Dit is de manier waarop ik de database zou ontwerpen:
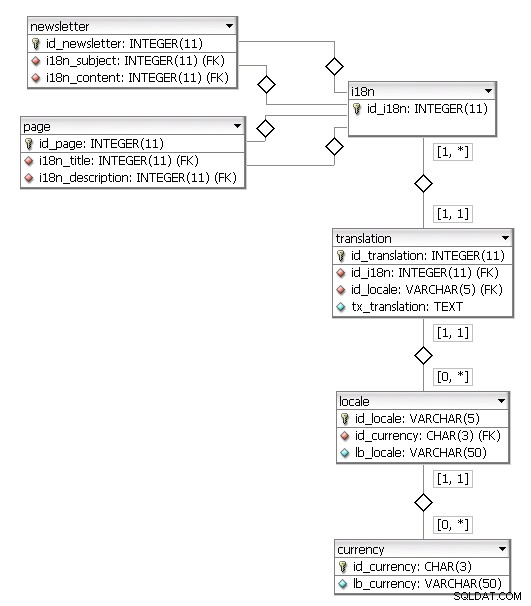
Visualisatie door DB Designer Fork
De i18n tabel bevat alleen een PK, zodat elke tabel alleen naar deze PK hoeft te verwijzen om een veld te internationaliseren. De tabel translation is dan verantwoordelijk voor het koppelen van deze generieke ID aan de juiste lijst met vertalingen.
locale.id_locale is een VARCHAR(5) om beide en . te beheren en en_US ISO-syntaxis
.
currency.id_currency is een CHAR(3) om de ISO 4217-syntaxis
te beheren .
Je kunt twee voorbeelden vinden:page en newsletter . Beide door de beheerder beheerde entiteiten moeten hun velden internationaliseren, respectievelijk title/description en subject/content .
Hier is een voorbeeldvraag:
select
t_subject.tx_translation as subject,
t_content.tx_translation as content
from newsletter n
-- join for subject
inner join translation t_subject
on t_subject.id_i18n = n.i18n_subject
-- join for content
inner join translation t_content
on t_content.id_i18n = n.i18n_content
inner join locale l
-- condition for subject
on l.id_locale = t_subject.id_locale
-- condition for content
and l.id_locale = t_content.id_locale
-- locale condition
where l.id_locale = 'en_GB'
-- other conditions
and n.id_newsletter = 1
Merk op dat dit een genormaliseerd datamodel is. Als je een enorme dataset hebt, zou je misschien kunnen nadenken over denormalisatie ervan om uw zoekopdrachten te optimaliseren. Je kunt ook met indexen spelen om de queryprestaties te verbeteren (in sommige DB worden externe sleutels automatisch geïndexeerd, bijv. MySQL/InnoDB ).