminste wanneer de pcid optie wordt gebruikt.
Begrijp me niet verkeerd, 5% daling is nog steeds een serieuze regressie. Het is zeker iets waar we om zouden geven tijdens PostgreSQL-ontwikkeling, b.v. bij het evalueren van de impact van voorgestelde patches. Maar het is iets wat bestaande systemen prima zouden moeten kunnen verwerken - als 5% toename van het CPU-gebruik je systeem over de streep haalt, heb je problemen, zelfs zonder Meltdown/Spectre.
Het is duidelijk dat dit niet het einde is van Meltdown/Spectre-fixes. Kernelontwikkelaars werken nog steeds aan het verbeteren van de beveiligingen en het toevoegen van nieuwe, en Intel en andere CPU-fabrikanten werken aan microcode-updates. En het is niet zo dat we alle mogelijke varianten van de kwetsbaarheden kennen, omdat onderzoekers nieuwe varianten van de aanvallen hebben weten te vinden.
Er komt dus nog meer en het zal interessant zijn om te zien wat de impact op de prestaties zal zijn.