Wanneer u aan een project werkt dat uit veel microservices bestaat, zal het waarschijnlijk ook meerdere databases bevatten.
U kunt bijvoorbeeld een MySQL-database en een PostgreSQL-database hebben, die beide op afzonderlijke servers draaien.
Om de gegevens uit de twee databases samen te voegen, moet u meestal een nieuwe microservice introduceren die de gegevens samenvoegt. Maar dit zou de complexiteit van het systeem vergroten.
In deze zelfstudie gebruiken we Materialise om MySQL en Postgres in een live gematerialiseerde weergave samen te voegen. We kunnen dat dan rechtstreeks opvragen en in realtime resultaten terugkrijgen van beide databases met behulp van standaard SQL.
Materialise is een bronbeschikbare streamingdatabase die is geschreven in Rust en die de resultaten van een SQL-query (een gematerialiseerde weergave) in het geheugen bewaart terwijl de gegevens veranderen.
De tutorial bevat een demoproject waarmee u aan de slag kunt gaan met docker-compose .
Het demo-project dat we gaan gebruiken, zal de bestellingen op onze nepwebsite volgen. Het genereert gebeurtenissen die later kunnen worden gebruikt om meldingen te verzenden wanneer een winkelwagentje voor een lange tijd is verlaten.
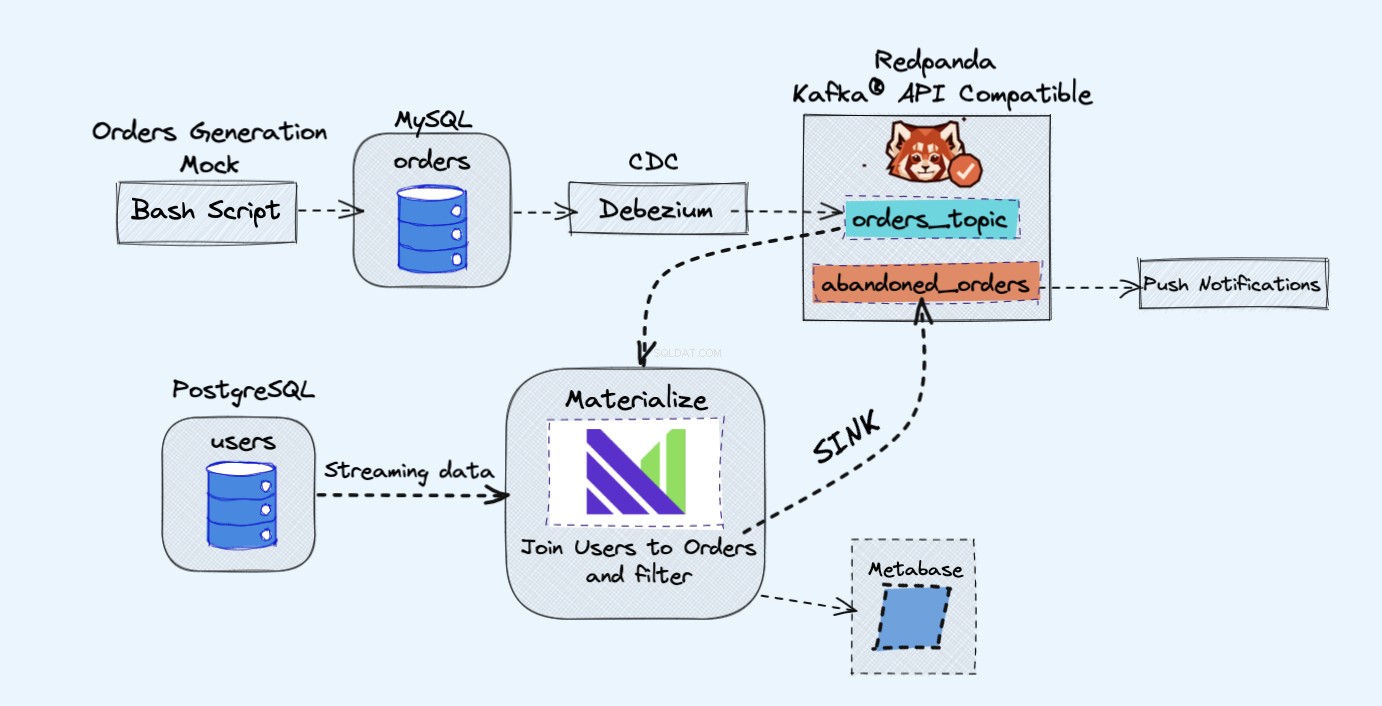
De architectuur van het demoproject is als volgt:
Vereisten
Alle services die we in de demo zullen gebruiken, draaien in Docker-containers, op die manier hoeft u geen extra services op uw laptop of server te installeren in plaats van Docker en Docker Compose.
Als je Docker en Docker Compose nog niet hebt geïnstalleerd, kun je de officiële instructies volgen om dat hier te doen:
- Installeer Docker
- Installeer Docker Compose
Overzicht
Zoals weergegeven in het bovenstaande diagram, hebben we de volgende componenten:
- Een nepservice om voortdurend bestellingen te genereren.
- De bestellingen worden opgeslagen in een MySQL-database .
- Terwijl de database schrijft, Debezium streamt de wijzigingen uit MySQL naar een Redpanda onderwerp.
- We hebben ook een Postgres database waar we onze gebruikers kunnen krijgen.
- We zullen dit Redpanda-onderwerp dan opnemen in Materialize rechtstreeks samen met de gebruikers uit de Postgres-database.
- In Materialize voegen we onze bestellingen en gebruikers samen, doen we wat filtering en creëren we een gematerialiseerde weergave die de verlaten winkelwageninformatie toont.
- We zullen dan een gootsteen maken om de verlaten winkelwagengegevens naar een nieuw Redpanda-onderwerp te sturen.
- Aan het eind gebruiken we Metabase om de gegevens te visualiseren.
- U kunt de informatie uit dat nieuwe onderwerp later gebruiken om meldingen naar uw gebruikers te sturen en hen eraan te herinneren dat ze een verlaten winkelwagentje hebben.
Als een kanttekening hier, zou je prima Kafka gebruiken in plaats van Redpanda. Ik hou gewoon van de eenvoud die Redpanda naar voren brengt, omdat je een enkele Redpanda-instantie kunt uitvoeren in plaats van alle Kafka-componenten.
De demo uitvoeren
Begin eerst met het klonen van de repository:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Daarna heeft u toegang tot de directory:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Laten we beginnen door eerst de Redpanda-container uit te voeren:
docker-compose up -d redpanda
Bouw de afbeeldingen:
docker-compose build
Start ten slotte alle services:
docker-compose up -d
Om de Materialise CLI te starten, kunt u de volgende opdracht uitvoeren:
docker-compose run mzcli
Dit is slechts een snelkoppeling naar een Docker-container met postgres-client voorgeïnstalleerd. Als je al psql . hebt je zou psql -U materialize -h localhost -p 6875 materialize kunnen uitvoeren in plaats daarvan.
Hoe maak je een Materialise Kafka-bron
Nu u zich in de Materialise CLI bevindt, gaan we de orders definiëren tabellen in de mysql.shop database als Redpanda-bronnen:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Als u de beschikbare kolommen van de orders . zou controleren bron door het volgende statement uit te voeren:
SHOW COLUMNS FROM orders;
Je zou kunnen zien dat, aangezien Materialise de berichtschemagegevens uit het Redpanda-register haalt, het de kolomtypen kent die voor elk attribuut moeten worden gebruikt:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Gematerialiseerde weergaven maken
Vervolgens zullen we onze eerste gematerialiseerde weergave maken om alle gegevens van de orders te krijgen Redpanda-bron:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
U kunt nu SELECT * FROM abandoned_orders; . gebruiken om de resultaten te zien:
SELECT * FROM abandoned_orders;
Voor meer informatie over het maken van gematerialiseerde weergaven, bekijk de sectie Gematerialiseerde weergaven van de Materialise-documentatie.
Een Postgres-bron maken
Er zijn twee manieren om een Postgres-bron te maken in Materialize:
- Debezium gebruiken net zoals we deden met de MySQL-bron.
- De Postgres Materialise Source gebruiken, waarmee je Materialise rechtstreeks met Postgres kunt verbinden, zodat je Debezium niet hoeft te gebruiken.
Voor deze demo zullen we de Postgres Materialize Source gebruiken als een demonstratie over het gebruik ervan, maar voel je vrij om in plaats daarvan Debezium te gebruiken.
Voer de volgende instructie uit om een Postgres Materialise Source te maken:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Een kort overzicht van de bovenstaande verklaring:
MATERIALIZED:materialiseert de gegevens van de PostgreSQL-bron. Alle gegevens worden in het geheugen bewaard en maken bronnen direct selecteerbaar.mz_source:De naam voor de PostgreSQL-bron.CONNECTION:De PostgreSQL-verbindingsparameters.PUBLICATION:De PostgreSQL-publicatie, die de tabellen bevat die naar Materialise moeten worden gestreamd.
Als we eenmaal de PostgreSQL-bron hebben gemaakt, moeten we, om de PostgreSQL-tabellen te kunnen doorzoeken, weergaven maken die de oorspronkelijke tabellen van de upstream-publicatie vertegenwoordigen.
In ons geval hebben we maar één tabel genaamd users dus de verklaring die we zouden moeten uitvoeren is:
CREATE VIEWS FROM SOURCE mz_source (users);
Voer de volgende instructie uit om de beschikbare weergaven te zien:
SHOW FULL VIEWS;
Zodra dat is gebeurd, kunt u de nieuwe weergaven direct opvragen:
SELECT * FROM users;
Laten we nu verder gaan en nog een paar weergaven maken.
Hoe maak je een Kafka-spoelbak
Met Sinks kun je gegevens van Materialize naar een externe bron sturen.
Voor deze demo gebruiken we Redpanda.
Redpanda is Kafka API-compatibel en Materialise kan er gegevens van verwerken net zoals het gegevens uit een Kafka-bron zou verwerken.
Laten we een gematerialiseerde weergave maken die alle onbetaalde bestellingen met een hoog volume bevat:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Zoals je kunt zien, voegen we ons hier feitelijk bij de users weergave die de gegevens rechtstreeks van onze Postgres-bron opneemt, en de abandond_orders weergave die de gegevens van het Redpanda-onderwerp samen opneemt.
Laten we een Sink maken waar we de gegevens van de bovenstaande gematerialiseerde weergave naartoe sturen:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Als u nu verbinding zou maken met de Redpanda-container en het rpk topic consume commando, kunt u de records van het onderwerp lezen.
Op dit moment kunnen we echter geen voorbeeld van de resultaten bekijken met rpk omdat het AVRO-geformatteerd is. Redpanda zou dit hoogstwaarschijnlijk in de toekomst implementeren, maar op dit moment kunnen we het onderwerp daadwerkelijk terug streamen naar Materialise om het formaat te bevestigen.
Zoek eerst de naam van het onderwerp dat automatisch is gegenereerd:
SELECT topic FROM mz_kafka_sinks;
Uitgang:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Bekijk de documentatie hier voor meer informatie over hoe de onderwerpnamen worden gegenereerd.
Maak vervolgens een nieuwe gematerialiseerde bron van dit Redpanda-onderwerp:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Zorg ervoor dat u de naam van het onderwerp dienovereenkomstig wijzigt!
Vraag ten slotte naar deze nieuwe gematerialiseerde weergave:
SELECT * FROM high_volume_orders_test LIMIT 2;
Nu je de gegevens in het onderwerp hebt, kun je andere services er verbinding mee laten maken en deze gebruiken en vervolgens bijvoorbeeld e-mails of waarschuwingen activeren.
Metabase verbinden
Om toegang te krijgen tot de Metabase-instantie gaat u naar https://localhost:3030 als u de demo lokaal uitvoert of https://your_server_ip:3030 als u de demo op een server uitvoert. Volg daarna de stappen om de Metabase-installatie te voltooien.
Zorg ervoor dat u Materialise selecteert als de bron van de gegevens.
Als u klaar bent, kunt u uw gegevens visualiseren zoals u zou doen met een standaard PostgreSQL-database.
De demo stoppen
Voer de volgende opdracht uit om alle services te stoppen:
docker-compose down
Conclusie
Zoals u kunt zien, is dit een heel eenvoudig voorbeeld van hoe u Materialise kunt gebruiken. U kunt Materialise gebruiken om gegevens uit verschillende bronnen op te nemen en deze vervolgens naar verschillende bestemmingen te streamen.
Nuttige bronnen:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT