Je vraag over Hoe bereken ik welke stad het meest verwant is? Bijvoorbeeld. Als ik naar stad 1 (Parijs) zou kijken, zouden de resultaten moeten zijn:Londen (2), New York (3) en op basis van uw verstrekte gegevensset is er maar één ding om te relateren, namelijk de gemeenschappelijke tags tussen de steden, dus de steden die de gemeenschappelijke tags delen, zijn de dichtstbijzijnde hieronder is de subquery die de steden vindt (anders dan die wordt verstrekt aan vind de dichtstbijzijnde steden) die de gemeenschappelijke tags delen
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Werken
Ik neem aan dat je een van de stads-ID's of namen invoert om de dichtstbijzijnde te vinden in mijn geval dat "Parijs" de ID heeft
SELECT tag_id FROM `cities_tags` WHERE city_id=1
Het zal alle tags id vinden die parijs dan heeft
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
Het haalt alle steden op behalve parijs die dezelfde tags hebben die parijs ook heeft
Hier is je Fiddle
Tijdens het lezen over de Jaccard-overeenkomst/index we hebben wat dingen gevonden om te begrijpen wat de termen eigenlijk zijn, laten we dit voorbeeld nemen, we hebben twee sets A &B
Ga nu naar uw scenario
Hier is de zoekopdracht tot nu toe die de perfecte jaccard-index berekent, je kunt het onderstaande voorbeeld van de viool zien
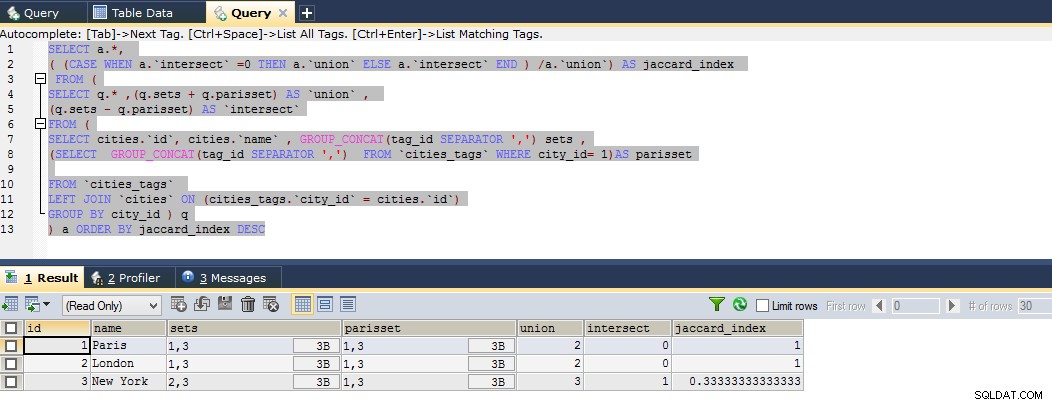
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
In bovenstaande query heb ik de ik heb de resultaatset afgeleid van twee subselects om mijn aangepaste berekende aliassen te krijgen
U kunt het filter in bovenstaande zoekopdracht toevoegen om de overeenkomst met zichzelf niet te berekenen
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
Dus het resultaat laat zien dat Parijs nauw verwant is aan Londen en vervolgens verwant is aan New York