Dit is het eerste artikel in een reeks artikelen over In-Memory OLTP. Het helpt u te begrijpen hoe de nieuwe Hekaton-motor intern werkt. We zullen ons concentreren op details van in-memory geoptimaliseerde tabellen en indexen. Dit is het artikel op instapniveau, wat betekent dat u geen SQL Server-expert hoeft te zijn, maar u moet wel enige basiskennis hebben over de traditionele SQL Server-engine.
Inleiding
De SQL Server 2014 In-Memory OLTP-engine (Hekaton-project) is vanaf het begin gemaakt om terabytes aan beschikbaar geheugen en enorme aantallen verwerkingskernen te gebruiken. In-Memory OLTP stelt gebruikers in staat om te werken met voor het geheugen geoptimaliseerde tabellen en indexen, en native gecompileerde opgeslagen procedures. U kunt het gebruiken samen met de op schijf gebaseerde tabellen en indexen, en opgeslagen T-SQL-procedures, die SQL Server altijd heeft geleverd.
In-Memory OLTP-engine internals en mogelijkheden verschillen aanzienlijk van de standaard relationele engine. U moet bijna alles herzien wat u wist over hoe meerdere gelijktijdige processen worden afgehandeld.
SQL Server-engine is geoptimaliseerd voor schijfgebaseerde opslag. Het leest 8KB-gegevenspagina's in het geheugen voor verwerking en schrijft 8KB-gegevenspagina's terug naar schijf na wijzigingen. Natuurlijk corrigeert SQL Server in de eerste plaats de wijzigingen aan de schijf in het transactielogboek. Het lezen van 8 KB datapagina's van schijf en terugschrijven kan veel I/O genereren en leidt tot hogere latentiekosten. Zelfs wanneer de gegevens zich in de buffercache bevinden, is de SQL-server ontworpen om aan te nemen dat dit niet het geval is, wat leidt tot inefficiënt CPU-gebruik.
Gezien de beperkingen van traditionele op schijven gebaseerde opslagstructuren, begon het SQL Server-team met het bouwen van een database-engine die is geoptimaliseerd voor een groot hoofdgeheugen en CPU's met meerdere kernen. Het team heeft de volgende doelen gesteld:
- Geoptimaliseerd voor gegevens die volledig in het geheugen waren opgeslagen, maar ook duurzaam waren bij het opnieuw opstarten van SQL Server
- Volledig geïntegreerd in de bestaande SQL Server-engine
- Zeer hoge prestaties voor OLTP-bewerkingen
- Ontworpen voor moderne CPU's
SQL Server In-Memory OLTP voldoet aan al deze doelen.
Over In-Memory OLTP
SQL Server 2014 In-Memory OLTP biedt een aantal technologieën om te werken met voor geheugen geoptimaliseerde tabellen, samen met de op schijf gebaseerde tabellen. Het geeft u bijvoorbeeld toegang tot gegevens in het geheugen met behulp van standaardinterfaces zoals T-SQL en SSMS. De volgende afbeelding toont geheugengeoptimaliseerde tabellen en indexen, als onderdeel van In-Memory OLTP (links) en de schijfgebaseerde tabellen (links) die 8KB-gegevenspagina's moeten lezen en schrijven. In-Memory OLTP ondersteunt ook native gecompileerde opgeslagen procedures en biedt een nieuwe in-memory OLTP-compiler.
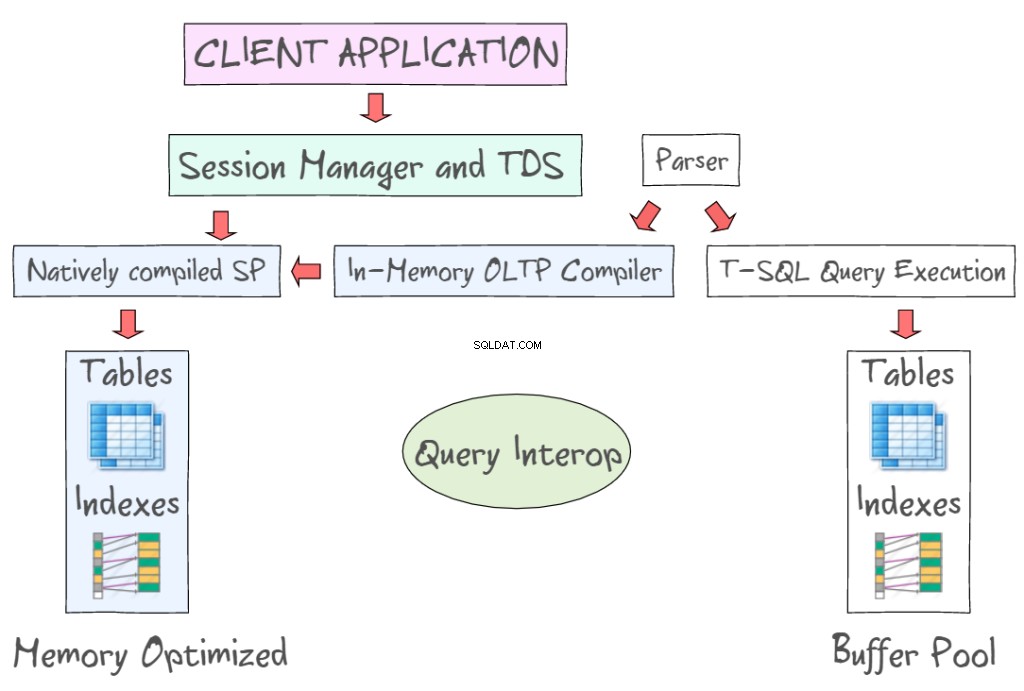
Met Query Interop kan T-SQL worden geïnterpreteerd om te verwijzen naar voor geheugen geoptimaliseerde tabellen. Als een transactie verwijst naar zowel voor geheugen geoptimaliseerde als op schijf gebaseerde tabellen, kan dit een cross-containertransactie worden genoemd. De client-app maakt gebruik van Tabular Data Stream - een applicatielaagprotocol dat wordt gebruikt om gegevens over te dragen tussen een databaseserver en een client. Het werd aanvankelijk ontworpen en ontwikkeld door Sybase Inc. voor hun relationele database-engine Sybase SQL Server in 1984, en later door Microsoft in Microsoft SQL Server.
Voor geheugen geoptimaliseerde tabellen
Bij het openen van op schijf gebaseerde tabellen kunnen de vereiste gegevens zich al in het geheugen bevinden, hoewel dit niet het geval is. Als er geen gegevens in het geheugen staan, moet SQL Server deze van de schijf lezen. Het meest fundamentele verschil bij het gebruik van voor geheugen geoptimaliseerde tabellen is dat de hele tabel en zijn indexen altijd in het geheugen worden opgeslagen . Gelijktijdige gegevensbewerkingen vereisen geen vergrendeling of vergrendeling.
Terwijl een gebruiker gegevens in het geheugen wijzigt, voert SQL Server enige schijf-I/O uit voor elke tabel die duurzaam moet zijn, anders gesproken, waar we een tabel nodig hebben om gegevens in het geheugen te behouden op het moment van een servercrash of herstart.
Op rijen gebaseerde opslagstructuur
Een ander belangrijk verschil is de onderliggende opslagstructuur. De op schijf gebaseerde tabellen zijn geoptimaliseerd voor block-addressable schijfopslag, terwijl in het geheugen geoptimaliseerde tabellen zijn geoptimaliseerd voor byte-adresseerbaar geheugenopslag.
SQL Server houdt gegevensrijen in 8K-gegevenspagina's bij, met ruimtetoewijzing van de gebieden voor op schijf gebaseerde tabellen. De gegevenspagina is de fundamentele eenheid van schijf- en geheugenopslag. Tijdens het lezen en schrijven van gegevens van schijf, leest en schrijft SQL Server alleen de relevante gegevenspagina's. Een gegevenspagina bevat slechts gegevens uit één tabel of index. Toepassingsprocessen wijzigen de rijen op verschillende gegevenspagina's indien nodig. Later, tijdens de CHECKPOINT-bewerking, herstelt SQL Server eerst de logboekrecords op schijf en schrijft vervolgens alle vuile pagina's naar schijf. Deze operatie veroorzaakt vaak veel willekeurige fysieke I/O.
Voor voor geheugen geoptimaliseerde tabellen zijn er geen gegevenspagina's en ook geen begrenzingen. Er worden alleen gegevensrijen achtereenvolgens naar het geheugen geschreven, in de volgorde waarin de transacties hebben plaatsgevonden. Elke rij bevat een indexaanwijzer naar de volgende rij. Alle I/O is in-memory scanning van deze structuren. Er is geen idee dat gegevensrijen worden geschreven naar een bepaalde locatie die bij een bepaald object hoort. U hoeft echter niet te denken dat voor geheugen geoptimaliseerde tabellen worden opgeslagen als de ongeorganiseerde set gegevensrijen (vergelijkbaar met op schijven gebaseerde heaps). Elke CREATE TABLE-instructie voor een tabel met geoptimaliseerd geheugen maakt ten minste één index die SQL Server gebruikt om alle gegevensrijen in die tabel aan elkaar te koppelen.
Elke afzonderlijke gegevensrij bestaat uit de rijkop en de payload die de feitelijke kolomgegevens zijn. In de koptekst wordt informatie opgeslagen over de instructie waarmee de rij is gemaakt, aanwijzers voor elke index in de doeltabel en tijdstempelwaarden. Tijdstempel geeft de tijd aan waarop een transactie een rij heeft ingevoegd en verwijderd. SQL Server-records worden bijgewerkt door een nieuwe rijversie in te voegen en de oude versie als verwijderd te markeren. Er kunnen op elk moment meerdere versies van dezelfde rij bestaan. Dit maakt gelijktijdige toegang tot dezelfde rij mogelijk tijdens de gegevenswijziging. SQL Server geeft de rijversie weer die relevant is voor elke transactie op basis van het tijdstip waarop de transactie is gestart ten opzichte van de tijdstempels van de rijversie. Dit is de kern van de nieuwe gelijktijdigheidscontrole van meerdere versies mechanisme voor tabellen in het geheugen.
Oracle heeft trouwens een uitstekend controlesysteem voor meerdere versies. In principe werkt het als volgt:
- Gebruiker A start een transactie en werkt 1000 rijen bij met een bepaalde waarde op tijdstip T1.
- Gebruiker B leest dezelfde 1000 rijen op tijdstip T2.
- Gebruiker A werkt rij 565 bij met waarde Y (oorspronkelijke waarde was X).
- Gebruiker B bereikt rij 565 en ontdekt dat er een transactie actief is sinds Tijd T1.
- De database retourneert het ongewijzigde record uit de logboeken. De geretourneerde waarde is de waarde die op dat moment is vastgelegd en kleiner is dan of gelijk is aan T2.
- Als het record niet kan worden opgehaald uit de herhalingslogboeken, betekent dit dat de database niet correct is ingesteld. Er moet meer ruimte worden toegewezen aan de logs.
- De geretourneerde resultaten zijn altijd hetzelfde met betrekking tot de starttijd van de transactie. Dus binnen de transactie wordt de leesconsistentie bereikt.
Native samengestelde tabellen
Het laatste grote verschil is dat de in-memory geoptimaliseerde tabellen natively gecompileerd . Wanneer een gebruiker een voor geheugen geoptimaliseerde tabel of index maakt, slaat SQL Server de structuur van elke tabel (samen met alle indexen) op in de metagegevens. Later gebruikt SQL Server die metadata om in DDL een set moedertaalroutines te compileren voor toegang tot de tabel. Dergelijke DDL zijn geassocieerd met de database, maar maken er eigenlijk geen deel van uit.
Met andere woorden, SQL Server houdt niet alleen tabellen en indexen in het geheugen, maar ook DDL voor toegang tot en wijziging van deze structuren. Nadat een tabel is gewijzigd, moet SQL Server alle DDL opnieuw maken voor tabelbewerkingen. Daarom kunt u een eenmaal aangemaakte tabel niet wijzigen. Deze bewerkingen zijn onzichtbaar voor gebruikers.
Natively gecompileerde opgeslagen procedures
De beste prestaties worden bereikt door gebruik te maken van native gecompileerde opgeslagen procedures om toegang te krijgen tot native gecompileerde tabellen. Dergelijke procedures bevatten processorinstructies en kunnen direct door de CPU worden uitgevoerd zonder verdere compilatie. Er zijn echter enkele beperkingen op de T-SQL-constructies voor de native gecompileerde opgeslagen procedures (vergeleken met traditioneel geïnterpreteerde code). Een ander belangrijk punt is dat native gecompileerde opgeslagen procedures alleen toegang hebben tot tabellen die geoptimaliseerd zijn voor het geheugen.
Geen sloten
In-Memory OLTP is een systeem zonder slot. Dit is mogelijk omdat SQL Server nooit een bestaande rij wijzigt. De UPDATE-bewerking maakt de nieuwe versie aan en markeert de vorige versie als verwijderd. Vervolgens wordt een nieuwe rijversie ingevoegd met nieuwe gegevens erin.
Indexen
Zoals je misschien al geraden had, zijn indexen heel anders dan de traditionele. In-memory geoptimaliseerde tabellen hebben geen pagina's. SQL Server maakt gebruik van indexen om alle rijen die bij een tabel horen, in één enkele structuur te koppelen. We kunnen de instructie CREATE INDEX niet gebruiken om een index te maken voor de in het geheugen geoptimaliseerde tabel. Nadat u de PRIMAIRE SLEUTEL voor een kolom hebt gemaakt, maakt SQL Server automatisch een unieke index voor die kolom. Het is eigenlijk de enige toegestane unieke index. U kunt maximaal acht indexen maken op een voor geheugen geoptimaliseerde tabel.
Naar analogie met tabellen houdt SQL Server voor het geheugen geoptimaliseerde indexen in het geheugen. SQL Server registreert echter nooit bewerkingen op indexen. SQL Server houdt indexen automatisch bij tijdens tabelwijzigingen.
Voor geheugen geoptimaliseerde tabellen ondersteunen twee typen indexen:hash-index en bereikindex . Beide zijn niet-geclusterde structuren.
De hash-index is een nieuw type index, speciaal ontworpen voor voor geheugen geoptimaliseerde tabellen. Het is uitermate handig voor het uitvoeren van zoekopdrachten op specifieke waarden. De index zelf wordt opgeslagen als een hashtabel. Het is een array van hash-buckets, waarbij elke bucket een verwijzing is naar een enkele rij.
De bereikindex (niet-geclusterd) is handig voor het ophalen van waardenbereiken.
Herstel
Het basisherstelmechanisme voor een database met voor geheugen geoptimaliseerde tabellen is hetzelfde als het herstelmechanisme van databases met op schijf gebaseerde tabellen. Het herstel van voor geheugen geoptimaliseerde tabellen omvat echter de stap van het laden van de voor geheugen geoptimaliseerde tabellen in het geheugen voordat de database beschikbaar is voor gebruikerstoegang.
Wanneer SQL Server opnieuw wordt opgestart, doorloopt elke database de volgende fasen van het herstelproces:analyse , opnieuw , en ongedaan maken .
Tijdens de analysefase identificeert de In-Memory OLTP-engine de checkpoint-inventaris die moet worden geladen en laadt de systeemtabellogboekvermeldingen vooraf. Het zal ook enkele logbestanden voor bestandstoewijzing verwerken.
Tijdens de herhalingsfase worden gegevens van de gegevens- en deltabestandsparen in het geheugen geladen. Vervolgens worden de gegevens bijgewerkt vanuit het actieve transactielogboek op basis van het laatste duurzame controlepunt en worden de in-memory tabellen gevuld en indexen opnieuw opgebouwd. Tijdens deze fase worden schijfgebaseerd en geheugen-geoptimaliseerd tabelherstel gelijktijdig uitgevoerd.
De ongedaanmakingsfase is niet nodig voor voor geheugen geoptimaliseerde tabellen, aangezien In-Memory OLTP geen niet-vastgelegde transacties registreert voor voor geheugen geoptimaliseerde tabellen.
Wanneer alle bewerkingen zijn voltooid, is de database beschikbaar voor toegang.
Samenvatting
In dit artikel hebben we een snelle blik geworpen op de SQL Server In-Memory OLTP-engine. We hebben geleerd dat voor geheugen geoptimaliseerde structuren in het geheugen worden opgeslagen. Applicatieprocessen kunnen de vereiste gegevens vinden door toegang te krijgen tot deze structuren in het geheugen zonder dat schijf-I/O nodig is. In de volgende artikelen bekijken we hoe u In-Memory OLTP-databases en -tabellen kunt maken en openen.
Verder lezen
In-Memory OLTP:wat is er nieuw in SQL Server 2016
Indexen gebruiken in voor geheugen geoptimaliseerde tabellen voor SQL Server