Het volgende is een uittreksel uit onze whitepaper "Hoe zeer beschikbare open source database-omgevingen te ontwerpen", dat gratis kan worden gedownload.
Een paar woorden over "Hoge beschikbaarheid"
Tegenwoordig is hoge beschikbaarheid een must voor elke serieuze implementatie. De tijd dat u een downtime van uw database kon plannen voor enkele uren om onderhoud uit te voeren, is lang voorbij. Als uw diensten niet beschikbaar zijn, verliest u klanten en geld. Daarom heeft een hoge beschikbaarheid van een databaseomgeving doorgaans een van de hoogste prioriteiten.
Dit vormt een grote uitdaging voor databasebeheerders. Allereerst, hoe weet u of uw omgeving zeer beschikbaar is of niet? Hoe zou je het meten? Welke stappen moet u nemen om de beschikbaarheid te verbeteren? Hoe ontwerp je je setup om deze vanaf het begin zeer beschikbaar te maken?
Er zijn veel HA-oplossingen beschikbaar in het MySQL (en MariaDB) ecosysteem, maar hoe weten we welke we kunnen vertrouwen? Sommige oplossingen werken mogelijk onder bepaalde specifieke omstandigheden, maar kunnen meer problemen veroorzaken als ze buiten deze omstandigheden worden toegepast. Zelfs een basisfunctionaliteit zoals MySQL-replicatie, die op veel manieren kan worden geconfigureerd, kan aanzienlijke schade aanrichten - bijvoorbeeld circulaire replicatie met meerdere beschrijfbare masters. Hoewel het eenvoudig is om een 'multi-master setup' op te zetten met behulp van replicatie, kan het heel gemakkelijk breken en ons met uiteenlopende datasets op verschillende servers achterlaten. Voor een database, die vaak wordt beschouwd als de enige bron van waarheid, kan een aangetaste gegevensintegriteit catastrofale gevolgen hebben.
In de volgende hoofdstukken bespreken we de vereisten voor hoge beschikbaarheid in databaseconfiguraties
en hoe het systeem van de grond af moet worden ontworpen.
Hoge beschikbaarheid meten
Wat is hoge beschikbaarheid? Om te kunnen beslissen of een bepaalde omgeving in hoge mate beschikbaar is of niet, moet je daar een aantal statistieken voor hebben. Er zijn talloze manieren waarop u hoge beschikbaarheid kunt meten, we zullen ons concentreren op enkele van de meest elementaire zaken.
Maar laten we eerst eens kijken waar deze hele hoge beschikbaarheid over gaat? Wat is de bedoeling? Het gaat erom ervoor te zorgen dat uw omgeving zijn doel dient. Een doel kan op veel manieren worden gedefinieerd, maar meestal gaat het om het leveren van een bepaalde service. In de databasewereld is het meestal enigszins gerelateerd aan gegevens. Het kan gegevens aan uw interne applicatie leveren. Het kan zijn om gegevens op te slaan en door analytische processen opvraagbaar te maken. Het kan zijn om bepaalde gegevens voor uw gebruikers op te slaan en deze op verzoek te verstrekken. Als we het doel helder hebben, kunnen we de succesfactoren vaststellen. Dit zal ons helpen te bepalen wat hoge beschikbaarheid in ons specifieke geval betekent.
SLA's
Service Level Agreement (SLA). Het is ook vrij gebruikelijk om SLA's voor interne services te definiëren. Wat is een SLA? Het is een definitie van het serviceniveau dat u aan uw klanten wilt bieden. Dit is voor hen om beter te begrijpen welk niveau van stabiliteit u plant voor een dienst die ze hebben gekocht of van plan zijn te kopen. Er zijn talloze methoden die u kunt gebruiken om een SLA op te stellen, maar typische zijn:
- Beschikbaarheid van de service (percentage)
- Responsiviteit van de service - latentie (gemiddeld, max, 95 percentiel, 99 percentiel)
- Pakketverlies via het netwerk (procent)
- Doorvoer (gemiddeld, minimum, 95 percentiel, 99 percentiel)
Het kan echter complexer worden dan dat. In een shard-omgeving met meerdere gebruikers kunt u, laten we zeggen, uw SLA definiëren als:"Service zal 99,99% van de tijd beschikbaar zijn, downtime wordt aangegeven wanneer meer dan 2% van de gebruikers wordt getroffen. Geen enkel incident kan langer dan 15 minuten duren om te worden opgelost”. Een dergelijke SLA kan ook worden uitgebreid om de responstijd voor query's op te nemen:"downtime wordt genoemd als 99 percentiel latentie voor query's 200 milliseconden overschrijdt".
Negen
Beschikbaarheid wordt meestal gemeten in "negen", laten we eens kijken wat een bepaald aantal "negen" precies garandeert. De onderstaande tabel is afkomstig van Wikipedia:
| Beschikbaarheid % | Stilstand per jaar | Stilstand per maand | Stilstand per week | Stilstand per dag |
|---|---|---|---|---|
| 90% ("een negen") | 36,5 dagen | 72 uur | 16,8 uur | 2.4 uur |
| 95% ("anderhalve negen") | 18,25 dagen | 36 uur | 8,4 uur | 1,2 uur |
| 97% | 10,96 dagen | 21,6 uur | 5,04 uur | 43,2 min |
| 98% | 7.30 dagen | 14,4 uur | 3,36 uur | 28,8 min |
| 99% ("twee negens") | 3,65 dagen | 7,20 uur | 1,68 uur | 14,4 min |
| 99,5% ("twee en een halve negen") | 1,83 dagen | 3,60 uur | 50,4 min | 7,2 min |
| 99,8% | 17.52 uur | 86,23 min | 20,16 min | 2,88 min |
| 99,9% ("drie negens") | 8,76 uur | 43,8 min | 10,1 min | 1,44 min |
| 99,95% ("drie en een halve negen") | 4.38 uur | 21,56 min | 5,04 min | 43,2 s |
| 99,99% ("vier negens") | 52,56 min | 4.38 min | 1,01 min | 8,64 s |
| 99,995% ("vier en een halve negen") | 26,28 min | 2,16 min | 30.24 s | 4.32 s |
| 99,999% ("vijf negens") | 5,26 min | 25,9 s | 6.05 s | 864.3 ms |
| 99,9999% ("zes negens") | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,999999% ("zeven negens") | 3.15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999% ("acht negens") | 315.569 ms | 26,297 ms | 6.048 ms | 0,864 ms |
| 99,9999999% ("negen negens") | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Zoals we kunnen zien, escaleert het snel. Vijf negens (99,999% beschikbaarheid) staat gelijk aan 5,26 minuten downtime in de loop van een jaar. Beschikbaarheid kan ook in verschillende, kleinere bereiken worden berekend:per maand, per week, per dag. Houd die cijfers in gedachten, want ze zullen nuttig zijn wanneer we beginnen met het bespreken van de kosten die gepaard gaan met het handhaven van verschillende beschikbaarheidsniveaus.
Beschikbaarheid meten
Om te weten of er sprake is van een downtime of niet, moet men inzicht hebben in de omgeving. U moet de statistieken bijhouden die de beschikbaarheid van uw systemen bepalen. Het is belangrijk om in gedachten te houden dat je het moet meten vanuit het oogpunt van een klant, rekening houdend met het bredere plaatje. Het maakt niet uit of uw databases actief zijn als, laten we zeggen, vanwege een netwerkprobleem, geen enkele toepassing ze niet kan bereiken. Elke afzonderlijke bouwsteen van uw installatie heeft zijn invloed op de beschikbaarheid.
Een van de goede plaatsen om naar beschikbaarheidsgegevens te zoeken, zijn webserverlogboeken. Alle verzoeken die met fouten eindigden, betekenen dat er iets is gebeurd. Het kan HTTP-fout 500 zijn die door de toepassing is geretourneerd, omdat de databaseverbinding is mislukt. Dat kunnen programmafouten zijn die wijzen op een aantal databaseproblemen en die in het foutenlogboek van Apache terecht zijn gekomen. U kunt ook eenvoudige metrische gegevens gebruiken als uptime van databaseservers, hoewel het met complexere SLA's lastig kan zijn om te bepalen hoe de onbeschikbaarheid van één database uw gebruikersbestand heeft beïnvloed. Wat u ook doet, u moet meer dan één statistiek gebruiken - dit is nodig om problemen vast te leggen die zich mogelijk in verschillende lagen van uw omgeving hebben voorgedaan.
Magisch getal:"Drie"
Hoewel hoge beschikbaarheid ook over redundantie gaat, is drie in het geval van databaseclusters een magisch getal. Het is niet genoeg om twee knooppunten te hebben voor redundantie - een dergelijke configuratie biedt geen ingebouwde hoge beschikbaarheid. Natuurlijk is het misschien beter dan slechts een enkel knooppunt, maar menselijke tussenkomst is vereist om services te herstellen. Laten we eens kijken waarom het zo is.
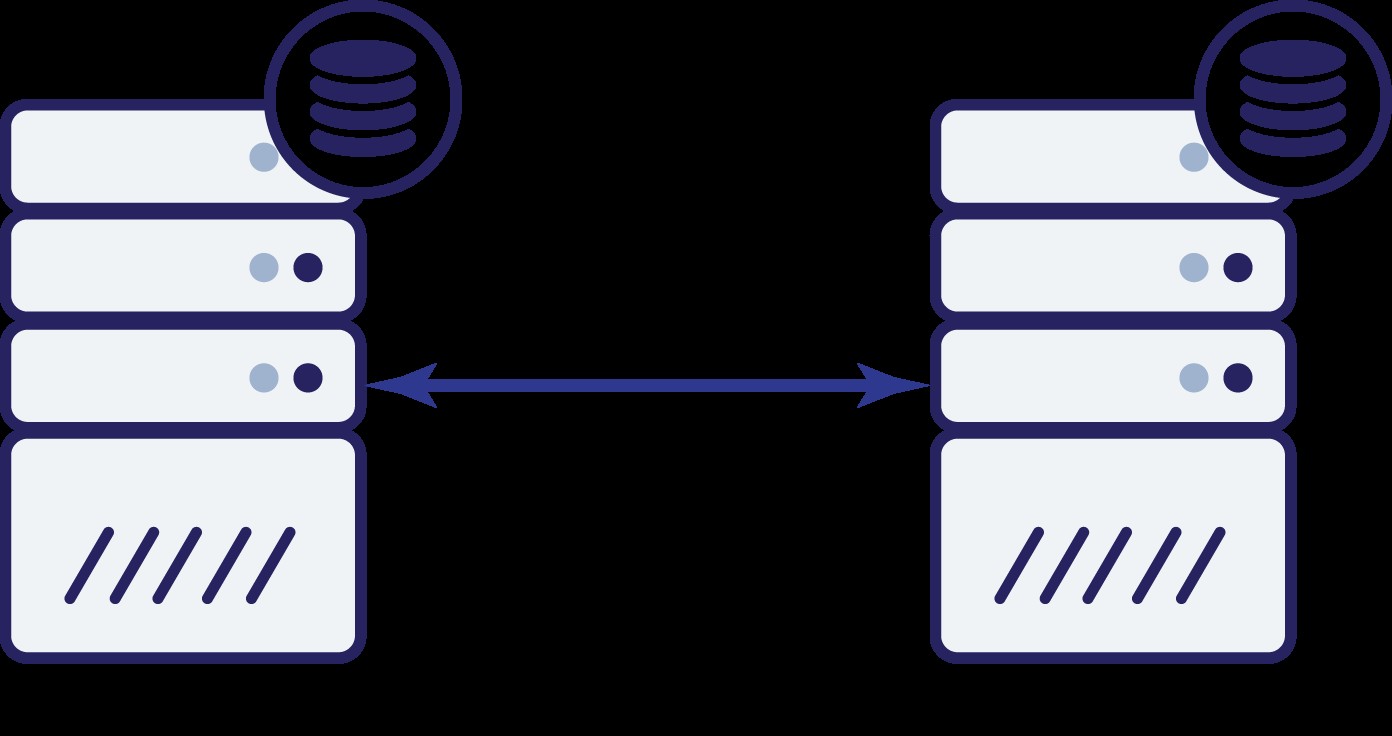
Laten we aannemen dat we twee knooppunten hebben, A en B. Er is een netwerkverbinding tussen hen. Laten we aannemen dat zowel A als B schrijfbewerkingen uitvoeren en dat de toepassing willekeurig kiest waar verbinding moet worden gemaakt (wat betekent dat een deel van de toepassing verbinding zal maken met knooppunt A en het andere deel zal verbinding maken met knooppunt B). Laten we ons nu eens voorstellen dat we een netwerkprobleem hebben waardoor de netwerkverbinding tussen A en B verloren gaat.
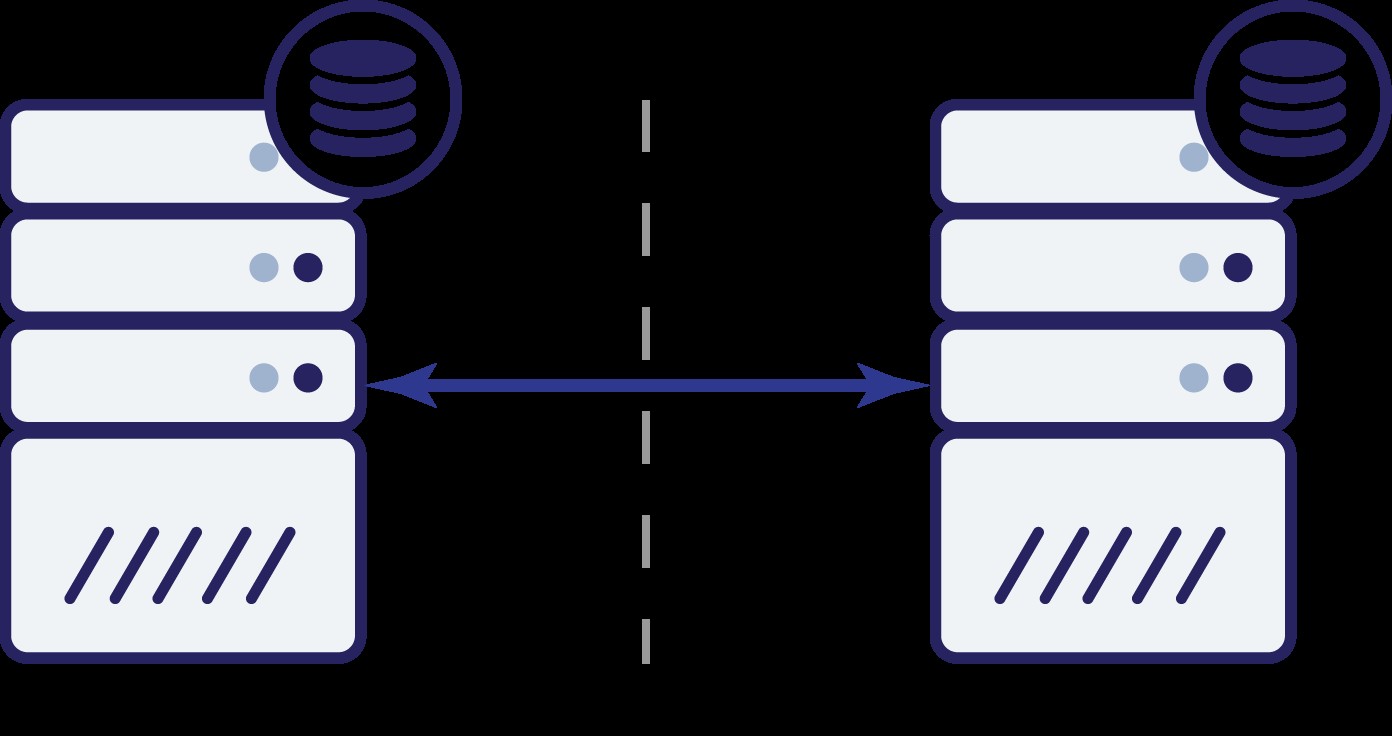
Wat nu? Noch A noch B kunnen de toestand van het andere knooppunt kennen. Er zijn twee acties die door beide knooppunten kunnen worden ondernomen:
- Ze kunnen doorgaan met het accepteren van verkeer
- Ze kunnen stoppen met werken en weigeren om enig verkeer te bedienen
Laten we eens nadenken over de eerste optie. Zolang het andere knooppunt inderdaad niet beschikbaar is, is dit de beste actie die moet worden ondernomen - we willen dat onze database verkeer blijft bedienen. Dit is immers de hoofdgedachte achter hoge beschikbaarheid. Wat zou er echter gebeuren als beide knooppunten verkeer zouden blijven accepteren terwijl ze van elkaar werden losgekoppeld? Er worden aan beide kanten nieuwe gegevens toegevoegd en de gegevenssets lopen niet meer synchroon. Wanneer het netwerkprobleem is opgelost, zal het een ontmoedigende taak zijn om die twee datasets samen te voegen. Daarom is het niet acceptabel om beide knooppunten actief te houden. Het probleem is - hoe kan knooppunt A zien of knooppunt B leeft of niet (en vice versa)? Het antwoord is:dat kan niet. Als alle verbindingen zijn verbroken, is er geen manier om een defect knooppunt te onderscheiden van een defect netwerk. Als gevolg hiervan is de enige veilige actie dat beide knooppunten alle bewerkingen stopzetten en weigeren om
verkeer te bedienen.
Laten we eens kijken hoe een derde knooppunt ons in zo'n situatie kan helpen.
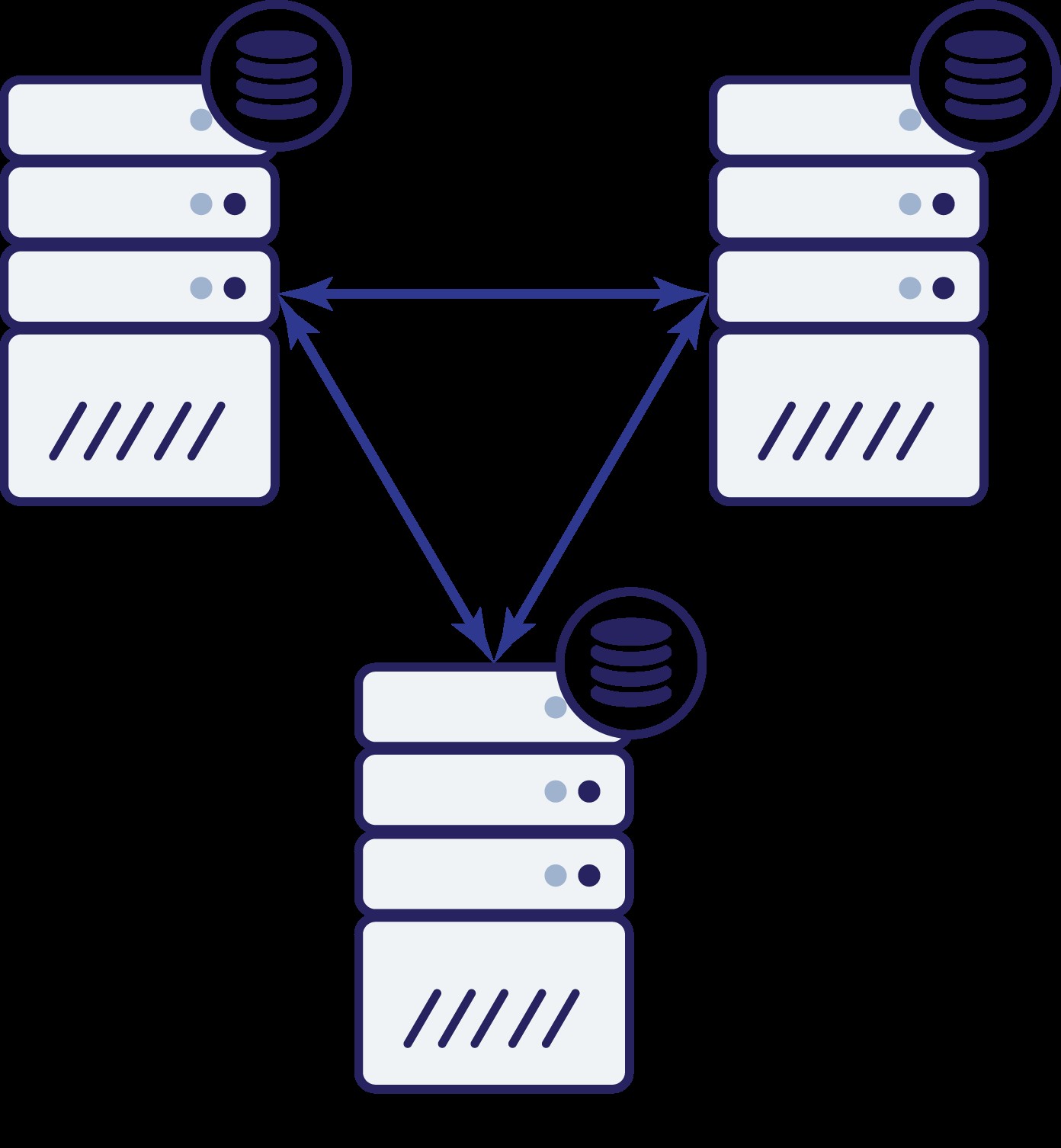
We hebben nu dus drie knooppunten:A, B en C. Ze zijn allemaal met elkaar verbonden, ze verwerken alle lees- en schrijfbewerkingen.
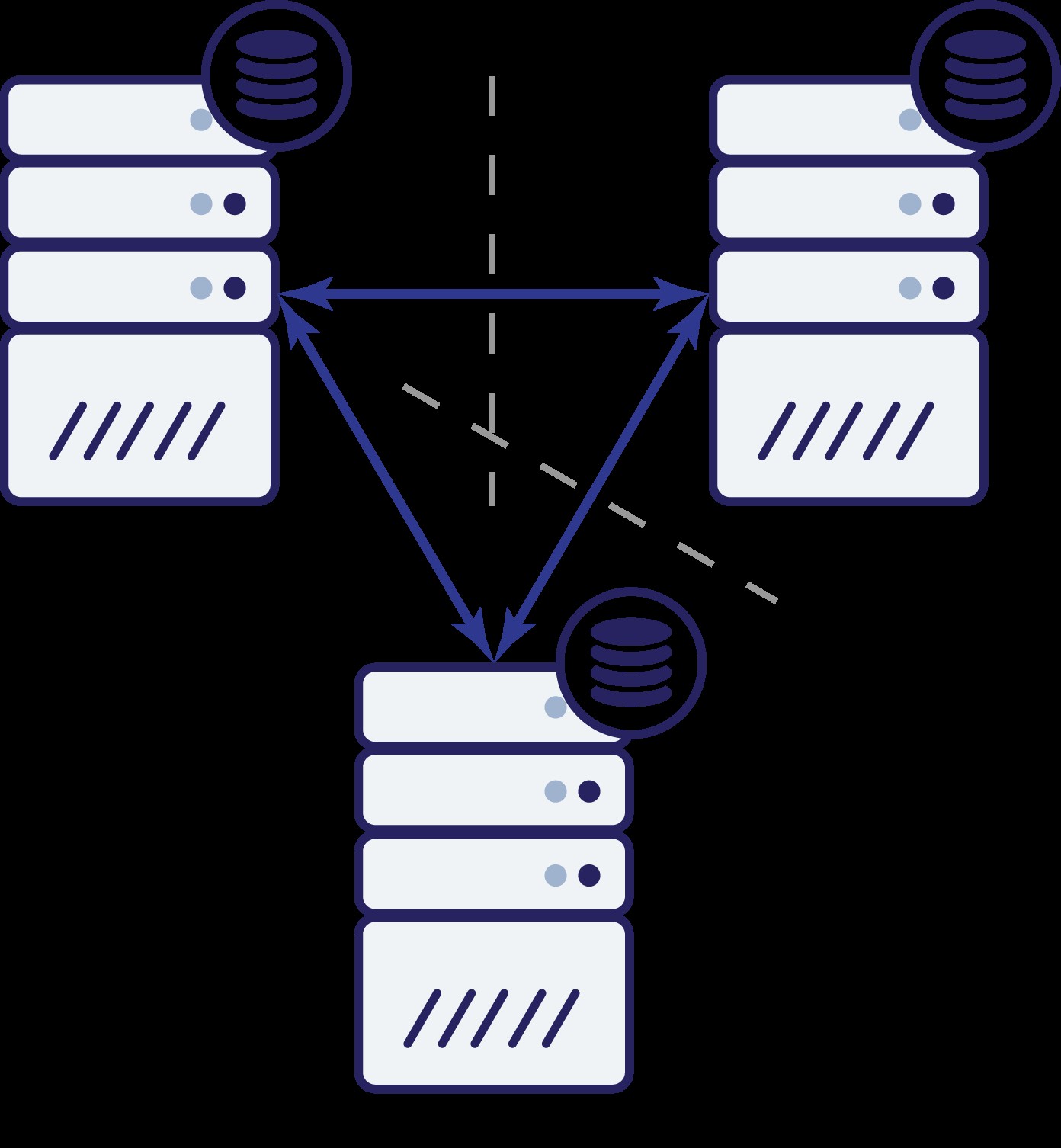
Nogmaals, zoals in het vorige voorbeeld, is knooppunt B afgesneden van de rest van het cluster vanwege netwerkproblemen. Wat kan er daarna gebeuren? Welnu, de situatie is redelijk vergelijkbaar met wat we eerder hebben besproken. Twee opties:knooppunt B kan ofwel down zijn (en de rest van het cluster moet doorgaan) of het kan up zijn, in welk geval het geen verkeer mag verwerken. Kunnen we nu zien wat de status van het cluster is? Eigenlijk ja. We kunnen zien dat knooppunten A en C met elkaar kunnen praten en als gevolg daarvan kunnen ze overeenkomen dat knooppunt B niet beschikbaar is. Ze zullen niet kunnen vertellen waarom het is gebeurd, maar wat ze weten is dat van de drie knooppunten in het cluster er nog steeds connectiviteit met elkaar is. Aangezien die twee knooppunten een meerderheid van het cluster vormen, is het mogelijk om het verkeer te blijven afhandelen. Tegelijkertijd kan knooppunt B ook afleiden dat het probleem aan zijn kant ligt. Het heeft geen toegang tot knooppunt A of knooppunt C, waardoor knooppunt B gescheiden is van de rest van het cluster. Omdat het geïsoleerd is en geen deel uitmaakt van een meerderheid (1 van 3), is de enige veilige actie die het kan nemen om het verkeer te stoppen en vragen te weigeren, zodat er geen data-drift zal plaatsvinden.
Dit betekent natuurlijk niet dat u slechts drie knooppunten in het cluster kunt hebben. Als u een betere faaltolerantie wilt, wilt u misschien meer toevoegen. Houd er echter rekening mee dat het een oneven aantal moet zijn als u de hoge beschikbaarheid wilt verbeteren. We hadden het ook over "knooppunten" in de bovenstaande voorbeelden. Houd er rekening mee dat dit ook geldt voor datacenters, beschikbaarheidszones enz. Als u twee datacenters heeft, elk met hetzelfde aantal knooppunten (laten we zeggen drie knooppunten elk), en u verliest de verbinding tussen die twee DC's, dan gelden hier dezelfde principes. - u kunt niet zeggen welke helft van het cluster het verkeer moet gaan afhandelen. Om dat te kunnen zien, moet je een waarnemer hebben in een derde datacenter. Het kan nog een andere set knooppunten zijn, of slechts een enkele host, met de taak
om de status van de resterende dataceters te observeren en deel te nemen aan het nemen van beslissingen (een voorbeeld hiervan is de Galera-arbiter).
Enkele punten van mislukking
Hoge beschikbaarheid heeft alles te maken met het verwijderen van single points of failure (SPOF) en niet met het introduceren van nieuwe in het proces. Wat zijn de SPOF's? Elk onderdeel van uw infrastructuur dat, wanneer het uitvalt, downtime veroorzaakt zoals gedefinieerd in SLA, wordt een SPOF genoemd. Infrastructuurontwerp vereist een holistische benadering, de verschillende componenten kunnen niet los van elkaar worden ontworpen. Hoogstwaarschijnlijk bent u niet verantwoordelijk voor het hele ontwerp -
databasebeheerders hebben de neiging zich te concentreren op databases en niet op bijvoorbeeld de netwerklaag. Toch moet je de andere onderdelen in gedachten houden en samenwerken met de teams die ervoor verantwoordelijk zijn, om ervoor te zorgen dat niet alleen het onderdeel waarvoor je verantwoordelijk bent correct is ontworpen, maar ook dat de resterende delen van de infrastructuur zijn ontworpen met behulp van de dezelfde principes. Bovendien helpt dergelijke kennis van hoe de hele
infrastructuur is ontworpen, u ook bij het ontwerpen van de databasestack. Weten welke problemen kunnen optreden, helpt bij het bouwen van een aantal mechanismen om te voorkomen dat ze de beschikbaarheid van de database beïnvloeden.