Bij het werken met namen van personen en het zoeken naar vage zoekopdrachten, werkte het voor mij om een tweede tabel met woorden te maken. Maak ook een derde tabel die een intersectietabel is voor de veel-op-veel-relatie tussen de tabel die de tekst bevat en de woordtabel. Wanneer een rij aan de teksttabel wordt toegevoegd, splitst u de tekst in woorden en vult u de intersectietabel op de juiste manier, waarbij u zo nodig nieuwe woorden aan de woordtabel toevoegt. Als deze structuur eenmaal op zijn plaats is, kun je iets sneller opzoeken, omdat je alleen je damlev-functie hoeft uit te voeren over de tabel met unieke woorden. Met een simpele join krijg je de tekst met de overeenkomende woorden. 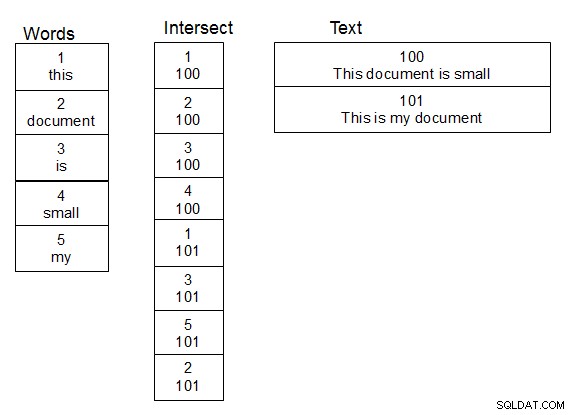
Een zoekopdracht voor een overeenkomst met één woord ziet er ongeveer zo uit:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
en twee woorden zouden er zo uitzien (uit mijn hoofd, dus misschien niet helemaal correct):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
De voordelen hier, ten koste van wat databaseruimte, is dat je alleen de tijdrovende damlev-functie hoeft toe te passen op de unieke woorden, die waarschijnlijk maar tienduizenden zullen bedragen, ongeacht de grootte van je teksttabel. Dit is van belang, omdat de damlev UDF geen indexen gebruikt - het scant de hele tabel waarop het is toegepast om een waarde voor elke rij te berekenen. Alleen de unieke woorden scannen zou veel sneller moeten gaan. Het andere voordeel is dat de damlev op woordniveau wordt toegepast, wat lijkt te zijn waar je om vraagt. Een ander voordeel is dat u de zoekopdracht kunt uitbreiden om zoeken op meerdere woorden te ondersteunen, en de resultaten kunt rangschikken door de overeenkomende kruisende rijen op TextId te groeperen en te rangschikken op het aantal overeenkomsten.