Sidenote/DISCLAIMER:
Dit is een slecht idee, aangezien de aanmaaktijd van de tabel niet 100% betrouwbaar is, omdat de tabel intern kan zijn verwijderd en opnieuw is gemaakt vanwege bewerkingen op de tafel, zoals CLUSTER.
Afgezien daarvan kun je de aanmaaktijd als volgt krijgen (ervan uitgaande dat voorbeeld-tabelnaam van t_benutzer ):
--select datname, datdba from pg_database;
--select relname, relfilenode from pg_class where relname ilike 't_benutzer';
-- (select relfilenode::text from pg_class where relname ilike 't_benutzer')
SELECT
pg_ls_dir
,
(
SELECT creation
FROM pg_stat_file('./base/'
||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
|| '/' || pg_ls_dir
)
) as createtime
FROM pg_ls_dir(
'./base/' ||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
)
WHERE pg_ls_dir = (SELECT relfilenode::text FROM pg_class WHERE relname ILIKE 't_benutzer')
Het geheim is om pg_stat_file te gebruiken in het respectievelijke tabelbestand.
-- https://www.greenplumdba.com/greenplum-dba-faq/howtofindtablecreationdateingreenplum
select
pg_ls_dir
,
(
select
--size
--access
--modification
--change
creation
--isdir
from pg_stat_file(pg_ls_dir)
) as createtime
from pg_ls_dir('.');
Volgens de opmerking in dit bericht PostgreSQL:tijd voor het maken van tabellen dit is niet 100% betrouwbaar, omdat de tabel mogelijk intern is verwijderd en opnieuw is gemaakt vanwege bewerkingen op de tafel, zoals CLUSTER.
Ook het patroon
/main/base/<database id>/<table filenode id>
lijkt verkeerd te zijn, want op mijn computer hebben alle tabellen van verschillende databases hetzelfde database-ID, en het lijkt alsof de map is vervangen door een willekeurig inodenummer, dus u moet de map vinden waarvan het nummer het dichtst bij dat van uw tabel ligt inode-id (max. mapnaam waarbij map-id <=table_inode_id en mapnaam numeriek is)
Vereenvoudigde versie gaat als volgt:
SELECT creation
FROM pg_stat_file(
'./base/'
||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
|| '/' || (SELECT relfilenode::text FROM pg_class WHERE relname ILIKE 't_benutzer')
)
Vervolgens kunt u information_schema en cte gebruiken om de query eenvoudig te maken, of uw eigen weergave maken:
;WITH CTE AS
(
SELECT
table_name
,
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE table_name)
) as folder
,(SELECT relfilenode FROM pg_class WHERE relname ILIKE table_name) filenode
FROM information_schema.tables
WHERE table_type = 'BASE TABLE'
AND table_schema = 'public'
)
SELECT
table_name
,(
SELECT creation
FROM pg_stat_file(
'./base/' || folder || '/' || filenode
)
) as creation_time
FROM CTE
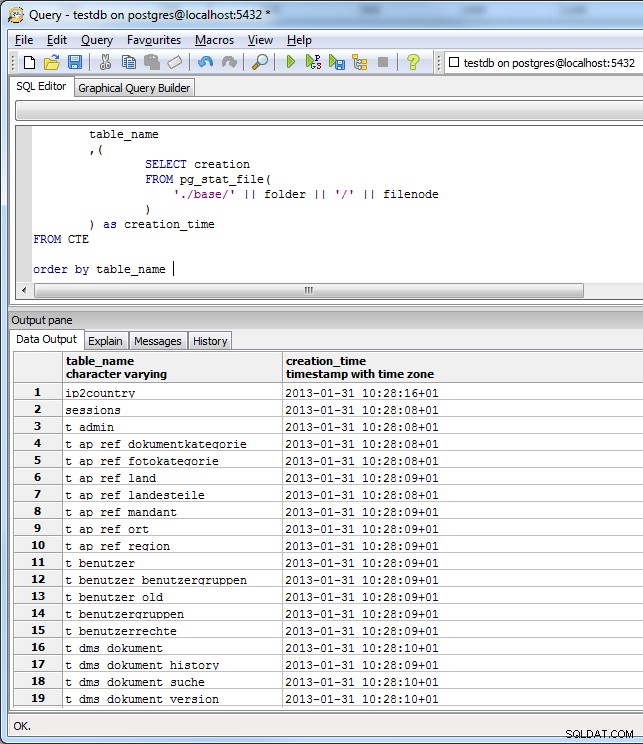
(alle tabellen gemaakt met nhibernate-schema maken, dus de min of meer dezelfde tijd op alle tabellen op de schermafbeelding is correct).
Gebruik voor risico's en bijwerkingen uw verstand en/of vraag uw arts of apotheker;)