Python en SQL zijn twee van de belangrijkste talen voor gegevensanalisten.
In dit artikel zal ik je door alles leiden wat je moet weten om Python en SQL te verbinden.
U leert hoe u gegevens uit relationele databases rechtstreeks in uw machine learning-pijplijnen kunt halen, gegevens uit uw Python-toepassing kunt opslaan in een eigen database of welke andere gebruikssituatie u ook kunt bedenken.
Samen behandelen we:
- Waarom leren hoe je Python en SQL samen kunt gebruiken?
- Hoe u uw Python-omgeving en MySQL Server instelt
- Verbinding maken met MySQL-server in Python
- Een nieuwe database maken
- Tabellen en tabelrelaties maken
- Tabellen vullen met gegevens
- Gegevens lezen
- Records bijwerken
- Records verwijderen
- Records maken van Python-lijsten
- Herbruikbare functies creëren om dit in de toekomst allemaal voor ons te doen
Dat is een heleboel zeer nuttige en zeer coole dingen. Laten we beginnen!
Een korte opmerking voordat we beginnen:er is een Jupyter Notebook met alle code die in deze tutorial wordt gebruikt, beschikbaar in deze GitHub-repository. Mee coderen wordt sterk aanbevolen!
De database en SQL-code die hier worden gebruikt, komen allemaal uit mijn vorige Inleiding tot SQL-serie die is gepost op Towards Data Science (neem contact met mij op als je problemen hebt met het bekijken van de artikelen en ik kan je een link sturen om ze gratis te bekijken).
Als je niet bekend bent met SQL en de concepten achter relationele databases, zou ik je op die serie willen wijzen (plus er is natuurlijk een enorme hoeveelheid geweldige dingen beschikbaar hier op freeCodeCamp!)
Waarom Python met SQL?
Voor data-analisten en datawetenschappers heeft Python veel voordelen. Een enorm scala aan open-sourcebibliotheken maakt het een ongelooflijk handig hulpmiddel voor elke gegevensanalist.
We hebben panda's, NumPy en Vaex voor data-analyse, Matplotlib, seaborn en Bokeh voor visualisatie, en TensorFlow, scikit-learn en PyTorch voor machine learning-toepassingen (plus nog veel, veel meer).
Met zijn (relatief) gemakkelijke leercurve en veelzijdigheid is het geen wonder dat Python een van de snelstgroeiende programmeertalen is die er zijn.
Dus als we Python gebruiken voor gegevensanalyse, is het de moeite waard om te vragen:waar komen al deze gegevens vandaan?
Hoewel er een enorme verscheidenheid aan bronnen voor datasets is, zullen in veel gevallen - vooral in ondernemingen - gegevens worden opgeslagen in een relationele database. Relationele databases zijn een uiterst efficiënte, krachtige en veelgebruikte manier om allerlei soorten gegevens te creëren, lezen, bijwerken en verwijderen.
De meest gebruikte relationele databasebeheersystemen (RDBMS) - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - gebruiken allemaal de Structured Query Language (SQL) om toegang te krijgen tot en wijzigingen aan te brengen in de gegevens.
Merk op dat elk RDBMS een iets andere smaak van SQL gebruikt, dus SQL-code die voor de ene is geschreven, werkt meestal niet in een andere zonder (normaal gesproken vrij kleine) wijzigingen. Maar de concepten, structuren en operaties zijn grotendeels identiek.
Dit betekent dat voor een werkende Data Analist een goed begrip van SQL enorm belangrijk is. Als u weet hoe u Python en SQL samen kunt gebruiken, krijgt u nog meer voordeel als het gaat om het werken met uw gegevens.
De rest van dit artikel is bedoeld om u precies te laten zien hoe we dat kunnen doen.
Aan de slag
Vereisten en installatie
Om samen met deze tutorial te coderen, heb je je eigen Python-omgeving nodig.
Ik gebruik Anaconda, maar er zijn veel manieren om dit te doen. Google gewoon "hoe Python te installeren" als je meer hulp nodig hebt. U kunt Binder ook gebruiken om samen met het bijbehorende Jupyter Notebook te coderen.
We zullen MySQL Community Server gebruiken omdat het gratis is en veel wordt gebruikt in de industrie. Als u Windows gebruikt, helpt deze handleiding u bij het instellen. Hier zijn ook handleidingen voor Mac- en Linux-gebruikers (hoewel deze per Linux-distributie kunnen verschillen).
Als je die eenmaal hebt ingesteld, moeten we ze met elkaar laten communiceren.
Daarvoor moeten we de MySQL Connector Python-bibliotheek installeren. Volg hiervoor de instructies, of gebruik gewoon pip:
pip install mysql-connector-pythonWe gaan ook panda's gebruiken, dus zorg ervoor dat je dat ook hebt geïnstalleerd.
pip install pandasBibliotheken importeren
Zoals bij elk project in Python, is het allereerste wat we willen doen onze bibliotheken importeren.
Het is een goede gewoonte om alle bibliotheken die we gaan gebruiken aan het begin van het project te importeren, zodat mensen die onze code lezen of bekijken ongeveer weten wat er gaat gebeuren, zodat er geen verrassingen zijn.
Voor deze tutorial gaan we maar twee bibliotheken gebruiken:MySQL Connector en panda's.
import mysql.connector
from mysql.connector import Error
import pandas as pdWe importeren de Error-functie afzonderlijk, zodat we er gemakkelijk toegang toe hebben voor onze functies.
Verbinding maken met MySQL Server
Op dit punt zouden we MySQL Community Server op ons systeem moeten hebben ingesteld. Nu moeten we wat code schrijven in Python waarmee we een verbinding met die server tot stand kunnen brengen.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionHet creëren van een herbruikbare functie voor code als deze is best practice, zodat we deze met minimale inspanning steeds opnieuw kunnen gebruiken. Als dit eenmaal is geschreven, kunt u het in de toekomst ook opnieuw gebruiken in al uw projecten, dus in de toekomst zult u dankbaar zijn!
Laten we dit regel voor regel doornemen, zodat we begrijpen wat hier gebeurt:
De eerste regel is dat we de functie een naam geven (create_server_connection) en de argumenten benoemen die die functie nodig heeft (hostnaam, gebruikersnaam en gebruikerswachtwoord).
De volgende regel sluit alle bestaande verbindingen, zodat de server niet verward raakt met meerdere open verbindingen.
Vervolgens gebruiken we een Python try-behalve-blok om mogelijke fouten af te handelen. Het eerste deel probeert een verbinding met de server tot stand te brengen met behulp van de mysql.connector.connect()-methode met behulp van de details die door de gebruiker in de argumenten zijn opgegeven. Als dit werkt, drukt de functie een gelukkig klein succesbericht af.
Het behalve deel van het blok drukt de fout af die MySQL Server retourneert, in de ongelukkige omstandigheid dat er een fout is.
Ten slotte, als de verbinding succesvol is, retourneert de functie een verbindingsobject.
We gebruiken dit in de praktijk door de uitvoer van de functie toe te wijzen aan een variabele, die dan ons verbindingsobject wordt. We kunnen er dan andere methoden (zoals cursor) op toepassen en andere nuttige objecten maken.
connection = create_server_connection("localhost", "root", pw)Dit zou een succesbericht moeten opleveren:

Een nieuwe database maken
Nu we een verbinding tot stand hebben gebracht, is onze volgende stap het creëren van een nieuwe database op onze server.
In deze tutorial zullen we dit slechts één keer doen, maar nogmaals, we zullen dit schrijven als een herbruikbare functie, zodat we een mooie nuttige functie hebben die we kunnen hergebruiken voor toekomstige projecten.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Deze functie heeft twee argumenten nodig, verbinding (ons verbindingsobject) en query (een SQL-query die we in de volgende stap zullen schrijven). Het voert de query uit in de server via de verbinding.
We gebruiken de cursormethode op ons verbindingsobject om een cursorobject te maken (MySQL Connector gebruikt een objectgeoriënteerd programmeerparadigma, dus er zijn veel objecten die eigenschappen erven van bovenliggende objecten).
Dit cursorobject heeft methoden zoals execute, executemany (die we in deze tutorial zullen gebruiken) samen met verschillende andere handige methoden.
Als het helpt, kunnen we aan het cursorobject denken dat het ons toegang geeft tot de knipperende cursor in een MySQL Server-terminalvenster.
Vervolgens definiëren we een query om de database te maken en roepen we de functie aan:

Alle SQL-query's die in deze zelfstudie worden gebruikt, worden uitgelegd in mijn Inleiding tot SQL-zelfstudiereeks, en de volledige code is te vinden in de bijbehorende Jupyter Notebook in deze GitHub-repository, dus ik zal geen uitleg geven over wat de SQL-code in deze zelfstudie.
Dit is misschien wel de eenvoudigste SQL-query die mogelijk is. Als je Engels kunt lezen, kun je waarschijnlijk achterhalen wat het doet!
Het uitvoeren van de functie create_database met de argumenten zoals hierboven resulteert in een database met de naam 'school' die op onze server wordt aangemaakt.
Waarom heet onze database 'school'? Misschien is het nu een goed moment om nader te bekijken wat we precies gaan implementeren in deze tutorial.
Onze database
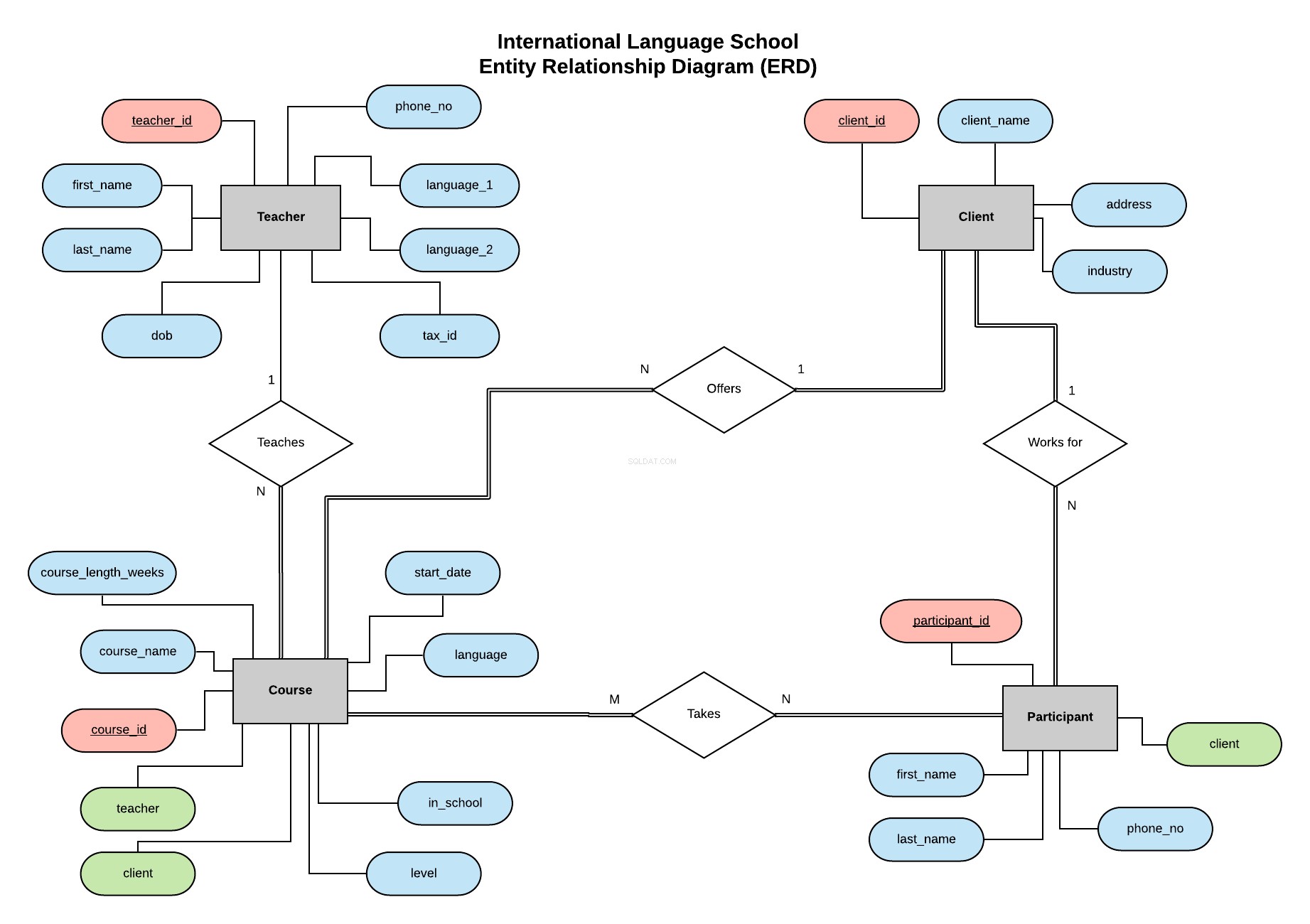
In navolging van het voorbeeld in mijn vorige serie gaan we de database implementeren voor de International Language School - een fictieve taalschool die professionele taallessen geeft aan zakelijke klanten.
Dit Entity Relationship Diagram (ERD) geeft een overzicht van onze entiteiten (leraar, cliënt, cursus en deelnemer) en definieert de relaties daartussen.
Alle informatie over wat een ERD is en waar u op moet letten bij het maken van een ERD en het ontwerpen van een database, vindt u in dit artikel.
De onbewerkte SQL-code, databasevereisten en gegevens om naar de database te gaan, zijn allemaal opgenomen in deze GitHub-repository, maar je zult het allemaal zien als we deze tutorial ook doornemen.
Verbinding maken met de database
Nu we een database hebben gemaakt in MySQL Server, kunnen we onze functie create_server_connection aanpassen om rechtstreeks verbinding te maken met deze database.
Merk op dat het mogelijk is - in feite gebruikelijk - om meerdere databases op één MySQL-server te hebben, dus we willen altijd en automatisch verbinding maken met de database waarin we geïnteresseerd zijn.
We kunnen dit als volgt doen:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionDit is exact dezelfde functie, maar nu nemen we nog een argument - de databasenaam - en geven dat door aan de methode connect() .
Een functie voor het uitvoeren van query's maken
De laatste functie die we (voorlopig) gaan maken, is een uiterst belangrijke - een functie voor het uitvoeren van query's. Hiermee worden onze SQL-query's, opgeslagen in Python als strings, doorgegeven aan de methode cursor.execute() om ze op de server uit te voeren.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Deze functie is precies hetzelfde als onze functie create_database van eerder, behalve dat deze de methode connection.commit() gebruikt om ervoor te zorgen dat de opdrachten die in onze SQL-query's worden beschreven, worden geïmplementeerd.
Dit wordt onze werkpaardfunctie, die we zullen gebruiken (naast create_db_connection) om tabellen te maken, relaties tussen die tabellen tot stand te brengen, de tabellen te vullen met gegevens en records in onze database bij te werken en te verwijderen.
Als je een SQL-expert bent, kun je met deze functie alle complexe commando's en vragen die je hebt, rechtstreeks vanuit een Python-script uitvoeren. Dit kan een zeer krachtig hulpmiddel zijn voor het beheren van uw gegevens.
Tabellen maken
Nu zijn we helemaal klaar om SQL-commando's op onze server uit te voeren en onze database te bouwen. Het eerste dat we willen doen, is de benodigde tabellen maken.
Laten we beginnen met onze Leraar-tabel:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryAllereerst kennen we ons SQL-commando (hier in detail uitgelegd) toe aan een variabele met een toepasselijke naam.
In dit geval gebruiken we Python's drievoudige aanhalingstekensnotatie voor strings met meerdere regels om onze SQL-query op te slaan, waarna we deze in onze execute_query-functie invoeren om deze te implementeren.
Merk op dat deze opmaak met meerdere regels puur in het voordeel is van mensen die onze code lezen. Noch SQL noch Python kan het schelen of het SQL-commando op deze manier wordt verspreid. Zolang de syntaxis correct is, zullen beide talen deze accepteren.
In het voordeel van mensen die je code zullen lezen (zelfs als dat alleen jij in de toekomst zal zijn!) is het erg handig om dit te doen om de code leesbaarder en begrijpelijker te maken.
Hetzelfde geldt voor de HOOFDLETTERS van operators in SQL. Dit is een veelgebruikte conventie die sterk wordt aanbevolen, maar de eigenlijke software die de code uitvoert, is niet hoofdlettergevoelig en behandelt 'CREATE TABLE teacher' en 'create table teacher' als identieke commando's.

Het uitvoeren van deze code geeft ons onze succesberichten. We kunnen dit ook verifiëren in de MySQL Server Command Line Client:
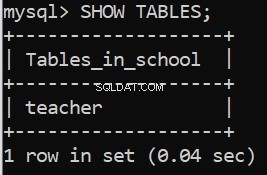
Super goed! Laten we nu de overige tabellen maken.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Dit creëert de vier tabellen die nodig zijn voor onze vier entiteiten.
Nu willen we de relaties ertussen definiëren en nog een tabel maken om de veel-op-veel-relatie tussen de deelnemers- en cursustabellen af te handelen (zie hier voor meer details).
We doen dit op precies dezelfde manier:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Nu zijn onze tabellen gemaakt, samen met de juiste beperkingen, primaire sleutel en externe sleutelrelaties.
De tabellen vullen
De volgende stap is het toevoegen van enkele records aan de tabellen. Opnieuw gebruiken we execute_query om onze bestaande SQL-commando's naar de server te voeren. Laten we opnieuw beginnen met de Leraar-tabel.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)werkt dit? We kunnen het opnieuw controleren in onze MySQL Command Line Client:
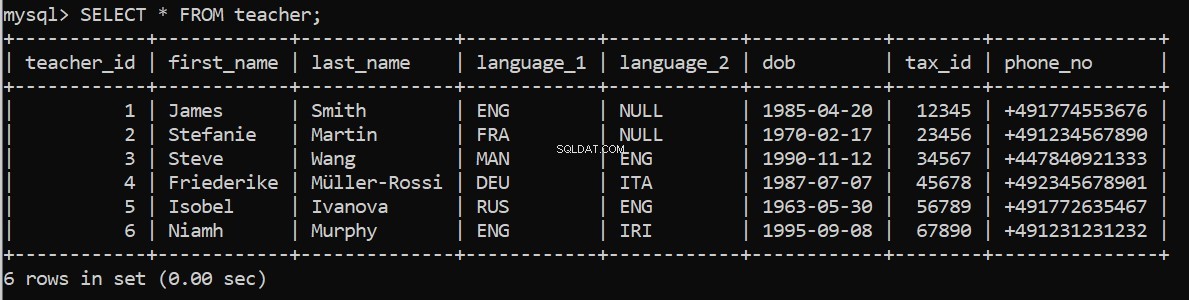
Nu om de resterende tabellen te vullen.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Verbazingwekkend! Nu hebben we een database gemaakt, compleet met relaties, beperkingen en records in MySQL, met alleen Python-commando's.
We hebben dit stap voor stap doorlopen om het begrijpelijk te houden. Maar op dit punt kun je zien dat dit allemaal heel gemakkelijk in één Python-script kan worden geschreven en in één opdracht in de terminal kan worden uitgevoerd. Krachtig spul.
Gegevens lezen
Nu hebben we een functionele database om mee te werken. Als Data Analist kom je waarschijnlijk in aanraking met bestaande databases in de organisaties waar je werkt. Het is erg handig om te weten hoe u gegevens uit die databases kunt halen, zodat deze vervolgens in uw Python-gegevenspijplijn kunnen worden ingevoerd. Hier gaan we nu aan werken.
Hiervoor hebben we nog een functie nodig, deze keer met cursor.fetchall() in plaats van cursor.commit(). Met deze functie lezen we gegevens uit de database en brengen we geen wijzigingen aan.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Nogmaals, we gaan dit op een vergelijkbare manier implementeren als execute_query. Laten we het proberen met een simpele vraag om te zien hoe het werkt.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)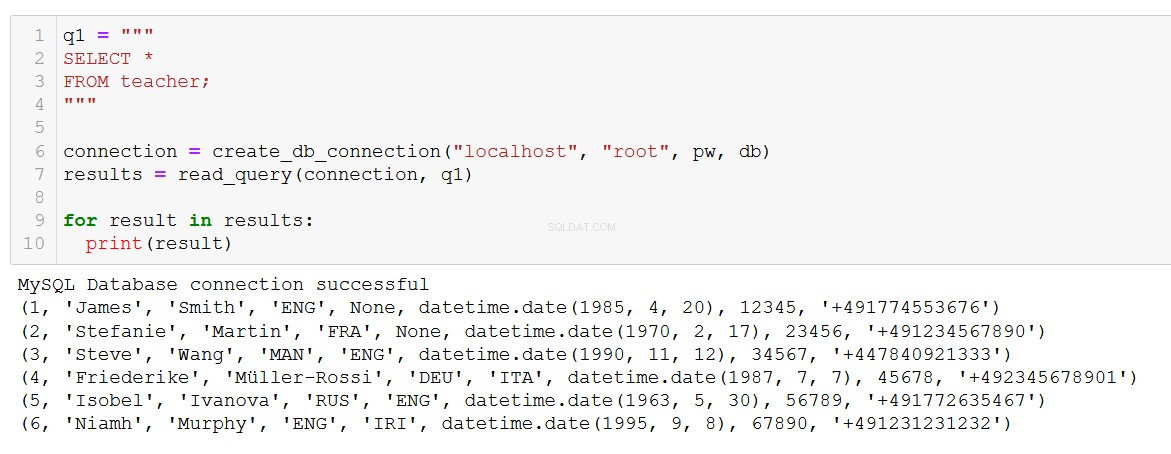
Precies wat we verwachten. De functie werkt ook met complexere zoekopdrachten, zoals deze met een JOIN op de cursus- en klantentafels.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)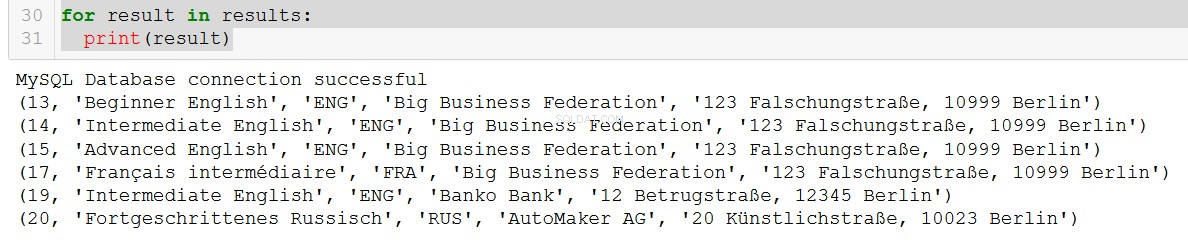
Erg fijn.
Voor onze datapijplijnen en workflows in Python willen we deze resultaten misschien in verschillende formaten krijgen om ze nuttiger te maken of klaar te maken voor ons om te manipuleren.
Laten we een paar voorbeelden doornemen om te zien hoe we dat kunnen doen.
Uitvoer opmaken in een lijst
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Uitvoer opmaken in een lijst met lijsten
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Uitvoer opmaken in een pandas DataFrame
Voor data-analisten die Python gebruiken, is panda's onze mooie en vertrouwde oude vriend. Het is heel eenvoudig om de output van onze database om te zetten in een DataFrame, en van daaruit zijn de mogelijkheden eindeloos!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)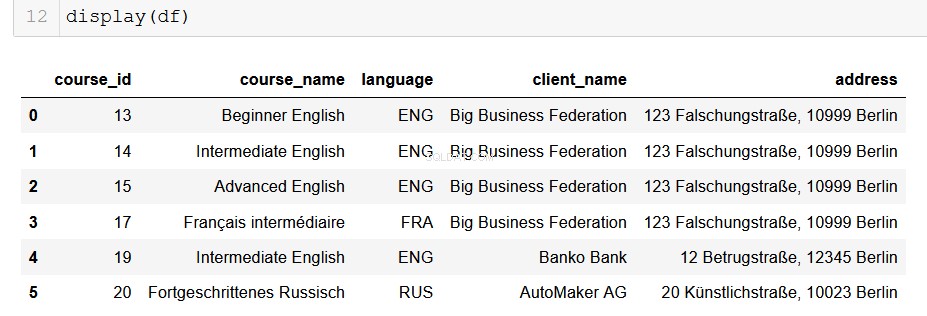
Hopelijk kunt u hier de mogelijkheden voor u zien ontvouwen. Met slechts een paar regels code kunnen we eenvoudig alle gegevens die we aankunnen, extraheren uit de relationele databases waar het zich bevindt, en het in onze ultramoderne pijplijnen voor gegevensanalyse opnemen. Dit is echt nuttig spul.
Records bijwerken
Wanneer we een database onderhouden, moeten we soms wijzigingen aanbrengen in bestaande records. In dit gedeelte gaan we kijken hoe u dat kunt doen.
Laten we zeggen dat de ILS op de hoogte is gebracht dat een van haar bestaande klanten, de Big Business Federation, kantoren gaat verhuizen naar de Fingiertweg 23, 14534 Berlijn. In dit geval moet de databasebeheerder (dat zijn wij!) enkele wijzigingen aanbrengen.
Gelukkig kunnen we dit doen met onze functie execute_query naast de SQL UPDATE-instructie.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Merk op dat de WHERE-clausule hier erg belangrijk is. Als we deze query uitvoeren zonder de WHERE-clausule, worden alle adressen voor alle records in onze Client-tabel bijgewerkt naar 23 Fingiertweg. Dat is helemaal niet wat we willen doen.
Merk ook op dat we "WHERE client_id =101" hebben gebruikt in de UPDATE-query. Het zou ook mogelijk zijn geweest om "WHERE client_name ='Big Business Federation'" of "WHERE address ='123 Falschungstraße, 10999 Berlin'" of zelfs "WHERE address LIKE '%Falschung%'" te gebruiken.
Het belangrijkste is dat we met de WHERE-clausule het record (of de records) die we willen bijwerken uniek kunnen identificeren.
Records verwijderen
Het is ook mogelijk om onze execute_query functie te gebruiken om records te verwijderen, door gebruik te maken van DELETE.
Wanneer we SQL gebruiken met relationele databases, moeten we voorzichtig zijn met het gebruik van de DELETE-operator. Dit is geen Windows, er is geen 'Weet u zeker dat u dit wilt verwijderen?' waarschuwingspop-up en er is geen prullenbak. Zodra we iets verwijderen, is het echt weg.
Dat gezegd hebbende, we moeten soms echt dingen verwijderen. Laten we daar eens naar kijken door een cursus uit onze cursustabel te verwijderen.
Laten we ons er allereerst aan herinneren welke cursussen we hebben.
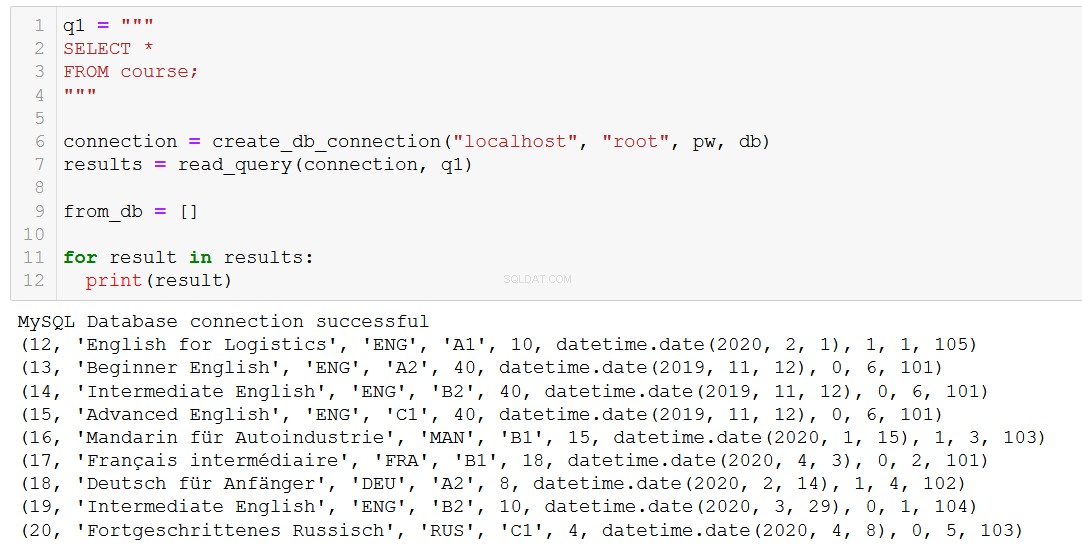
Laten we zeggen dat cursus 20, 'Fortgeschrittenes Russisch' (dat is 'Geavanceerd Russisch' voor jou en mij), ten einde loopt, dus we moeten het uit onze database verwijderen.
In dit stadium zult u helemaal niet verbaasd zijn over hoe we dit doen - sla de SQL-opdracht op als een tekenreeks en voer deze vervolgens in onze werkpaard execute_query-functie.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Laten we controleren of dit het beoogde effect had:
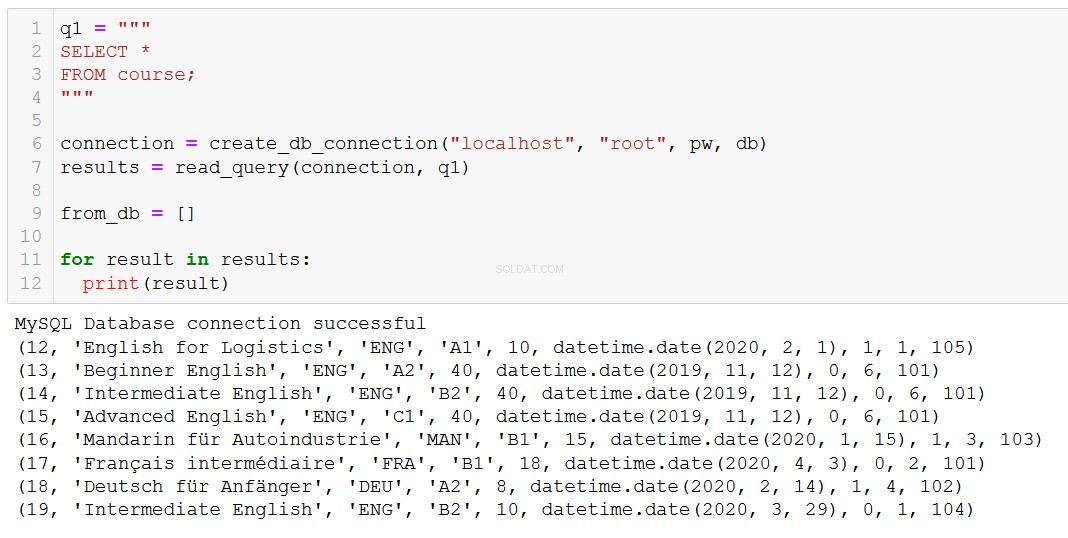
'Advanced Russian' is weg, zoals we verwachtten.
Dit werkt ook met het verwijderen van hele kolommen met DROP COLUMN en hele tabellen met DROP TABLE-opdrachten, maar die zullen we in deze zelfstudie niet behandelen.
Ga je gang en experimenteer ermee - het maakt niet uit of je een kolom of tabel verwijdert uit een database voor een fictieve school, en het is een goed idee om vertrouwd te raken met deze commando's voordat je naar een productieomgeving gaat.
Oh CRUD
Op dit punt zijn we nu in staat om de vier belangrijkste bewerkingen voor permanente gegevensopslag te voltooien.
We hebben geleerd hoe:
- Maken - geheel nieuwe databases, tabellen en records
- Lezen - extraheer gegevens uit een database en sla die gegevens op in meerdere indelingen
- Update - breng wijzigingen aan in bestaande records in de database
- Verwijderen - verwijder records die niet langer nodig zijn
Dit zijn fantastisch nuttige dingen om te kunnen doen.
Voordat we het hier afronden, moeten we nog een zeer handige vaardigheid leren.
Records maken van lijsten
We zagen bij het vullen van onze tabellen dat we de SQL INSERT-opdracht in onze execute_query-functie kunnen gebruiken om records in onze database in te voegen.
Aangezien we Python gebruiken om onze SQL-database te manipuleren, zou het handig zijn om een Python-gegevensstructuur (zoals een lijst) te kunnen nemen en die rechtstreeks in onze database in te voegen.
Dit kan handig zijn als we logs van gebruikersactiviteit willen opslaan op een app voor sociale media die we in Python hebben geschreven, of input van gebruikers in een Wiki die we hebben gebouwd, bijvoorbeeld. Er zijn zoveel mogelijke toepassingen hiervoor als je maar kunt bedenken.
Deze methode is ook veiliger als onze database op elk moment open staat voor onze gebruikers, omdat het helpt bij het voorkomen van SQL-injectie-aanvallen, die onze hele database kunnen beschadigen of zelfs vernietigen.
Om dit te doen, zullen we een functie schrijven met de methode executemany() in plaats van de eenvoudigere methode execute() die we tot nu toe hebben gebruikt.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Nu hebben we de functie, we moeten een SQL-commando ('sql') definiëren en een lijst met de waarden die we in de database willen invoeren ('val'). De waarden moeten worden opgeslagen als een lijst met tuples, wat een vrij gebruikelijke manier is om gegevens in Python op te slaan.
Om twee nieuwe docenten aan de database toe te voegen, kunnen we een code zoals deze schrijven:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Merk hier op dat we in de 'sql'-code de '%s' gebruiken als een tijdelijke aanduiding voor onze waarde. De gelijkenis met de tijdelijke aanduiding '%s' voor een tekenreeks in python is gewoon toeval (en eerlijk gezegd erg verwarrend), we willen '%s' gebruiken voor alle gegevenstypen (tekenreeksen, ints, datums, enz.) met de MySQL Python Aansluiting.
Je kunt een aantal vragen over StackOverflow zien waarbij iemand in de war is geraakt en heeft geprobeerd '%d' tijdelijke aanduidingen te gebruiken voor gehele getallen, omdat ze dit gewend zijn in Python. Dit werkt hier niet - we moeten een '%s' gebruiken voor elke kolom waaraan we een waarde willen toevoegen.
De functie executemany neemt vervolgens elke tuple in onze 'val'-lijst en voegt de relevante waarde voor die kolom in plaats van de tijdelijke aanduiding in en voert het SQL-commando uit voor elke tuple in de lijst.
Dit kan worden uitgevoerd voor meerdere rijen met gegevens, zolang ze maar correct zijn opgemaakt. In ons voorbeeld zullen we slechts twee nieuwe docenten toevoegen, ter illustratie, maar in principe kunnen we er zoveel toevoegen als we zouden willen.
Laten we doorgaan en deze query uitvoeren en de docenten toevoegen aan onze database.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)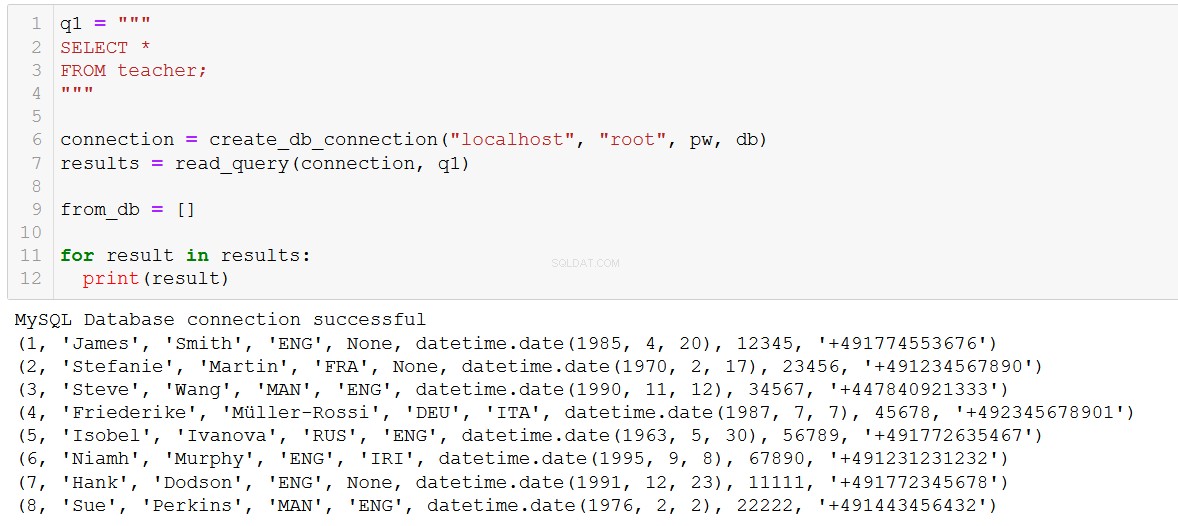
Welkom bij de ILS, Hank en Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusie
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!
