Bouw een hoge beschikbaarheid, stap voor stap
Als het gaat om database-infrastructuur, willen we dat allemaal. We streven er allemaal naar om een zeer beschikbare opstelling te bouwen. Redundantie is het sleutelwoord. We beginnen met het implementeren van redundantie op het laagste niveau en gaan verder op de stapel. Het begint met hardware - redundante voedingen, redundante koeling, hot-swap schijven. Netwerklaag - meerdere NIC's aan elkaar verbonden en verbonden met verschillende switches die redundante routers gebruiken. Voor opslag gebruiken we schijven die zijn ingesteld in RAID, wat betere prestaties maar ook redundantie geeft. Vervolgens gebruiken we op softwareniveau clustertechnologieën:meerdere databaseknooppunten die samenwerken om redundantie te implementeren:MySQL-cluster, Galera-cluster.
Dit alles is niet goed als je alles in één datacenter hebt:wanneer een datacenter uitvalt, of een deel van de (maar belangrijke) services offline gaat, of zelfs als je de verbinding met het datacenter verliest, zal je service uitvallen - ongeacht de hoeveelheid redundantie in de lagere niveaus. En ja, die dingen gebeuren.
- Verstoring van de S3-service heeft in februari 2017 grote schade aangericht in de regio VS-Oost-1
- EC2- en RDS-servicestoring in de regio VS-oost in april 2011
- EC2, EBS en RDS werden in augustus 2011 verstoord in de regio EU-West
- Stroomuitval bracht Rackspace Texas DC in juni 2009 onderuit
- UPS-storing zorgde ervoor dat honderden servers in januari 2010 offline gingen in Rackspace London DC
Dit is geenszins een volledige lijst met fouten, het is slechts het resultaat van een snelle Google-zoekopdracht. Deze dienen als voorbeelden dat er dingen mis kunnen en gaan als je al je eieren in dezelfde mand legt. Een ander voorbeeld zou orkaan Sandy zijn, die een enorme uittocht van gegevens van VS-Oost naar VS-West DC's veroorzaakte - in die tijd kon je nauwelijks instanties in US-West op gang brengen, omdat iedereen zich haastte om hun infrastructuur naar de andere kust te verplaatsen in afwachting dat Noord-Virginia DC ernstig zal worden beïnvloed door het weer.
Opstellingen met meerdere datacenters zijn dus een must als u een omgeving met hoge beschikbaarheid wilt bouwen. In deze blogpost bespreken we hoe je een dergelijke infrastructuur kunt bouwen met Galera Cluster for MySQL/MariaDB.
Galera-concepten
Laten we, voordat we naar bepaalde oplossingen kijken, wat tijd besteden aan het uitleggen van twee concepten die erg belangrijk zijn in zeer beschikbare, multi-DC Galera-opstellingen.
Quorum
Hoge Beschik baarheid vereist resources - u hebt namelijk een aantal knoop punten in het cluster nodig om het maximaal beschikbaar te maken. Een cluster kan het verlies van enkele van zijn leden tolereren, maar slechts tot op zekere hoogte. Voorbij een bepaald percentage mislukkingen, zou je kunnen kijken naar een split-brain-scenario.
Laten we een voorbeeld nemen met een opstelling met 2 knooppunten. Als een van de knooppunten uitvalt, hoe kan de andere dan weten dat zijn peer is gecrasht en dat het geen netwerkstoring is? In dat geval kan het andere knooppunt net zo goed actief zijn en verkeer bedienen. Er is geen goede manier om zo'n geval aan te pakken... Daarom begint fouttolerantie meestal vanaf drie knooppunten. Galera gebruikt een quorumberekening om te bepalen of het veilig is voor het cluster om verkeer af te handelen, of dat het zijn activiteiten moet staken. Na een storing proberen alle resterende knooppunten verbinding met elkaar te maken en te bepalen hoeveel er in de lucht zijn. Het wordt dan vergeleken met de vorige status van het cluster, en zolang meer dan 50% van de nodes actief is, kan het cluster blijven werken.
Dit resulteert in het volgende:
Cluster met 2 knooppunten - geen fouttolerantie
Cluster met 3 knooppunten - tot 1 crash
Cluster met 4 knooppunten - tot 1 crash (als twee knooppunten zouden crashen, slechts 50% van het cluster beschikbaar zou zijn, heb je meer dan 50% nodes nodig om te overleven)
Cluster met 5 nodes - tot 2 crashes
Cluster met 6 nodes - tot 2 crashes
U ziet waarschijnlijk het patroon - u wilt dat uw cluster een oneven aantal knooppunten heeft - in termen van hoge beschikbaarheid heeft het geen zin om van 5 naar 6 knooppunten in het cluster te gaan. Als je een betere fouttolerantie wilt, moet je voor 7 nodes gaan.
Segmenten
Doorgaans volgt in een Galera-cluster alle communicatie het all-to-all-patroon. Elk knooppunt praat met alle andere knooppunten in het cluster.
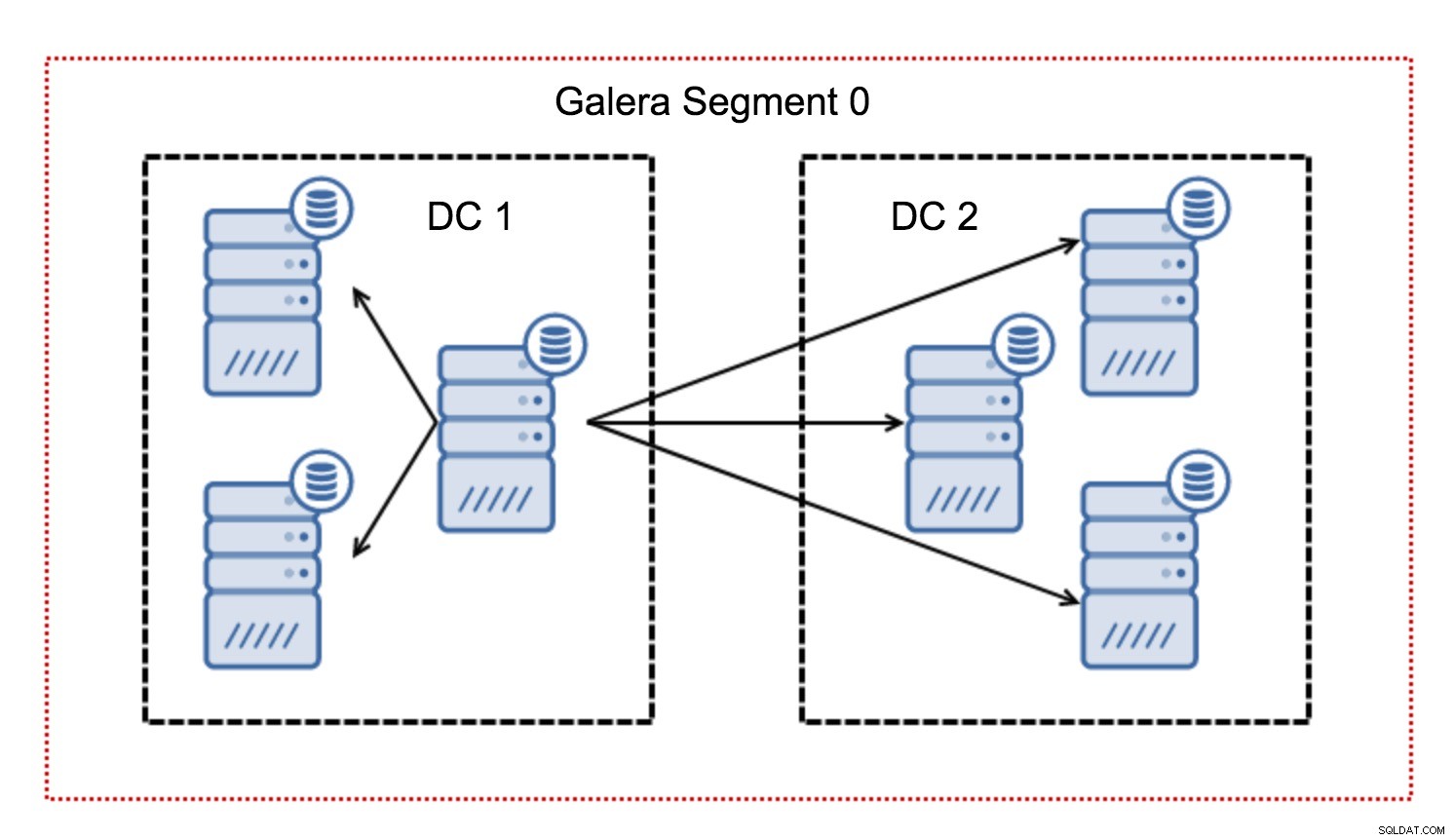
Zoals u wellicht weet, moet elke schrijfset in Galera worden gecertificeerd door alle knooppunten in het cluster - daarom moet elke schrijfactie op een knooppunt worden overgedragen naar alle knooppunten in het cluster. Dit werkt prima in een omgeving met lage latentie. Maar als we het hebben over multi-DC-configuraties, moeten we rekening houden met een veel hogere latentie dan in een lokaal netwerk. Om het draaglijker te maken in clusters die zich uitstrekken over Wide Area Networks, heeft Galera segmenten geïntroduceerd.
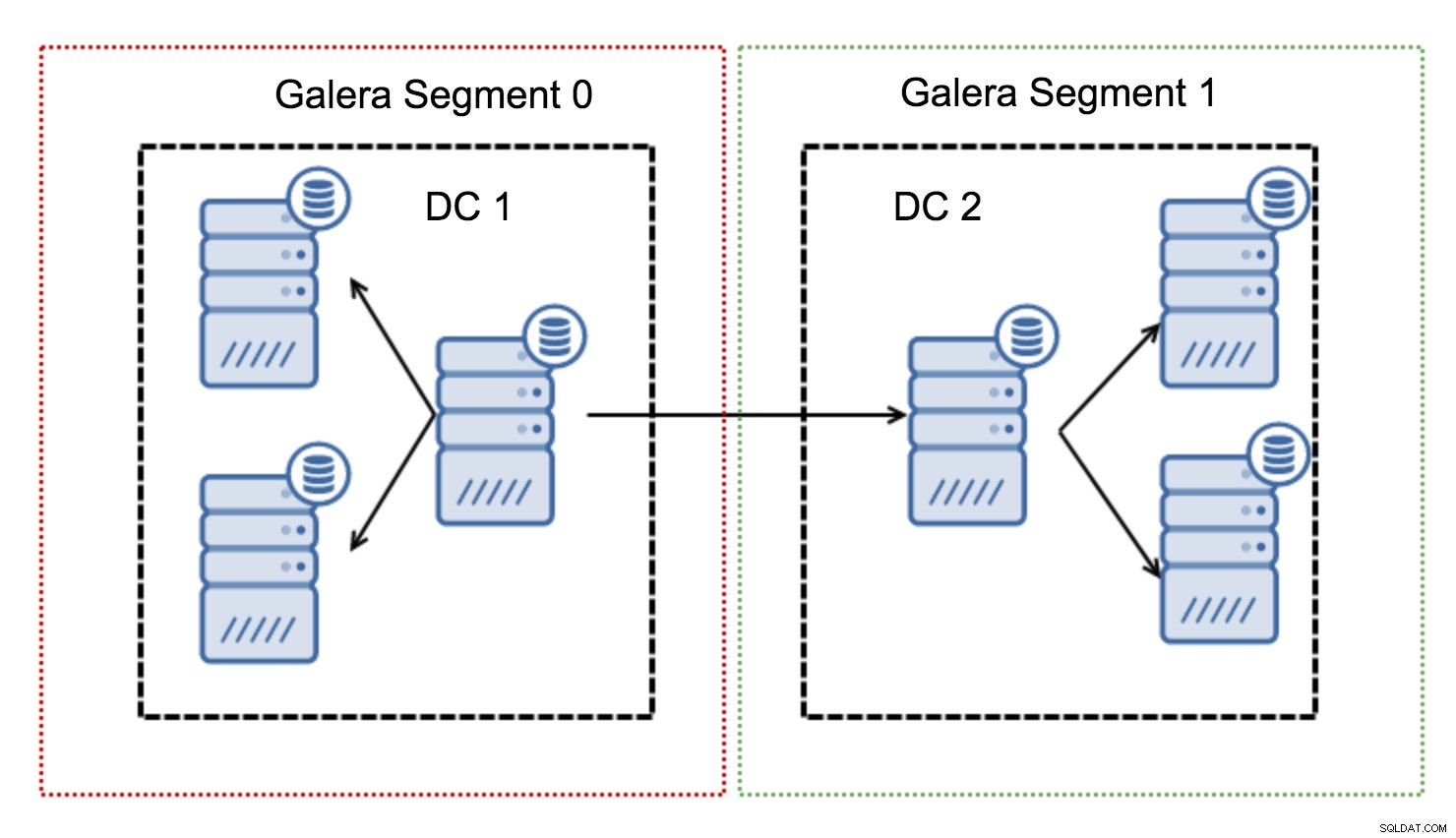
Ze werken door het Galera-verkeer binnen een groep knooppunten (segment) te houden. Alle knooppunten binnen een enkel segment gedragen zich alsof ze zich in een lokaal netwerk bevinden - ze gaan uit van één voor alle communicatie. Voor cross-segment verkeer zijn de zaken anders - in elk van de segmenten wordt één "relay" node gekozen, al het cross-segment verkeer gaat via die nodes. Wanneer een relaisknooppunt uitvalt, wordt een ander knooppunt gekozen. Dit vermindert de latentie niet veel - de WAN-latentie blijft immers hetzelfde, ongeacht of u verbinding maakt met één externe host of met meerdere externe hosts, maar aangezien WAN-links doorgaans beperkt zijn in bandbreedte en er mogelijk een kosten in rekening brengen voor de hoeveelheid overgedragen gegevens, kunt u met een dergelijke aanpak de hoeveelheid gegevens die tussen segmenten wordt uitgewisseld, beperken. Een andere tijd- en kostenbesparende optie is het feit dat knooppunten in hetzelfde segment prioriteit krijgen wanneer een donor nodig is - nogmaals, dit beperkt de hoeveelheid gegevens die via het WAN wordt overgedragen en, hoogstwaarschijnlijk, versnelt SST als een lokaal netwerk bijna altijd zal sneller zijn dan een WAN-link.
Nu we een aantal van deze concepten uit de weg hebben geruimd, gaan we eens kijken naar enkele andere belangrijke aspecten van multi-DC-opstellingen voor Galera-cluster.
Problemen waarmee u te maken krijgt
Wanneer u werkt in omgevingen die zich uitstrekken over WAN, zijn er een aantal zaken waarmee u rekening moet houden bij het ontwerpen van uw omgeving.
Quorumberekening
In de vorige sectie hebben we beschreven hoe een quorumberekening eruitziet in Galera-cluster - kortom, u wilt een oneven aantal knooppunten hebben om de overlevingskansen te maximaliseren. Dat is allemaal nog steeds het geval in multi-DC-opstellingen, maar er worden nog wat meer elementen aan de mix toegevoegd. Allereerst moet u beslissen of u wilt dat Galera een datacenterstoring automatisch afhandelt. Dit bepaalt hoeveel datacenters u gaat gebruiken. Laten we ons twee DC's voorstellen - als u uw knooppunten 50% - 50% splitst, als een datacenter uitvalt, heeft het tweede geen 50% + 1 knooppunten om zijn "primaire" toestand te behouden. Als u uw nodes op een ongelijke manier opsplitst, en de meerderheid ervan in het "hoofd" datacenter gebruikt, en wanneer dat datacenter uitvalt, zal de "back-up" DC geen 50% + 1 nodes hebben om een quorum te vormen. U kunt verschillende gewichten toewijzen aan knooppunten, maar het resultaat zal precies hetzelfde zijn - er is geen manier om automatisch een failover tussen twee DC's uit te voeren zonder handmatige tussenkomst. Om geautomatiseerde failover te implementeren, hebt u meer dan twee DC's nodig. Nogmaals, idealiter een oneven aantal - drie datacenters is een prima opzet. Vervolgens is de vraag:hoeveel knooppunten u moet hebben? Je wilt ze gelijk verdeeld hebben over de datacenters. De rest is gewoon een kwestie van hoeveel mislukte nodes je setup moet verwerken.
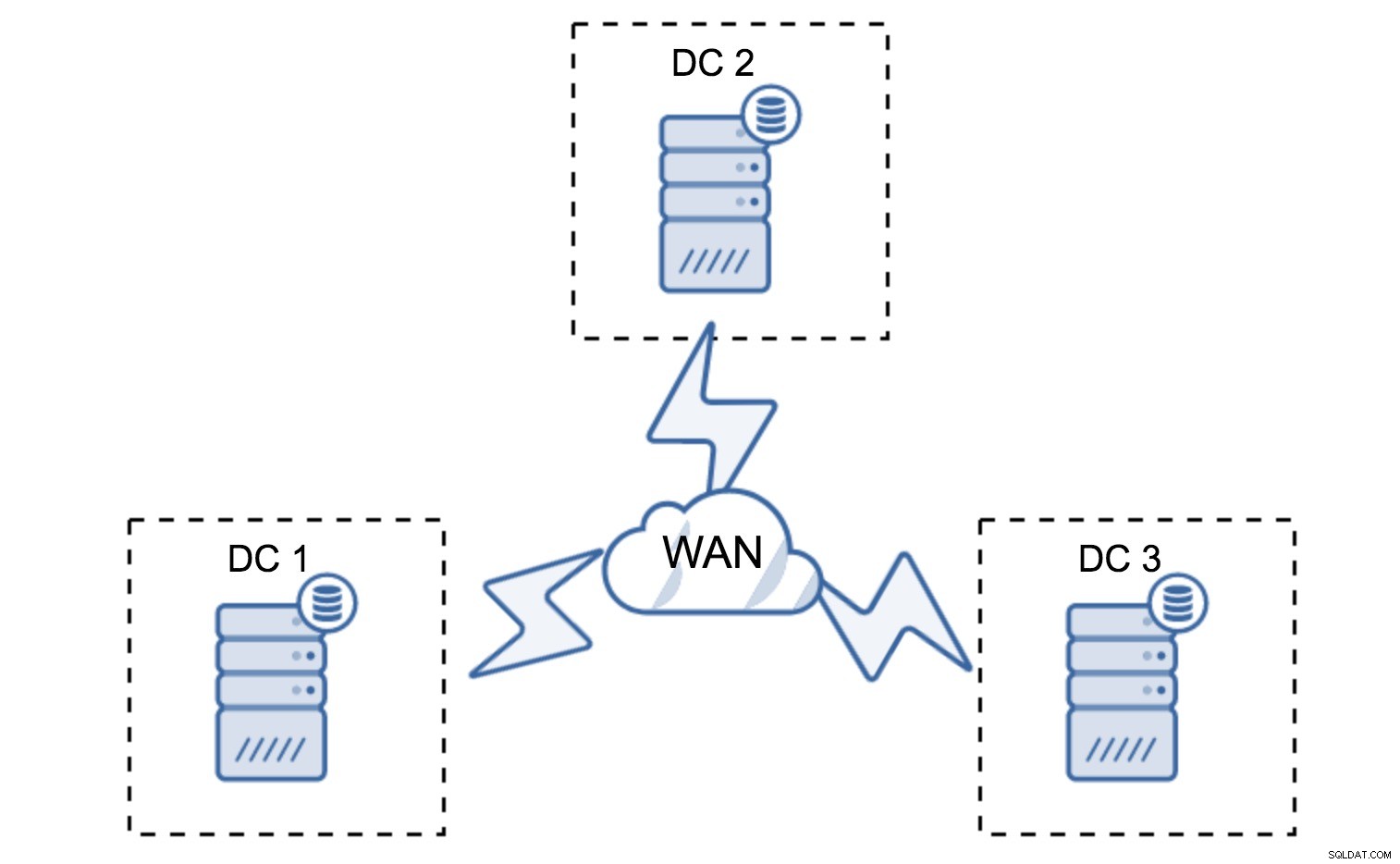
Minimale setup zal één node per datacenter gebruiken - het heeft echter ernstige nadelen. Voor elke statusoverdracht moeten gegevens over het WAN worden verplaatst en dit resulteert in een langere tijd die nodig is om SST te voltooien of hogere kosten.
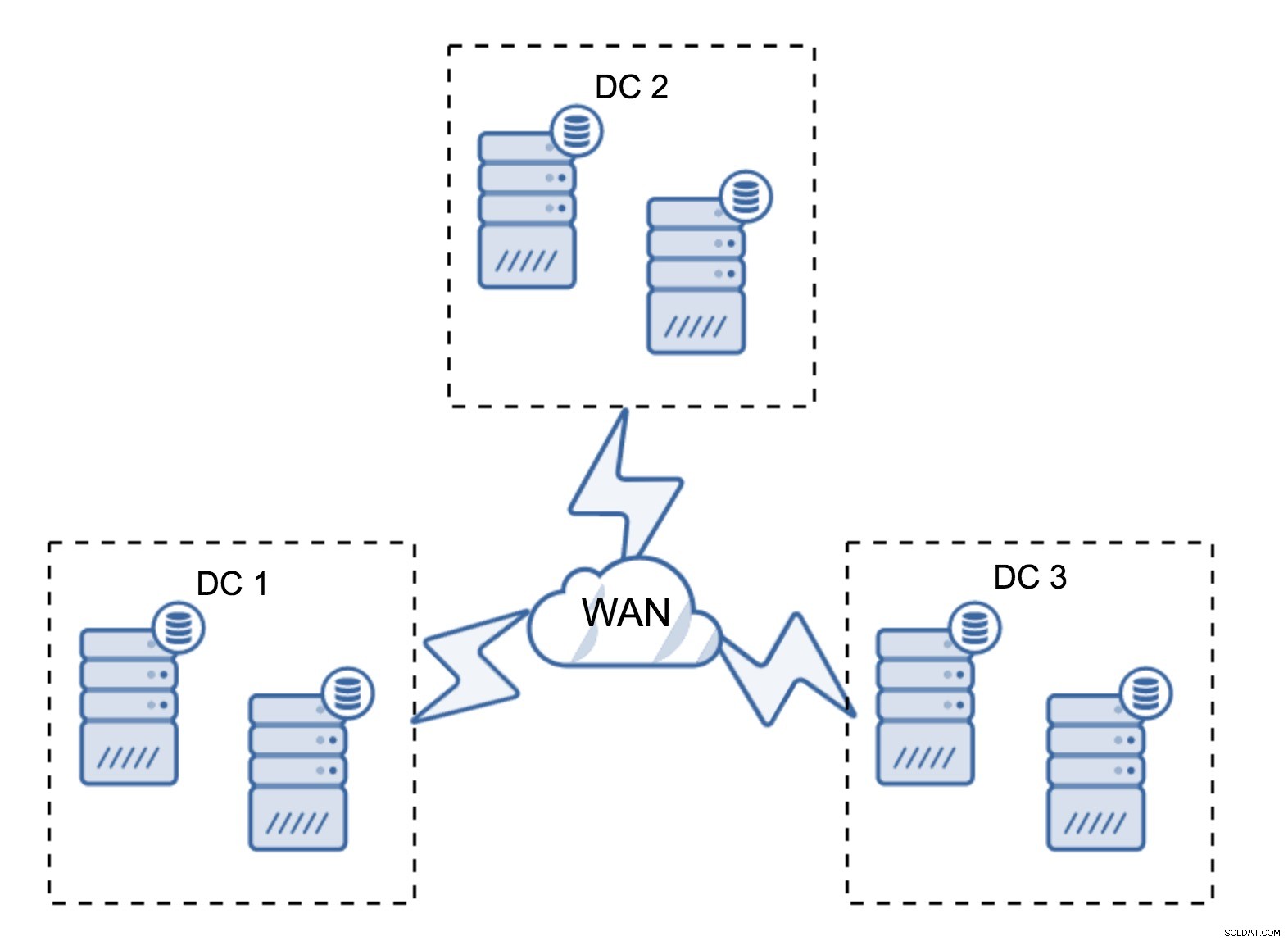
Een vrij typische opstelling is om zes nodes te hebben, twee per datacenter. Deze opstelling lijkt onverwacht omdat deze een even aantal knooppunten heeft. Maar als je erover nadenkt, is het misschien niet zo'n groot probleem:het is vrij onwaarschijnlijk dat drie knooppunten tegelijk uitvallen, en een dergelijke opstelling zal een crash van maximaal twee knooppunten overleven. Een heel datacenter kan offline gaan en twee resterende DC's zullen hun activiteiten voortzetten. Het heeft ook een enorm voordeel ten opzichte van de minimale setup:wanneer een node offline gaat, is er altijd een tweede node in het datacenter die als donor kan dienen. Meestal wordt het WAN niet gebruikt voor SST.
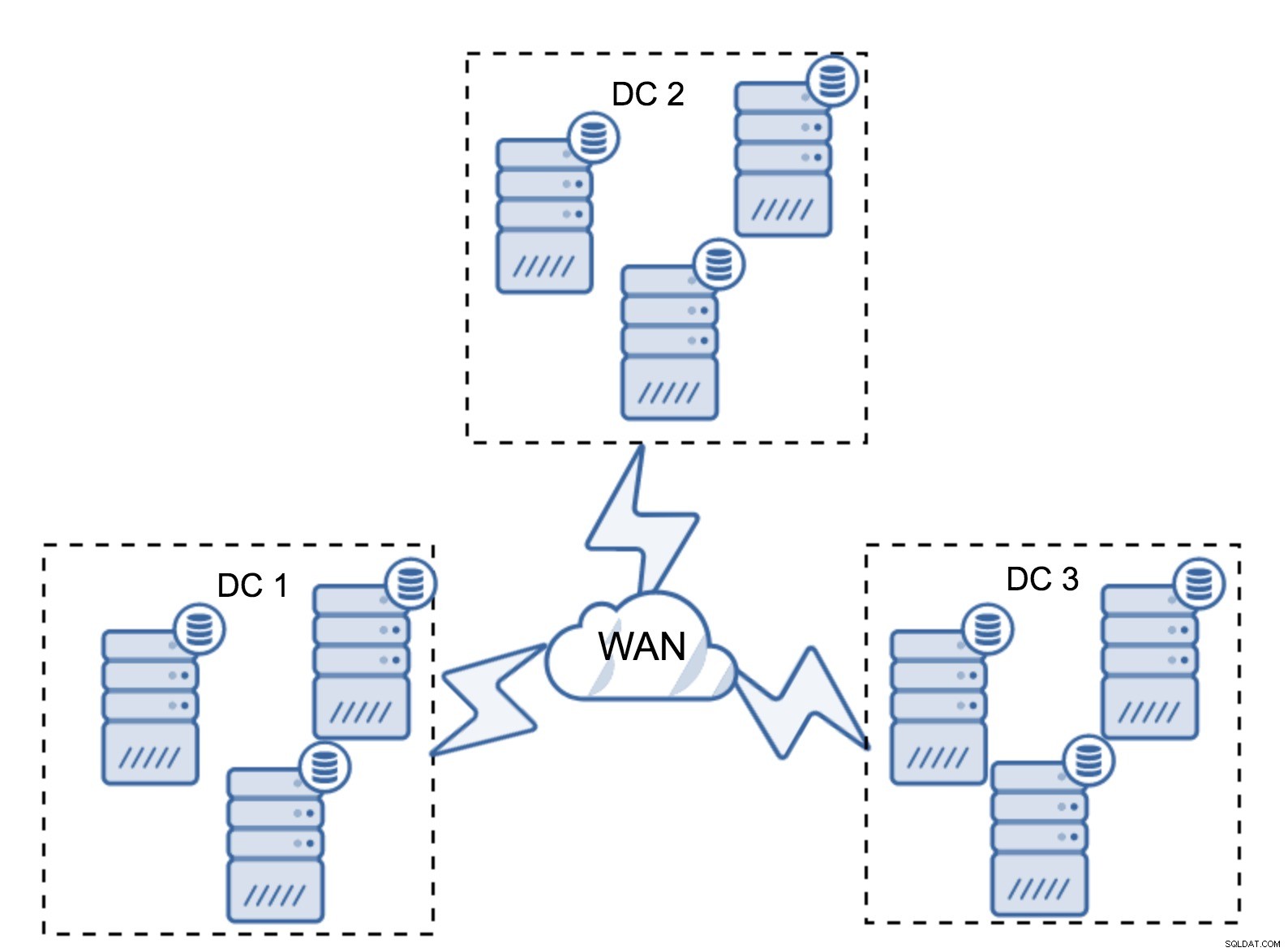
Natuurlijk kunt u het aantal nodes verhogen tot drie per cluster, negen in totaal. Dit geeft je een nog betere overlevingskans:maximaal vier nodes kunnen crashen en het cluster zal nog steeds overleven. Aan de andere kant moet je er rekening mee houden dat, zelfs met het gebruik van segmenten, meer nodes een hogere overhead van bewerkingen betekenen en dat je Galera-cluster slechts tot op zekere hoogte kunt uitschalen.
Het kan voorkomen dat er geen derde datacenter nodig is omdat uw applicatie zich bijvoorbeeld in slechts twee daarvan bevindt. Natuurlijk is de vereiste van drie datacenters nog steeds geldig, dus je zult er niet omheen gaan, maar het is prima om een Galera Arbitrator (garbd) te gebruiken in plaats van volledig geladen databaseservers.
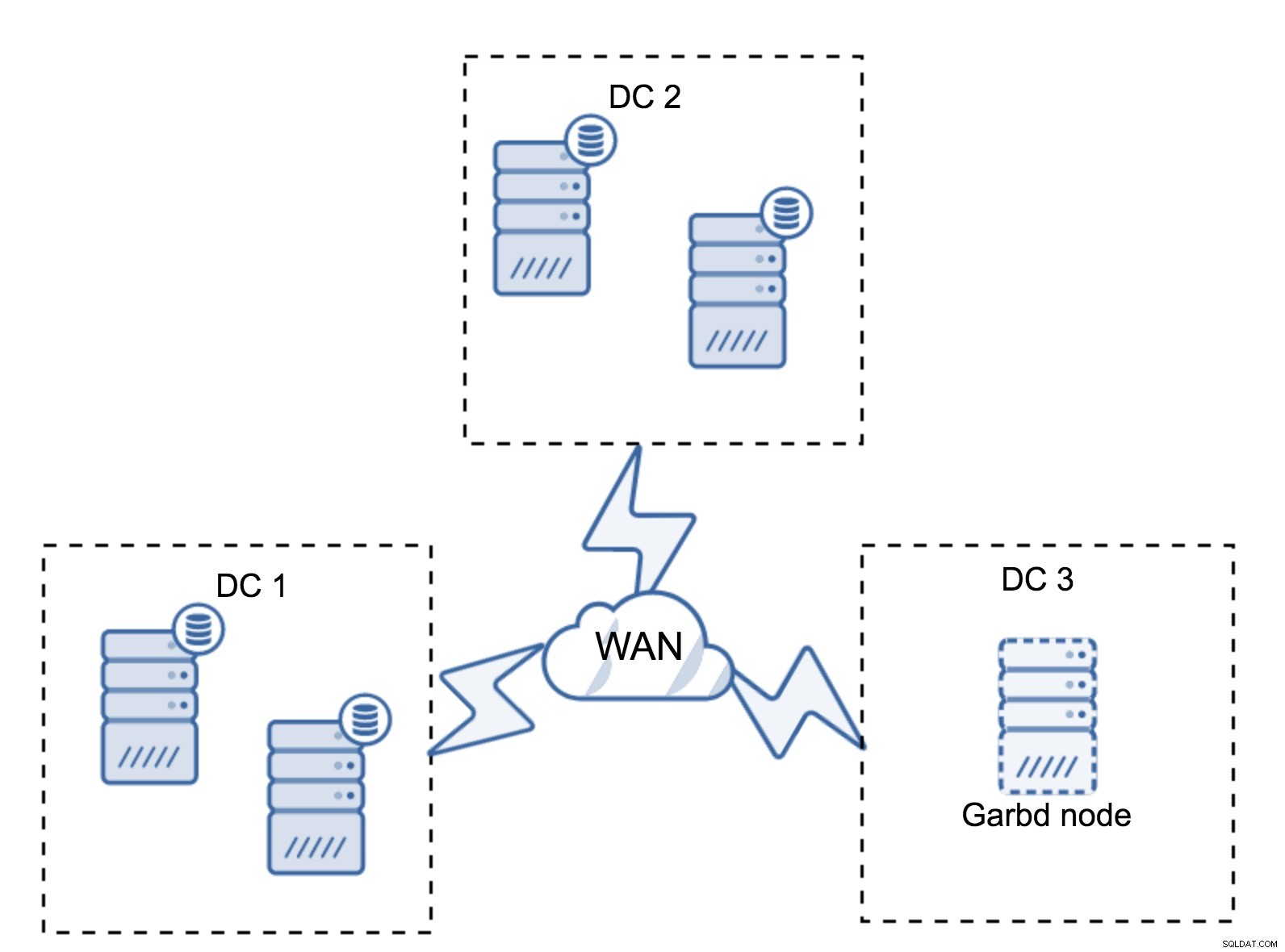
Garbd kan op kleinere knooppunten worden geïnstalleerd, zelfs op virtuele servers. Het vereist geen krachtige hardware, het slaat geen gegevens op en past geen schrijfsets toe. Maar het ziet wel al het replicatieverkeer en neemt deel aan de quorumberekening. Dankzij dit kun je setups implementeren zoals vier knooppunten, twee per DC + garbd in de derde - je hebt in totaal vijf knooppunten en zo'n cluster kan maximaal twee fouten accepteren. Het betekent dus dat het een volledige afsluiting van een van de datacenters kan accepteren.
Welke optie is beter voor jou? Er is niet voor alle gevallen de beste oplossing, het hangt allemaal af van uw infrastructuurvereisten. Gelukkig zijn er verschillende opties om uit te kiezen:min of meer knooppunten, volledige 3 DC of 2 DC en gekleed in de derde - het is vrij waarschijnlijk dat u iets vindt dat geschikt is voor u.
Netwerklatentie
Bij het werken met multi-DC-configuraties moet u er rekening mee houden dat de netwerklatentie aanzienlijk hoger zal zijn dan wat u zou verwachten van een lokale netwerkomgeving. Dit kan de prestaties van het Galera-cluster ernstig verminderen wanneer u het vergelijkt met een zelfstandige MySQL-instantie of een MySQL-replicatie-installatie. De vereiste dat alle knooppunten een schrijfset moeten certificeren, betekent dat alle knooppunten deze moeten ontvangen, ongeacht hoe ver ze verwijderd zijn. Met asynchrone replicatie hoeft u niet te wachten voordat u een vastlegging uitvoert. Natuurlijk heeft replicatie andere problemen en nadelen, maar latentie is niet de belangrijkste. Het probleem is vooral zichtbaar wanneer uw database hotspots heeft - rijen, die regelmatig worden bijgewerkt (tellers, wachtrijen, enz.). Die rijen kunnen niet vaker dan één keer per netwerkretour worden bijgewerkt. Voor clusters over de hele wereld kan dit gemakkelijk betekenen dat u een enkele rij niet vaker dan 2-3 keer per seconde kunt bijwerken. Als dit een beperking voor u wordt, kan dit betekenen dat het Galera-cluster niet geschikt is voor uw specifieke werklast.
Proxylaag in Multi-DC Galera-cluster
Het is niet voldoende om een Galera-cluster te hebben dat zich over meerdere datacenters uitstrekt, u hebt nog steeds uw applicatie nodig om er toegang toe te krijgen. Een van de populaire methoden om de complexiteit van de databaselaag voor een toepassing te verbergen, is het gebruik van een proxy. Proxy's worden gebruikt als toegangspunt tot de databases, ze volgen de status van de databaseknooppunten en zouden verkeer altijd naar alleen de beschikbare knooppunten moeten leiden. In deze sectie zullen we proberen een proxy-laagontwerp voor te stellen dat kan worden gebruikt voor een multi-DC Galera-cluster. We gebruiken ProxySQL, wat je behoorlijk wat flexibiliteit geeft bij het omgaan met databaseknooppunten, maar je kunt een andere proxy gebruiken, zolang deze de status van Galera-knooppunten kan volgen.
Waar vind je de proxy's?
Kortom, er zijn hier twee veelvoorkomende patronen:u kunt ProxySQL op afzonderlijke knooppunten implementeren of u kunt ze implementeren op de hosts van de toepassing. Laten we eens kijken naar de voor- en nadelen van elk van deze opstellingen.
Proxylaag als een aparte set hosts
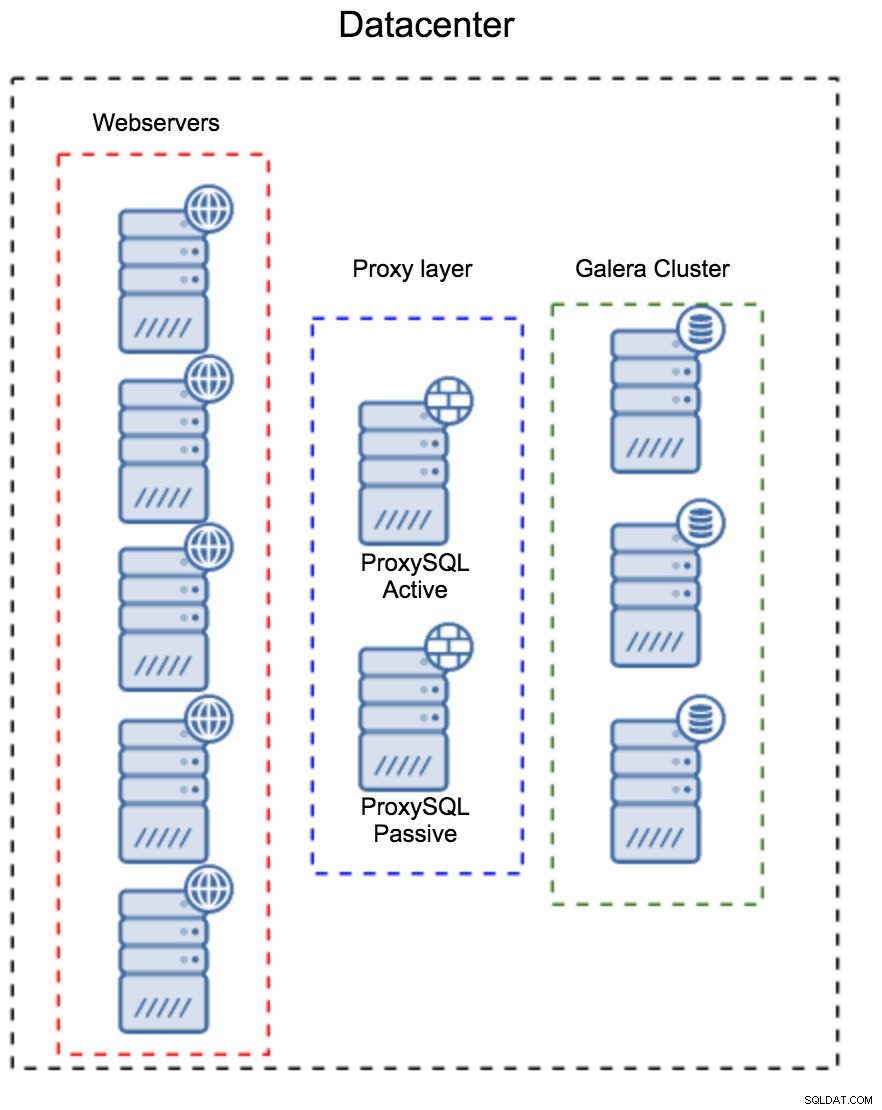
Het eerste patroon is het bouwen van een proxy-laag met behulp van afzonderlijke, toegewijde hosts. U kunt ProxySQL op een aantal hosts implementeren en Virtual IP en keepalive gebruiken om een hoge beschikbaarheid te behouden. Een applicatie gebruikt de VIP om verbinding te maken met de database, en de VIP zorgt ervoor dat verzoeken altijd worden doorgestuurd naar een beschikbare ProxySQL. Het belangrijkste probleem met deze opstelling is dat u maximaal één van de ProxySQL-instanties gebruikt - alle standby-knooppunten worden niet gebruikt voor het routeren van het verkeer. Dit kan u dwingen om krachtigere hardware te gebruiken dan u normaal zou gebruiken. Aan de andere kant is het gemakkelijker om de setup te onderhouden - u zult configuratiewijzigingen moeten toepassen op alle ProxySQL-knooppunten, maar er zullen er maar een handvol zijn. U kunt ook de optie van ClusterControl gebruiken om de knooppunten te synchroniseren. Een dergelijke installatie moet worden gedupliceerd op elk datacenter dat u gebruikt.
Proxy geïnstalleerd op applicatie-instanties
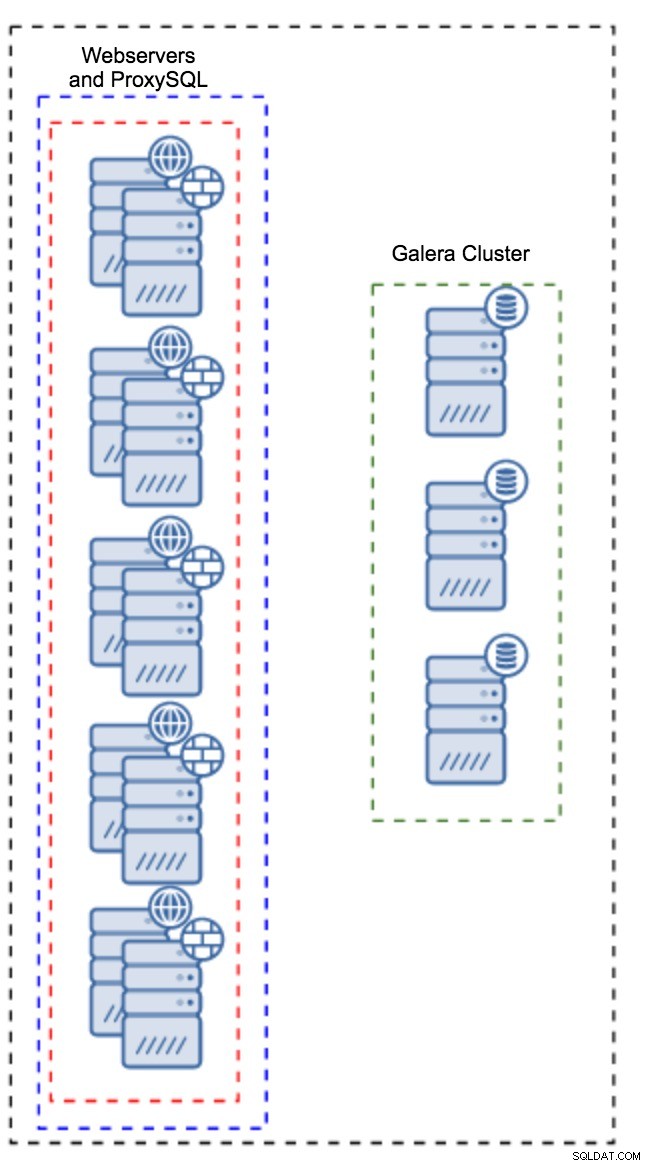
In plaats van een aparte set hosts te hebben, kan ProxySQL ook op de applicatiehosts worden geïnstalleerd. Applicatie zal rechtstreeks verbinding maken met de ProxySQL op localhost, het kan zelfs Unix-socket gebruiken om de overhead van de TCP-verbinding te minimaliseren. Het grote voordeel van zo'n setup is dat je een groot aantal ProxySQL-instances hebt en de belasting gelijkmatig over hen wordt verdeeld. Als er een uitvalt, wordt alleen die applicatiehost beïnvloed. De overige knooppunten blijven werken. Het meest serieuze probleem waarmee u te maken krijgt, is configuratiebeheer. Met een groot aantal ProxySQL-knooppunten is het cruciaal om een geautomatiseerde methode te bedenken om hun configuraties gesynchroniseerd te houden. Je zou ClusterControl kunnen gebruiken, of een configuratiebeheertool zoals Puppet.
Afstemming van Galera in een WAN-omgeving
Galera-standaardinstellingen zijn ontworpen voor een lokaal netwerk en als u het in een WAN-omgeving wilt gebruiken, is enige afstemming vereist. Laten we enkele van de basisaanpassingen bespreken die u kunt maken. Houd er rekening mee dat de precieze afstemming productiegegevens en verkeer vereist - je kunt niet zomaar wat wijzigingen aanbrengen en aannemen dat ze goed zijn, je moet de juiste benchmarking uitvoeren.
Besturingssysteemconfiguratie
Laten we beginnen met de configuratie van het besturingssysteem. Niet alle hier voorgestelde wijzigingen zijn WAN-gerelateerd, maar het is altijd goed om onszelf eraan te herinneren wat een goed startpunt is voor een MySQL-installatie.
vm.swappiness = 1Swappiness bepaalt hoe agressief het besturingssysteem swap zal gebruiken. Het mag niet op nul worden gezet, omdat het in recentere kernels verhindert dat het besturingssysteem swap gebruikt en dit ernstige prestatieproblemen kan veroorzaken.
/sys/block/*/queue/scheduler = deadline/noopDe planner voor het blokapparaat, dat MySQL gebruikt, moet worden ingesteld op deadline of noop. De exacte keuze hangt af van de benchmarks, maar beide instellingen zouden vergelijkbare prestaties moeten leveren, beter dan de standaardplanner, CFQ.
Voor MySQL zou je moeten overwegen om EXT4 of XFS te gebruiken, afhankelijk van de kernel (de prestaties van die bestandssystemen veranderen van de ene kernelversie naar de andere). Voer enkele benchmarks uit om de betere optie voor u te vinden.
Daarnaast wil je misschien de sysctl-netwerkinstellingen bekijken. We zullen ze niet in detail bespreken (u kunt hier documentatie vinden), maar het algemene idee is om buffers, achterstanden en time-outs te vergroten, om het gemakkelijker te maken om stallen en een onstabiele WAN-link op te vangen.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Naast het afstemmen van het besturingssysteem zou u moeten overwegen om Galera-netwerkgerelateerde instellingen aan te passen.
evs.suspect_timeout
evs.inactive_timeoutU kunt overwegen de standaardwaarden van deze variabelen te wijzigen. Beide time-outs bepalen hoe het cluster mislukte knoop punten verwijdert. Verdachte time-out vindt plaats wanneer alle knooppunten het inactieve lid niet kunnen bereiken. Inactieve time-out definieert een harde limiet voor hoe lang een knoop punt in het cluster kan blijven als het niet reageert. Meestal zult u merken dat de standaardwaarden goed werken. Maar in sommige gevallen, vooral als u uw Galera-cluster via WAN uitvoert (bijvoorbeeld tussen AWS-regio's), kan het verhogen van die variabelen resulteren in stabielere prestaties. We raden aan om beide in te stellen op PT1M, om het minder waarschijnlijk te maken dat instabiliteit van de WAN-link een knooppunt uit het cluster gooit.
evs.send_window
evs.user_send_windowDeze variabelen, evs.send_window en evs.user_send_window , definieer hoeveel pakketten er tegelijkertijd via replicatie kunnen worden verzonden (evs.send_window ) en hoeveel daarvan gegevens kunnen bevatten (evs.user_send_window ). Voor verbindingen met hoge latentie kan het de moeite waard zijn om die waarden aanzienlijk te verhogen (bijvoorbeeld 512 of 1024).
evs.inactive_check_periodDe bovenstaande variabele kan ook worden gewijzigd. evs.inactive_check_period , is standaard ingesteld op één seconde, wat te vaak kan zijn voor een WAN-configuratie. We raden u aan deze in te stellen op PT30S.
gcs.fc_factor
gcs.fc_limitHier willen we de kans dat flow control in werking treedt minimaliseren, daarom raden we aan om gcs.fc_factor in te stellen. naar 1 en verhoog gcs.fc_limit naar bijvoorbeeld 260.
gcs.max_packet_sizeOmdat we werken met de WAN-link, waar de latentie aanzienlijk hoger is, willen we de grootte van de pakketten vergroten. Een goed startpunt zou 2097152 zijn.
Zoals we eerder vermeldden, is het vrijwel onmogelijk om een eenvoudig recept te geven voor het instellen van deze parameters, omdat het van te veel factoren afhangt - u zult uw eigen benchmarks moeten doen, met gegevens die zo dicht mogelijk bij uw productiegegevens liggen, voordat u kan zeggen dat uw systeem is afgesteld. Dat gezegd hebbende, zouden deze instellingen je een startpunt moeten geven voor een meer nauwkeurige afstemming.
Dat is het voor nu. Galera werkt redelijk goed in WAN-omgevingen, dus probeer het eens en laat ons weten hoe het je vergaat.