Prestaties zijn uiterst belangrijk in veel consumentenproducten zoals e-commerce, betalingssystemen, gaming, transport-apps, enzovoort. Hoewel databases intern worden geoptimaliseerd via meerdere mechanismen om te voldoen aan hun prestatie-eisen in de moderne wereld, hangt veel ook af van de applicatie-ontwikkelaar - tenslotte weet alleen een ontwikkelaar welke query's de applicatie moet uitvoeren.
Ontwikkelaars die zich bezighouden met relationele databases hebben indexering al gebruikt of hebben er tenminste van gehoord, en het is een veel voorkomend concept in de databasewereld. Het belangrijkste is echter om te begrijpen wat u moet indexeren en hoe de indexering de responstijd van de query zal verhogen. Om dat te doen, moet u begrijpen hoe u uw databasetabellen gaat opvragen. Een goede index kan alleen worden gemaakt als u precies weet hoe uw query- en gegevenstoegangspatronen eruitzien.
In eenvoudige terminologie wijst een index zoeksleutels toe aan overeenkomstige gegevens op schijf door gebruik te maken van verschillende gegevensstructuren in het geheugen en op de schijf. Index wordt gebruikt om het zoeken te versnellen door het aantal te zoeken records te verminderen.
Meestal wordt een index gemaakt op de kolommen die zijn opgegeven in de WHERE clausule van een query terwijl de database gegevens uit de tabellen ophaalt en filtert op basis van die kolommen. Als u geen index maakt, scant de database alle rijen, filtert de overeenkomende rijen eruit en retourneert het resultaat. Met miljoenen records kan deze scanbewerking vele seconden duren en deze hoge responstijd maakt API's en applicaties langzamer en onbruikbaar. Laten we een voorbeeld bekijken —
We zullen MySQL gebruiken met een standaard InnoDB-database-engine, hoewel de concepten die in dit artikel worden uitgelegd min of meer hetzelfde zijn in andere databaseservers, zoals Oracle, MSSQL enz.
Maak een tabel met de naam index_demo met het volgende schema:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Hoe verifiëren we dat we de InnoDB-engine gebruiken?
Voer het onderstaande commando uit:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;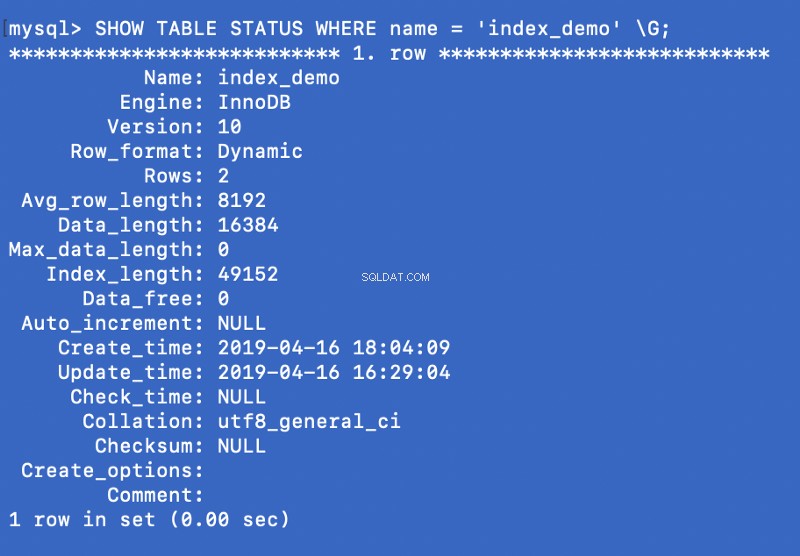
De Engine kolom in de bovenstaande schermafbeelding vertegenwoordigt de engine die wordt gebruikt om de tabel te maken. Hier InnoDB wordt gebruikt.
Voeg nu wat willekeurige gegevens in de tabel in, mijn tabel met 5 rijen ziet er als volgt uit:
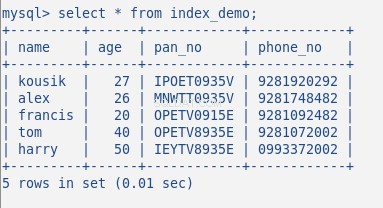
Ik heb tot nu toe geen index gemaakt voor deze tabel. Laten we dit verifiëren met het commando:SHOW INDEX . Het levert 0 resultaten op.

Als we op dit moment een eenvoudige SELECT query, aangezien er geen door de gebruiker gedefinieerde index is, scant de query de hele tabel om het resultaat te achterhalen:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN laat zien hoe de query-engine van plan is de query uit te voeren. In de bovenstaande schermafbeelding kunt u zien dat de rows kolom retourneert 5 &possible_keys retourneert null . possible_keys geeft aan wat alle beschikbare indices zijn die in deze query kunnen worden gebruikt. De key kolom geeft aan welke index daadwerkelijk zal worden gebruikt van alle mogelijke indices in deze zoekopdracht.
Primaire sleutel:
De bovenstaande query is erg inefficiënt. Laten we deze zoekopdracht optimaliseren. We maken de phone_no kolom a PRIMARY KEY ervan uitgaande dat er geen twee gebruikers in ons systeem kunnen bestaan met hetzelfde telefoonnummer. Houd rekening met het volgende bij het maken van een primaire sleutel:
- Een primaire sleutel moet deel uitmaken van veel essentiële vragen in uw toepassing.
- Primaire sleutel is een beperking die elke rij in een tabel op unieke wijze identificeert. Als meerdere kolommen deel uitmaken van de primaire sleutel, moet die combinatie uniek zijn voor elke rij.
- Primaire sleutel moet niet-null zijn. Maak nooit van null-velden uw primaire sleutel. Volgens ANSI SQL-standaarden moeten primaire sleutels met elkaar vergelijkbaar zijn en moet u zeker kunnen zien of de waarde van de primaire sleutelkolom voor een bepaalde rij groter, kleiner of gelijk is aan die van een andere rij. Sinds
NULLbetekent een ongedefinieerde waarde in SQL-standaarden, u kuntNULLniet deterministisch vergelijken met elke andere waarde, dus logischNULLis niet toegestaan. - Het ideale type primaire sleutel moet een getal zijn zoals
INTofBIGINTomdat vergelijkingen van gehele getallen sneller zijn, dus het doorlopen van de index zal erg snel gaan.
Vaak definiëren we een id veld als AUTO INCREMENT in tabellen en gebruik die als primaire sleutel, maar de keuze van een primaire sleutel hangt af van ontwikkelaars.
Wat als u zelf geen primaire sleutel maakt?
Het is niet verplicht om zelf een primaire sleutel aan te maken. Als u geen primaire sleutel hebt gedefinieerd, maakt InnoDB er impliciet een voor u aan, omdat InnoDB door het ontwerp een primaire sleutel in elke tabel moet hebben. Dus zodra u later een primaire sleutel voor die tabel maakt, verwijdert InnoDB de eerder automatisch gedefinieerde primaire sleutel.
Aangezien we vanaf nu geen primaire sleutel hebben gedefinieerd, laten we eens kijken wat InnoDB standaard voor ons heeft gemaakt:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED toont alle indices die niet door de gebruiker kunnen worden gebruikt, maar volledig worden beheerd door MySQL.
Hier zien we dat MySQL een samengestelde index heeft gedefinieerd (we zullen later op samengestelde indices ingaan) op DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR , &alle kolommen die in de tabel zijn gedefinieerd. Bij afwezigheid van een door de gebruiker gedefinieerde primaire sleutel, wordt deze index gebruikt om records op unieke wijze te vinden.
Wat is het verschil tussen sleutel en index?
Hoewel de termen key &index worden door elkaar gebruikt, key betekent een beperking die wordt opgelegd aan het gedrag van de kolom. In dit geval is de beperking dat de primaire sleutel een veld is dat niet null kan worden en dat elke rij op unieke wijze identificeert. Aan de andere kant, index is een speciale gegevensstructuur die het zoeken naar gegevens over de tafel vergemakkelijkt.
Laten we nu de primaire index maken op phone_no &bekijk de gemaakte index:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Merk op dat CREATE INDEX kan niet worden gebruikt om een primaire index te maken, maar ALTER TABLE wordt gebruikt.

In de bovenstaande schermafbeelding zien we dat er één primaire index is gemaakt in de kolom phone_no . De kolommen van de volgende afbeeldingen worden als volgt beschreven:
Table :De tabel waarop de index is gemaakt.
Non_unique :Als de waarde 1 is, is de index niet uniek, als de waarde 0 is, is de index uniek.
Key_name :De naam van de gemaakte index. De naam van de primaire index is altijd PRIMARY in MySQL, ongeacht of u een indexnaam hebt opgegeven of niet tijdens het maken van de index.
Seq_in_index :Het volgnummer van de kolom in de index. Als meerdere kolommen deel uitmaken van de index, wordt het volgnummer toegewezen op basis van de volgorde van de kolommen tijdens het aanmaken van de index. Volgnummer begint bij 1.
Collation :hoe de kolom is gesorteerd in de index. A betekent oplopend, D betekent aflopend, NULL betekent niet gesorteerd.
Cardinality :Het geschatte aantal unieke waarden in de index. Meer kardinaliteit betekent een grotere kans dat de query-optimizer de index voor zoekopdrachten kiest.
Sub_part :Het indexvoorvoegsel. Het is NULL als de hele kolom is geïndexeerd. Anders wordt het aantal geïndexeerde bytes weergegeven voor het geval de kolom gedeeltelijk is geïndexeerd. We zullen de gedeeltelijke index later definiëren.
Packed :Geeft aan hoe de sleutel is verpakt; NULL als dat niet zo is.
Null :YES als de kolom NULL mag bevatten waarden en blanco als dat niet het geval is.
Index_type :Geeft aan welke indexeringsgegevensstructuur voor deze index wordt gebruikt. Enkele mogelijke kandidaten zijn — BTREE , HASH , RTREE , of FULLTEXT .
Comment :De informatie over de index die niet in zijn eigen kolom wordt beschreven.
Index_comment :De opmerking voor de index die is opgegeven toen u de index maakte met de COMMENT attribuut.
Laten we nu eens kijken of deze index het aantal rijen vermindert dat zal worden doorzocht voor een gegeven phone_no in de WHERE clausule van een zoekopdracht.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
Merk in deze momentopname op dat de rows kolom heeft 1 geretourneerd alleen de possible_keys &key beide retourneert PRIMARY . Het betekent dus in wezen dat het gebruik van de primaire index met de naam PRIMARY (de naam wordt automatisch toegewezen wanneer u de primaire sleutel maakt), de query-optimizer gaat gewoon rechtstreeks naar de record en haalt deze op. Het is erg efficiënt. Dit is precies waar een index voor dient — om het zoekbereik te minimaliseren ten koste van extra ruimte.
Geclusterde Index:
Een clustered index wordt samen met de gegevens in dezelfde tabelruimte of hetzelfde schijfbestand geplaatst. Je kunt ervan uitgaan dat een geclusterde index een B-Tree is index waarvan de bladknooppunten de daadwerkelijke gegevensblokken op de schijf zijn, aangezien de index en gegevens bij elkaar staan. Dit soort index organiseert de gegevens op schijf fysiek volgens de logische volgorde van de indexsleutel.
Wat betekent fysieke gegevensorganisatie?
Fysiek zijn gegevens op schijf georganiseerd over duizenden of miljoenen schijf- / gegevensblokken. Voor een geclusterde index is het niet verplicht dat alle schijfblokken besmettelijk worden opgeslagen. Fysieke datablokken worden de hele tijd hier en daar door het besturingssysteem verplaatst wanneer dat nodig is. Een databasesysteem heeft geen absolute controle over hoe de fysieke gegevensruimte wordt beheerd, maar binnen een gegevensblok kunnen records worden opgeslagen of beheerd in de logische volgorde van de indexsleutel. Het volgende vereenvoudigde diagram legt het uit:
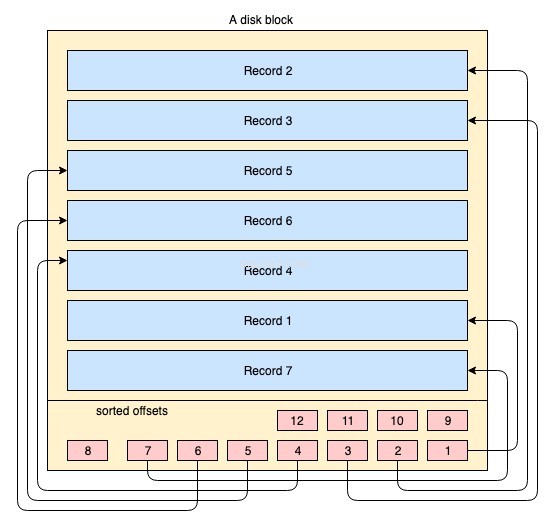
- De geel gekleurde grote rechthoek vertegenwoordigt een schijfblok / datablok
- de blauw gekleurde rechthoeken vertegenwoordigen gegevens die zijn opgeslagen als rijen binnen dat blok
- het voettekstgebied vertegenwoordigt de index van het blok waar roodgekleurde kleine rechthoeken zich in de gesorteerde volgorde van een bepaalde sleutel bevinden. Deze kleine blokjes zijn niets anders dan een soort wijzers die verwijzen naar offsets van de records.
Records worden in willekeurige volgorde op het schijfblok opgeslagen. Telkens wanneer nieuwe records worden toegevoegd, worden ze toegevoegd in de volgende beschikbare ruimte. Telkens wanneer een bestaand record wordt bijgewerkt, beslist het besturingssysteem of dat record nog steeds in dezelfde positie kan passen of dat er een nieuwe positie voor dat record moet worden toegewezen.
De positie van records wordt dus volledig afgehandeld door OS en er bestaat geen duidelijke relatie tussen de volgorde van twee records. Om de records in de logische volgorde van de sleutel op te halen, bevatten schijfpagina's een indexsectie in de voettekst, de index bevat een lijst met offset-wijzers in de volgorde van de sleutel. Elke keer dat een record wordt gewijzigd of aangemaakt, wordt de index aangepast.
Op deze manier hoeft u zich echt geen zorgen te maken over het daadwerkelijk ordenen van het fysieke record in een bepaalde volgorde, maar wordt een kleine indexsectie in die volgorde bijgehouden en wordt het ophalen of onderhouden van records heel eenvoudig.
Voordeel van geclusterde index:
Deze ordening of co-locatie van gerelateerde gegevens maakt een geclusterde index in feite sneller. Wanneer gegevens van schijf worden opgehaald, wordt het volledige blok met de gegevens door het systeem gelezen, aangezien ons schijf-IO-systeem gegevens in blokken schrijft en leest. Dus in het geval van bereikquery's is het heel goed mogelijk dat de gecolloceerde gegevens in het geheugen worden gebufferd. Stel dat u de volgende query uitvoert:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Een datablok wordt in het geheugen opgehaald wanneer de query wordt uitgevoerd. Stel dat het datablok phone_no . bevat in het bereik van 9010000000 naar 9030000000 . Dus welk bereik je ook hebt aangevraagd in de query is slechts een subset van de gegevens die in het blok aanwezig zijn. Als u nu de volgende zoekopdracht uitvoert om alle telefoonnummers in het bereik te krijgen, zeg dan van 9015000000 naar 9019000000 , hoeft u geen blokken meer van de schijf te halen. De volledige gegevens zijn te vinden in het huidige gegevensblok, dus clustered_index vermindert het aantal schijf-IO's door gerelateerde gegevens zoveel mogelijk in hetzelfde gegevensblok te plaatsen. Deze verminderde schijf-IO zorgt voor prestatieverbetering.
Dus als je een goed doordachte primaire sleutel hebt en je zoekopdrachten zijn gebaseerd op de primaire sleutel, zullen de prestaties supersnel zijn.
Beperkingen van geclusterde index:
Aangezien een geclusterde index de fysieke organisatie van de gegevens beïnvloedt, kan er slechts één geclusterde index per tabel zijn.
Relatie tussen primaire sleutel en geclusterde index:
U kunt niet handmatig een geclusterde index maken met InnoDB in MySQL. MySQL kiest het voor je uit. Maar hoe kiest het? De volgende fragmenten zijn afkomstig uit MySQL-documentatie:
Als je eenPRIMARY KEYdefinieert op uw tafel,InnoDBgebruikt het als de geclusterde index. Definieer een primaire sleutel voor elke tabel die u maakt. Als er geen logische unieke en niet-null kolom of reeks kolommen is, voegt u een nieuwe kolom voor automatisch verhogen toe, waarvan de waarden automatisch worden ingevuld.
Als u geenPRIMARY KEYdefinieert voor uw tafel lokaliseert MySQL de eersteUNIQUEindex waarbij alle sleutelkolommenNOT NULLzijn enInnoDBgebruikt het als de geclusterde index.
Als de tabel geenPRIMARY KEY. heeft of geschiktUNIQUEindex,InnoDBgenereert intern een verborgen geclusterde index genaamdGEN_CLUST_INDEXop een synthetische kolom met rij-ID-waarden. De rijen zijn gerangschikt op de ID dieInnoDBtoewijst aan de rijen in een dergelijke tabel. De rij-ID is een veld van 6 bytes dat monotoon toeneemt naarmate nieuwe rijen worden ingevoegd. De rijen die zijn geordend op de rij-ID staan dus fysiek in de volgorde van invoegen.
Kortom, de MySQL InnoDB-engine beheert de primaire index als geclusterde index voor het verbeteren van de prestaties, dus de primaire sleutel en het daadwerkelijke record op schijf worden samen geclusterd.
Structuur van primaire sleutel (geclusterd) Index:
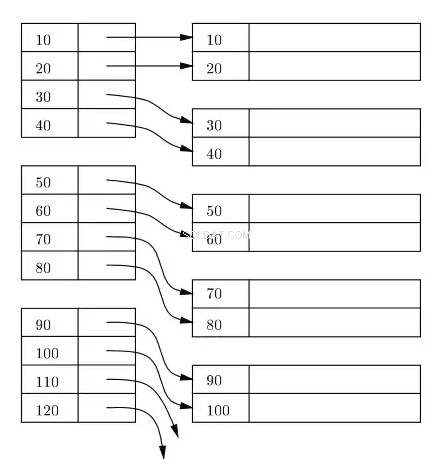
Een index wordt gewoonlijk bijgehouden als een B+ Tree op schijf en in het geheugen, en elke index wordt in blokken op schijf opgeslagen. Deze blokken worden indexblokken genoemd. De items in het indexblok zijn altijd gesorteerd op de index-/zoeksleutel. Het bladindexblok van de index bevat een rijzoeker. Voor de primaire index verwijst de rijzoeker naar het virtuele adres van de corresponderende fysieke locatie van de gegevensblokken op de schijf waar de rijen zich bevinden, gesorteerd volgens de indexsleutel.
In het volgende diagram vertegenwoordigen de rechthoeken aan de linkerkant de indexblokken op bladniveau en de rechthoeken aan de rechterkant de gegevensblokken. Logischerwijs lijken de gegevensblokken in een gesorteerde volgorde te zijn uitgelijnd, maar zoals eerder beschreven, kunnen de werkelijke fysieke locaties hier en daar verspreid zijn.
Is het mogelijk om een primaire index te maken op een niet-primaire sleutel?
In MySQL wordt automatisch een primaire index aangemaakt, en we hebben hierboven al beschreven hoe MySQL de primaire index kiest. Maar in de databasewereld is het eigenlijk niet nodig om een index op de primaire sleutelkolom te maken - de primaire index kan ook op elke niet-primaire sleutelkolom worden gemaakt. Maar wanneer gemaakt op de primaire sleutel, zijn alle sleutelitems uniek in de index, terwijl in het andere geval de primaire index ook een gedupliceerde sleutel kan hebben.
Is het mogelijk om een primaire sleutel te verwijderen?
Het is mogelijk om een primaire sleutel te verwijderen. Wanneer u een primaire sleutel verwijdert, gaan de gerelateerde geclusterde index en de uniciteitseigenschap van die kolom verloren.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Voordelen van de primaire index:
- Op zoek naar een op de primaire index gebaseerde bereikquery's zijn zeer efficiënt. Het is mogelijk dat het schijfblok dat de database van de schijf heeft gelezen alle gegevens bevat die bij de query horen, aangezien de primaire index is geclusterd en records fysiek zijn geordend. Dus de plaats van gegevens kan worden geleverd door de primaire index.
- Elke zoekopdracht die gebruikmaakt van de primaire sleutel is erg snel.
Nadelen van de primaire index:
- Aangezien de primaire index een directe verwijzing naar het datablokadres bevat via de virtuele adresruimte en schijfblokken fysiek zijn georganiseerd in de volgorde van de indexsleutel, elke keer dat het besturingssysteem een schijfpagina splitst vanwege
DMLbewerkingen zoalsINSERT/UPDATE/DELETE, moet ook de primaire index worden bijgewerkt. DusDMLoperaties legt enige druk op de prestaties van de primaire index.
Secundaire index:
Elke andere index dan een geclusterde index wordt een secundaire index genoemd. Secundaire indices hebben geen invloed op fysieke opslaglocaties, in tegenstelling tot primaire indices.
Wanneer heb je een secundaire index nodig?
Mogelijk hebt u verschillende gebruiksscenario's in uw toepassing waarbij u de database niet opvraagt met een primaire sleutel. In ons voorbeeld phone_no is de primaire sleutel, maar het kan zijn dat we de database moeten opvragen met pan_no , of name . In dergelijke gevallen heeft u secundaire indexen voor deze kolommen nodig als de frequentie van dergelijke zoekopdrachten erg hoog is.
Hoe maak je een secundaire index in MySQL?
De volgende opdracht maakt een secundaire index in de name kolom in de index_demo tafel.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Structuur van secundaire index:
In het onderstaande diagram vertegenwoordigen de roodgekleurde rechthoeken secundaire indexblokken. Secundaire index wordt ook bijgehouden in de B+ Tree en wordt gesorteerd volgens de sleutel waarop de index is gemaakt. De bladknooppunten bevatten een kopie van de sleutel van de corresponderende gegevens in de primaire index.
Om dit te begrijpen, kun je ervan uitgaan dat de secundaire index verwijst naar het adres van de primaire sleutel, hoewel dit niet het geval is. Als u gegevens ophaalt via de secundaire index, moet u twee B+-bomen doorkruisen — de ene is de secundaire index B+-boom zelf en de andere is de primaire index B+-boom.
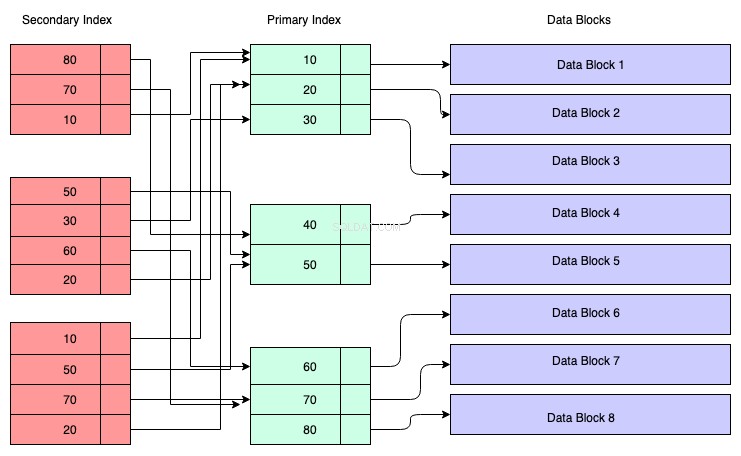
Voordelen van een secundaire index:
Logischerwijs kunt u zoveel secundaire indices maken als u wilt. Maar in werkelijkheid hoeveel indices er eigenlijk nodig zijn, moet serieus worden nagedacht, aangezien elke index zijn eigen straf heeft.
Nadelen van een secundaire index:
Met DML bewerkingen zoals DELETE / INSERT , moet de secundaire index ook worden bijgewerkt, zodat de kopie van de primaire sleutelkolom kan worden verwijderd / ingevoegd. In dergelijke gevallen kan het bestaan van veel secundaire indexen problemen veroorzaken.
Ook als een primaire sleutel erg groot is, zoals een URL , aangezien secundaire indexen een kopie van de kolomwaarde van de primaire sleutel bevatten, kan deze inefficiënt zijn in termen van opslag. Meer secundaire sleutels betekent een groter aantal dubbele kopieën van de kolomwaarde van de primaire sleutel, dus meer opslagruimte in het geval van een grote primaire sleutel. Ook de primaire sleutel zelf slaat de sleutels op, dus het gecombineerde effect op de opslag zal erg hoog zijn.
Overweging voordat u een primaire index verwijdert:
In MySQL kunt u een primaire index verwijderen door de primaire sleutel te verwijderen. We hebben al gezien dat een secundaire index afhankelijk is van een primaire index. Dus als u een primaire index verwijdert, moeten alle secundaire indices worden bijgewerkt om een kopie van de nieuwe primaire indexsleutel te bevatten die MySQL automatisch aanpast.
Dit proces is duur wanneer er meerdere secundaire indexen bestaan. Ook andere tabellen kunnen een refererende-sleutelverwijzing naar de primaire sleutel hebben, dus u moet die refererende-sleutelverwijzingen verwijderen voordat u de primaire sleutel verwijdert.
Wanneer een primaire sleutel wordt verwijderd, maakt MySQL automatisch intern een andere primaire sleutel aan, en dat is een kostbare operatie.
UNIEKE sleutelindex:
Net als primaire sleutels kunnen unieke sleutels ook records op unieke wijze identificeren met één verschil:de unieke sleutelkolom kan null bevatten waarden.
In tegenstelling tot andere databaseservers, kan een unieke sleutelkolom in MySQL zoveel null . hebben waarden mogelijk te maken. In SQL-standaard, null betekent een ongedefinieerde waarde. Dus als MySQL maar één null . hoeft te bevatten waarde in een unieke sleutelkolom, moet het ervan uitgaan dat alle null-waarden hetzelfde zijn.
Maar logischerwijs is dit niet correct aangezien null betekent ongedefinieerd — en ongedefinieerde waarden kunnen niet met elkaar worden vergeleken, het is de aard van null . Omdat MySQL niet kan bevestigen als alle null s hetzelfde betekenen, het staat meerdere null . toe waarden in de kolom.
De volgende opdracht laat zien hoe u een unieke sleutelindex in MySQL maakt:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Samengestelde index:
Met MySQL kunt u indices definiëren op meerdere kolommen, tot wel 16 kolommen. Deze index wordt een Multi-column / Composite / Compound index genoemd.
Laten we zeggen dat we een index hebben gedefinieerd op 4 kolommen — col1 , col2 , col3 , col4 . Met een samengestelde index hebben we zoekmogelijkheden op col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . We kunnen dus elk voorvoegsel aan de linkerkant van de geïndexeerde kolommen gebruiken, maar we kunnen geen kolom uit het midden weglaten en die gebruiken zoals - (col1, col3) of (col1, col2, col4) of col3 of col4 etc. Dit zijn ongeldige combinaties.
De volgende commando's creëren 2 samengestelde indexen in onze tabel:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Als u vragen heeft met een WHERE clausule op meerdere kolommen, schrijf de clausule in de volgorde van de kolommen van de samengestelde index. De index zal die zoekopdracht ten goede komen. Terwijl u de kolommen voor een samengestelde index bepaalt, kunt u zelfs verschillende gebruiksscenario's van uw systeem analyseren en proberen de volgorde van kolommen te bedenken die de meeste van uw gebruiksscenario's ten goede komen.
Samengestelde indices kunnen u helpen bij JOIN &SELECT ook vragen. Voorbeeld:in het volgende SELECT * zoekopdracht, composite_index_2 wordt gebruikt.

Als er meerdere indexen zijn gedefinieerd, kiest de MySQL-query-optimizer die index die het grootste aantal rijen elimineert of zo min mogelijk rijen scant voor een betere efficiëntie.
Waarom gebruiken we samengestelde indices ? Waarom definiëren we niet meerdere secundaire indices voor de kolommen waarin we geïnteresseerd zijn?
MySQL gebruikt slechts één index per tabel per zoekopdracht, behalve UNION. (In een UNION wordt elke logische query afzonderlijk uitgevoerd en worden de resultaten samengevoegd.) Het definiëren van meerdere indices op meerdere kolommen garandeert dus niet dat die indices worden gebruikt, zelfs als ze deel uitmaken van de query.
MySQL houdt iets bij dat indexstatistieken wordt genoemd en waarmee MySQL kan afleiden hoe de gegevens er in het systeem uitzien. Indexstatistieken zijn echter een generalisatie, maar op basis van deze metagegevens beslist MySQL welke index geschikt is voor de huidige zoekopdracht.
Hoe werkt een samengestelde index?
De kolommen die in samengestelde indices worden gebruikt, worden aan elkaar gekoppeld en die aaneengeschakelde sleutels worden in gesorteerde volgorde opgeslagen met behulp van een B+ Tree. Wanneer u een zoekopdracht uitvoert, wordt de aaneenschakeling van uw zoeksleutels vergeleken met die van de samengestelde index. Als er dan een mismatch is tussen de volgorde van uw zoeksleutels en de volgorde van de samengestelde indexkolommen, kan de index niet worden gebruikt.
In ons voorbeeld wordt voor de volgende record een samengestelde indexsleutel gevormd door pan_no samen te voegen , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Hoe te identificeren of u een samengestelde index nodig heeft:
- Analyseer eerst uw zoekopdrachten op basis van uw gebruiksscenario's. Als u ziet dat bepaalde velden in veel zoekopdrachten samen voorkomen, kunt u overwegen een samengestelde index te maken.
- Als u een index maakt in
col1&een samengestelde index in (col1,col2), dan zou alleen de samengestelde index in orde moeten zijn.col1alleen kan worden bediend door de samengestelde index zelf, omdat het een voorvoegsel aan de linkerkant van de index is. - Overweeg kardinaliteit. Als kolommen die in de samengestelde index worden gebruikt uiteindelijk samen een hoge kardinaliteit hebben, zijn ze een goede kandidaat voor de samengestelde index.
Dekkingsindex:
Een dekkingsindex is een speciaal soort samengestelde index waarbij alle kolommen die in de query zijn gespecificeerd ergens in de index voorkomen. De query-optimizer hoeft dus niet de database te raken om de gegevens te krijgen, maar haalt het resultaat uit de index zelf. Voorbeeld:we hebben al een samengestelde index gedefinieerd op (pan_no, name, age) , dus overweeg nu de volgende vraag:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
De kolommen vermeld in de SELECT &WHERE clausules maken deel uit van de samengestelde index. In dit geval kunnen we dus daadwerkelijk de waarde van de age . krijgen kolom uit de samengestelde index zelf. Laten we eens kijken wat de EXPLAIN commando toont voor deze zoekopdracht:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';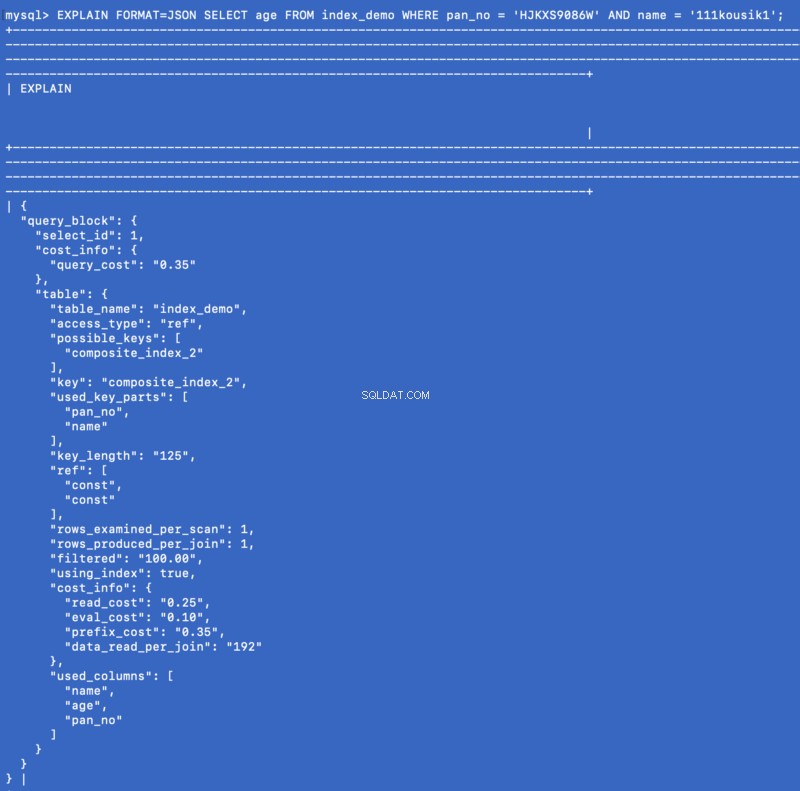
Merk in het bovenstaande antwoord op dat er een sleutel is — using_index die is ingesteld op true wat betekent dat de dekkingsindex is gebruikt om de vraag te beantwoorden.
Ik weet niet hoeveel dekkende indices worden gewaardeerd in productieomgevingen, maar het lijkt een goede optimalisatie te zijn voor het geval de zoekopdracht voldoet.
Gedeeltelijke index:
We weten al dat indexen onze zoekopdrachten versnellen ten koste van ruimte. Hoe meer indexen u heeft, hoe meer opslagvereisten. We hebben al een index gemaakt met de naam secondary_idx_1 in de kolom name . De kolom name kan grote waarden van elke lengte bevatten. Ook in de index hebben de metadata van de rijzoekers of rijaanwijzers hun eigen grootte. Dus over het algemeen kan een index een hoge opslag- en geheugenbelasting hebben.
In MySQL is het ook mogelijk om een index te maken op de eerste paar bytes aan gegevens. Voorbeeld:het volgende commando maakt een index aan op de eerste 4 bytes van de naam. Hoewel deze methode de geheugenoverhead met een bepaalde hoeveelheid vermindert, kan de index niet veel rijen elimineren, aangezien in dit voorbeeld de eerste 4 bytes gemeenschappelijk kunnen zijn voor veel namen. Gewoonlijk wordt dit soort prefix-indexering ondersteund op CHAR ,VARCHAR , BINARY , VARBINARY type kolommen.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Wat gebeurt er onder de motorkap als we een index definiëren?
Laten we de SHOW EXTENDED . uitvoeren commando opnieuw:
SHOW EXTENDED INDEXES FROM index_demo;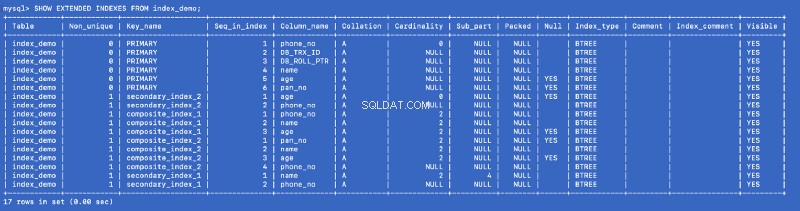
We hebben secondary_index_1 defined gedefinieerd op name , maar MySQL heeft een samengestelde index gemaakt op (name , phone_no ) waar phone_no is de primaire sleutelkolom. We hebben secondary_index_2 . gemaakt op age &MySQL heeft een samengestelde index gemaakt op (age , phone_no ). We hebben composite_index_2 gemaakt op (pan_no , name , age ) &MySQL heeft een samengestelde index gemaakt op (pan_no , name , age , phone_no ). De samengestelde index composite_index_1 heeft al phone_no als onderdeel ervan.
Dus welke index we ook maken, MySQL op de achtergrond creëert een samengestelde backing-index die op zijn beurt naar de primaire sleutel verwijst. Dit betekent dat de primaire sleutel een eersteklas burger is in de MySQL-indexeringswereld. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html