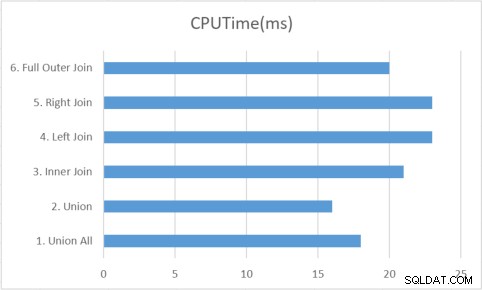
Union zal sneller zijn, omdat het simpelweg de eerste SELECT-instructie passeert en vervolgens de tweede SELECT-instructie ontleedt en de resultaten aan het einde van de uitvoertabel toevoegt.
De Join doorloopt elke rij van beide tabellen en vindt overeenkomsten in de andere tabel, waardoor er veel meer verwerking nodig is vanwege het zoeken naar overeenkomende rijen voor elke rij.
BEWERKEN
Met Union bedoel ik Union All omdat het voldoende leek voor wat je probeerde te bereiken. Hoewel een normale Union over het algemeen sneller is dan Join.
BEWERK 2 (Antwoord op de opmerking van @seebiscuit)
Ik ben het niet met hem eens. Technisch gezien, hoe goed je join ook is, een "JOIN" is nog steeds duurder dan een pure aaneenschakeling. Ik heb een blogpost gemaakt om het te bewijzen op mijn blog codePERF[dot]net . Praktisch gesproken dienen ze 2 totaal verschillende doelen en het is belangrijker om ervoor te zorgen dat uw indexering juist is en dat u de juiste tool voor de klus gebruikt.
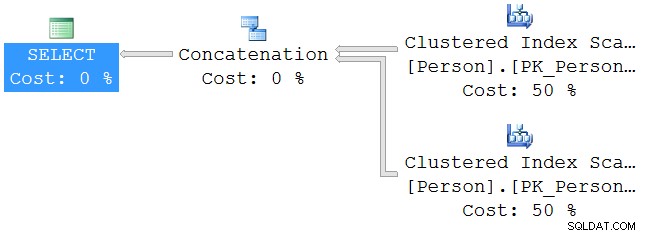
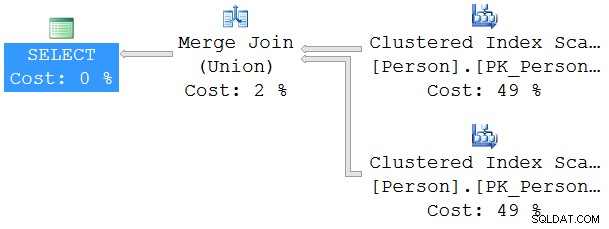
Technisch gezien denk ik dat het kan worden samengevat met behulp van de volgende 2 uitvoeringsplannen uit mijn blogpost:
UNION ALL Uitvoeringsplan
JOIN Uitvoeringsplan
Praktische resultaten
Praktisch gesproken is het verschil bij het opzoeken van een geclusterde index te verwaarlozen: