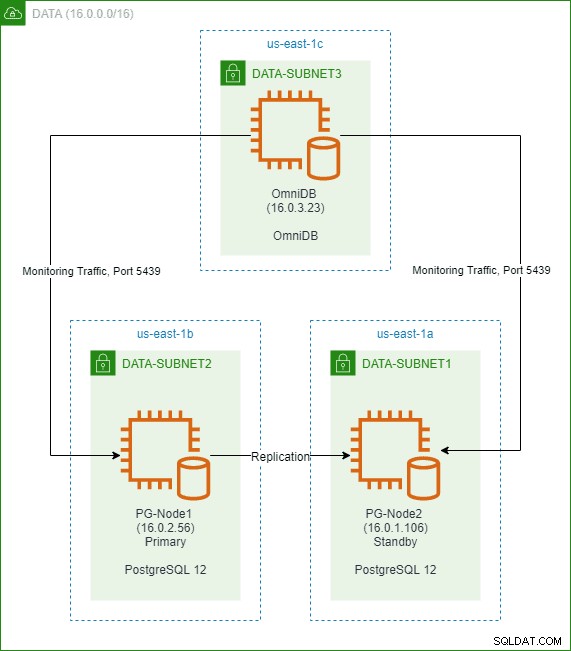
In een vorig artikel van deze serie hebben we een PostgreSQL 12-cluster met twee knooppunten in de AWS-cloud gemaakt. We hebben ook 2ndQuadrant OmniDB geïnstalleerd en geconfigureerd in een derde knooppunt. De afbeelding hieronder toont de architectuur:
We kunnen verbinding maken met zowel het primaire als het standby-knooppunt vanuit de webgebaseerde gebruikersinterface van OmniDB. Vervolgens hebben we een voorbeelddatabase met de naam "dvdrental" in het primaire knooppunt hersteld, die begon te repliceren naar de stand-by.
In dit deel van de serie leren we hoe we een monitoringdashboard in OmniDB kunnen maken en gebruiken. DBA's en operationele teams geven vaak de voorkeur aan grafische tools in plaats van complexe query's om de databasestatus visueel te inspecteren. OmniDB wordt geleverd met een aantal belangrijke widgets die eenvoudig in een monitoringdashboard kunnen worden gebruikt. Zoals we later zullen zien, kunnen gebruikers hiermee ook hun eigen monitoringwidgets schrijven.
Een dashboard voor prestatiebewaking bouwen
Laten we beginnen met het standaard dashboard waarmee OmniDB wordt geleverd.
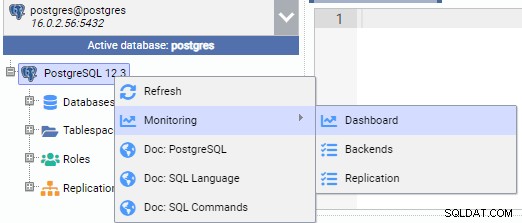
In de onderstaande afbeelding zijn we verbonden met het primaire knooppunt (PG-Node1). We klikken met de rechtermuisknop op de instantienaam en kiezen vervolgens in het pop-upmenu "Monitor" en vervolgens "Dashboard".
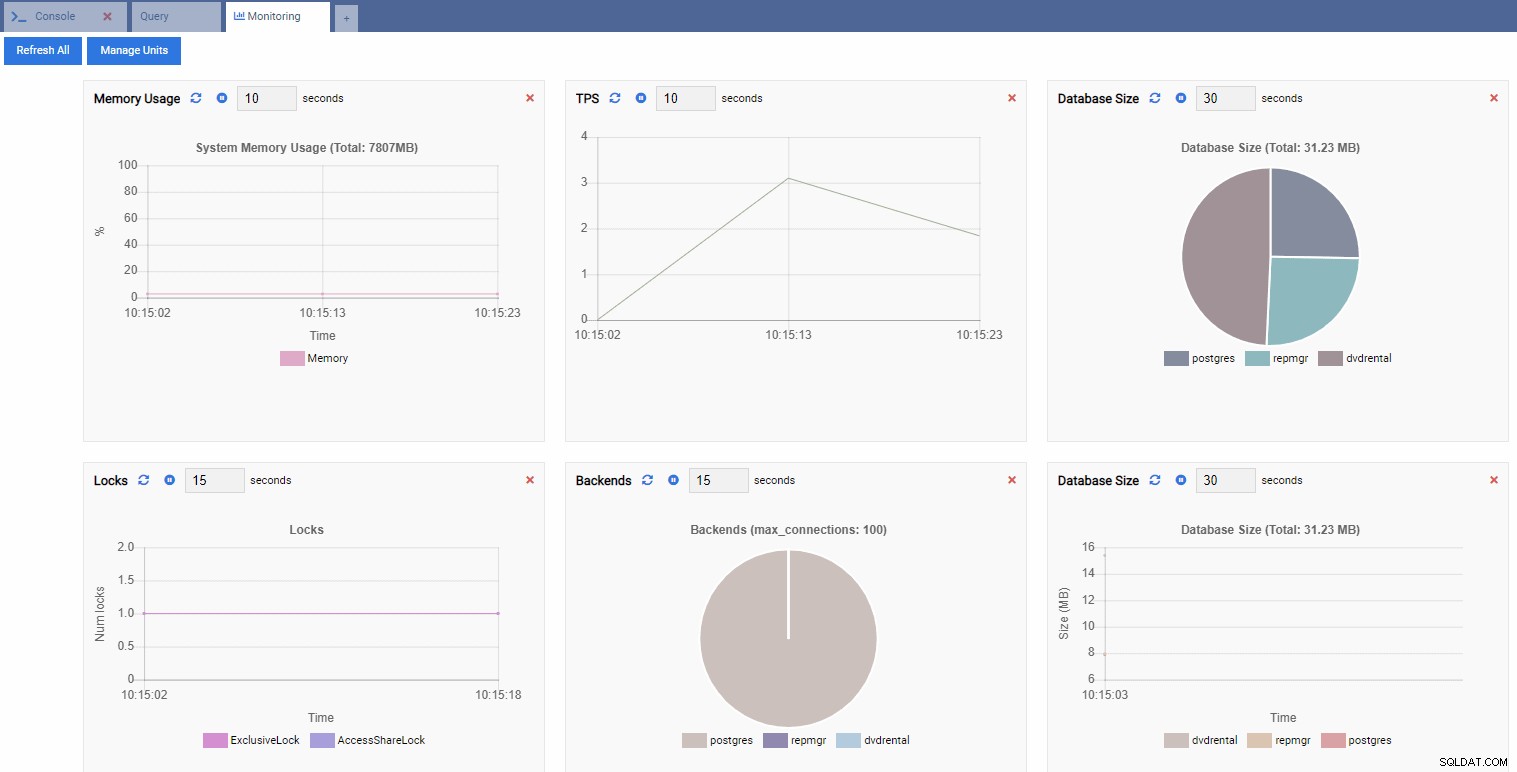
Dit opent een dashboard met enkele widgets erin.
In OmniDB-termen worden de rechthoekige widgets in het dashboard Bewakingseenheden genoemd . Elk van deze eenheden toont een specifieke statistiek van de PostgreSQL-instantie waarmee het is verbonden en vernieuwt dynamisch de gegevens.
Monitoring-eenheden begrijpen
OmniDB wordt geleverd met vier soorten Monitoring Units:
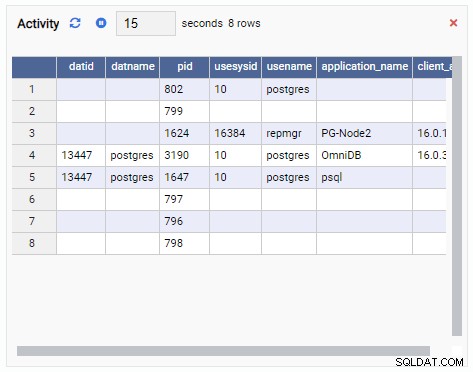
- Een Raster is een tabelstructuur die het resultaat van een query laat zien. Dit kan bijvoorbeeld de uitvoer zijn van SELECT * FROM pg_stat_replication. Een raster ziet er als volgt uit:
- Een Grafiek toont de gegevens in grafisch formaat, zoals lijnen of cirkeldiagrammen. Wanneer het wordt vernieuwd, wordt de hele grafiek opnieuw op het scherm getekend met een nieuwe waarde en is de oude waarde verdwenen. Met deze Monitoring Units kunnen we alleen de huidige waarde van de metriek zien. Hier is een voorbeeld van een grafiek:
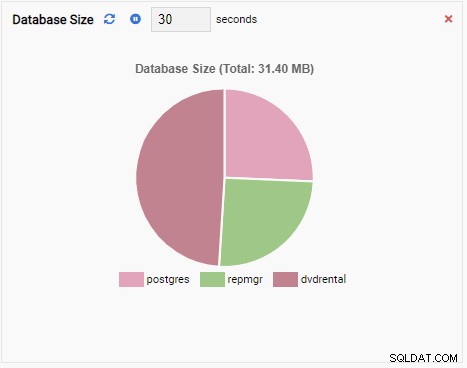
- Een Chart-Append is ook een bewakingseenheid van het type Grafiek, behalve wanneer deze wordt vernieuwd, de nieuwe waarde wordt toegevoegd aan de bestaande reeks. Met Chart-Append kunnen we gemakkelijk trends in de tijd zien. Hier is een voorbeeld:
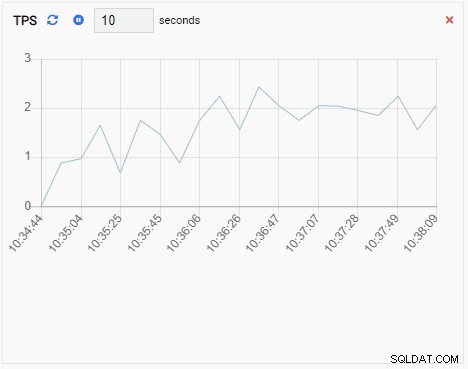
- Een Grafiek toont relaties tussen PostgreSQL-clusterinstanties en een bijbehorende metriek. Net als de Chart Monitoring Unit ververst een Graph Monitoring Unit ook zijn oude waarde met een nieuwe. De onderstaande afbeelding toont het huidige knooppunt (PG-Node1) dat repliceert naar de PG-Node2:
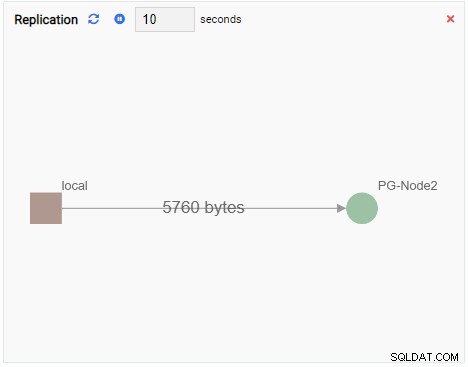
Elke Monitoring Unit heeft een aantal gemeenschappelijke elementen:
- De naam van de bewakingseenheid
- Een "refresh"-knop om het apparaat handmatig te vernieuwen
- Een "pauze"-knop om tijdelijk te stoppen met het vernieuwen van de Monitoring Unit
- Een tekstvak met het huidige verversingsinterval. Dit kan worden gewijzigd
- Een "close"-knop (rood kruisteken) om de Monitoring Unit van het dashboard te verwijderen
- Het eigenlijke tekengebied van de Monitoring
Vooraf gebouwde bewakingseenheden
OmniDB wordt geleverd met een aantal Monitoring Units voor PostgreSQL die we aan ons dashboard kunnen toevoegen. Om toegang te krijgen tot deze eenheden, klikken we op de knop "Eenheden beheren" bovenaan het dashboard:
Dit opent de lijst "Eenheden beheren":
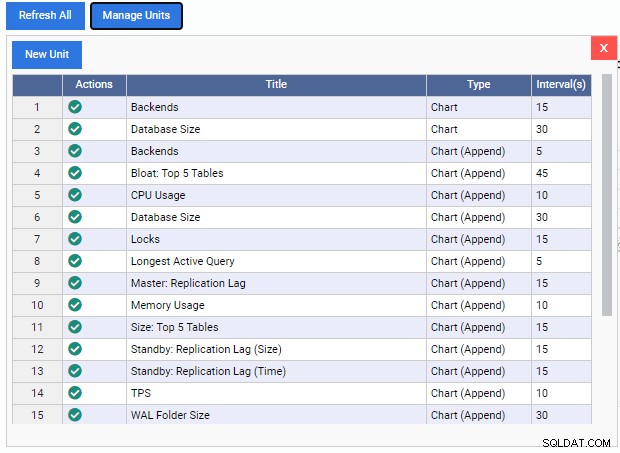
Zoals we kunnen zien, zijn er hier maar weinig vooraf gebouwde Monitoring Units. De codes voor deze Monitoring Units kunnen gratis worden gedownload van de GitHub-repo van 2ndQuadrant. Elke eenheid die hier wordt vermeld, toont zijn naam, type (grafiek, grafiek toevoegen, grafiek of raster) en de standaardverversingsfrequentie.
Om een Monitoring Unit aan het dashboard toe te voegen, hoeven we alleen maar op het groene vinkje onder de kolom "Acties" voor die unit te klikken. We kunnen verschillende Monitoring Units mixen en matchen om het dashboard te bouwen dat we willen.
In de onderstaande afbeelding hebben we de volgende eenheden toegevoegd voor ons dashboard voor prestatiebewaking en al het andere verwijderd:
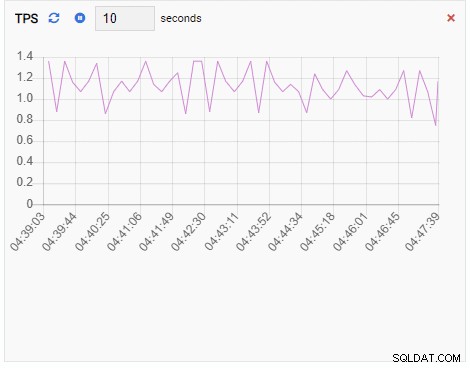
TPS (transactie per seconde):
Aantal sloten:
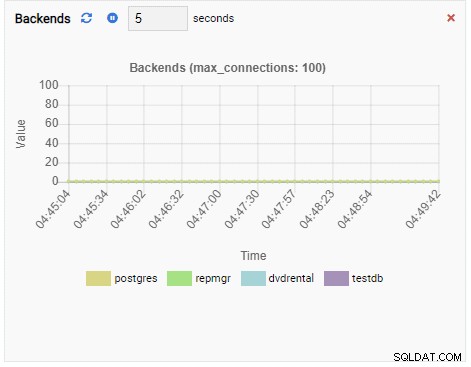
Aantal backends:
Omdat onze instantie inactief is, kunnen we zien dat de TPS-, Locks- en Backends-waarden minimaal zijn.
Het monitoringdashboard testen
We zullen nu pgbench uitvoeren in ons primaire knooppunt (PG-Node1). pgbench is een eenvoudige benchmarking-tool die wordt geleverd met PostgreSQL. Net als de meeste andere tools in zijn soort, maakt pgbench een voorbeeld van een OLTP-systeemschema en tabellen in een database wanneer het wordt geïnitialiseerd. Daarna kan het meerdere clientverbindingen emuleren, waarbij elk een aantal transacties in de database uitvoert. In dit geval zullen we het primaire knooppunt van PostgreSQL niet benchmarken; we zullen alleen de database voor pgbench maken en kijken of onze dashboardbewakingseenheden de verandering in de systeemgezondheid oppikken.
Eerst maken we een database voor pgbench in het primaire knooppunt:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb";CREATE DATABASE
Vervolgens initialiseren we de "testdb"-database voor pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbverwijderen van oude tabellen...maken van tabellen...genereren data...100000 van 2000000 tuples (5%) gedaan (verstreken 0,02 s, resterende 0,43 s)200000 van 2000000 tuples (10%) gedaan (verstreken 0,05 s, resterende 0,41 s)……2000000 van 2000000 tuples (100%) klaar (verstreken 1,84 s, resterende 0,00 s)stofzuigen...primaire sleutels maken...klaar.
Met de database geïnitialiseerd, beginnen we nu met het daadwerkelijke laadproces. In het onderstaande codefragment vragen we pgbench om te beginnen met 50 gelijktijdige clientverbindingen met de testdb-database, waarbij elke verbinding 100.000 transacties op zijn tabellen uitvoert. De laadtest loopt over twee threads.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbstart vacuüm...end.……
Als we nu teruggaan naar ons OmniDB-dashboard, zien we dat de Monitoring Units heel andere resultaten laten zien.
De TPS-statistiek toont een vrij hoge waarde. Er is een plotselinge sprong van minder dan 2 naar meer dan 2000:
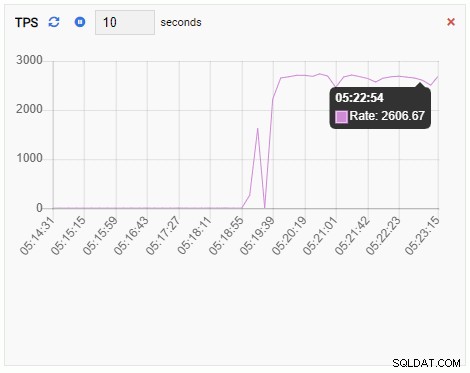
Het aantal backends is toegenomen. Zoals verwacht heeft testdb 50 connecties terwijl andere databases inactief zijn:
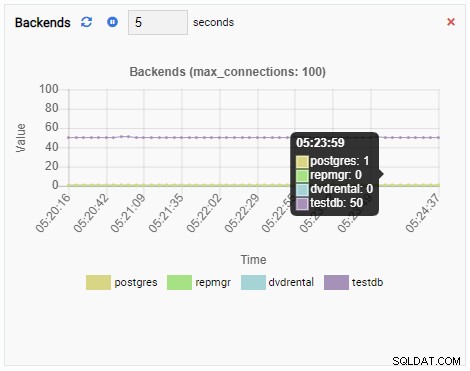
En tot slot is het aantal rij-exclusieve vergrendelingen in de testdb-database ook hoog:
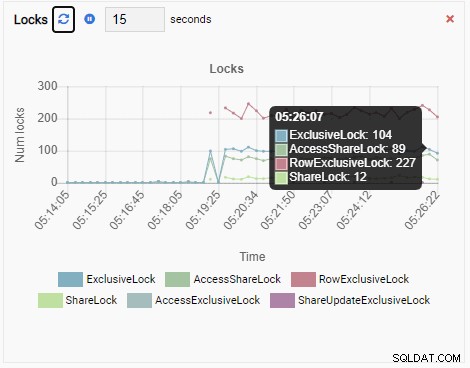
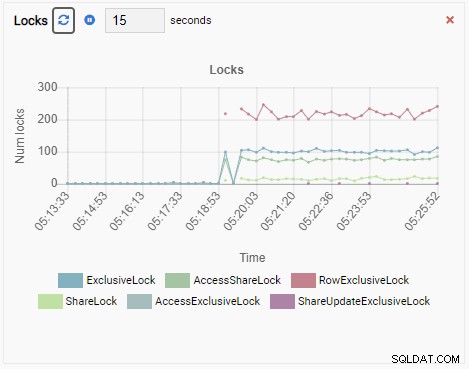
Stel je dit nu eens voor. U bent een DBA en u gebruikt OmniDB voor het beheren van een vloot van PostgreSQL-instanties. In een van de gevallen wordt u gebeld om de trage prestaties te onderzoeken.
Met behulp van een dashboard zoals we zojuist hebben gezien (hoewel het een heel eenvoudige is), kun je gemakkelijk de oorzaak vinden. U kunt het aantal backends, vergrendelingen, beschikbaar geheugen, enz. controleren om te zien wat het probleem veroorzaakt.
En dat is waar OmniDB een erg handig hulpmiddel kan zijn.
Aangepaste bewakingseenheden maken
Soms zullen we onze eigen Monitoring Units moeten creëren. Om een nieuwe Monitoring Unit te schrijven, klikken we op de knop “New Unit” in de lijst “Manage Units”. Dit opent een nieuw tabblad met een leeg canvas voor het schrijven van code:
Boven aan het scherm moeten we een naam specificeren voor onze Monitoring Unit, het type selecteren en het standaard verversingsinterval specificeren. We kunnen ook een bestaande unit als sjabloon selecteren.
Onder het kopgedeelte bevinden zich twee tekstvakken. In de "Data Script" -editor schrijven we code om gegevens voor onze Monitoring Unit te krijgen. Elke keer dat een eenheid wordt vernieuwd, wordt de datascriptcode uitgevoerd. In de "Chart Script" -editor schrijven we code voor het tekenen van de eigenlijke eenheid. Dit wordt uitgevoerd wanneer de eenheid de eerste keer wordt getekend.
Alle datascriptcode is geschreven in Python. Voor de Monitoring Unit van het type Grafiek moet OmniDB het grafiekscript schrijven in Chart.js.
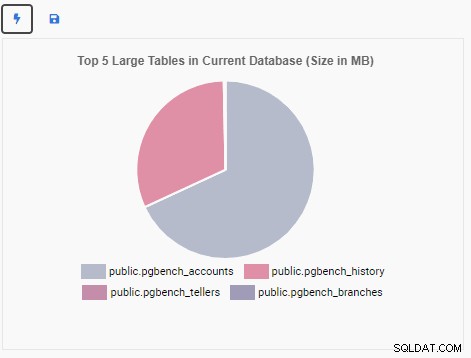
We gaan nu een Monitoring Unit maken om de top 5 grote tabellen in de huidige database weer te geven. Op basis van de database die is geselecteerd in OmniDB, zal de Monitoring Unit de weergave wijzigen om de namen van de vijf grootste tabellen in die database weer te geven.
Voor het schrijven van een nieuwe Unit kun je het beste beginnen met een bestaande sjabloon en de code ervan wijzigen. Dit bespaart zowel tijd als moeite. In de volgende afbeelding hebben we onze Monitoring Unit "Top 5 Large Tables" genoemd. We hebben ervoor gekozen om van het kaarttype te zijn (No Append) en hebben een verversingssnelheid van 30 seconden geboden. We hebben onze Monitoring Unit ook gebaseerd op de sjabloon Databasegrootte:
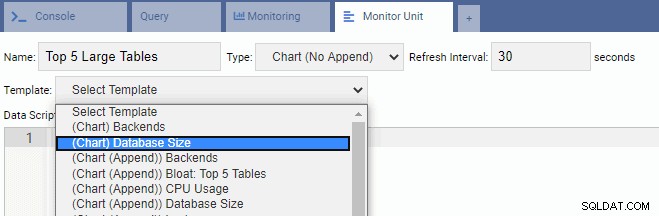
Het tekstvak Data Script wordt automatisch ingevuld met de code voor Database Size Monitoring Unit:
from datetime import datetimefrom random import randintdatabases =connection.Query(''' SELECT d.datname AS datname, round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size FROM pg_catalog.pg_database WHEREd datname not in ('template0','template1')''')data =[]color =[]label =[]voor db in databases.Rijen: data.append(db["size"]) color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "labels "(Tot:label, "datasets":[ { "data":data, "backgroundColor":color, "label":"Dataset 1" ] } ] " MB)"} En het tekstvak Grafiekscript is ook gevuld met code:
total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT datistemplate''')result ={ "type":"pie" , "data":Geen, "options":{ "responsive":True, "title":{ "display":True, "text":"Databasegrootte ((totaal)_ + str } }} We kunnen het Data Script aanpassen om de top 5 grote tabellen in de database te krijgen. In het onderstaande script hebben we het grootste deel van de originele code behouden, behalve de SQL-instructie:
from datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tablename", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" FROM pg_class C LEFT JOIN pg_namespace N ON (N.oid =C.relnamespace) WHERE nspname NOT IN ('pg_catalog', 'information_schema') AND C.relkind <> 'i' AND nspname !~ '^pOR_toast' BY 2 DESC LIMIT 5;''')data =[]color =[]label =[]voor tabel in tabellen.Rijen: data.append(table["table_size"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(tabel["tabelnaam" ])result ={ "labels":label, "datasets":[ { "data":data, "backgroundColor":kleur, "label" }
Hier krijgen we de gecombineerde grootte van elke tabel en zijn indexen in de huidige database. We sorteren de resultaten in aflopende volgorde en selecteren de bovenste vijf rijen.
Vervolgens vullen we drie Python-arrays door de resultatenset te herhalen.
Ten slotte bouwen we een JSON-string op basis van de waarden van de arrays.
In het tekstvak Grafiekscript hebben we de code gewijzigd om de oorspronkelijke SQL-opdracht te verwijderen. Hier specificeren we alleen het cosmetische aspect van de grafiek. We definiëren het diagram als taarttype en geven er een titel voor:
result ={ "type":"pie", "data":Geen, "options":{ "responsive":True, "title":{ "display":True, Groot Tabellen in huidige database (grootte in MB)" } }}
Nu kunnen we het apparaat testen door op het bliksempictogram te klikken. Dit toont de nieuwe Monitoring Unit in het preview-tekengebied:
Vervolgens slaan we het apparaat op door op het schijfpictogram te klikken. Een berichtvenster bevestigt dat het apparaat is opgeslagen:

We gaan nu terug naar ons monitoringdashboard en voegen de nieuwe Monitoring Unit toe:
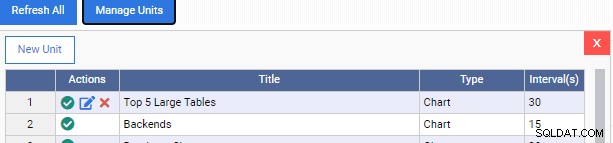
Merk op dat we nog twee pictogrammen hebben onder de kolom "Acties" voor onze aangepaste Monitoring Unit. De ene is om het te bewerken, de andere is om het uit OmniDB te verwijderen.
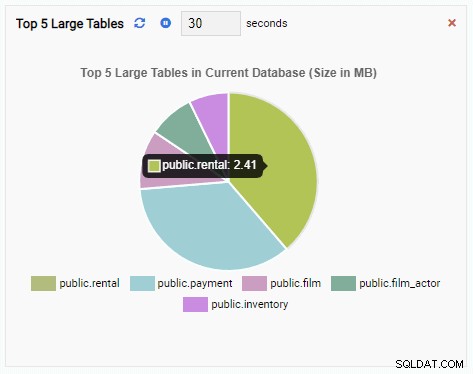
De Monitoring Unit "Top 5 grote tabellen" toont nu de vijf grootste tabellen in de huidige database:
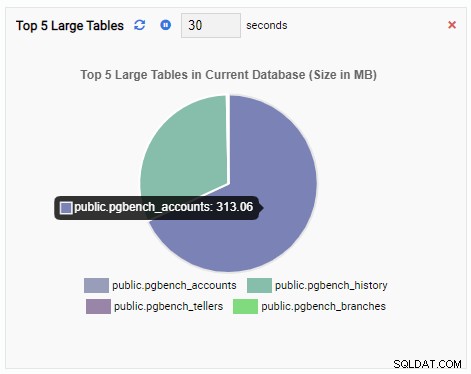
Als we het dashboard sluiten, vanuit het navigatievenster naar een andere database overschakelen en het dashboard opnieuw openen, zien we dat de Monitoring Unit is gewijzigd om de tabellen van die database weer te geven:
Laatste woorden
Dit besluit onze tweedelige serie over OmniDB. Zoals we hebben gezien, heeft OmniDB een aantal handige Monitoring Units die PostgreSQL DBA's nuttig zullen vinden voor het bijhouden van prestaties. We hebben gezien hoe we deze units kunnen gebruiken om mogelijke knelpunten in de server te identificeren. We hebben ook gezien hoe we onze eigen aangepaste eenheden kunnen maken. Lezers worden aangemoedigd om prestatiebewakingseenheden te maken en te testen voor hun specifieke workloads. 2ndQuadrant verwelkomt elke bijdrage aan de OmniDB Monitoring Unit GitHub repo.