Databasebeheerder doet altijd zijn best om de queryprestaties van SQL Server af te stemmen. De eerste stap bij het afstemmen van de queryprestaties is het analyseren van het uitvoeringsplan van een query. Onder bepaalde voorwaarden kan SQL Server Query Optimizer verschillende uitvoeringsplannen maken. Op dit punt zou ik enkele opmerkingen willen toevoegen over SQL Server Query Optimizer. SQL Server Query Optimizer is een op kosten gebaseerde optimizer die uitvoeringsplannen analyseert en het optimale uitvoeringsplan voor een query bepaalt. Het belangrijkste sleutelwoord voor de SQL Server Query Optimizer is een optimaal uitvoeringsplan dat niet noodzakelijk het beste uitvoeringsplan is. Dat is de reden waarom, als SQL Server Query Optimizer probeert het beste uitvoeringsplan voor elke query te vinden, dit extra tijd kost en schade toebrengt aan de prestaties van SQL Server Engine. In SQL Server 2016 heeft Microsoft een nieuwe mogelijkheid toegevoegd aan SQL Server Management Studio, genaamd Compare Showplan. Met deze functie kunnen we twee verschillende uitvoeringsplannen met elkaar vergelijken. Tegelijkertijd kunnen we deze optie offline gebruiken, wat betekent dat we de SQL Server-instantie niet hoeven te verbinden. Stel je voor dat je een query schrijft en deze query presteert goed in de TEST-omgeving, maar in PROD (productieomgeving) presteert hij erg slecht. Om dit probleem aan te pakken, moeten we uitvoeringsplannen vergelijken. Vóór deze functie openden we twee SQL Server Management Studios en brachten we uitvoeringsplannen naast elkaar, maar deze methode was erg onhandig.
Hoe twee uitvoeringsplannen vergelijken?
In deze demonstratie zullen we de AdventureWorks-database gebruiken en twee uitvoeringsplannen vergelijken die een verschillende Cardinality Estimation Model-versie hebben en dit verschil detecteren met Compare Showplan.
Eerst openen we een nieuw queryvenster in SQL Server Management Studio en klikken we op Include Actual Execution Plan en voer dan de volgende query uit.
SELECT
soh.[SalesPersonID]
,p.[FirstName] + ' ' + COALESCE(p.[MiddleName], '') + ' ' + p.[LastName] AS [FullName]
,e.[JobTitle]
,st.[Name] AS [SalesTerritory]
,soh.[SubTotal]
,YEAR(DATEADD(m, 6, soh.[OrderDate])) AS [FiscalYear]
FROM [Sales].[SalesPerson] sp
INNER JOIN [Sales].[SalesOrderHeader] soh
ON sp.[BusinessEntityID] = soh.[SalesPersonID]
INNER JOIN [Sales].[SalesTerritory] st
ON sp.[TerritoryID] = st.[TerritoryID]
INNER JOIN [HumanResources].[Employee] e
ON soh.[SalesPersonID] = e.[BusinessEntityID]
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = sp.[BusinessEntityID]
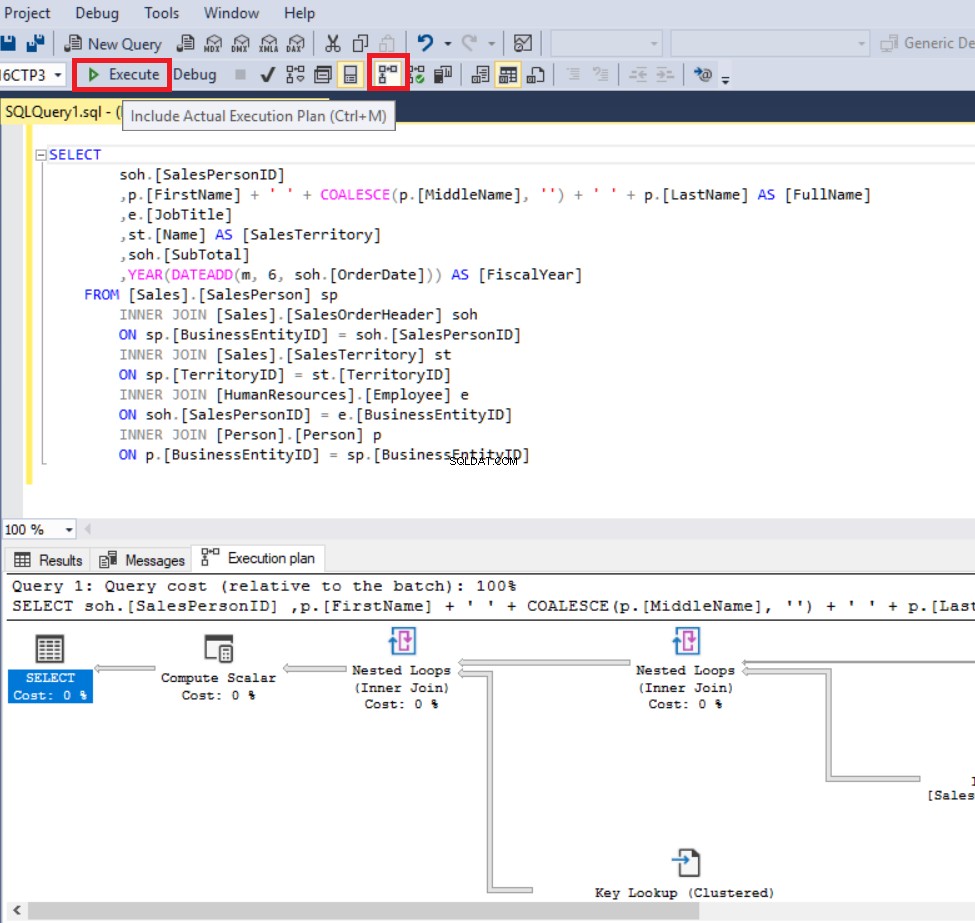
In deze stap slaan we ons eerste uitvoeringsplan op. Klik met de rechtermuisknop ergens in het uitvoeringsplan en klik op Uitvoeringsplan opslaan als en sla het uitvoeringsplan op als ExecutionPlan_CE140.sqlplan.
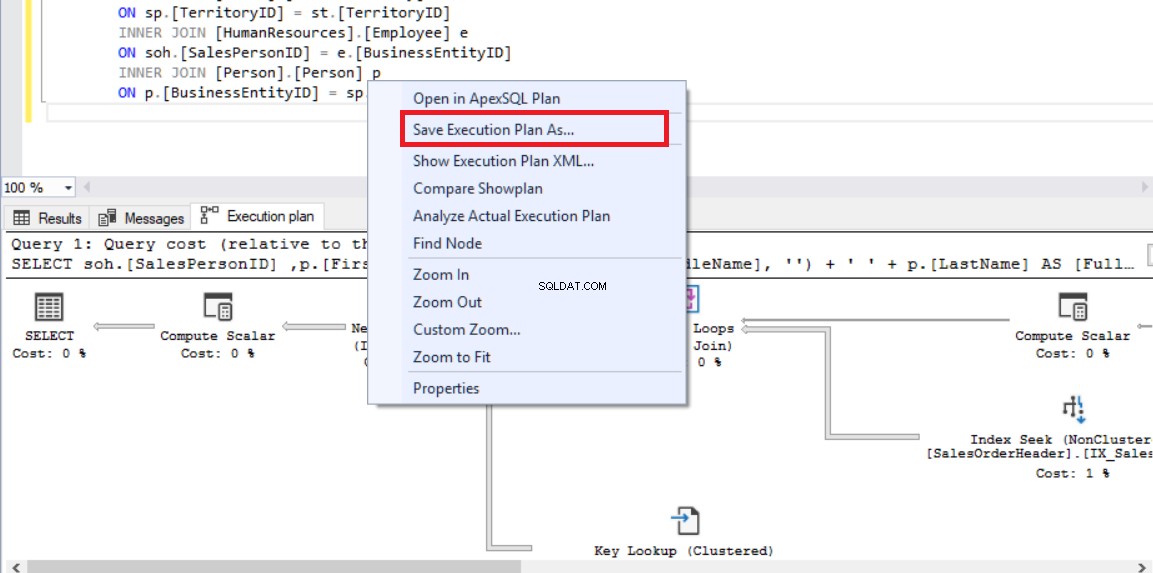
Nu zullen we een nieuw querytabblad openen in SQL Server Management Studio en de onderstaande query uitvoeren. In deze query voegen we de FORCE_LEGACY_CARDINALITY_ESTIMATION-queryhint toe aan het einde van de query, waardoor de oudere versie van het kardinaliteitsschattingsmodel moet worden gebruikt.
De taak van Kardinaliteitsschatting is om te voorspellen hoeveel rijen onze zoekopdracht zal retourneren.
SELECT
soh.[SalesPersonID]
,p.[FirstName] + ' ' + COALESCE(p.[MiddleName], '') + ' ' + p.[LastName] AS [FullName]
,e.[JobTitle]
,st.[Name] AS [SalesTerritory]
,soh.[SubTotal]
,YEAR(DATEADD(m, 6, soh.[OrderDate])) AS [FiscalYear]
FROM [Sales].[SalesPerson] sp
INNER JOIN [Sales].[SalesOrderHeader] soh
ON sp.[BusinessEntityID] = soh.[SalesPersonID]
INNER JOIN [Sales].[SalesTerritory] st
ON sp.[TerritoryID] = st.[TerritoryID]
INNER JOIN [HumanResources].[Employee] e
ON soh.[SalesPersonID] = e.[BusinessEntityID]
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = sp.[BusinessEntityID]
OPTION (USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION')); We klikkenShowplan vergelijken en selecteer het vorige uitvoeringsplan dat is opgeslagen als ExecutionPlan_CE140.sqlplan.
De volgende afbeelding illustreert het eerste scherm van het SQL Server-uitvoeringsvergelijkingsplan en roze gekleurde gemarkeerde gebieden definiëren vergelijkbare bewerkingen.
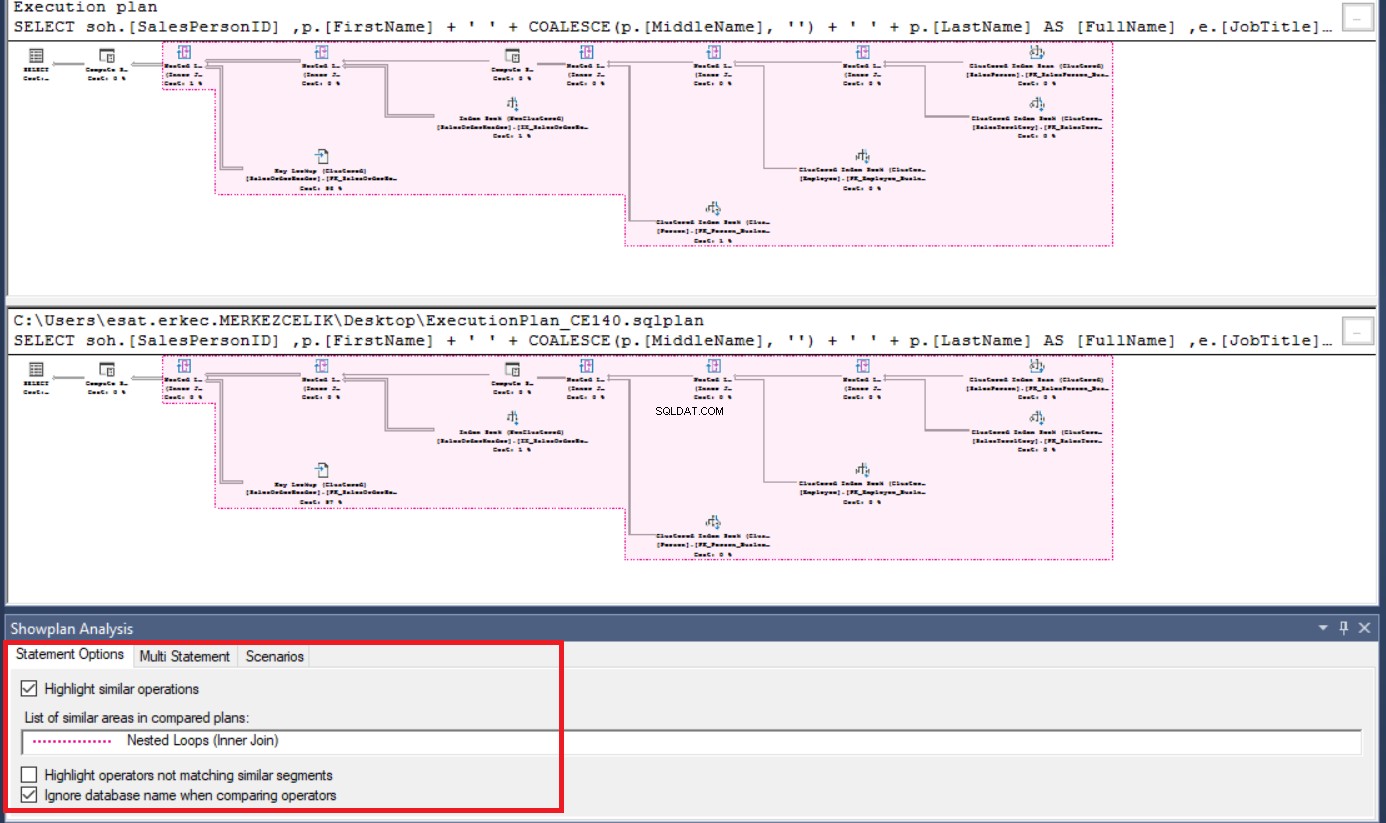
Als we op een operator in het onderstaande of bovenstaande uitvoeringsplanscherm klikken, markeert SQL Server Management Studio andere vergelijkbare operators. Aan de rechterkant van het paneel vindt u eigenschappen en vergelijkingsdetails van eigenschappen.
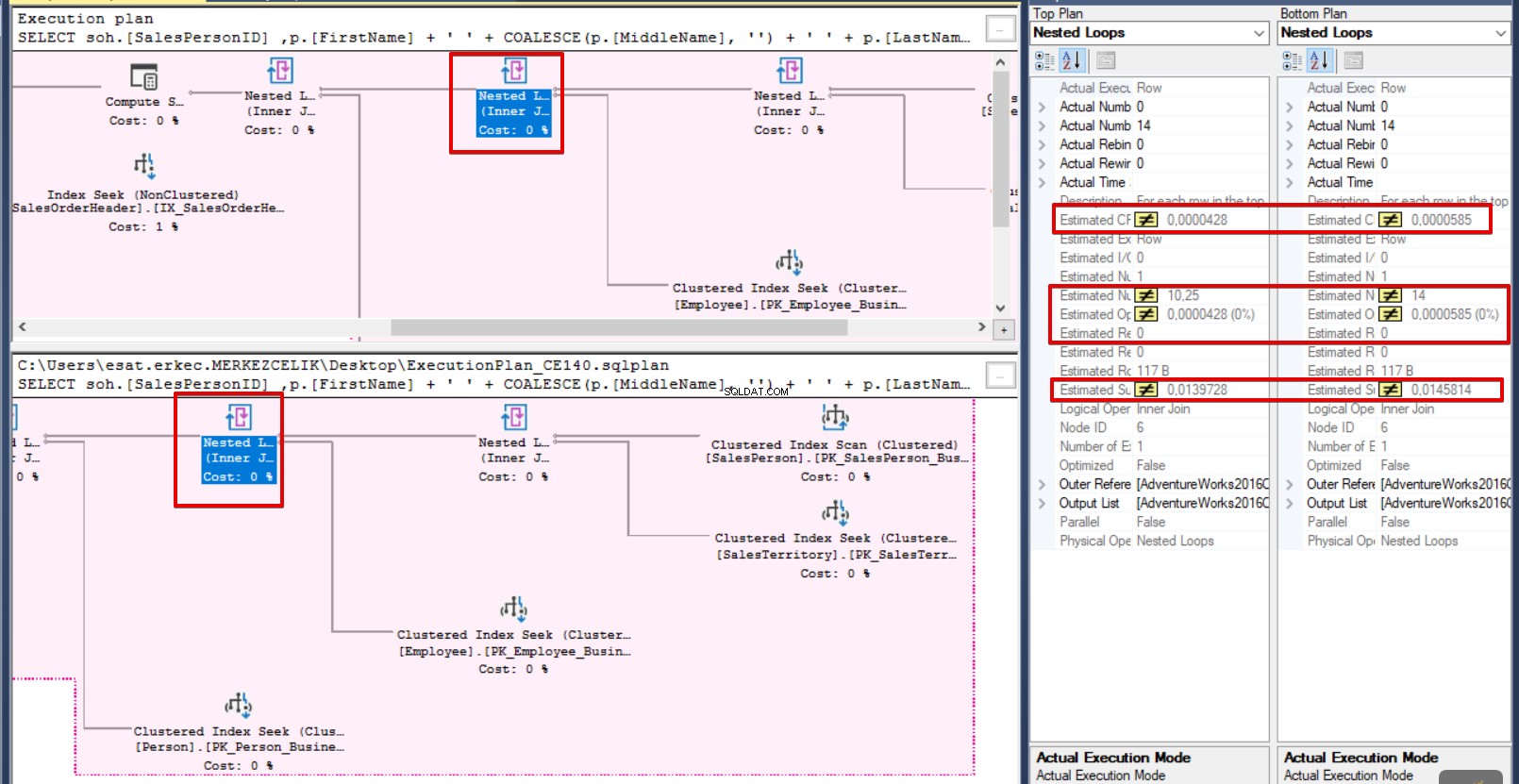
In deze stap zullen we de ShowPlan Analysis-opties wijzigen en de operator die niet overeenkomt markeren. Onderaan het scherm zien we de Showplan-analyse paneel. Als we Vergelijkbare bewerkingen markeren . wissen en selecteer Markeer operators die niet overeenkomen met vergelijkbare segmenten, SQL Server Management Studio benadrukt ongeëvenaarde operator. Klik daarna op Selecteer operators in het onderstaande en bovenstaande uitvoeringsplan in het paneel. SQL Server Management Studio vergelijkt eigenschappen van de geselecteerde operators en plaatst ongelijkheidstekens op de niet-identieke waarden.
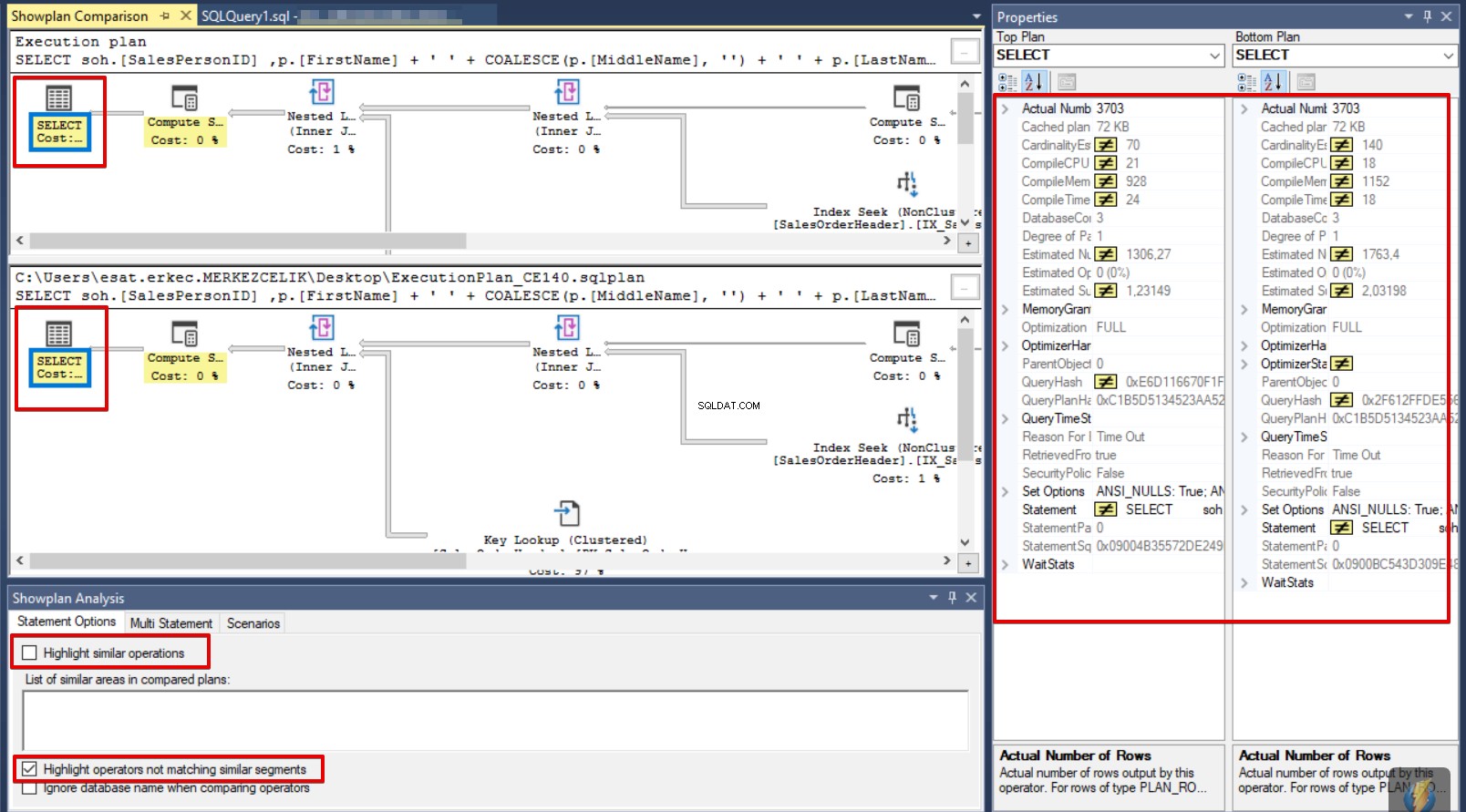
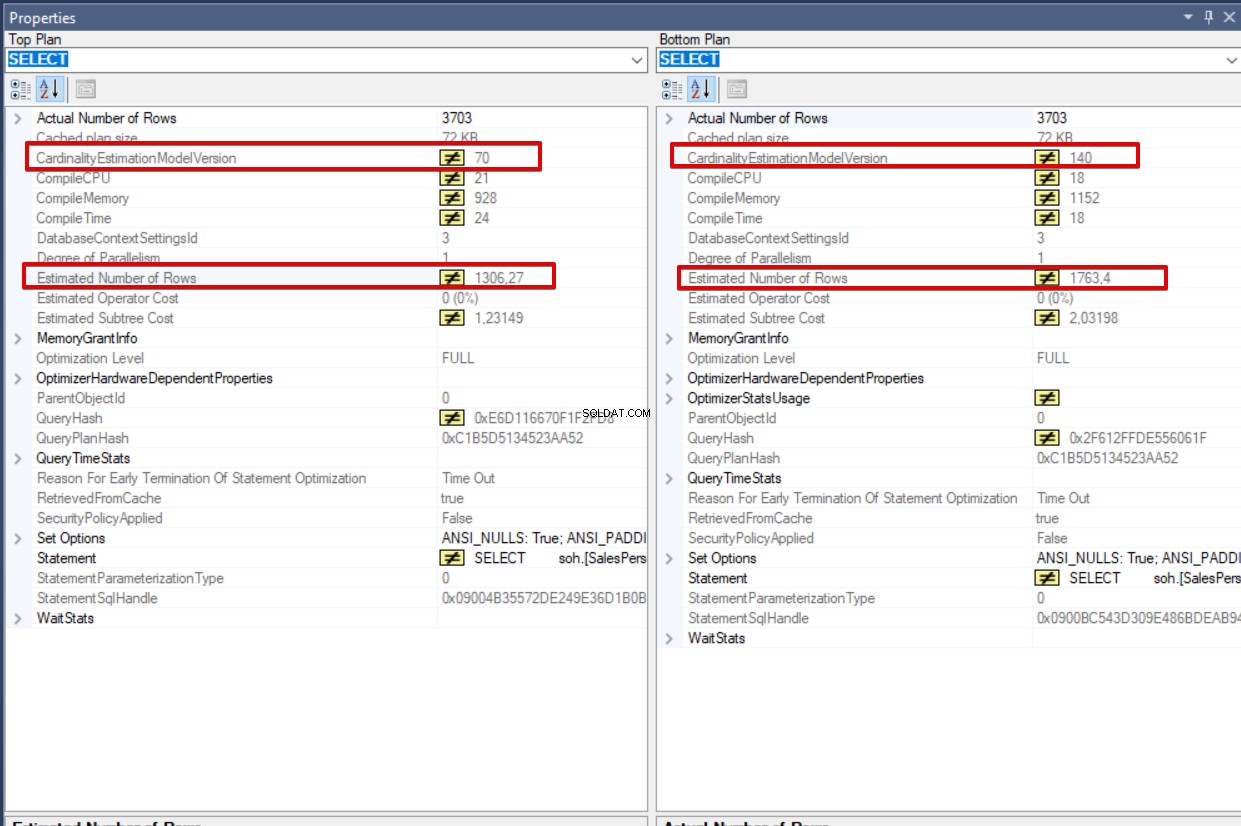
Als we dit scherm in meer detail analyseren, is het eerste ding de versie van het kardinaliteitsschattingsmodel verschil. De eerste queryversie is 70 en de tweede is 140. Dit verschil is van invloed op Geschat aantal rijen . De belangrijkste reden die de verschillende Geschatte aantal rijen . veroorzaakt is een andere versie van Cardinality Estimation. De Cardinality Estimation-versie heeft dus rechtstreeks invloed op de geschatte statistieken van de query. Voor deze zoekopdrachtvergelijking kunnen we concluderen dat de zoekopdracht waarvan de Cardinality Estimation-versie 140 is, beter presteert omdat het geschatte aantal rijen dicht bij het Werkelijke aantal rijen ligt. . Deze zaak kan worden verduidelijkt aan de hand van de onderstaande tabel.
[tabel id=50 /]
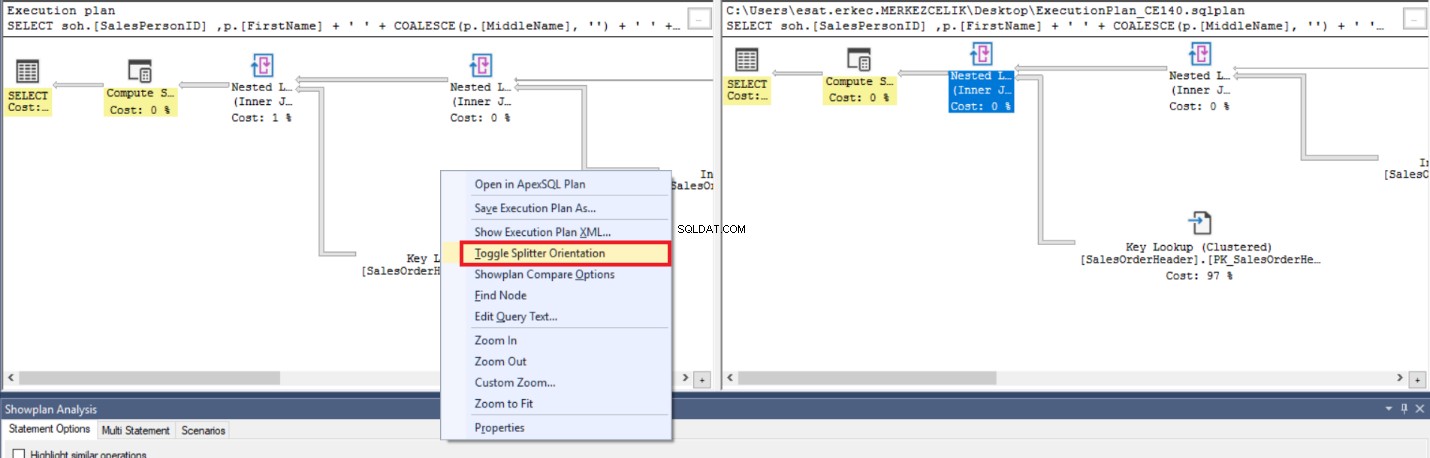
Als we uitvoeringsplannen naast elkaar op hetzelfde scherm willen zien, kunnen we klikken op Toggle Splitter Orientation .
Nu gaan we weer een demonstratie geven. We zullen de onderstaande query bekijken en uitvoeringsplannen vergelijken voor en na het maken van de index.
Als we kijken naar het onderstaande query-uitvoeringsplan, wordt aanbevolen een niet-geclusterde index te maken.
SELECT [CarrierTrackingNumber] FROM [Sales].[SalesOrderDetail] WHERE [SalesOrderDetailID]=12
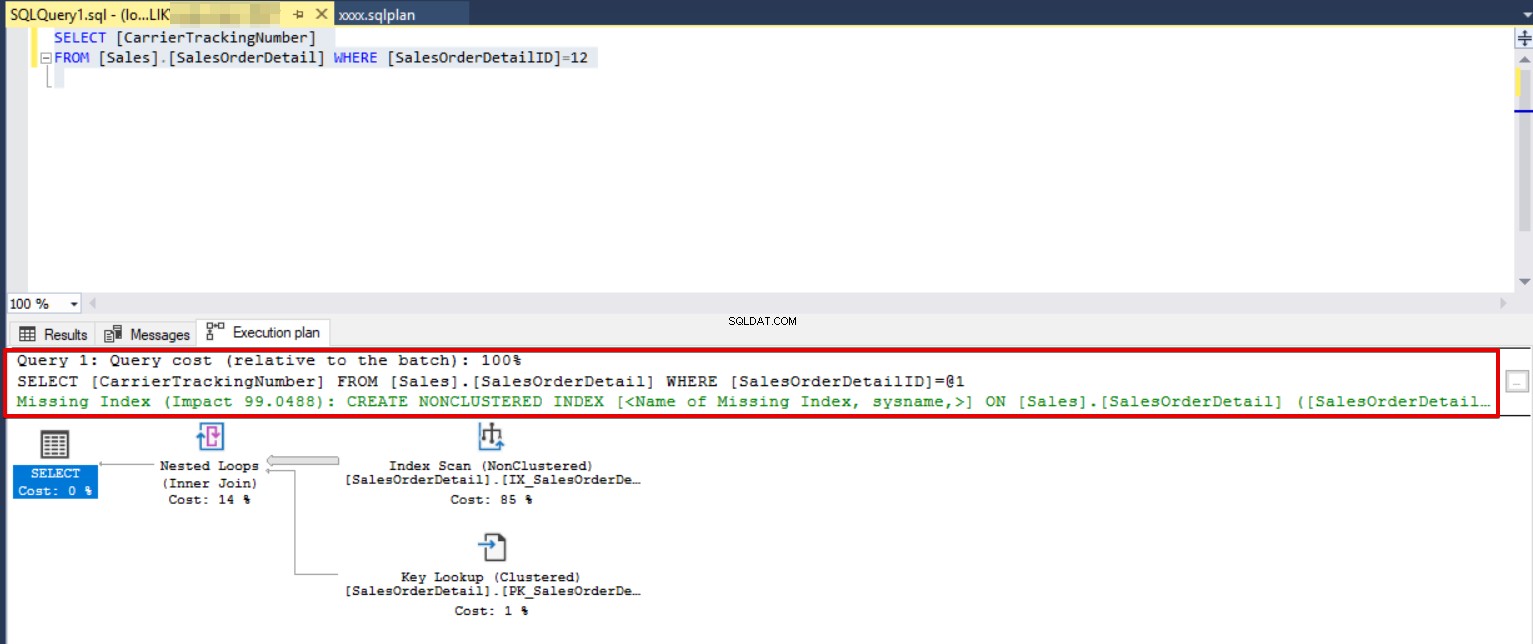
We zullen de aanbevolen index toepassen en dezelfde zoekopdracht opnieuw uitvoeren.
CREATE NONCLUSTERED INDEX Index_NC ON [Sales].[SalesOrderDetail] ([SalesOrderDetailID]) GO SELECT [CarrierTrackingNumber] FROM [Sales].[SalesOrderDetail] WHERE [SalesOrderDetailID]=12
In deze laatste stap zullen we de uitvoeringsplannen vergelijken.
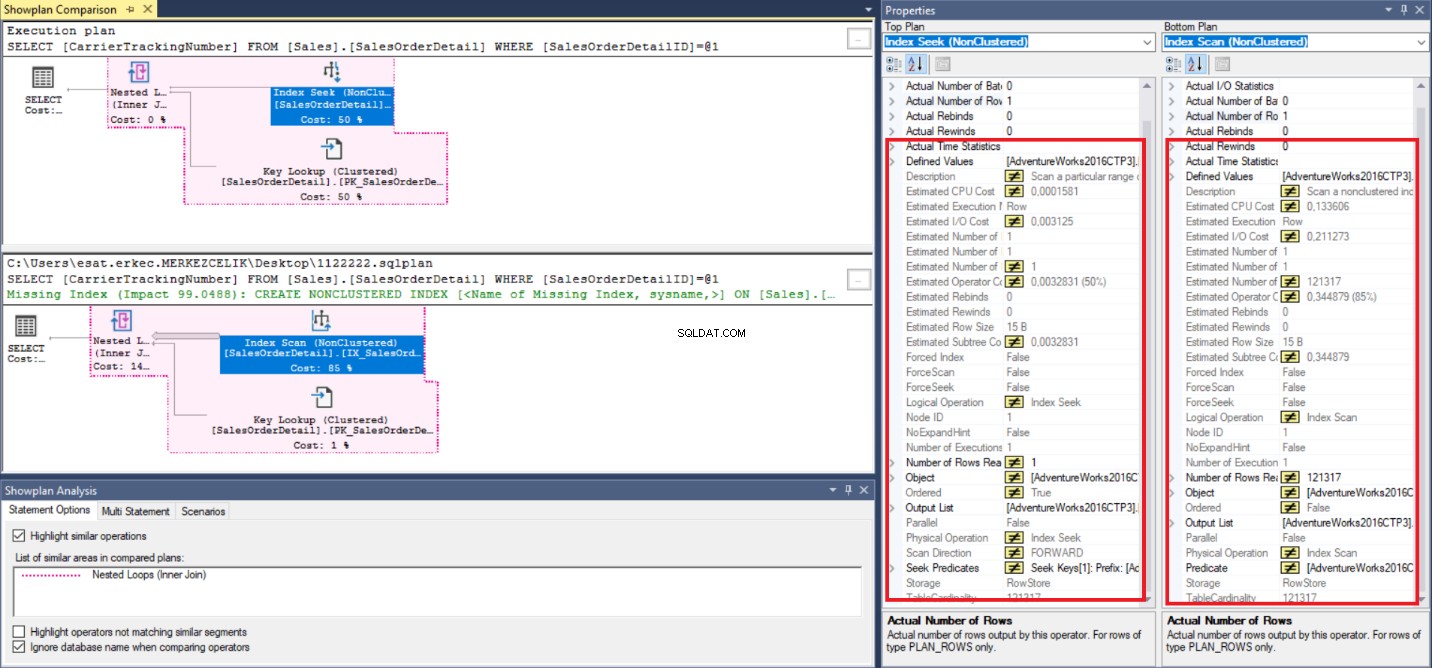
In de bovenstaande afbeelding kunnen we verschillende informatie over uitvoeringsplannen verkrijgen. Maar het grote verschil is de logische bewerking veld. Een daarvan is Index Seek en een andere is Index Scan en deze differentiatie van bewerkingen leidt tot ongelijke geschatte en werkelijke metrische waarden. Ten slotte presteert de Index Seek-operator beter dan de Index Scan-operator.
Conclusies
Zoals we in het artikel vermeldden, biedt de functie Showplan vergelijken enkele voordelen voor databaseontwikkelaars of -beheerders. Sommige hiervan kunnen worden geteld als:
- Eenvoudig om het verschil tussen twee uitvoeringsplannen te vergelijken.
- Eenvoudig om prestatieproblemen met query's in verschillende SQL Server-versies te detecteren.
- Eenvoudig om prestatieproblemen met query's in verschillende omgevingen te detecteren.
- Verduidelijkt eenvoudig de wijzigingen in het uitvoeringsplan voor en na het maken van de index.
Referenties
- Kadinaliteitsschatting (SQL Server)
- Handleiding voor architectuur van queryverwerking