Gezien de huidige grote use-case van een database om gegevens op te halen, wordt het erg belangrijk dat de prestaties ervan zeer hoog zijn en dat dit alleen kan worden bereikt als gegevens op de meest efficiënt mogelijke manier uit de opslag worden gehaald. Er zijn veel succesvolle uitvindingen en implementaties gedaan om hetzelfde te bereiken. Een van de bekende benaderingen van de meeste databases is om een index op tafel te hebben.
Wat is een database-index?
Database Index, zoals de naam al doet vermoeden, houdt een index bij van de werkelijke gegevens en verbetert daardoor de prestaties om gegevens uit de werkelijke tabel op te halen. In een meer databaseterminologie maakt de index het mogelijk om pagina's met geïndexeerde gegevens op te halen in een zeer minimale doorgang, aangezien gegevens in een specifieke volgorde worden gesorteerd. Indexvoordeel gaat ten koste van extra opslagruimte om extra gegevens te schrijven. Indexen zijn specifiek voor de onderliggende tabel en bestaan uit een of meer sleutels (d.w.z. een of meer kolommen van de opgegeven tabel). Er zijn hoofdzakelijk twee soorten indexarchitectuur
- Geclusterde index - Indexgegevens worden samen met andere delen van gegevens opgeslagen en gegevens worden gesorteerd op basis van de indexsleutel. Er kan maximaal één index in deze categorie zijn voor een gespecificeerde tabel.
- Niet-geclusterde index - Indexgegevens worden afzonderlijk opgeslagen en hebben een verwijzing naar de opslag waar een ander deel van de gegevens wordt opgeslagen. Dit wordt ook wel secundaire index genoemd. Er kunnen zoveel indexen van deze categorie zijn als je wilt op een gespecificeerde tabel.
Er zijn verschillende datastructuren die worden gebruikt voor het implementeren van indexen. Enkele van de meest gebruikte databases zijn B-Tree en Hash.
Wat is een PostgreSQL-index?
PostgreSQL ondersteunt alleen niet-geclusterde indexen. Dat betekent indexgegevens en volledige gegevens (hier verder aangeduid als heap data ) worden in een aparte opslagruimte bewaard. Niet-geclusterde indexen zijn als "Inhoudsopgave" in elk document, waarbij we eerst het paginanummer controleren en vervolgens die paginanummers controleren om de hele inhoud te lezen. Om de volledige gegevens op basis van een index te krijgen, houdt het een verwijzing naar de bijbehorende heapgegevens bij. Het is hetzelfde als na het kennen van het paginanummer, het naar die pagina moet gaan en de daadwerkelijke inhoud van de pagina moet krijgen.
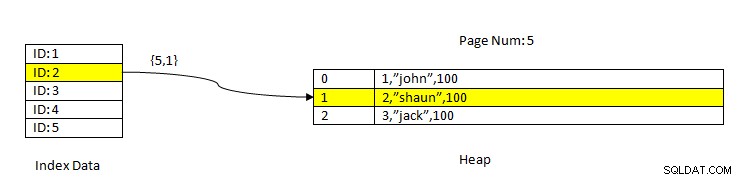 PostgreSQL:gegevens gelezen met index
PostgreSQL:gegevens gelezen met index Denk bijvoorbeeld aan een tabel met drie kolommen en een index op kolom ID . Om de gegevens te LEZEN op basis van de sleutel ID=2, worden eerst de geïndexeerde gegevens met de ID-waarde 2 doorzocht. Dit bevat een aanwijzer (genaamd Item Pointer) in termen van het paginanummer (d.w.z. bloknummer) en offset van gegevens binnen die pagina. In het huidige voorbeeld verwijst de index naar paginanummer 5 en het tweede regelitem op de pagina, dat op zijn beurt de volledige gegevens (2, "Shaun", 100) verschoven houdt. Merk op dat hele gegevens ook de geïndexeerde gegevens bevatten, wat betekent dat dezelfde gegevens in twee opslagplaatsen worden herhaald.
Hoe helpt INDEX om de prestaties te verbeteren? Welnu, om een INDEX-record te selecteren, scant het niet alle pagina's opeenvolgend, maar moet het slechts een deel van de pagina's gedeeltelijk scannen met behulp van de onderliggende Index-gegevensstructuur. Maar er is een wending, aangezien elk record dat uit Index-gegevens wordt gevonden, in Heap-gegevens moet zoeken naar volledige gegevens, wat veel willekeurige I/O veroorzaakt en waarvan wordt aangenomen dat het langzamer presteert dan Sequentiële I/O. Dus alleen als een klein percentage records wordt geselecteerd (wat is besloten op basis van de PostgreSQL-optimalisatiekosten), dan kiest alleen PostgreSQL Index Scan, anders blijft het Sequence Scan gebruiken, ook al staat er een index op de tafel.
Samengevat, hoewel het maken van indexen de prestaties versnelt, moet het zorgvuldig worden gekozen omdat het overhead heeft in termen van opslag, verslechterde INSERT-prestaties.
Nu kunnen we ons afvragen, als we alleen het indexgedeelte van gegevens nodig hebben, kunnen we dan alleen ophalen van de indexopslagpagina? Welnu, het antwoord hierop is direct gerelateerd aan hoe MVCC werkt op de indexopslag, zoals hierna wordt uitgelegd.
MVCC gebruiken voor indexeren
Net als Heap-pagina's, bevat de indexpagina meerdere versies van index-tuple, maar houdt deze geen zichtbaarheidsinformatie bij. Zoals uitgelegd in mijn vorige MVCC blog, om een geschikte zichtbare versie van tupels te bepalen, moet de transactie worden vergeleken. De transactie die een tuple heeft ingevoegd/bijgewerkt/verwijderd, wordt samen met de heap-tuple bijgehouden, maar hetzelfde wordt niet bijgehouden met de index-tuple. Dit wordt puur gedaan om opslagruimte te besparen en het is een afweging tussen ruimte en prestaties.
Nu terugkomend op de oorspronkelijke vraag, aangezien de zichtbaarheidsinformatie in Index-tuple er niet is, moet het de overeenkomstige heap-tuple raadplegen om te zien of de geselecteerde gegevens zichtbaar zijn. Dus hoewel andere delen van de gegevens van heap tuple niet vereist zijn, moet je toch toegang hebben tot de heap-pagina's om de zichtbaarheid te controleren. Maar nogmaals, er is een wending in het geval dat alle tuples op een bepaalde pagina (pagina waarnaar wordt verwezen door index, d.w.z. ItemPointer) zichtbaar zijn, dan hoeft niet elk item van de Heap-pagina te worden doorverwezen voor "zichtbaarheidscontrole" en daarom kunnen de gegevens alleen worden geretourneerd van de Index-pagina. Dit speciale geval wordt "Index Only Scan" genoemd. Om dit te ondersteunen, houdt PostgreSQL een zichtbaarheidskaart bij voor elke pagina om de zichtbaarheid op paginaniveau te controleren.
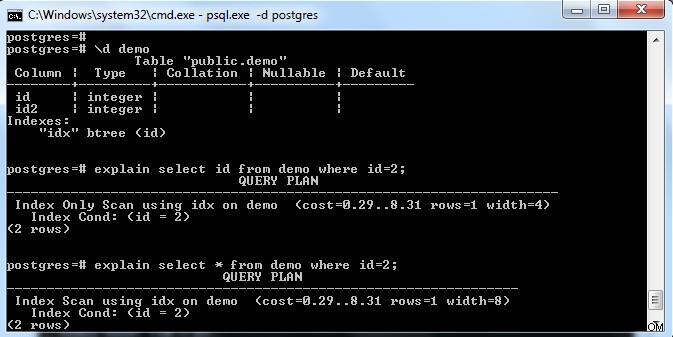
Zoals te zien is in de bovenstaande afbeelding, is er een index op de tabel "demo" met een sleutel op kolom "id". Als we alleen het indexveld (d.w.z. id) proberen te selecteren, heeft het de "Index Only Scan" gekozen (gezien de verwijzende pagina volledig zichtbaar).
Geclusterde index
Er is geen ondersteuning voor directe geclusterde index in PostgreSQL, maar er is een indirecte manier om hetzelfde gedeeltelijk te bereiken. Dit wordt bereikt door onderstaande SQL-commando's:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Het eerste commando geeft de database de opdracht om een tabel te clusteren (d.w.z. om de tabel te sorteren) met behulp van de gegeven index. Deze index had al aangemaakt moeten zijn. Deze clustering is slechts een eenmalige bewerking en de impact ervan blijft niet bestaan na de volgende bewerking op deze tabel, d.w.z. als er meer records worden ingevoegd/bijgewerkt, blijft de tabel mogelijk niet geordend. Indien nodig door de gebruiker om de tabel nog steeds geclusterd (geordend) te houden, kunnen ze het eerste commando gebruiken zonder een indexnaam op te geven.
De tweede opdracht is alleen nuttig om de tabel opnieuw te clusteren (d.w.z. de tabel die al was geclusterd met behulp van een index). Met deze opdracht worden alle tabellen in de huidige database opnieuw geclusterd die zichtbaar zijn voor de huidige verbonden gebruiker.
In de onderstaande afbeelding retourneert de eerste SELECT records in ongesorteerde volgorde omdat er geen geclusterde index is. Ook al is er al een niet-geclusterde index, maar de records worden geselecteerd uit het heapgebied waar de records niet zijn gesorteerd.
De tweede SELECT retourneert de records gesorteerd op kolom "id" zoals het is geclusterd met behulp van index die kolom "id" bevat.
De derde SELECT retourneert gedeeltelijke records in gesorteerde volgorde, maar nieuw ingevoegde records worden niet gesorteerd. De vierde SELECT retourneert opnieuw alle records in gesorteerde volgorde omdat de tabel opnieuw is geclusterd
 PostgreSQL-clusteropdracht
PostgreSQL-clusteropdracht Indextype
PostgreSQL biedt verschillende soorten indexen, zoals hieronder:
- B-Tree
- Hash
- GiST
- GIN
- BRIN
Elk indextype implementeert verschillende soorten onderliggende gegevensstructuur, die het meest geschikt is voor verschillende soorten query's. Standaard wordt de B-Tree-index gemaakt, wat veelgebruikte indexen zijn. Details van elk indextype zullen in een toekomstige blog worden behandeld.
Diversen:Gedeeltelijke en expressie-index
We hebben alleen gesproken over indexen op een of meer kolommen van een tabel, maar er zijn nog twee andere manieren om indexen te maken op PostgreSQL
- Gedeeltelijke index: Gedeeltelijke index is een index die is gebouwd met behulp van de subset van een sleutelkolom voor een bepaalde tabel. De subset wordt gedefinieerd door de voorwaardelijke expressie die wordt gegeven tijdens de index maken. Dus met de gedeeltelijke index wordt opslagruimte voor het opslaan van indexgegevens bespaard. De gebruiker moet de voorwaarde dus zo kiezen dat dit niet erg veelvoorkomende waarden zijn, want voor vaker voorkomende (veelvoorkomende) waarden wordt sowieso geen indexscan gekozen. De rest van de functionaliteit blijft hetzelfde als voor een normale index. Voorbeeld:gedeeltelijke index
- Expressie-index: Expressie-indexen geven een ander soort flexibiliteit in PostgreSQL. Alle indexen die tot nu toe zijn besproken, inclusief gedeeltelijke indexen, staan op een bepaalde reeks kolommen. Maar wat als een query toegang tot een tabel inhoudt op basis van de expressie (expressie met een of meer kolommen), zonder een expressie-index zal het geen indexscan kiezen. Dus om snel toegang te krijgen tot dit soort query's, maakt PostgreSQL het mogelijk om een index op een expressie te maken. De rest van de functionaliteit blijft hetzelfde als voor een normale index.
 Voorbeeld:expressie-index
Voorbeeld:expressie-index
Indexopslag in InnoDB
Het gebruik en de functionaliteit van Index is grotendeels hetzelfde als die in PostgreSQL met een groot verschil in termen van geclusterde index.
InnoDB ondersteunt twee categorieën indexen:
- Geclusterde index
- Secundaire index
Geclusterde index
Clustered Index is een speciaal soort index in InnoDB. Hier worden de geïndexeerde gegevens niet afzonderlijk opgeslagen, maar maken ze deel uit van de hele rijgegevens. Met andere woorden, de geclusterde index dwingt alleen de tabelgegevens fysiek te sorteren met behulp van de sleutelkolom van de index. Het kan worden beschouwd als "Woordenboek", waar gegevens worden gesorteerd op basis van het alfabet.
Aangezien de geclusterde index rijen sorteert met behulp van een indexsleutel, kan er slechts één geclusterde index zijn. Er moet ook één geclusterde index zijn, aangezien InnoDB deze gebruikt om gegevens optimaal te manipuleren tijdens verschillende gegevensbewerkingen.
Geclusterde indexen worden automatisch gemaakt (als onderdeel van het maken van tabellen) met behulp van een van de tabelkolommen volgens onderstaande prioriteit:
- De primaire sleutel gebruiken als de primaire sleutel wordt vermeld als onderdeel van het maken van de tabel.
- Kies een unieke kolom waarbij alle sleutelkolommen NIET NULL zijn.
- Anders wordt intern een verborgen geclusterde index op een systeemkolom gegenereerd die de rij-ID van elke rij bevat.
In tegenstelling tot PostgreSQL niet-geclusterde index, heeft InnoDB sneller toegang tot een rij met behulp van geclusterde index omdat de indexzoekopdracht rechtstreeks naar de pagina met alle rijgegevens leidt en zo willekeurige I/O vermijdt.
Ook het verkrijgen van de tabelgegevens in gesorteerde volgorde met behulp van de geclusterde index is erg snel omdat alle gegevens al zijn gesorteerd en ook volledige gegevens beschikbaar zijn.
Secundaire index
De index die expliciet in InnoDB is gemaakt, wordt beschouwd als een secundaire index, die vergelijkbaar is met de niet-geclusterde PostgreSQL-index. Elk record in de secundaire indexopslag bevat een primaire sleutelkolom van de rijen (die werden gebruikt voor het maken van een geclusterde index) en ook de kolommen die zijn opgegeven om een secundaire index te maken.
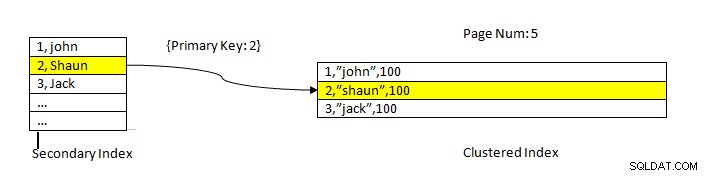 InnoDB:gegevens gelezen met index
InnoDB:gegevens gelezen met index Het ophalen van gegevens met behulp van een secundaire index is vergelijkbaar met het geval van PostgreSQL, behalve dat het opzoeken van de secundaire index van InnoDB een primaire sleutel geeft als een aanwijzer om de resterende gegevens uit de geclusterde index op te halen.
Zoals te zien is in de bovenstaande afbeelding, bevindt de geclusterde index zich bijvoorbeeld in de kolom ID, dus tabelgegevens worden op dezelfde manier gesorteerd. De secundaire index staat in de kolom "naam ”, dus zoals we kunnen zien, heeft de secundaire index zowel ID als naamwaarde. Zodra we zoeken met behulp van de secundaire index, vindt deze de juiste sleuf met de bijbehorende sleutelwaarde. Vervolgens wordt de bijbehorende primaire sleutel gebruikt om te verwijzen naar het resterende deel van de gegevens uit de geclusterde index.
MVCC voor index
De geclusterde index MVCC gebruikt het traditionele InnoDB Undo-model (eigenlijk hetzelfde als MVCC met volledige gegevens, omdat de geclusterde index niets anders is dan volledige gegevens).
Maar de secundaire Index MVCC gebruikt een iets andere benadering om MVCC te behouden. Bij het bijwerken van de secundaire index wordt het oude indexitem gemarkeerd met verwijderen en worden nieuwe records in dezelfde opslag geplaatst, d.w.z. UPDATE is niet aanwezig. Ten slotte worden oude indexitems verwijderd. Inmiddels is het je misschien opgevallen dat de secundaire index MVCC van InnoDB bijna hetzelfde is als die van het PostgreSQL MVCC-model.
Indextype
InnoDB ondersteunt alleen B-Tree type index en hoeft daarom niet te worden opgegeven tijdens het maken van een index.
Diversen:Adaptieve hash-indexen
Zoals vermeld in het vorige gedeelte dat alleen B-Tree-type index wordt ondersteund door InnoDB, maar er is een wending. InnoDB heeft de functionaliteit om automatisch te detecteren of de query baat kan hebben bij het bouwen van een hash-index en ook hele gegevens van de tabel in het geheugen passen, dan doet het dat automatisch.
De hash-index wordt gebouwd met behulp van de bestaande B-Tree-index, afhankelijk van de query. Als er meerdere secundaire B-Tree-indexen zijn, wordt degene gekozen die in aanmerking komt volgens de zoekopdracht. De opgebouwde hash-index is niet compleet, het bouwt slechts een gedeeltelijke index op volgens het gegevensgebruikspatroon.
Dit is een van de echt krachtige functies om de queryprestaties dynamisch te verbeteren.
Conclusie
Het gebruik van een index in een database is erg nuttig om de READ-prestaties te verbeteren, maar tegelijkertijd verslechtert het de INSERT/UPDATE-prestaties omdat het aanvullende gegevens moet schrijven. De index moet dus zeer verstandig worden gekozen en mag alleen worden gemaakt als de indexsleutels worden gebruikt als een predikaat om gegevens op te halen.
InnoDB biedt een zeer goede functie in termen van de geclusterde index, wat erg handig kan zijn, afhankelijk van de gebruikssituaties. De adaptieve hash-indexering is ook erg krachtig.
Terwijl PostgreSQL verschillende soorten indexen biedt, die echt opties voor het bereiken van functies kunnen bieden en een of alle indexen kunnen worden gebruikt, afhankelijk van de zakelijke use-case. Ook de gedeeltelijke en de expressie-indexen zijn behoorlijk nuttig, afhankelijk van het gebruik.