U kunt gegevens uit een CSV-bestand (Comma Separated Values) importeren in een Neo4j-database. Gebruik hiervoor de LOAD CSV clausule.
Door CSV-bestanden in Neo4j te kunnen laden, is het gemakkelijk om gegevens uit een ander databasemodel te importeren (bijvoorbeeld een relationele database).
Met Neo4j kunt u CSV-bestanden laden vanaf een lokale of externe URL.
Om toegang te krijgen tot een bestand dat lokaal is opgeslagen (op de databaseserver), gebruikt u een file:/// URL. Anders kunt u externe bestanden importeren met elk van de HTTPS-, HTTP- en FTP-protocollen.
Een CSV-bestand laden
Laten we een CSV-bestand laden met de naam genres.csv met behulp van het HTTP-protocol. Het is geen groot bestand — het bevat een lijst van 115 muziekgenres, dus het zal 115 nodes (en 230 eigenschappen) creëren.
Dit bestand is opgeslagen op Quackit.com, dus u kunt deze code uitvoeren vanuit uw Neo4j-browser en het zou rechtstreeks in uw database moeten worden geïmporteerd (ervan uitgaande dat u verbonden bent met internet).
Je kunt het bestand ook hier downloaden:genres.csv
LOAD CSV FROM 'https://www.quackit.com/neo4j/tutorial/genres.csv' AS line
CREATE (:Genre { GenreId: line[0], Name: line[1]})
Indien nodig kunt u bepaalde velden uit het CSV-bestand weglaten. Als u bijvoorbeeld niet wilt dat het eerste veld in de database wordt geïmporteerd, kunt u eenvoudig GenreId: line[0], weglaten van de bovenstaande code.
Het uitvoeren van de bovenstaande instructie zou het volgende succesbericht moeten opleveren:
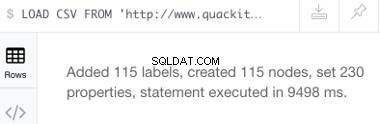
U kunt dat opvolgen met een vraag om de nieuw gemaakte knooppunten te zien:
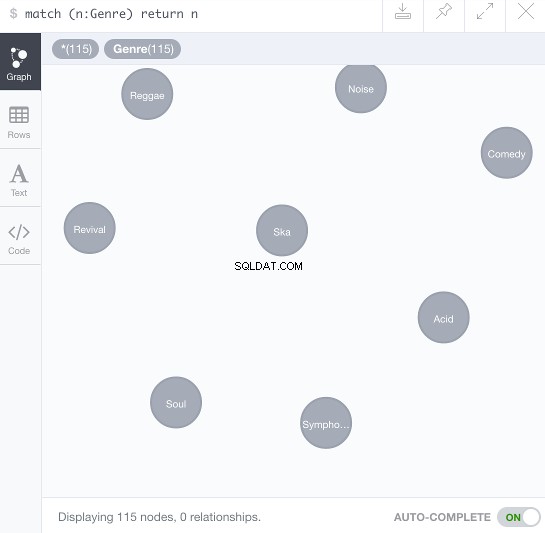
MATCH (n:Genre) RETURN n
Wat zou moeten resulteren in de knooppunten verspreid over het datavisualisatieframe:
Importeer een CSV-bestand met Headers
Het vorige CSV-bestand bevatte geen headers. Als het CSV-bestand headers bevat, kunt u WITH HEADERS . gebruiken .
Als u deze methode gebruikt, kunt u ook naar elk veld verwijzen met hun kolom-/kopnaam.
We hebben nog een CSV-bestand, dit keer met headers. Dit bestand bevat een lijst met albumtracks.
Nogmaals, dit is geen groot bestand — het bevat een lijst van 32 tracks, dus het zal 32 nodes (en 96 eigenschappen) creëren.
Dit bestand is ook opgeslagen op Quackit.com, dus u kunt deze code uitvoeren vanuit uw Neo4j-browser en het zou rechtstreeks in uw database moeten worden geïmporteerd (ervan uitgaande dat u verbonden bent met internet).
U kunt het bestand ook hier downloaden:tracks.csv
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Dit zou het volgende succesbericht moeten opleveren:
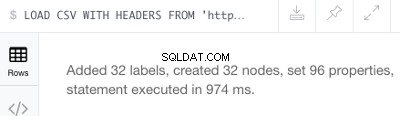
Gevolgd door een vraag om de nieuw gemaakte knooppunten te bekijken:
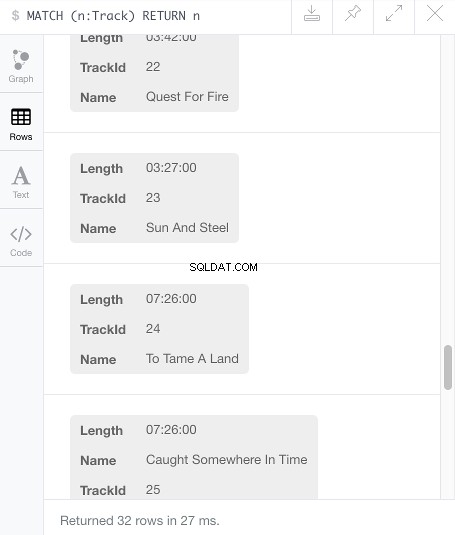
MATCH (n:Track) RETURN n
Wat zou moeten resulteren in de nieuwe knooppunten verspreid over het gegevensvisualisatieframe.
Klik op de Rijen icoon om elk knooppunt en zijn drie eigenschappen te zien:
Aangepast scheidingsteken voor velden
U kunt indien nodig een aangepast veldscheidingsteken opgeven. U kunt bijvoorbeeld een puntkomma opgeven in plaats van een komma als het CSV-bestand zo is opgemaakt.
Om dit te doen, voegt u gewoon de FIELDTERMINATOR . toe clausule bij de verklaring. Zoals dit:
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line FIELDTERMINATOR ';'
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Grote bestanden importeren
Als je een bestand met veel gegevens gaat importeren, moet de PERODIC COMMIT clausule kan handig zijn.
PERIODIC COMMIT gebruiken instrueert Neo4j om de gegevens na een bepaald aantal rijen vast te leggen. Dit vermindert de geheugenoverhead van de transactiestatus.
De standaard is 1000 rijen, dus de gegevens worden elke duizend rijen vastgelegd.
Om PERIODIC COMMIT te gebruiken plaats gewoon USING PERIODIC COMMIT aan het begin van de instructie (vóór LOAD CSV )
Hier is een voorbeeld:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) De snelheid van periodieke vastleggingen instellen
U kunt het tarief ook wijzigen van standaard 1000 rijen naar een ander getal. Voeg eenvoudig het nummer toe na USING PERIODIC COMMIT :
Zoals dit:
USING PERIODIC COMMIT 800
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) CSV-indeling/vereisten
Hier is wat informatie over hoe het CSV-bestand moet worden opgemaakt bij gebruik van LOAD CSV :
- De tekencodering moet UTF-8 zijn.
- De eindlijnafsluiting is systeemafhankelijk, bijvoorbeeld
\nop Unix of\r\nop Windows. - De terminator moet een komma zijn
,tenzij anders aangegeven met behulp van deFIELDTERMINATORoptie. - Het teken voor aanhalingstekens is het dubbele aanhalingsteken
"(deze worden verwijderd wanneer de gegevens worden ingelezen). - Alle tekens die moeten worden ontsnapt, kunnen worden ontsnapt met de backslash
\karakter. LOAD CSVondersteunt bronnen die zijn gecomprimeerd met gzip, Deflate en ZIP-archieven.