Hier is hoe deze twee benaderingen fysiek in de database worden weergegeven:
Laten we beide benaderingen analyseren...
Benadering 1 (beide richtingen opgeslagen in de tabel):
- PRO:eenvoudigere zoekopdrachten.
- CON:Gegevens kunnen beschadigd raken door alleen in te voegen/bijwerken/verwijderen één richting.
- MINOR PRO:vereist geen extra beperkingen om ervoor te zorgen dat een vriendschap niet kan worden gedupliceerd.
- Verdere analyse nodig:
- TIE:één index omslagen beide richtingen, dus je hebt geen secundaire index nodig.
- TIE:opslagvereisten.
- TIE:Prestaties.
Benadering 2 (slechts één richting opgeslagen in de tabel):
- CON:Ingewikkeldere zoekopdrachten.
- PRO:De gegevens kunnen niet worden beschadigd door te vergeten de tegenovergestelde richting uit te voeren, aangezien er geen tegenovergestelde richting is .
- MINOR CON:vereist
CHECK(UID < FriendID), dus eenzelfde vriendschap kan nooit op twee verschillende manieren worden weergegeven, en de sleutel op(UID, FriendID)kan zijn werk doen. - Verdere analyse nodig:
- TIE:Er zijn twee indexen nodig om dekking
beide richtingen van zoekopdrachten (samengestelde index op
{UID, FriendID}en samengestelde index op{FriendID, UID}). - TIE:opslagvereisten.
- TIE:Prestaties.
- TIE:Er zijn twee indexen nodig om dekking
beide richtingen van zoekopdrachten (samengestelde index op
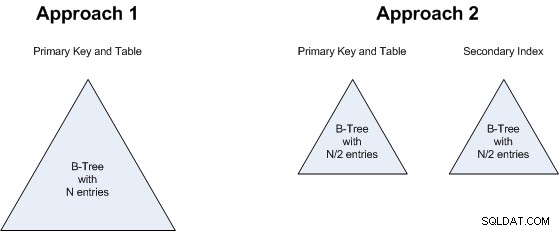
Het punt 1 is van bijzonder belang. MySQL/InnoDB altijd clusters gegevens en secundaire indexen kunnen duur zijn in geclusterde tabellen (zie "Nadelen van clustering" in dit artikel ), dus het lijkt misschien alsof de secundaire index in benadering 2 alle voordelen van minder rijen zou opeten. Echter , de secundaire index bevat exact dezelfde velden als de primaire (alleen in de tegenovergestelde volgorde), dus er is in dit specifieke geval geen opslagoverhead. Er is ook geen verwijzing naar table heap (aangezien er geen table heap is), dus het is qua opslag waarschijnlijk zelfs goedkoper dan een normale op heap gebaseerde index. En ervan uitgaande dat de query wordt gedekt door de index, zal er ook geen dubbele zoekopdracht zijn die normaal gesproken wordt geassocieerd met een secundaire index in een geclusterde tabel. Dit is dus eigenlijk een gelijkspel (noch benadering 1 noch benadering 2 heeft een significant voordeel).
Het punt 2 houdt verband met punt 1:het maakt niet uit of we een B-boom met N-waarden hebben of twee B-bomen, elk met N/2-waarden. Dit is dus ook een gelijkspel:beide benaderingen zullen ongeveer dezelfde hoeveelheid opslagruimte gebruiken.
Dezelfde redenering is van toepassing op punt 3 :of we nu één grotere B-Tree zoeken of 2 kleinere, maakt niet zoveel uit, dus ook dit is gelijkspel.
Dus, voor de robuustheid, en ondanks wat lelijkere vragen en een behoefte aan extra CHECK , ik zou voor benadering 2 gaan.