In de laatste paar blogs hebben we besproken hoe je een Galera-cluster op Docker kunt draaien, of het nu op een stand-alone Docker is of op een Docker Swarm met meerdere hosts met een overlay-netwerk. In deze blogpost gaan we in op het gebruik van Galera Cluster op Kubernetes, een orkestratietool om containers op grote schaal uit te voeren. Sommige onderdelen zijn anders, zoals hoe de applicatie verbinding moet maken met het cluster, hoe Kubernetes omgaat met failover en hoe de taakverdeling in Kubernetes werkt.
Kubernetes vs Docker Swarm
Ons uiteindelijke doel is ervoor te zorgen dat Galera Cluster betrouwbaar draait in een containeromgeving. We hebben Docker Swarm eerder behandeld en het bleek dat het draaien van Galera Cluster erop een aantal blokkades heeft, waardoor het niet productieklaar is. Onze reis gaat nu verder met Kubernetes, een tool voor het orkestreren van containers op productieniveau. Laten we eens kijken welk niveau van "productiegereedheid" het kan ondersteunen bij het uitvoeren van een stateful service zoals Galera Cluster.
Voordat we verder gaan, laten we eerst enkele van de belangrijkste verschillen tussen Kubernetes (1.6) en Docker Swarm (17.03) benadrukken bij het uitvoeren van Galera Cluster op containers:
- Kubernetes ondersteunt twee gezondheidscontroles:levendigheid en gereedheid. Dit is belangrijk bij het uitvoeren van een Galera-cluster op containers, omdat een live Galera-container niet betekent dat deze klaar is om te dienen en moet worden opgenomen in de load balancing-set (denk aan een toetredende/donorstatus). Docker Swarm ondersteunt slechts één gezondheidscontrole-sonde die vergelijkbaar is met de levendigheid van Kubernetes, een container is ofwel gezond en blijft draaien of ongezond en wordt opnieuw gepland. Lees hier voor details.
- Kubernetes heeft een UI-dashboard dat toegankelijk is via "kubectl-proxy".
- Docker Swarm ondersteunt alleen round-robin load balancing (ingress), terwijl Kubernetes de minste verbinding gebruikt.
- Docker Swarm ondersteunt routeringsmesh om een service naar het externe netwerk te publiceren, terwijl Kubernetes iets soortgelijks ondersteunt, NodePort genaamd, evenals externe load balancers (GCE GLB/AWS ELB) en externe DNS-namen (zoals voor v1.7)
Kubernetes installeren met Kubeadm
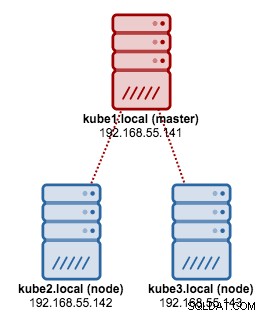
We gaan kubeadm gebruiken om een 3-node Kubernetes-cluster op CentOS 7 te installeren. Het bestaat uit 1 master en 2 nodes (minions). Onze fysieke architectuur ziet er als volgt uit:
1. Installeer kubelet en Docker op alle knooppunten:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. Initialiseer de master op de master, kopieer het configuratiebestand, stel het pod-netwerk in met Weave en installeer Kubernetes Dashboard:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Dan op de andere resterende knooppunten:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Controleer of de knooppunten gereed zijn:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3We hebben nu een Kubernetes-cluster voor de implementatie van Galera Cluster.
Galera-cluster op Kubernetes
In dit voorbeeld gaan we een MariaDB Galera Cluster 10.1 implementeren met behulp van een Docker-afbeelding die is opgehaald uit onze DockerHub-repository. De YAML-definitiebestanden die in deze implementatie worden gebruikt, zijn te vinden in de map voorbeeld-kubernetes in de Github-repository.
Kubernetes ondersteunt een aantal implementatiecontrollers. Om een Galera-cluster in te zetten, kan men gebruik maken van:
- ReplicaSet
- StatefulSet
Elk van hen heeft zijn eigen voor- en nadelen. We gaan ze allemaal bekijken en kijken wat het verschil is.
Vereisten
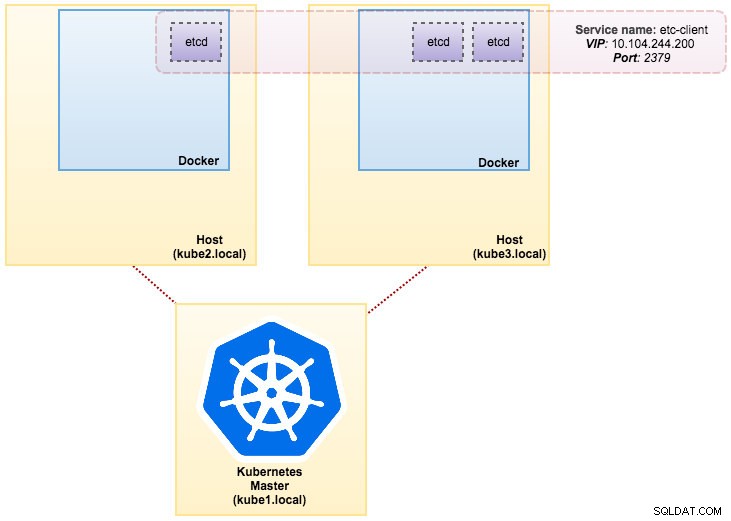
De afbeelding die we hebben gebouwd, vereist een etcd (zelfstandig of cluster) voor servicedetectie. Om een etcd-cluster uit te voeren, moet elke etcd-instantie met verschillende opdrachten worden uitgevoerd, dus we gaan de Pods-controller gebruiken in plaats van Deployment en een service maken met de naam "etcd-client" als eindpunt voor etcd Pods. Het definitiebestand etcd-cluster.yaml vertelt het allemaal.
Om een 3-pod etcd cluster te implementeren, voert u eenvoudig het volgende uit:
$ kubectl create -f etcd-cluster.yamlControleer of het etcd-cluster gereed is:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dOnze architectuur ziet er nu ongeveer zo uit:
 Severalnines MySQL op Docker:hoe u uw database kunt containerenOntdek alles wat u moet weten wanneer u overweegt een MySQL-service uit te voeren op top of Docker-containervirtualisatieDownload de whitepaper
Severalnines MySQL op Docker:hoe u uw database kunt containerenOntdek alles wat u moet weten wanneer u overweegt een MySQL-service uit te voeren op top of Docker-containervirtualisatieDownload de whitepaper ReplicaSet gebruiken
Een ReplicaSet zorgt ervoor dat er op een bepaald moment een bepaald aantal pod "replica's" wordt uitgevoerd. Een implementatie is echter een concept op een hoger niveau dat ReplicaSets beheert en declaratieve updates voor pods biedt, samen met een heleboel andere handige functies. Daarom wordt aanbevolen om implementaties te gebruiken in plaats van rechtstreeks ReplicaSets te gebruiken, tenzij u aangepaste update-orkestratie nodig hebt of helemaal geen updates nodig hebt. Wanneer u implementaties gebruikt, hoeft u zich geen zorgen te maken over het beheer van de ReplicaSets die ze maken. Implementaties bezitten en beheren hun ReplicaSets.
In ons geval gaan we Deployment gebruiken als de werkbelastingcontroller, zoals weergegeven in deze YAML-definitie. We kunnen de Galera Cluster ReplicaSet en Service rechtstreeks maken door de volgende opdracht uit te voeren:
$ kubectl create -f mariadb-rs.ymlControleer of het cluster gereed is door te kijken naar de ReplicaSet (rs), pods (po) en services (svc):
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dUit de bovenstaande uitvoer kunnen we onze pods en service als volgt illustreren:
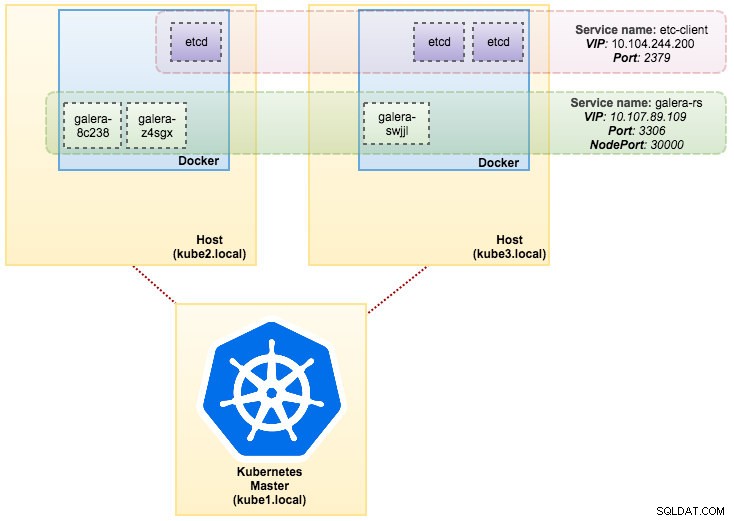
Het uitvoeren van Galera Cluster op ReplicaSet is vergelijkbaar met het behandelen als een stateless applicatie. Het orkestreert het maken, verwijderen en bijwerken van pods en kan worden getarget voor Horizontal Pod Autoscales (HPA), d.w.z. een ReplicaSet kan automatisch worden geschaald als het aan bepaalde drempels of doelen voldoet (CPU-gebruik, pakketten per seconde, verzoek per seconde enz.).
Als een van de Kubernetes-knooppunten uitvalt, worden nieuwe pods gepland op een beschikbaar knooppunt om aan de gewenste replica's te voldoen. Volumes die aan de pod zijn gekoppeld, worden verwijderd als de pod wordt verwijderd of opnieuw wordt gepland. De hostnaam van de pod wordt willekeurig gegenereerd, waardoor het moeilijker wordt om bij te houden waar de container thuishoort door simpelweg naar de hostnaam te kijken.
Dit alles werkt redelijk goed in test- en staging-omgevingen, waar u een volledige containerlevenscyclus kunt uitvoeren, zoals implementeren, schalen, bijwerken en vernietigen zonder enige afhankelijkheden. Op- en neerschalen is eenvoudig, door het YAML-bestand bij te werken en naar het Kubernetes-cluster te posten of door het scale-commando te gebruiken:
$ kubectl scale replicaset galera-rs --replicas=5StatefulSet gebruiken
StatefulSet, in pre 1.6 versie bekend als PetSet, is de beste manier om Galera Cluster in productie te nemen, omdat:
- Het verwijderen en/of verkleinen van een StatefulSet zal de volumes die aan de StatefulSet zijn gekoppeld niet verwijderen. Dit wordt gedaan om de veiligheid van gegevens te waarborgen, wat over het algemeen waardevoller is dan het automatisch opschonen van alle gerelateerde StatefulSet-bronnen.
- Voor een StatefulSet met N replica's, wanneer Pods worden geïmplementeerd, worden ze opeenvolgend gemaakt, in de volgorde van {0 .. N-1 }.
- Als pods worden verwijderd, worden ze in omgekeerde volgorde beëindigd, vanaf {N-1 .. 0}.
- Voordat een schaalbewerking op een pod wordt toegepast, moeten alle voorgangers actief en gereed zijn.
- Voordat een Pod wordt beëindigd, moeten alle opvolgers volledig worden afgesloten.
StatefulSet biedt eersteklas ondersteuning voor stateful containers. Het biedt een implementatie- en schaalgarantie. Wanneer een Galera-cluster met drie knooppunten wordt gemaakt, worden drie pods geïmplementeerd in de volgorde db-0, db-1, db-2. db-1 zal niet worden geïmplementeerd voordat db-0 "Running and Ready" is, en db-2 zal niet worden geïmplementeerd totdat db-1 "Running and Ready" is. Als db-0 zou mislukken, nadat db-1 "Running and Ready" is, maar voordat db-2 is gelanceerd, zal db-2 niet worden gestart totdat db-0 opnieuw is gestart en "Running and Ready" wordt.
We gaan Kubernetes-implementatie gebruiken van persistente opslag genaamd PersistentVolume en PersistentVolumeClaim. Dit om de persistentie van de gegevens te garanderen als de pod opnieuw wordt gepland naar het andere knooppunt. Hoewel Galera Cluster de exacte kopie van de gegevens op elke replica levert, is het goed om de gegevens in elke pod permanent te hebben voor het oplossen van problemen en voor hersteldoeleinden.
Om een permanente opslag te creëren, moeten we eerst PersistentVolume voor elke pod maken. PV's zijn volume-plug-ins zoals Volumes in Docker, maar hebben een levenscyclus die onafhankelijk is van een individuele pod die de PV gebruikt. Aangezien we een Galera-cluster met 3 knooppunten gaan implementeren, moeten we 3 PV's maken:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirDe bovenstaande definitie laat zien dat we 3 PV gaan maken, toegewezen aan het fysieke pad van de Kubernetes-knooppunten met 10 GB opslagruimte. We hebben ReadWriteOnce gedefinieerd, wat betekent dat het volume door slechts één knooppunt als lezen-schrijven kan worden aangekoppeld. Sla de bovenstaande regels op in mariadb-pv.yml en post deze op Kubernetes:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdDefinieer vervolgens de PersistentVolumeClaim-bronnen:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"De bovenstaande definitie laat zien dat we de PV-bronnen willen claimen en de spec.selector.matchLabels willen gebruiken om onze PV te zoeken (metadata.labels.app:galera-ss ) op basis van de respectieve pod-index (metadata.labels.podindex ) toegewezen door Kubernetes. De metadata.name resource moet de indeling "{volumeMounts.name}-{pod}-{ordinal index}" gebruiken die is gedefinieerd onder de spec.templates.containers zodat Kubernetes weet welk koppelpunt de claim in de pod moet plaatsen.
Sla de bovenstaande regels op in mariadb-pvc.yml en post deze op Kubernetes:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdOnze permanente opslag is nu klaar. We kunnen dan de implementatie van de Galera-cluster starten door een StatefulSet-bron te maken samen met een Headless-servicebron, zoals weergegeven in mariadb-ss.yml:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdHaal nu de samenvatting op van onze StatefulSet-implementatie:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dOp dit moment kan onze Galera-cluster die op StatefulSet draait, worden geïllustreerd zoals in het volgende diagram:
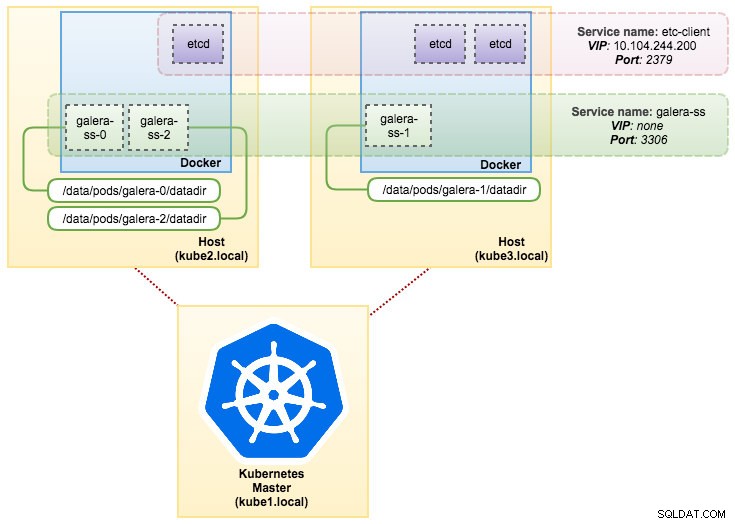
Draaien op StatefulSet garandeert consistente identifiers zoals hostnaam, IP-adres, netwerk-ID, clusterdomein, Pod DNS en opslag. Hierdoor kan de Pod zich gemakkelijk onderscheiden van anderen in een groep Pods. Het volume blijft op de host staan en wordt niet verwijderd als de pod wordt verwijderd of opnieuw wordt gepland op een ander knooppunt. Dit zorgt voor gegevensherstel en vermindert het risico van totaal gegevensverlies.
Aan de negatieve kant is de implementatietijd N-1 keer (N =replica's) langer omdat Kubernetes de ordinale volgorde zal volgen bij het implementeren, opnieuw plannen of verwijderen van de resources. Het zou een beetje een gedoe zijn om de PV en claims voor te bereiden voordat u nadenkt over het schalen van uw cluster. Houd er rekening mee dat het bijwerken van een bestaande StatefulSet momenteel een handmatig proces is, waarbij u alleen spec.replicas kunt bijwerken. op dit moment.
Verbinding maken met Galera Cluster Service en Pods
Er zijn een aantal manieren waarop u verbinding kunt maken met het databasecluster. U kunt rechtstreeks verbinding maken met de poort. In het voorbeeld van de "galera-rs"-service gebruiken we NodePort, waarbij de service op het IP-adres van elke Node wordt weergegeven op een statische poort (de NodePort). Er wordt automatisch een ClusterIP-service gemaakt, waarnaar de NodePort-service zal routeren. U kunt van buiten het cluster contact opnemen met de NodePort-service door {NodeIP}:{NodePort} aan te vragen. .
Voorbeeld om extern aan te sluiten op de Galera Cluster:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000Binnen de Kubernetes-netwerkruimte kunnen Pods intern verbinding maken via cluster-IP of servicenaam, die kan worden opgehaald met de volgende opdracht:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>Uit de servicelijst kunnen we zien dat de Galera Cluster ReplicaSet Cluster-IP 10.107.89.109 is. Intern kan een andere pod toegang krijgen tot de database via dit IP-adres of de servicenaam met behulp van de blootgestelde poort, 3306:
(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+U kunt ook verbinding maken met de externe NodePort vanuit elke pod op poort 30000:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+De verbinding met de backend-pods wordt dienovereenkomstig in evenwicht gebracht op basis van het minste verbindingsalgoritme.
Samenvatting
Op dit moment lijkt Galera Cluster op Kubernetes in productie veel veelbelovender in vergelijking met Docker Swarm. Zoals besproken in de laatste blogpost, worden de geuite zorgen anders aangepakt met de manier waarop Kubernetes containers orkestreert in StatefulSet (hoewel het nog steeds een bètafunctie is in v1.6). We hopen dat de voorgestelde aanpak zal helpen om Galera Cluster op containers op grote schaal in productie te laten draaien.