Mysqldump is de meest populaire logische back-uptool voor MySQL. Het is opgenomen in de MySQL-distributie, dus het is klaar voor gebruik op alle MySQL-instanties.
Logische back-ups zijn echter niet de snelste en ook niet de meest ruimtebesparende manier om MySQL-databases te back-uppen, maar ze hebben een enorm voordeel ten opzichte van fysieke back-ups.
Fysieke back-ups zijn meestal alles of niets back-ups. Hoewel het mogelijk is om een gedeeltelijke back-up te maken met Xtrabackup (we hebben dit beschreven in een van onze vorige blogposts), is het herstellen van een dergelijke back-up lastig en tijdrovend.
Als we een enkele tabel willen herstellen, moeten we de hele replicatieketen stoppen en het herstel op alle knooppunten tegelijk uitvoeren. Dit is een groot probleem - tegenwoordig kunt u het zich zelden veroorloven om alle databases te stoppen.
Een ander probleem is dat het tabelniveau het laagste granulariteitsniveau is dat u kunt bereiken met Xtrabackup:u kunt een enkele tabel herstellen, maar u kunt een deel ervan niet herstellen. Logische back-up kan echter worden hersteld op de manier waarop SQL-instructies worden uitgevoerd, daarom kan het eenvoudig worden uitgevoerd op een actief cluster en u kunt (we zouden het niet gemakkelijk noemen, maar toch) kiezen welke SQL-instructies u wilt uitvoeren, zodat u kunt doe een gedeeltelijk herstel van een tabel.
Laten we eens kijken hoe dit in de echte wereld kan.
Een enkele MySQL-tabel herstellen met mysqldump
Houd er in het begin rekening mee dat gedeeltelijke back-ups geen consistent beeld van de gegevens geven. Wanneer u back-ups maakt van afzonderlijke tabellen, kunt u een dergelijke back-up niet op tijd terugzetten naar een bekende positie (bijvoorbeeld om de replicatieslave in te richten), zelfs als u alle gegevens van de back-up zou herstellen. Nu we dit achter de rug hebben, gaan we verder.
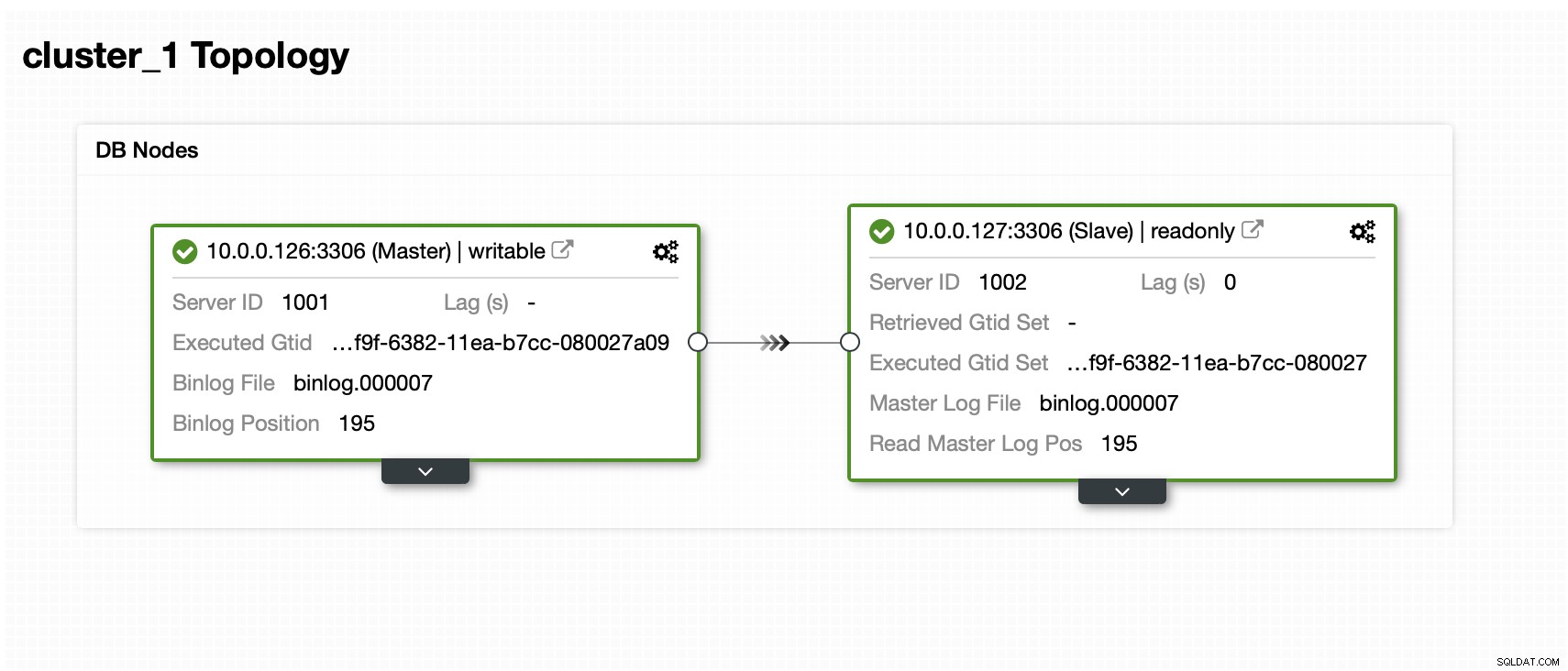
We hebben een meester en een slaaf:
Dataset bevat één schema en meerdere tabellen:
mysql> SHOW SCHEMAS;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sbtest |
| sys |
+--------------------+
5 rows in set (0.01 sec)
mysql> SHOW TABLES FROM sbtest;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest11 |
| sbtest12 |
| sbtest13 |
| sbtest14 |
| sbtest15 |
| sbtest16 |
| sbtest17 |
| sbtest18 |
| sbtest19 |
| sbtest2 |
| sbtest20 |
| sbtest21 |
| sbtest22 |
| sbtest23 |
| sbtest24 |
| sbtest25 |
| sbtest26 |
| sbtest27 |
| sbtest28 |
| sbtest29 |
| sbtest3 |
| sbtest30 |
| sbtest31 |
| sbtest32 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
32 rows in set (0.00 sec)Nu moeten we een back-up maken. Er zijn verschillende manieren waarop we dit probleem kunnen aanpakken. We kunnen gewoon een consistente back-up maken van de hele dataset, maar dit genereert een groot, enkel bestand met alle gegevens. Om de enkele tabel te herstellen, zouden we gegevens voor de tabel uit dat bestand moeten extraheren. Het is natuurlijk mogelijk, maar het is behoorlijk tijdrovend en het is vrijwel handmatige bewerking die kan worden gescript, maar als u niet over de juiste scripts beschikt, is het schrijven van ad-hoccode wanneer uw database niet beschikbaar is en u onder grote druk staat niet per se het veiligste idee.
In plaats daarvan kunnen we een back-up maken zodat elke tabel in een apart bestand wordt opgeslagen:
example@sqldat.com:~/backup# d=$(date +%Y%m%d) ; db='sbtest'; for tab in $(mysql -uroot -ppass -h127.0.0.1 -e "SHOW TABLES FROM ${db}" | grep -v Tables_in_${db}) ; do mysqldump --set-gtid-purged=OFF --routines --events --triggers ${db} ${tab} > ${d}_${db}.${tab}.sql ; doneHoud er rekening mee dat we --set-gtid-purged=OFF hebben ingesteld. We hebben het nodig als we deze gegevens later in de database willen laden. Anders zal MySQL proberen @@GLOBAL.GTID_PURGED in te stellen, wat hoogstwaarschijnlijk zal mislukken. MySQL zou net zo goed SET @@SESSION.SQL_LOG_BIN=0 instellen; wat zeker niet is wat we willen. Die instellingen zijn nodig als we een consistente back-up van de hele dataset willen maken en deze willen gebruiken om een nieuw knooppunt in te richten. In ons geval weten we dat het geen consistente back-up is en dat we er op geen enkele manier iets van kunnen herbouwen. Het enige wat we willen is een dump genereren die we op de master kunnen laden en deze naar slaves kunnen repliceren.
Dat commando genereerde een mooie lijst met sql-bestanden die geüpload kunnen worden naar het productiecluster:
example@sqldat.com:~/backup# ls -alh
total 605M
drwxr-xr-x 2 root root 4.0K Mar 18 14:10 .
drwx------ 9 root root 4.0K Mar 18 14:08 ..
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest10.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest11.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest12.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest13.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest14.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest15.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest16.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest17.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest18.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest19.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest1.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest20.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest21.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest22.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest23.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest24.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest25.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest26.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest27.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest28.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest29.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest2.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest30.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest31.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest32.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest3.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest4.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest5.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest6.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest7.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest8.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest9.sqlAls u de gegevens wilt herstellen, hoeft u alleen maar het SQL-bestand in het hoofdknooppunt te laden:
example@sqldat.com:~/backup# mysql -uroot -ppass sbtest < 20200318_sbtest.sbtest11.sqlDe gegevens worden in de database geladen en naar alle slaves gerepliceerd.
Hoe kan ik een enkele MySQL-tabel herstellen met ClusterControl?
Momenteel biedt ClusterControl geen gemakkelijke manier om slechts een enkele tabel te herstellen, maar het is nog steeds mogelijk om dit te doen met slechts een paar handmatige acties. Er zijn twee opties die u kunt gebruiken. Ten eerste, geschikt voor een klein aantal tabellen, kunt u in principe een schema maken waarin u een voor een gedeeltelijke back-ups van afzonderlijke tabellen uitvoert:
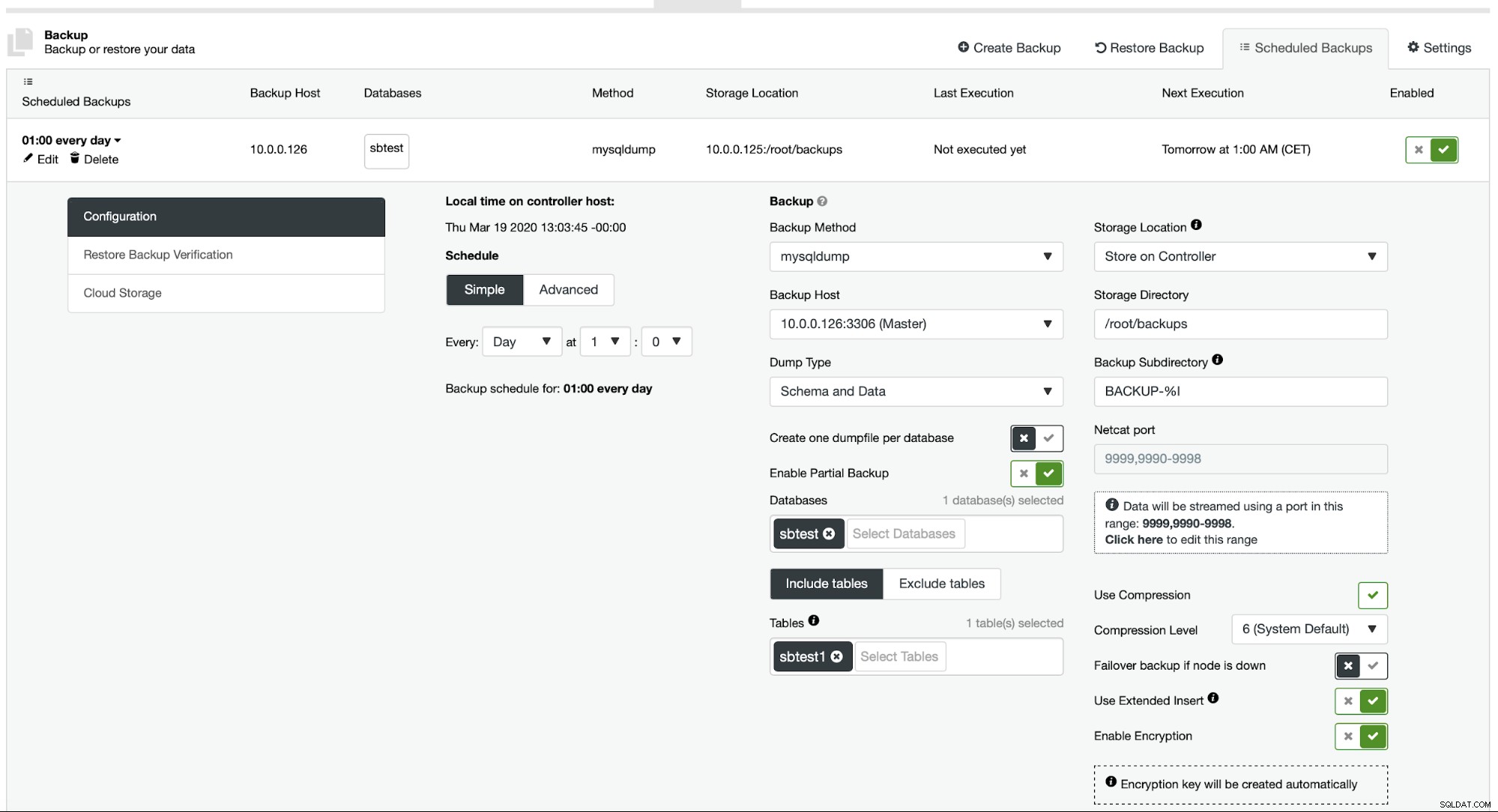
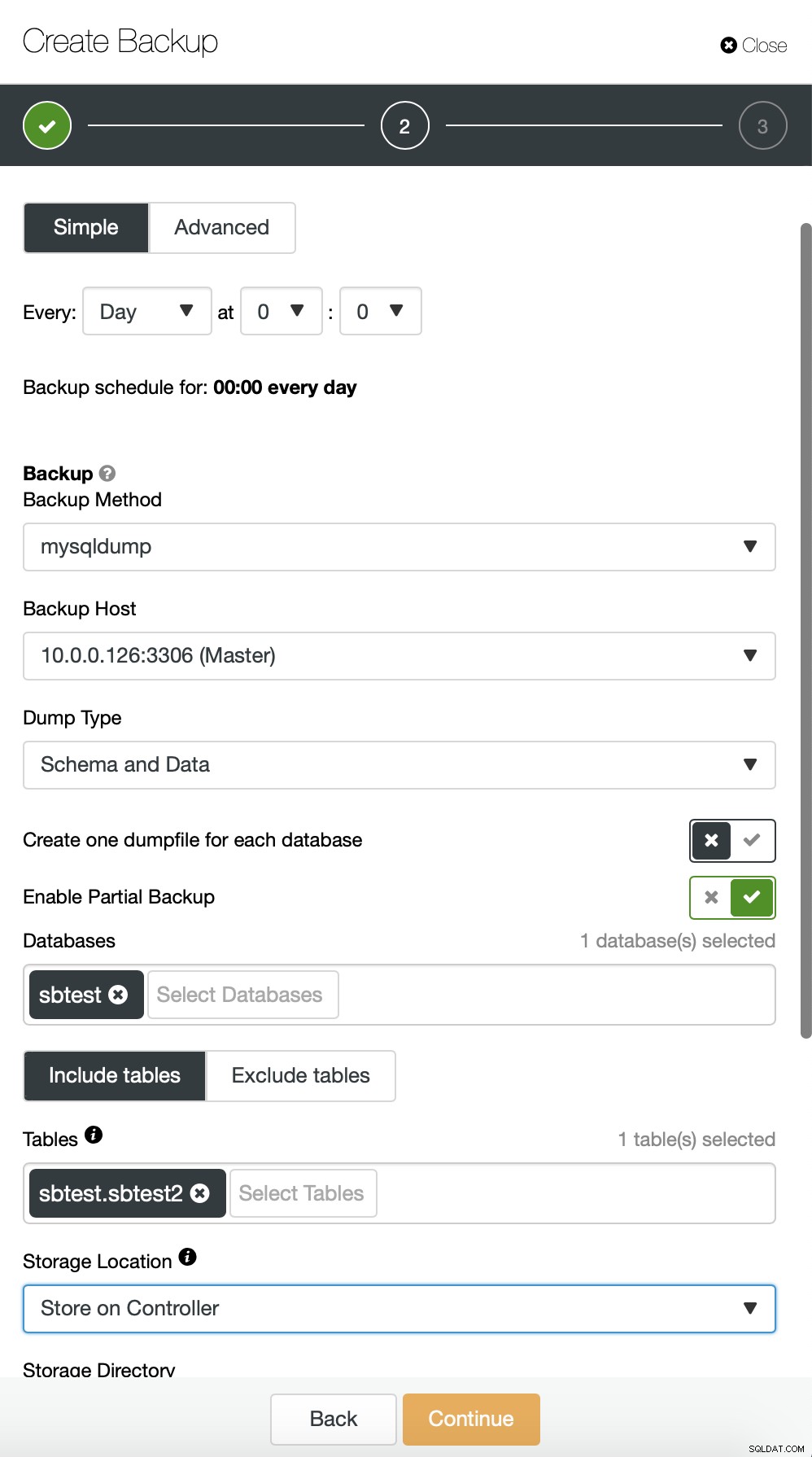
Hier maken we een back-up van de sbtest.sbtest1-tabel. We kunnen gemakkelijk een nieuwe back-up plannen voor de sbtest2-tabel:
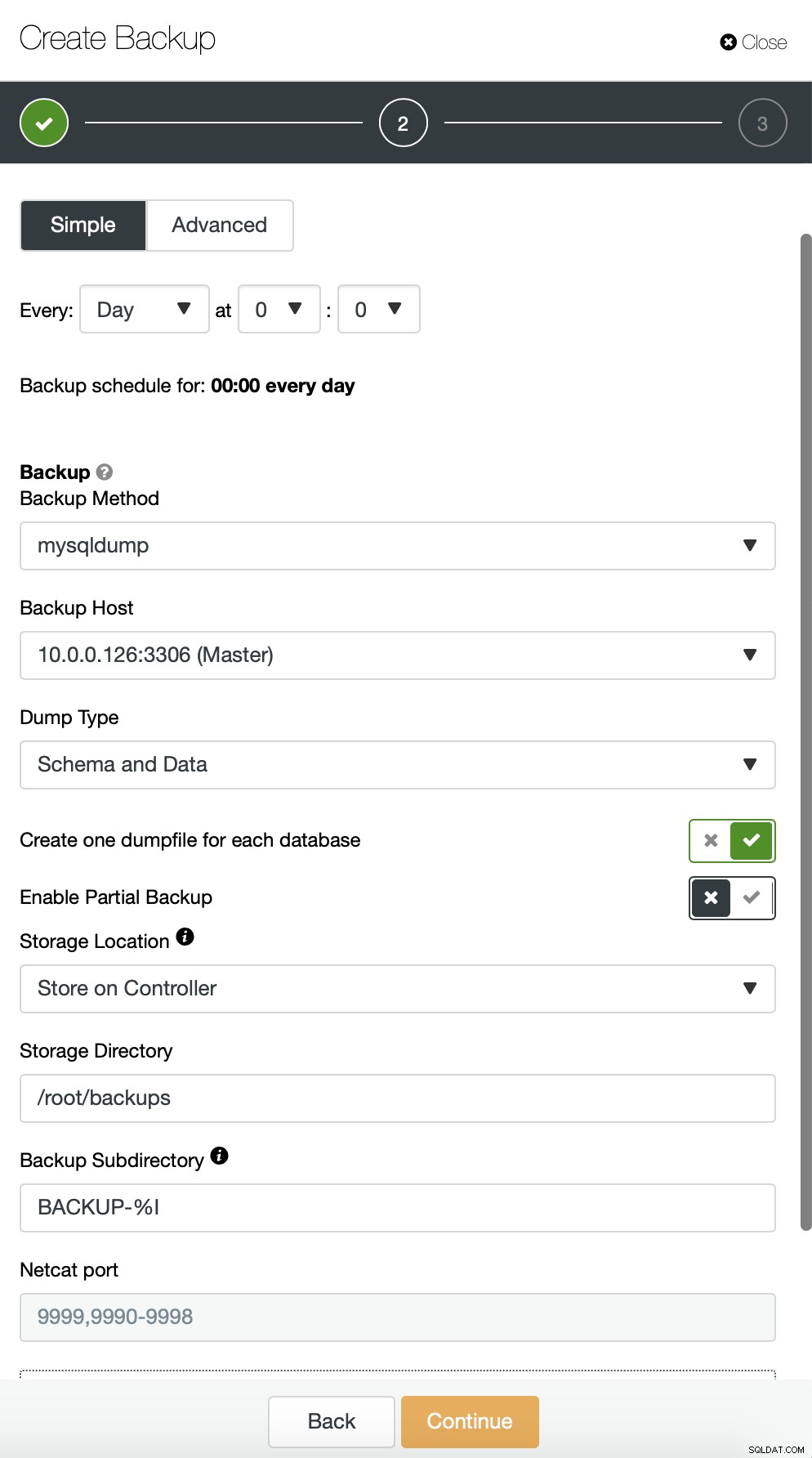
Als alternatief kunnen we een back-up maken en gegevens van een enkel schema in een apart bestand:
Nu kunt u de ontbrekende gegevens handmatig in het bestand vinden, herstellen deze back-up naar een aparte server of laat ClusterControl het doen:
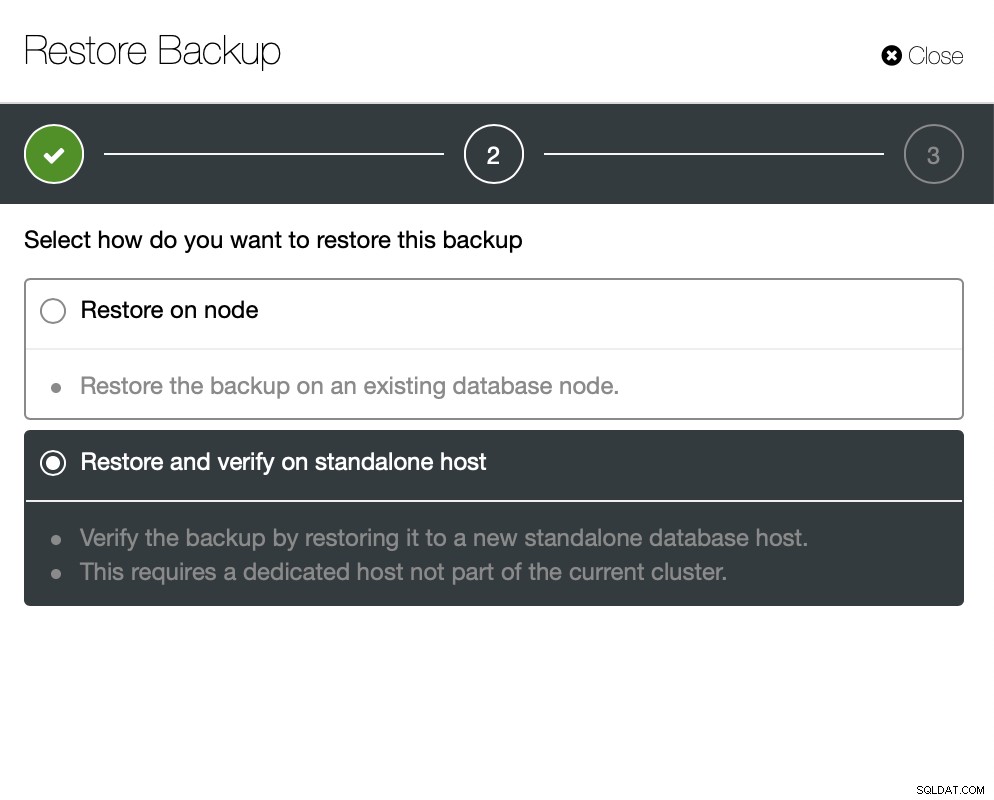
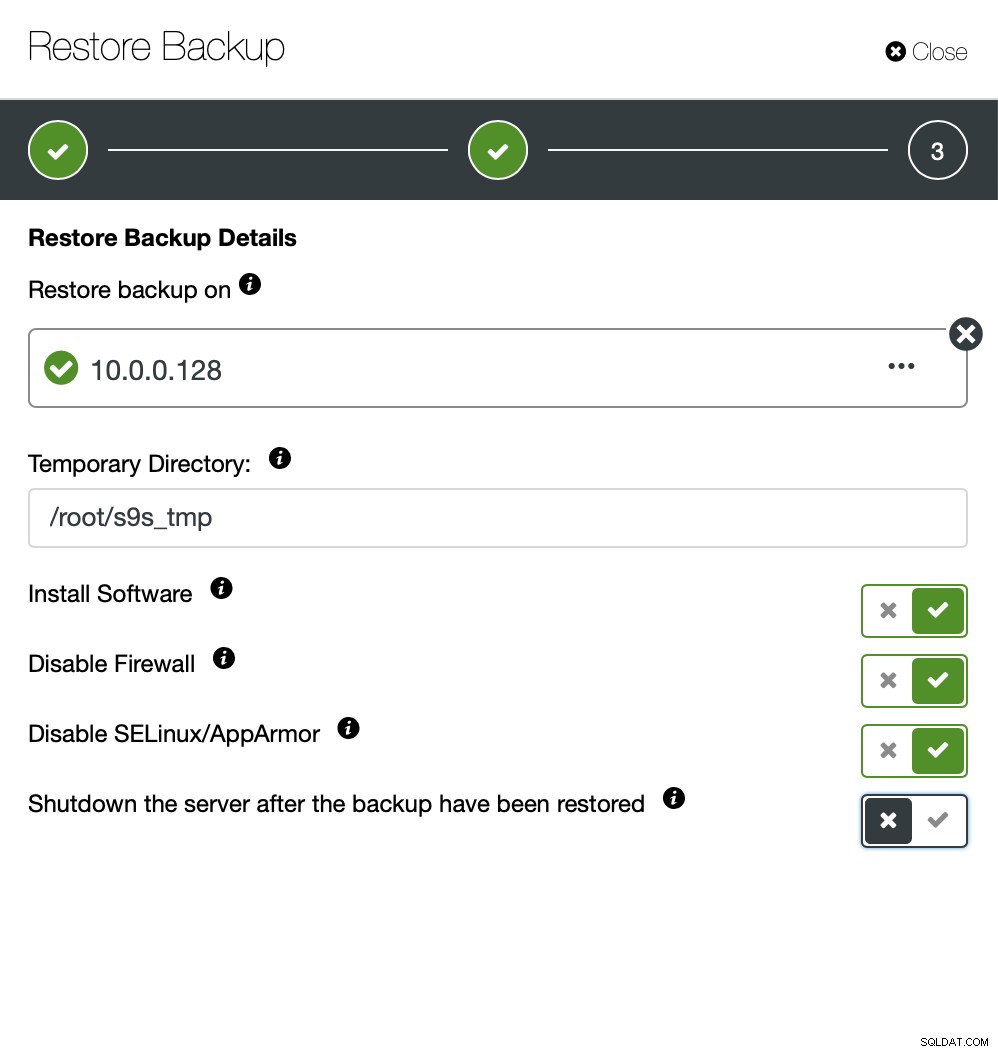
U houdt de server actief en u kunt de gegevens extraheren die u wilde herstellen met mysqldump of SELECT ... INTO OUTFILE. Dergelijke geëxtraheerde gegevens zijn klaar om te worden toegepast op het productiecluster.