Wilde inspringen met de optie om uw taak op te lossen met pure BigQuery (standaard SQL)
Vereisten/aannames :brongegevens bevinden zich in sandbox.temp.id1_id2_pairs
U moet dit vervangen door uw eigen of als u wilt testen met dummy-gegevens van uw vraag - u kunt deze tabel maken zoals hieronder (vervang natuurlijk sandbox.temp met uw eigen project.dataset )
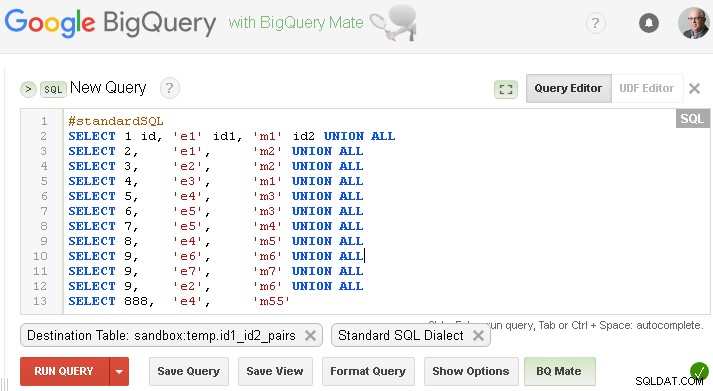
Zorg ervoor dat u de respectievelijke bestemmingstabel instelt
Opmerking :je kunt alle respectievelijke zoekopdrachten (als tekst) onderaan dit antwoord vinden, maar voor nu illustreer ik mijn antwoord met screenshots - zodat alles wordt gepresenteerd - vraag, resultaat en gebruikte opties
Er zijn dus drie stappen:
Stap 1 - Initialisatie
Hier doen we gewoon de eerste groepering van id1 op basis van verbindingen met id2:
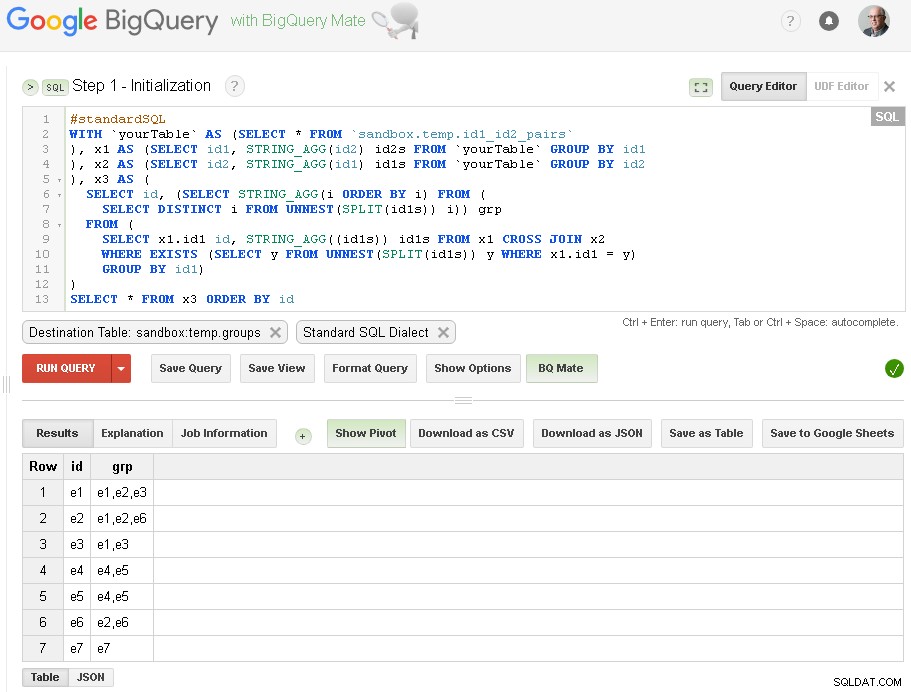
Zoals je hier kunt zien, hebben we een lijst gemaakt met alle id1-waarden met respectieve verbindingen op basis van een eenvoudige verbinding op één niveau via id2
Uitvoertabel is sandbox.temp.groups
Stap 2 - Iteraties groeperen
In elke iteratie zullen we groepering verrijken op basis van reeds bestaande groepen.
Bron van query is uitvoertabel van vorige stap (sandbox.temp.groups ) en Bestemming is dezelfde tabel (sandbox.temp.groups ) met Overschrijven
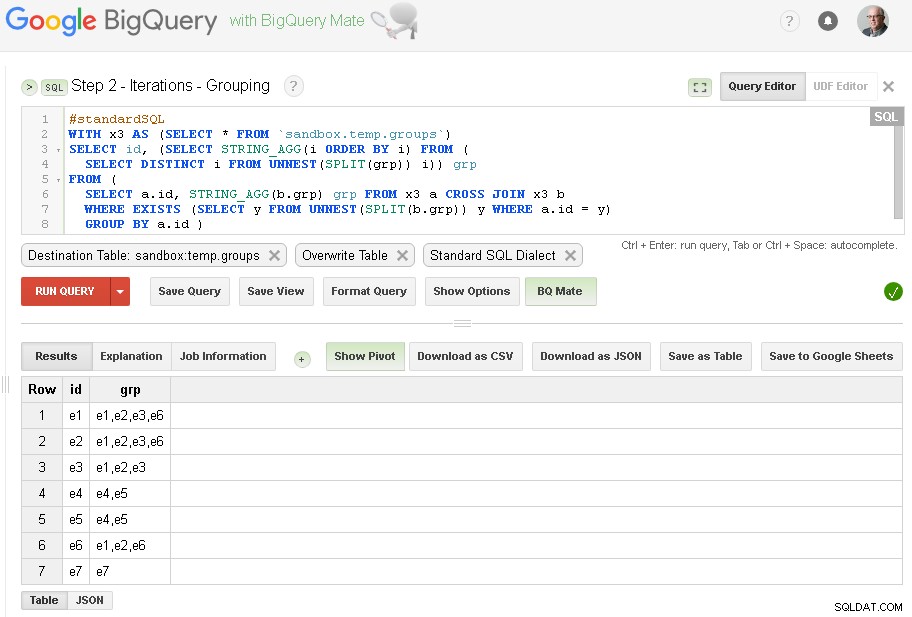
We zullen doorgaan met iteraties tot wanneer het aantal gevonden groepen hetzelfde zal zijn als in de vorige iteratie
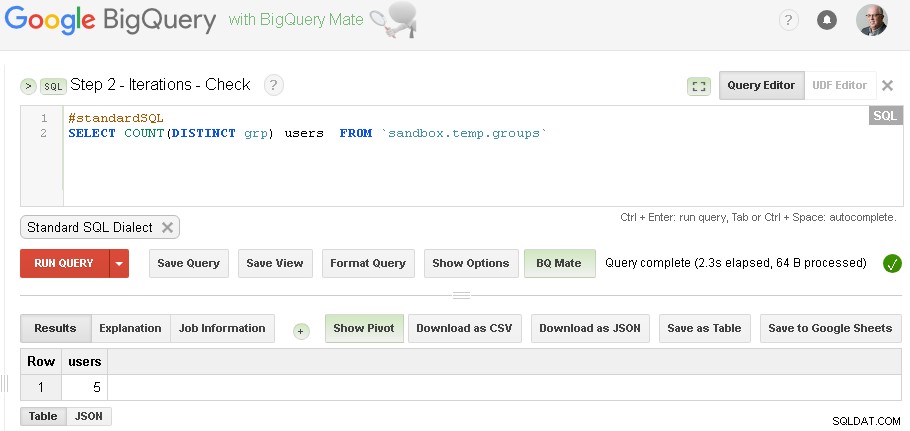
Opmerking :u kunt gewoon twee BigQuery Web UI-tabbladen openen (zoals hierboven wordt weergegeven) en zonder enige code te wijzigen, hoeft u alleen maar Grouping uit te voeren en vervolgens keer op keer te controleren totdat iteratie convergeert
(voor specifieke gegevens die ik heb gebruikt in het gedeelte met vereisten - ik had drie iteraties - de eerste iteratie produceerde 5 gebruikers, de tweede iteratie produceerde 3 gebruikers en de derde iteratie produceerde opnieuw 3 gebruikers - wat aangaf dat we klaar waren met iteraties.
Natuurlijk, in het echte leven - het aantal iteraties kan meer zijn dan slechts drie - dus we hebben een soort automatisering nodig (zie de respectievelijke sectie onderaan het antwoord).
Stap 3 – Definitieve groepering
Als de id1-groepering is voltooid, kunnen we de definitieve groepering voor id2 toevoegen
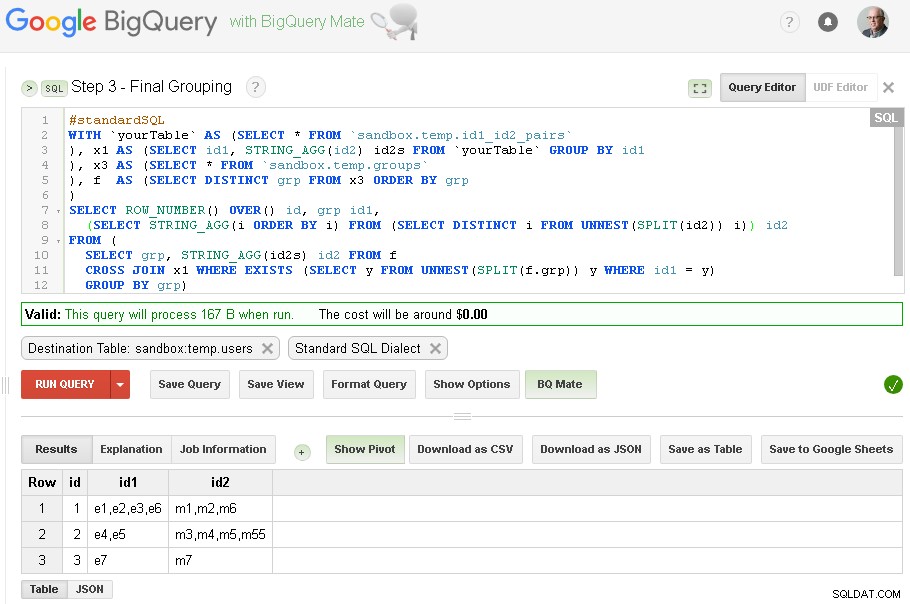
Het eindresultaat staat nu in sandbox.temp.users tafel
Gebruikte zoekopdrachten (vergeet niet om de respectievelijke bestemmingstabellen in te stellen en indien nodig te overschrijven volgens de hierboven beschreven logica en screenshots):
Vereisten:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Stap 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Stap 2 - Groeperen
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Stap 2 - Controleer
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Stap 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automatisering :
Natuurlijk kan het bovenstaande "proces" handmatig worden uitgevoerd in het geval dat iteraties snel convergeren - je krijgt dus 10-20 runs. Maar in meer praktijkgevallen kunt u dit eenvoudig automatiseren met elke client
naar keuze