Releasetests zijn doorgaans een van de stappen in het hele implementatieproces. Je schrijft de code, en dan verifieer je hoe deze zich gedraagt in een staging-omgeving, en ten slotte implementeer je de nieuwe code op de productie. Databases zijn intern voor elk soort applicatie en daarom is het belangrijk om te controleren hoe de databasegerelateerde wijzigingen de applicatie veranderen. Het is mogelijk om het op een aantal manieren te verifiëren; een van hen zou zijn om een speciale replica te gebruiken. Laten we eens kijken hoe het kan.
Natuurlijk wilt u niet dat dit proces handmatig is - het zou onderdeel moeten zijn van de CI/CD-processen van uw bedrijf. Afhankelijk van de exacte applicatie, omgeving en processen die je hebt, kun je replica's gebruiken die ad-hoc zijn gemaakt of replica's die altijd deel uitmaken van de database-omgeving.
De manier waarop Galera Cluster werkt, is dat het schemawijzigingen op een specifieke manier verwerkt. Het is mogelijk om een schemawijziging uit te voeren op een enkel knooppunt in het cluster, maar het is lastig, omdat het niet alle mogelijke schemawijzigingen ondersteunt, en het heeft invloed op de productie als er iets misgaat. Zo'n node zou volledig opnieuw opgebouwd moeten worden met behulp van SST, wat betekent dat een van de overgebleven Galera-nodes als donor zal moeten optreden en al zijn gegevens over het netwerk moet overdragen.
Een alternatief is het gebruik van een replica of zelfs een hele extra Galera-cluster die als replica fungeert. Het is duidelijk dat het proces moet worden geautomatiseerd om het in de ontwikkelingspijplijn te kunnen aansluiten. Er zijn veel manieren om dit te doen:scripts of talloze infrastructuur-orkestratietools zoals Ansible, Chef, Puppet of Salt-stack. We zullen ze niet in detail beschrijven, maar we willen graag dat je de stappen laat zien die nodig zijn om het hele proces goed te laten werken, en we laten de implementatie in een van de tools aan jou over.
Automatisering van releasetests
Allereerst willen we eenvoudig een nieuwe database kunnen implementeren. Het moet worden voorzien van de recente gegevens, en dit kan op veel manieren worden gedaan - u kunt de gegevens van de productiedatabase naar de testserver kopiëren; dat is het eenvoudigste om te doen. Als alternatief kunt u de meest recente back-up gebruiken - een dergelijke aanpak heeft extra voordelen van het testen van de back-upherstel. Back-upverificatie is een must-have in elke vorm van serieuze implementaties, en het opnieuw opbouwen van testopstellingen is een geweldige manier om te controleren of uw herstelproces werkt. Het helpt u ook om het herstelproces te timen. Als u weet hoe lang het duurt om uw back-up te herstellen, kunt u de situatie correct beoordelen in een scenario voor noodherstel.
Zodra de gegevens in de database zijn ingericht, kunt u dat knooppunt instellen als een replica van uw primaire cluster. Het heeft zijn voor- en nadelen. Als u al uw verkeer opnieuw zou kunnen uitvoeren naar het zelfstandige knooppunt, zou dat perfect zijn - in dat geval is het niet nodig om de replicatie in te stellen. Met sommige load balancers, zoals ProxySQL, kunt u het verkeer spiegelen en de kopie naar een andere locatie verzenden. Aan de andere kant is replicatie het beste alternatief. Ja, u kunt geen schrijfacties rechtstreeks op dat knooppunt uitvoeren, waardoor u moet plannen hoe u de query's opnieuw zult uitvoeren, omdat de eenvoudigste benadering van alleen maar antwoorden niet zal werken. Aan de andere kant zullen alle schrijfacties uiteindelijk via de SQL-thread worden uitgevoerd, dus je hoeft alleen maar te plannen hoe je met SELECT-query's omgaat.
Afhankelijk van de exacte wijziging, wil je misschien het schemawijzigingsproces testen. Schemawijzigingen zijn vrij gebruikelijk om uit te voeren en ze kunnen zelfs ernstige gevolgen hebben voor de prestaties van de database. Het is dus belangrijk om ze te verifiëren voordat ze in productie worden genomen. We willen kijken naar de tijd die nodig is om de wijziging uit te voeren en na te gaan of de wijziging afzonderlijk op knooppunten kan worden toegepast of nodig is om de wijziging tegelijkertijd op de hele topologie uit te voeren. Dit zal ons vertellen welk proces we moeten gebruiken voor een bepaalde schemawijziging.
ClusterControl gebruiken om de automatisering van de releasetests te verbeteren
ClusterControl wordt geleverd met een reeks functies die kunnen worden gebruikt om u te helpen bij het automatiseren van de releasetests. Laten we eens kijken naar wat het biedt. Om het duidelijk te maken, de functies die we gaan laten zien, zijn op een aantal manieren beschikbaar. De eenvoudigste manier is om de gebruikersinterface te gebruiken, maar het is niet nodig wat u wilt doen als u aan automatisering denkt. Er zijn nog twee manieren om dit te doen:Command Line Interface naar ClusterControl en RPC API. In beide gevallen kunnen taken worden geactiveerd vanuit externe scripts, zodat u ze kunt aansluiten op uw bestaande CI/CD-processen. Het zal u ook veel tijd besparen, aangezien het implementeren van het cluster slechts een kwestie kan zijn van het uitvoeren van één opdracht in plaats van het handmatig in te stellen.
Het testcluster implementeren
Eerst en vooral wordt ClusterControl geleverd met een optie om een nieuw cluster te implementeren en het te voorzien van de gegevens uit de bestaande database. Alleen al met deze functie kunt u de inrichting van de staging-server eenvoudig implementeren.
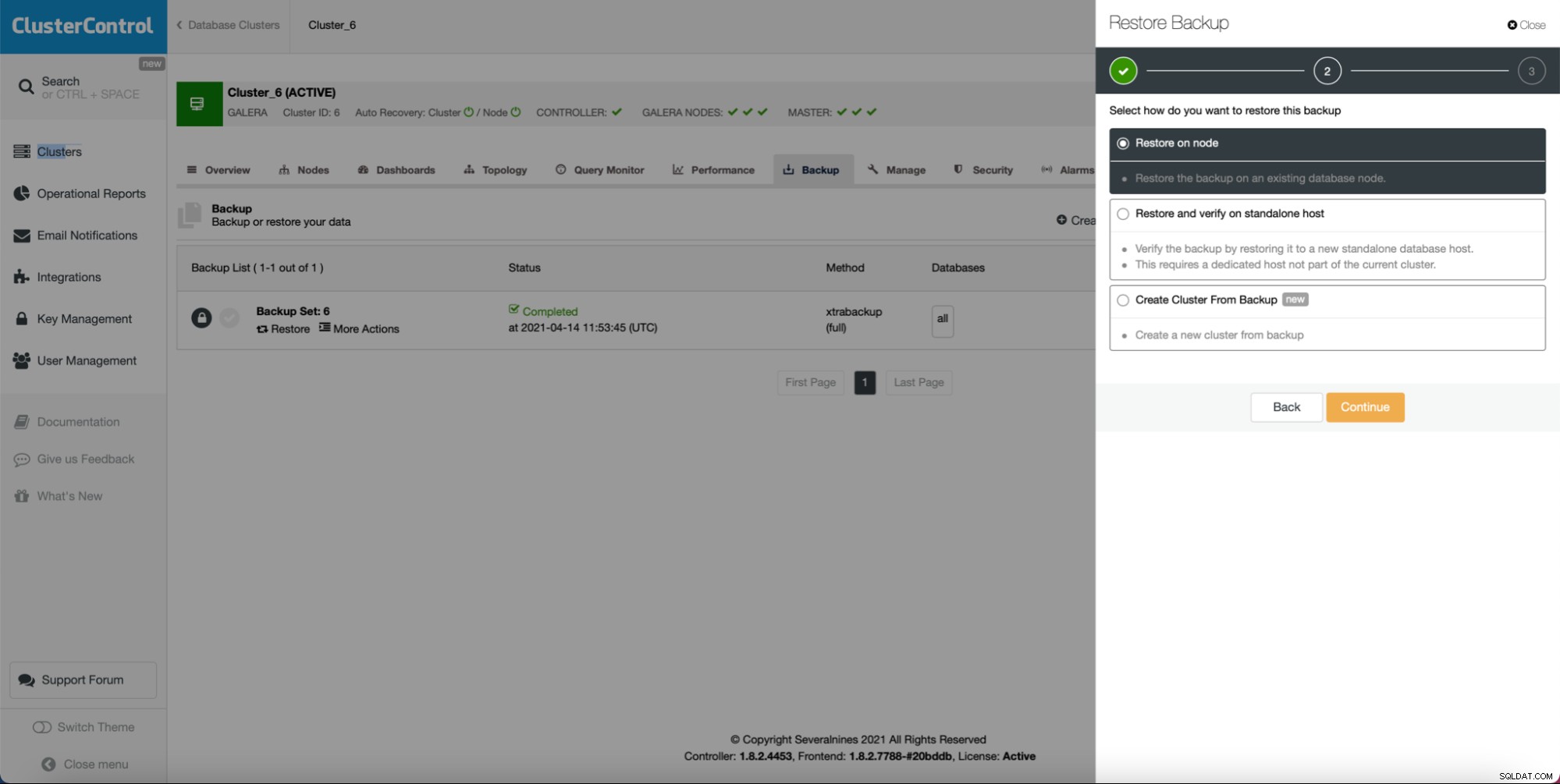
Zolang u een back-up hebt gemaakt, kan een nieuw cluster maken en inrichten met behulp van de gegevens van de back-up:
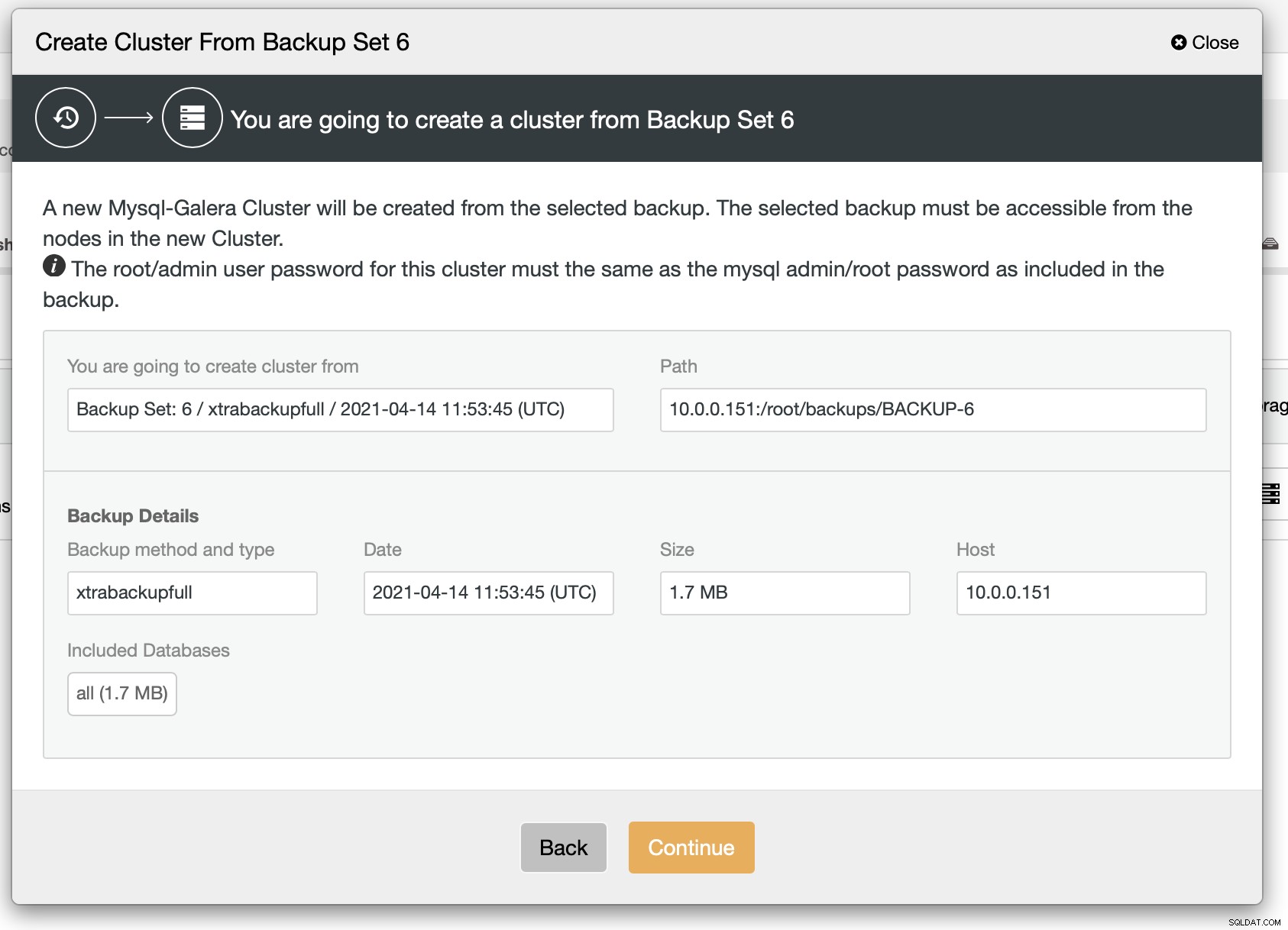
Zoals we kunnen zien, is er een korte samenvatting van wat er gaat gebeuren. Als u op Doorgaan klikt, gaat u verder.
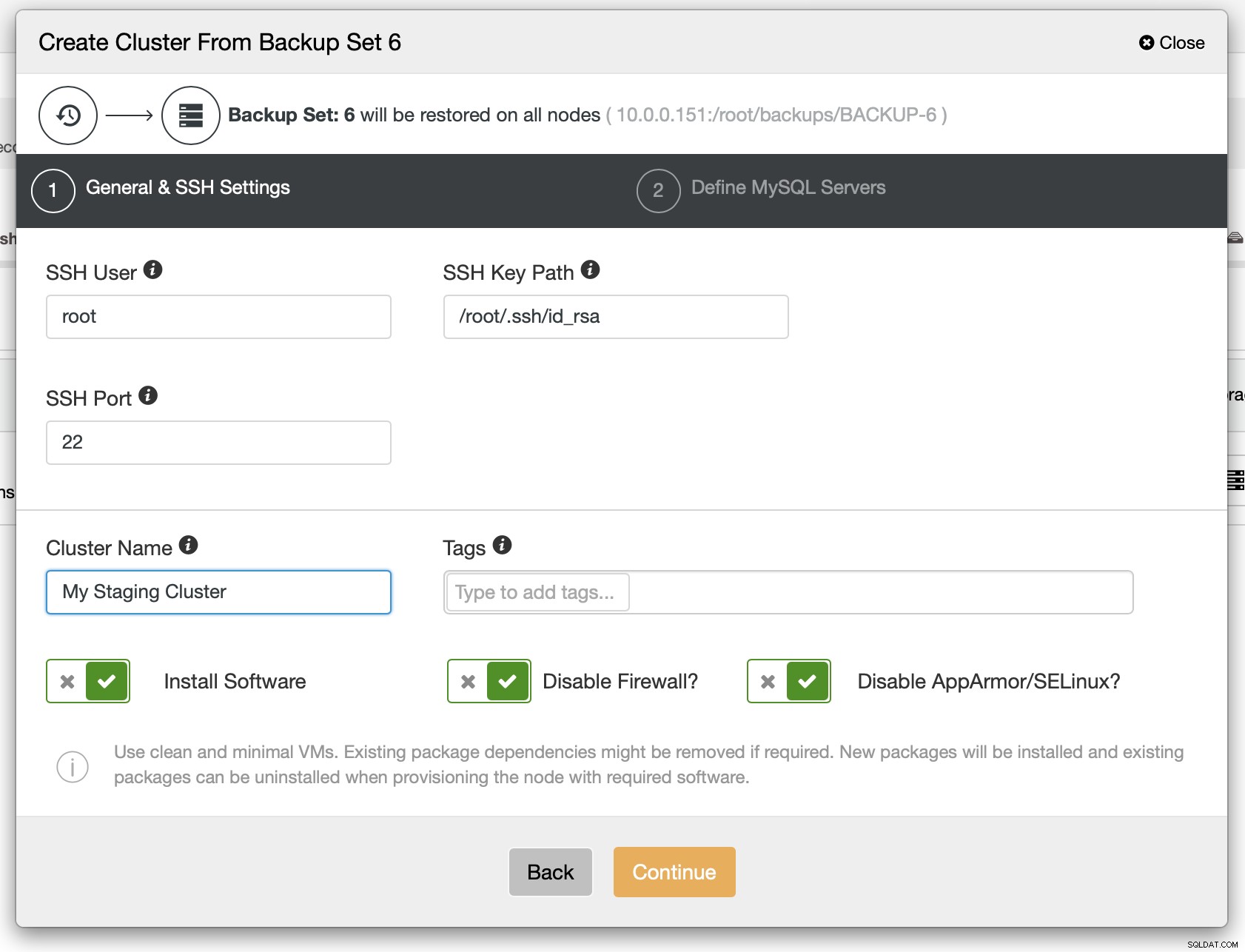
Als volgende stap moet u de SSH-connectiviteit definiëren - deze moet aanwezig zijn voordat ClusterControl de knooppunten kan implementeren.
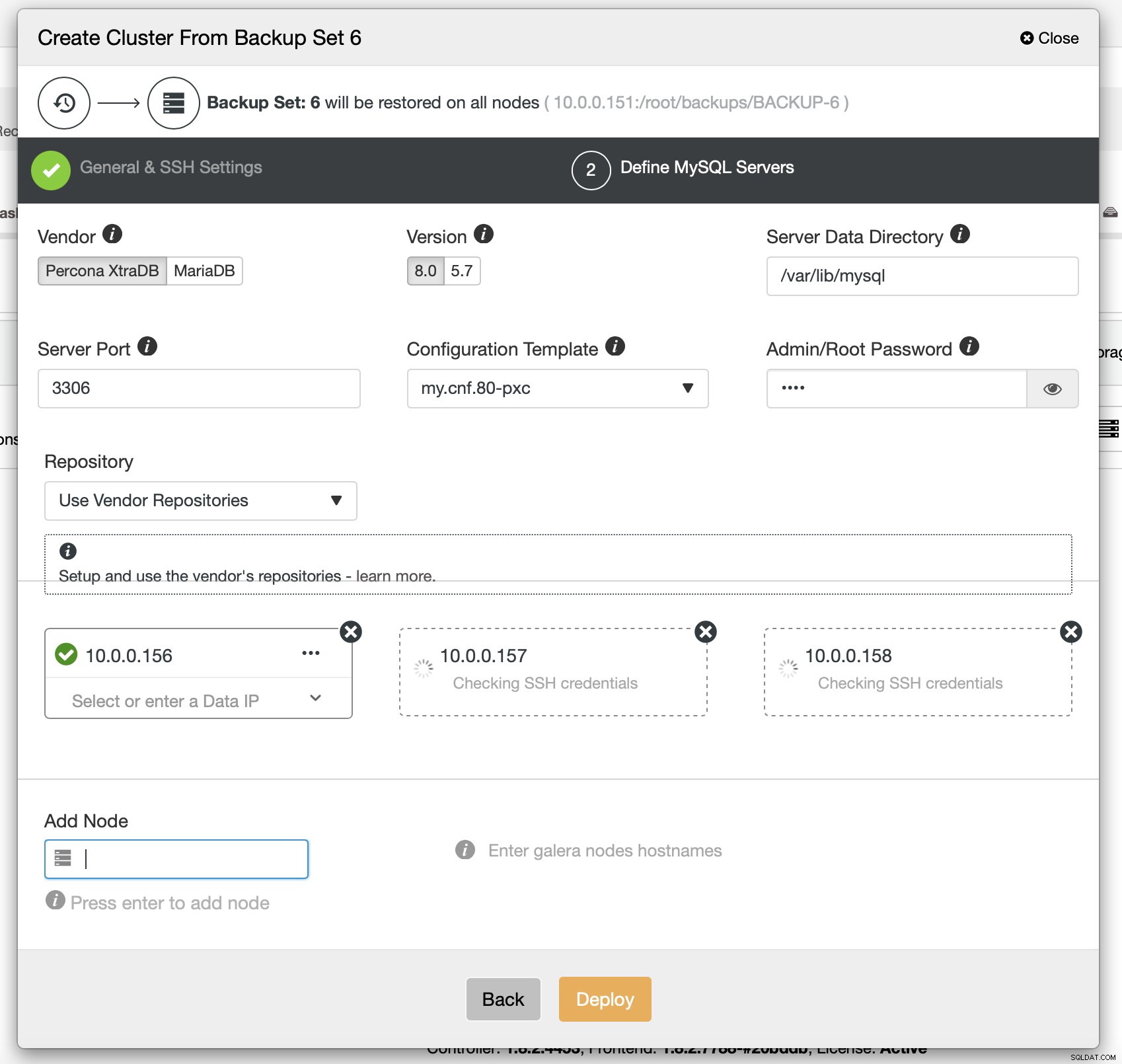
Ten slotte moet je (onder andere) de leverancier, versie en hostnamen kiezen van de nodes die je in het cluster wilt gebruiken. Dat is het gewoon.
Het CLI-commando dat hetzelfde zou bereiken ziet er als volgt uit:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6ProxySQL configureren om het verkeer te spiegelen
Als we een cluster hebben geïmplementeerd, willen we er misschien het productieverkeer naartoe sturen om te controleren hoe het nieuwe schema het bestaande verkeer verwerkt. Een manier om dit te doen is door ProxySQL te gebruiken.
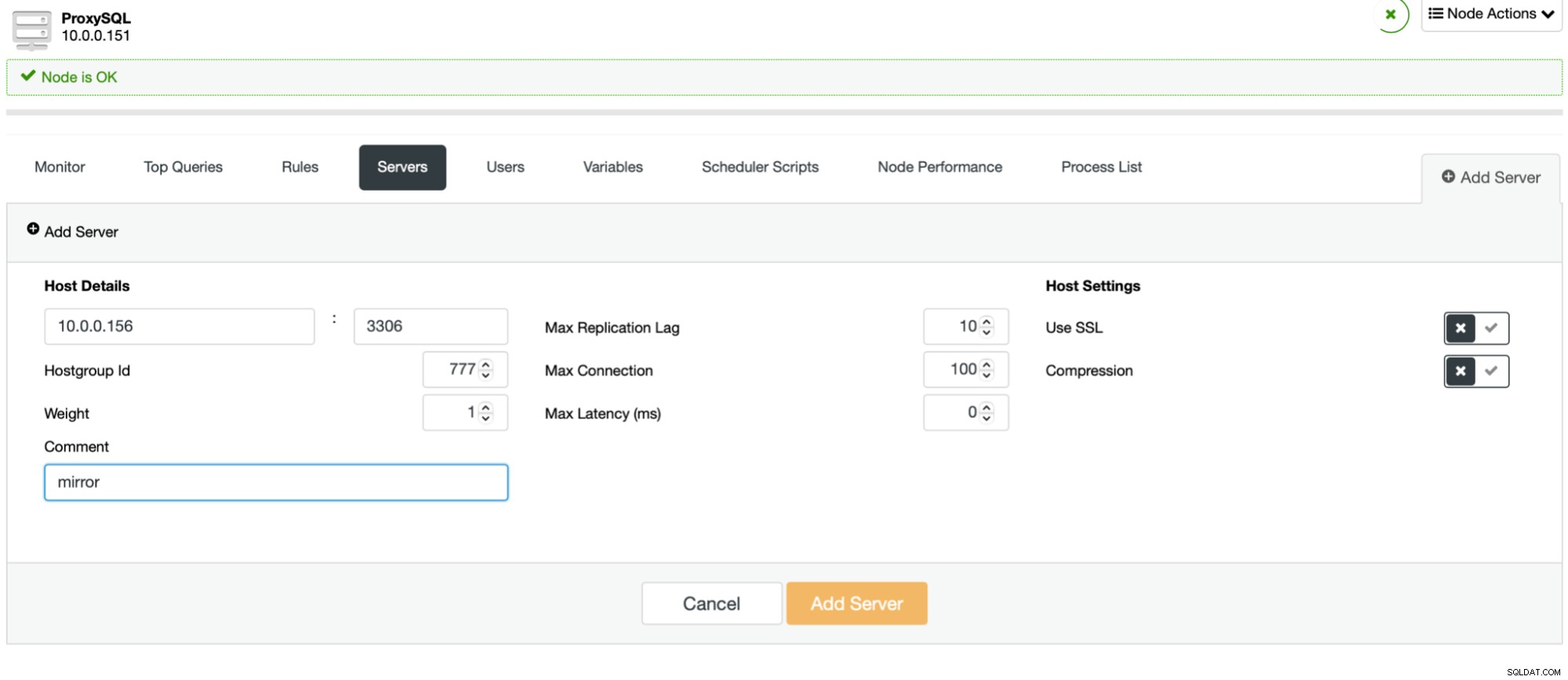
Het proces is eenvoudig. Eerst moet u de knooppunten toevoegen aan ProxySQL. Ze zouden tot een aparte hostgroep moeten behoren die nog niet in gebruik is. Zorg ervoor dat de ProxySQL-monitorgebruiker er toegang toe heeft.
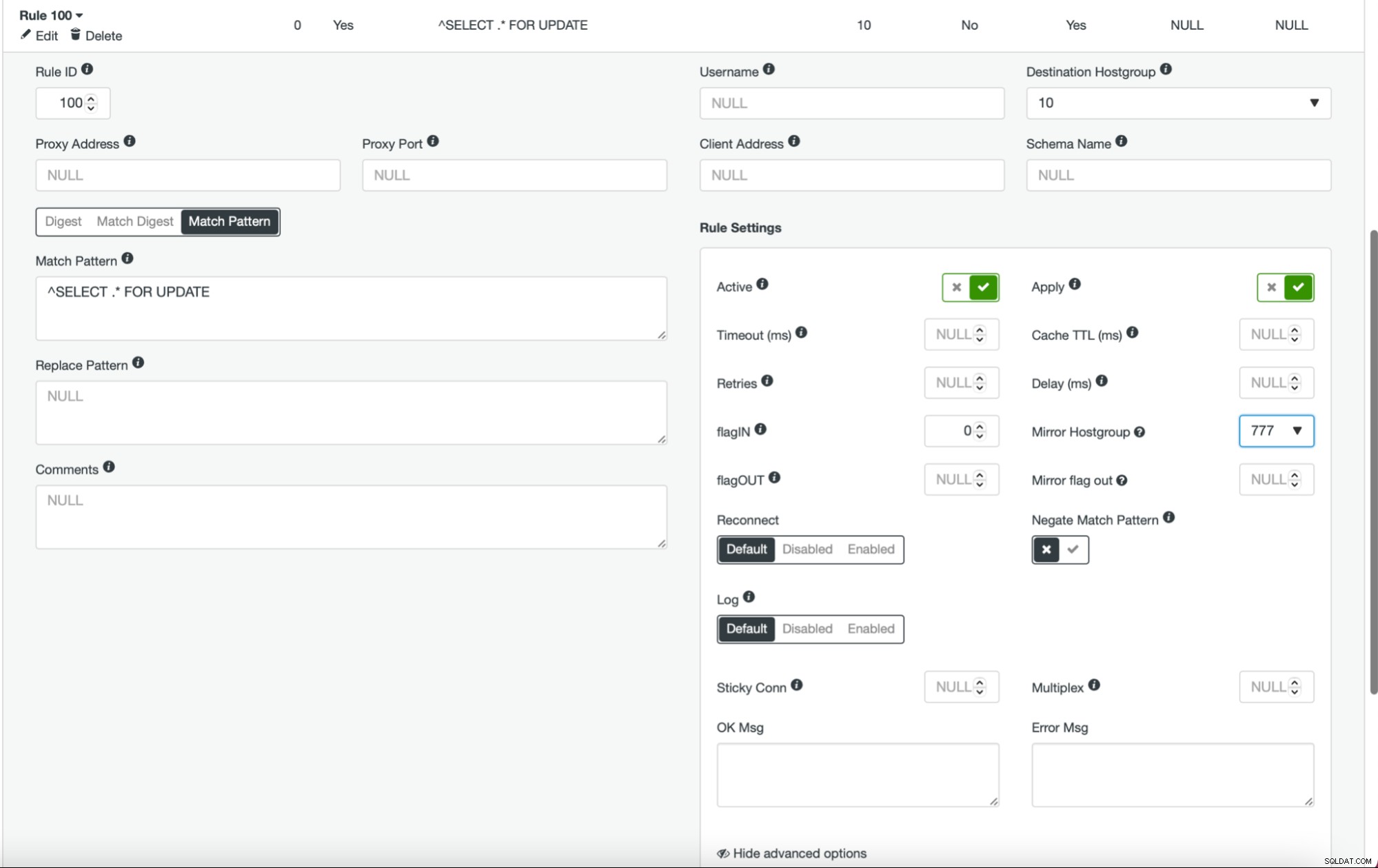
Zodra dit is gebeurd en u alle (of sommige) knooppunten in de hostgroep hebt geconfigureerd, kunt u de queryregels bewerken en de mirror-hostgroep definiëren (deze is beschikbaar in de geavanceerde opties). Als u dit voor al het verkeer wilt doen, wilt u waarschijnlijk al uw zoekregels op deze manier bewerken. Als u alleen SELECT-query's wilt spiegelen, moet u de juiste queryregels bewerken. Nadat dit is gebeurd, zou uw staging-cluster productieverkeer moeten gaan ontvangen.
Cluster inzetten als slaaf
Zoals we eerder hebben besproken, zou een alternatieve oplossing zijn om een nieuw cluster te maken dat zal fungeren als een replica van de bestaande installatie. Met een dergelijke aanpak kunnen we alle schrijfbewerkingen automatisch laten testen met behulp van de replicatie. SELECT's kunnen worden getest met behulp van de aanpak die we hierboven hebben beschreven - spiegelen via ProxySQL.
De implementatie van een slave-cluster is vrij eenvoudig.
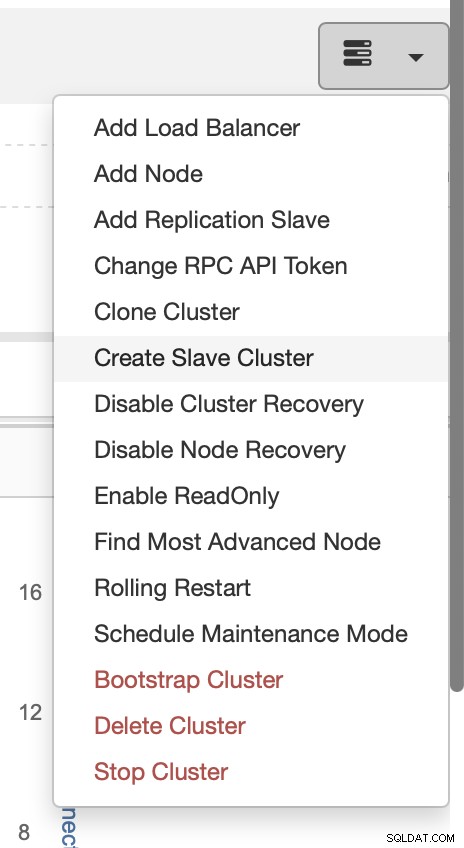
Kies de taak Slavecluster maken.
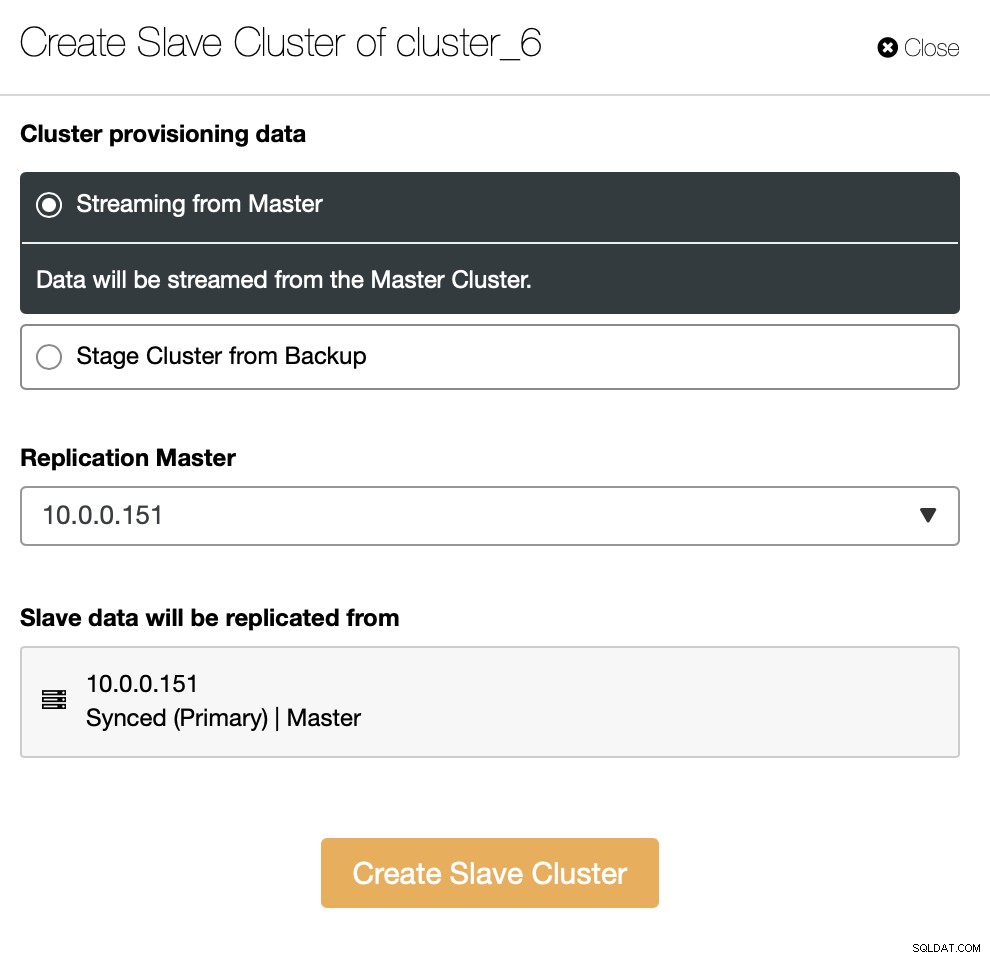
U moet beslissen hoe u de replicatie wilt instellen. U kunt alle gegevens van de master naar de nieuwe nodes laten overbrengen.
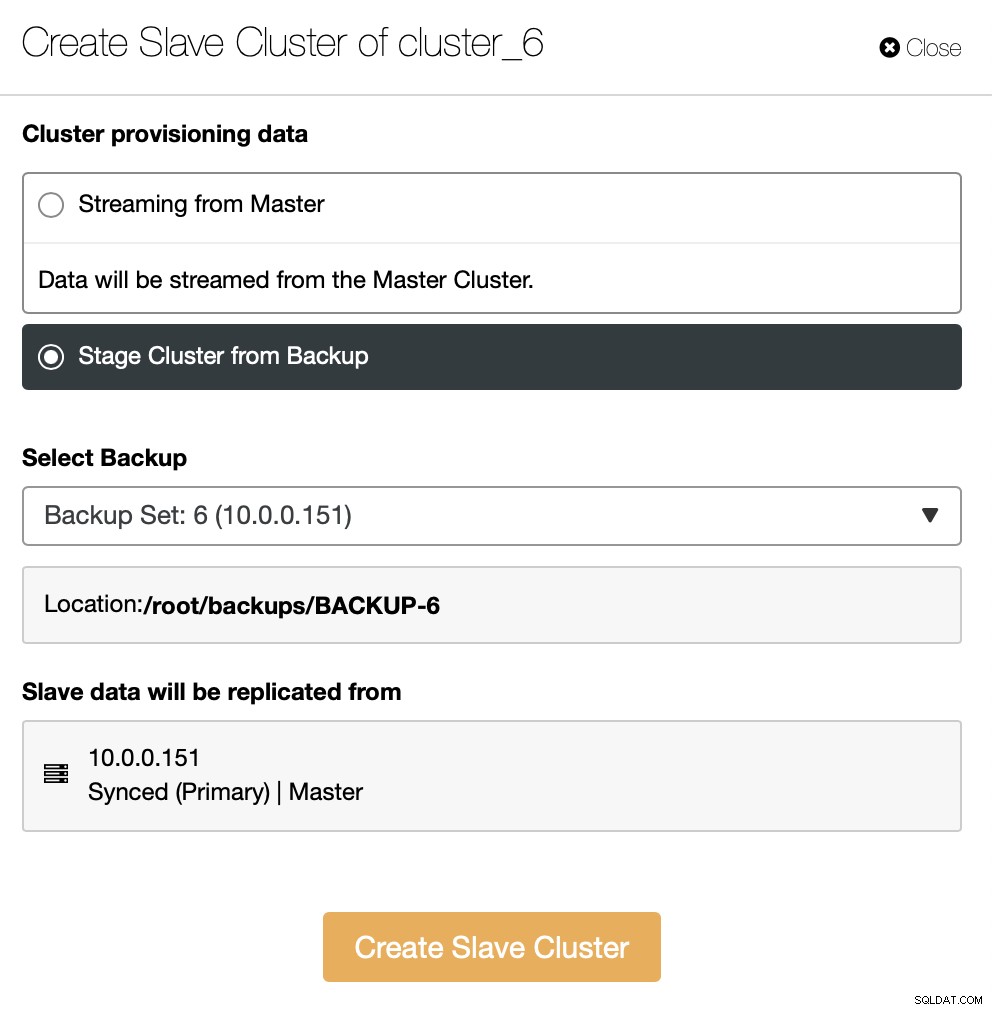
Als alternatief kunt u een bestaande back-up gebruiken om het nieuwe cluster in te richten. Dit zal helpen om de werklast op het hoofdknooppunt te verminderen - in plaats van alle gegevens over te dragen, hoeven alleen transacties te worden overgedragen die zijn uitgevoerd tussen het moment dat de back-up is gemaakt en het moment waarop de replicatie is ingesteld.
De rest is om de standaard implementatiewizard te volgen, die SSH-connectiviteit, versie, leverancier, hosts enzovoort definieert. Zodra het is geïmplementeerd, ziet u het cluster in de lijst.
Alternatieve oplossing voor de gebruikersinterface is om dit via RPC te doen.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Vooruit gaan
Als u meer wilt weten over de manieren waarop u uw processen kunt integreren met ClusterControl, verwijzen we u graag naar de documentatie, waar we een hele sectie hebben over het ontwikkelen van oplossingen waarbij ClusterControl een belangrijke rol speelt. belangrijke rol:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
We hopen dat je deze korte blog informatief en nuttig vond. Als u vragen heeft over de integratie van ClusterControl in uw omgeving, neem dan contact met ons op en we zullen ons best doen om u te helpen.