Uw vraag is echt onnauwkeurig. Volg alstublieft de suggesties van @RiggsFolly en lees de referenties over hoe u een goede vraag kunt stellen.
Ook, zoals voorgesteld door @DuduMarkovitz, moet u beginnen met het vereenvoudigen van het probleem en het opschonen van uw gegevens. Een paar bronnen om u op weg te helpen:
- Basishandleiding voor tekstverwerking door Matt Deny
- Verwerking en verwerking van strings in R door Gaston Sánchez
Als u tevreden bent met de resultaten, kunt u verder gaan met het identificeren van een groep voor elke Var1 invoer (dit zal u op weg helpen om verdere analyses / manipulaties uit te voeren op vergelijkbare invoer) Dit kan op veel verschillende manieren worden gedaan, maar zoals vermeld door @GordonLinoff, is een mogelijkheid de Levenshtein-afstand.
Opmerking :voor 50K inzendingen zal het resultaat niet 100% nauwkeurig zijn omdat het niet altijd categoriseer de termen in de juiste groep, maar dit zou de handmatige inspanningen aanzienlijk moeten verminderen.
In R zou je dit kunnen doen met adist()
Uw voorbeeldgegevens gebruiken:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
Voor deze kleine steekproef kun je de 3 verschillende groepen zien (de clusters van lage Levensthein Distance-waarden) en deze gemakkelijk handmatig toewijzen, maar voor grotere sets heb je waarschijnlijk een clusteralgoritme nodig.
Ik heb je in de reacties al gewezen op een van mijn vorige antwoord
laat zien hoe je dit doet met hclust() en de minimale variantiemethode van de Ward, maar ik denk dat je hier beter andere technieken kunt gebruiken (een van mijn favoriete bronnen over dit onderwerp voor een snel overzicht van enkele van de meest gebruikte methoden in R is deze gedetailleerd antwoord
)
Hier is een voorbeeld waarin affiniteitspropagatieclustering wordt gebruikt:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
U vindt in het APResult-object d_ap de elementen die bij elke cluster horen en het optimale aantal clusters, in dit geval:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
U kunt ook een visuele weergave zien:
> heatmap(d_ap, margins = c(10, 10))
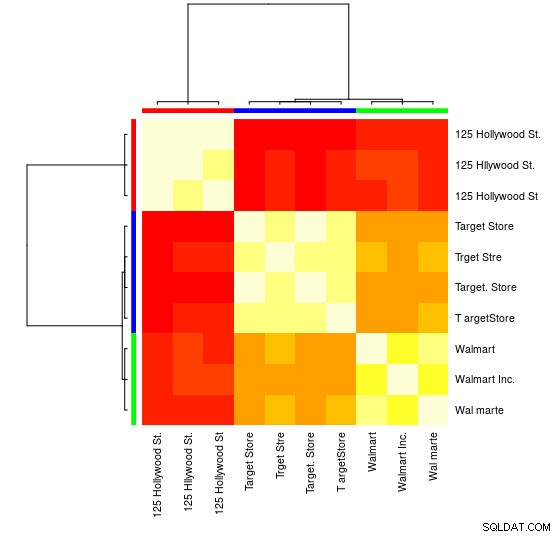
Vervolgens kunt u voor elke groep verdere manipulaties uitvoeren. Als voorbeeld gebruik ik hier hunspell om elk afzonderlijk woord op te zoeken van Var1 in een en_US woordenboek voor spelfouten en probeer binnen elke group , welke id bevat geen spelfouten (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Wat geeft:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Opmerking :Aangezien we hier geen tekstverwerking hebben uitgevoerd, zijn de resultaten niet erg overtuigend, maar u begrijpt het idee.
Gegevens
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)